Meta提出Multi-Token注意力机制(MTA),解决Transformer处理长文本多Token关联问题。实验表明,MTA在多个任务中优于传统Transformer。
原文标题:Multi-Token突破注意力机制瓶颈,Meta发明了一种很新的Transformer
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 MTA 在长距离依赖任务上表现出色,那么在实际应用中,例如处理超长文本、对话生成等场景,MTA 有哪些潜在的应用价值和挑战?
3、MTA 通过键-查询卷积和头混合卷积来改进注意力机制,那么未来是否有可能将这两种卷积方式应用于其他的 Transformer 变体或新型注意力机制中?
原文内容
机器之心报道
编辑:蛋酱、杜伟
Attention 还在卷自己。
当上下文包含大量 Token 时,如何在忽略干扰因素的同时关注到相关部分,是一个至关重要的问题。然而,大量研究表明,标准注意力在这种情况下可能会出现性能不佳的问题。
标准多头注意力的工作原理是使用点积比较当前查询向量与上下文 Token 对应的键向量的相似性。与查询相似的关键字会获得更高的注意力权重,随后其值向量会主导输出向量。
例如,与「Alice」Token 相对应的查询向量能够定位上下文中所有提及「Alice」的内容。然而,每个注意力权重只取决于单个关键字和查询向量(除了归一化为 1)。
对单个 token 向量相似性的依赖给注意力机制带来了根本性的限制。在许多情况下,上下文的相关部分无法通过单个 token 来识别。例如,查找一个同时提到「Alice」和「rabbit」的句子需要查询向量对这两个 token 进行编码。用一个注意头查找「Alice」,再用另一个注意头查找「rabbit」,可以分别找到这两个词,但不足以确定这两个词在哪里被同时提及虽然可以通过 Transformer 的层将多个 token 编码成一个向量,但这需要增加维度,而且模型需要将大量容量用于这项任务。
在本文中,研究者提出了一种超越「单个 token」瓶颈的新型注意力机制 ——Multi-Token 注意力(MTA),其高层次目标是利用多个向量对的相似性来确定注意力必须集中在哪里。
而研究者仅通过对现有注意力机制进行简单的修改去实现这一目标。他们设计了对注意力权重的卷积运算,该运算在三个维度上运行:键、查询和注意力头。这就允许其注意力权重以相邻键、之前的查询和其他头为条件。
直观地说,在上述例子中,MTA 可以先分别查找「Alice」和「rabbit」的提及,然后将这些注意力组合在一起,只关注两者都存在的地方。

-
论文:Multi-Token Attention
-
论文链接:https://arxiv.org/abs/2504.00927
具体来说,这项研究的亮点在于:
-
研究者首先用一个有趣的玩具任务进行实验,该任务揭示了标准注意力的缺陷,并证明 MTA 可以轻松解决这一问题;
-
接下来,研究者通过在标准语言建模任务中对 1050 亿个词库的 880M 个参数模型进行预训练,对本文的方法进行了大规模测试;
-
研究者发现 MTA 在验证复杂度和标准基准任务方面都有所改进,而参数数量只增加了 0.001%;
-
此外,研究者还在长语境任务(如 Needle-in-the-Haystack 和 BabiLong)上评估了所生成的模型,结果发现 MTA 的表现明显优于基线。
方法概览
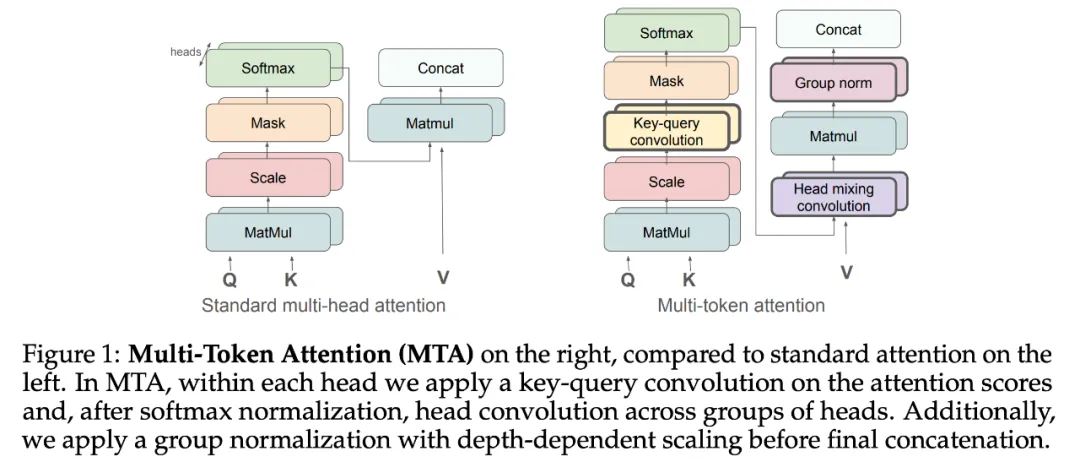
如图 1(右图)所示,本文提出的「Multi-Token 注意力」由建立在多头注意力基础上的三个重要部分组成:键 - 查询卷积、头混合卷积和带深度缩放的组归一化。
研究者提出了键 - 查询卷积,以在头部内组合多个键和查询,并提出了头卷积,在头之间共享知识并放大重要信息。最后,研究者应用具有深度缩放功能的组归一化来抵消残差流,改善梯度流。
键 - 查询卷积(key-query convolution)
对于 pre-softmax 卷积,MTA 在注意力 logit 上进行了一个卷积操作,并结合来自多个查询和键 token 的信息:
键和查询的长度维数中采用了卷积,同时 batch 和头维数保持独立。更确切地说,从查询 q_i 到键 k_j 的注意力权重 a_ij 计算如下:

对于键,研究者使用指示函数 1_i≥j−j′将未来键归零。但是,这样的掩码太复杂,无法实现(必须修改卷积 CUDA 内核),因此本文提出了一个更简单的版本,将已有的因果掩码应用了两次:
对于 post-softmax 卷积,研究者同样在注意力权重的顶部进行卷积操作:
这使得注意力权重之间的交互累加而不是相乘。研究者试验了两个版本,但默认情况下使用 pre-softmax 版本。每个注意力头都有单独的 θ 参数,所以它们可以执行不同的卷积操作。选择的内核维数决定了如何将离得远的 token 组合在一起。
头混合卷积(head mixing convolution)
键 - 查询卷积允许从不同的时间步中混合注意力权重,而研究者进一步提出在头组中使用头卷积,因此可以将不同头的注意力权重组合起来。
具体地,对于大小为 c_h 的头卷积内核,所有头被分为 M/c_h 个组。在每个组中,研究者使用了不重叠的卷积操作。这样一来,MTA 不仅允许在每个头内部的多个查询和键向量上调整注意力权重,还可以跨头共享注意力信息。
举例而言,考虑将所有头分为两个组,使内核大小为「c_h = 2」。当使用上标来表示头指数时,则 A^1 和 A^2 是来自两个不同头的注意力权重。这时,新的注意力权重如下:
其中 w_11、w_12、w_21 和 w_22 是内核权重。这里 softmax 之后出现混合,但可以在 softmax 之前混合 logit。
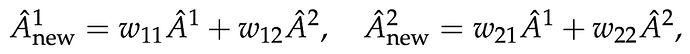
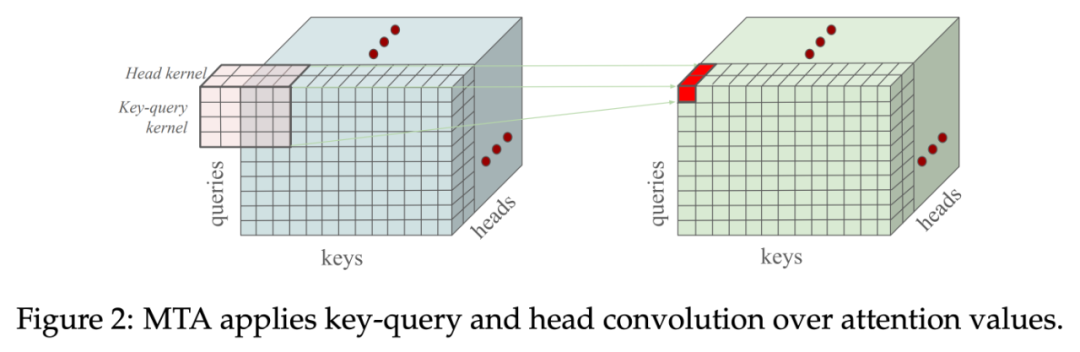
将一切组合起来(putting everything together)
在前文中,研究者引入两种不同的方式来混合注意力权重,一是跨键 - 查询时间步,二是跨不同头。这两种方式都可以在单个 MTA 模块中实现。每种方式都有 pre - 和 post-softmax 版本,因此有多种方法将它们组合在一起。如果都采用 pre-softmax 来混合,则可以通过单个 3 维卷积操作来实现,如下图 2 所示。
实验结果
研究者在一系列标准和长距离(long-range)依赖任务上对 MTA 架构进行了实验,并与基线进行了比较,从「toy」任务开始。他们使用了键 - 查询卷积 pre-softmax 和头混合 post-softmax,另有说明除外。
简单的 toy 任务
研究者首先测试了 toy 任务,以验证本文方法相较于标准多头注意力的有效性。此任务中为模型提供了一个块序列,其中每个块由 N 个随机字母组成。相比之下,MTA 先是找到了每个问题字母的位置,然后使用卷积操作来增加所有 L 字母一起被发现的位置的注意力。
结果如下表 1 所示,如预期一样,具有标准多头注意力的 transformer 解决这项任务时,即使问题中只有「L = 2」字母,通常也无法找到目标块。相比之下,MTA 以接近零误差的成功率解决了所有版本的任务。

大型语言建模
对于语言建模实验,研究者对 880M 参数的模型进行了预训练,并比较了 Transformer、DIFF Transformer 和 Transformer with MTA。对于每个模型,他们进行了两次训练,并在下表 2 中提供了平均验证困惑度。
结果显示,经过 MTA 训练的模型,在所有验证数据集上均实现了性能提升,即使只在四分之一的层中应用键 - 查询卷积,并且要比 DIFF Transformer 的可学习参数更少。此外,使用层 scaling 的组归一化是一个重要组件,可以为 DIFF Transformer 和 MTA 架构提供更优越的性能。
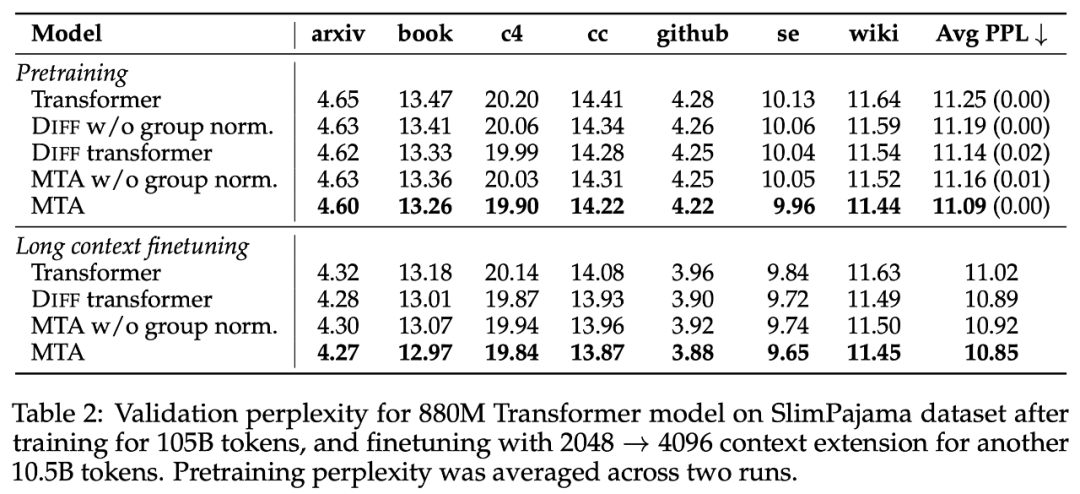
接着,研究者在以上相同的六个数据集上对模型进行了另外 10.5B token 的微调,并将上下文长度从 2048 增加到了 4096。同时将 RoPE 的 θ 值增加到了 50 万,将权重衰减变成 0,并将预热步骤降为 50,其他参数与预训练阶段保持一致。结果表明,使用 MTA 生成的 Transformer 模型在困惑度评估中同样优于新的基线。
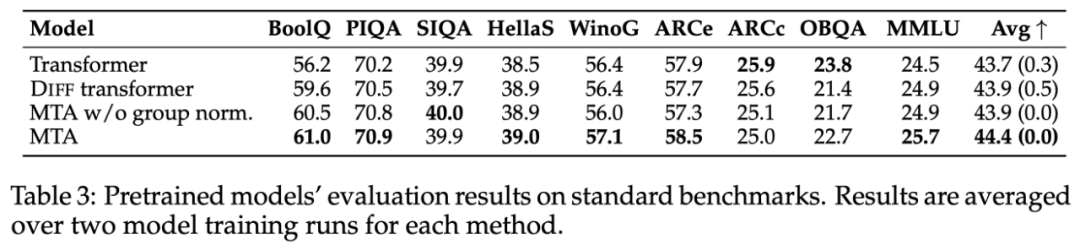
在 zero-shot 设置下,研究者进一步评估了模型在一系列流行基准上的表现,结果如下表 3 所示。经过 MTA 训练的模型在大多数基准上优于基线,并取得了更高的平均分,尽管这些并不是长上下文任务。
长距离依赖任务 Long-range dependency tasks
此前的研究表明,Transformer 很难找到相关信息,尤其是在长上下文中。
为了在这种情况下测试 MTA,研究者在三个任务中对训练有素的模型进行了评估: LAMBADA、NeedleIn-A-Haystack 和 BabiLong。所有这些任务都要求模型几乎要密切关注埋藏在上下文中的长距离 tokens。
LAMBADA。研究者观察到使用 MTA 训练的模型在正确猜测下一个单词方面更胜一筹(如表 4),明显优于基线 Transformer 模型。

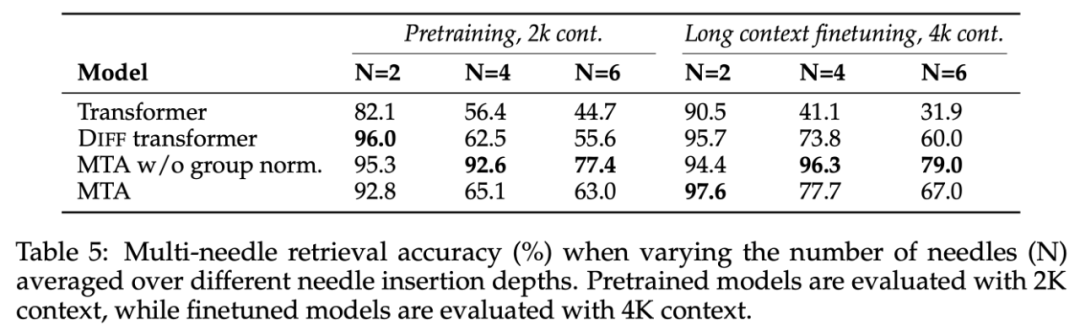
如表 5 所示,使用 MTA 训练的模型在所有「针数」和不同上下文长度的捞针能力都有显著提高。
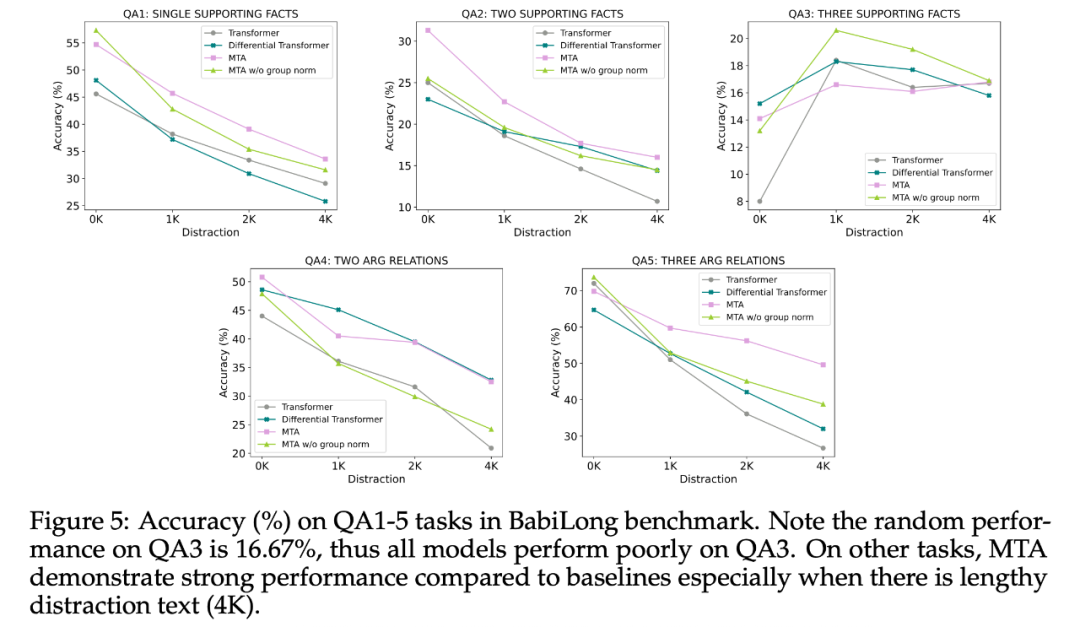
BabiLong。研究者将重点放在了 QA1-5 任务上,在这些任务中,正确的回答需要不同数量的事实或论据关系。输入和目标输出样本如表 7 所示。
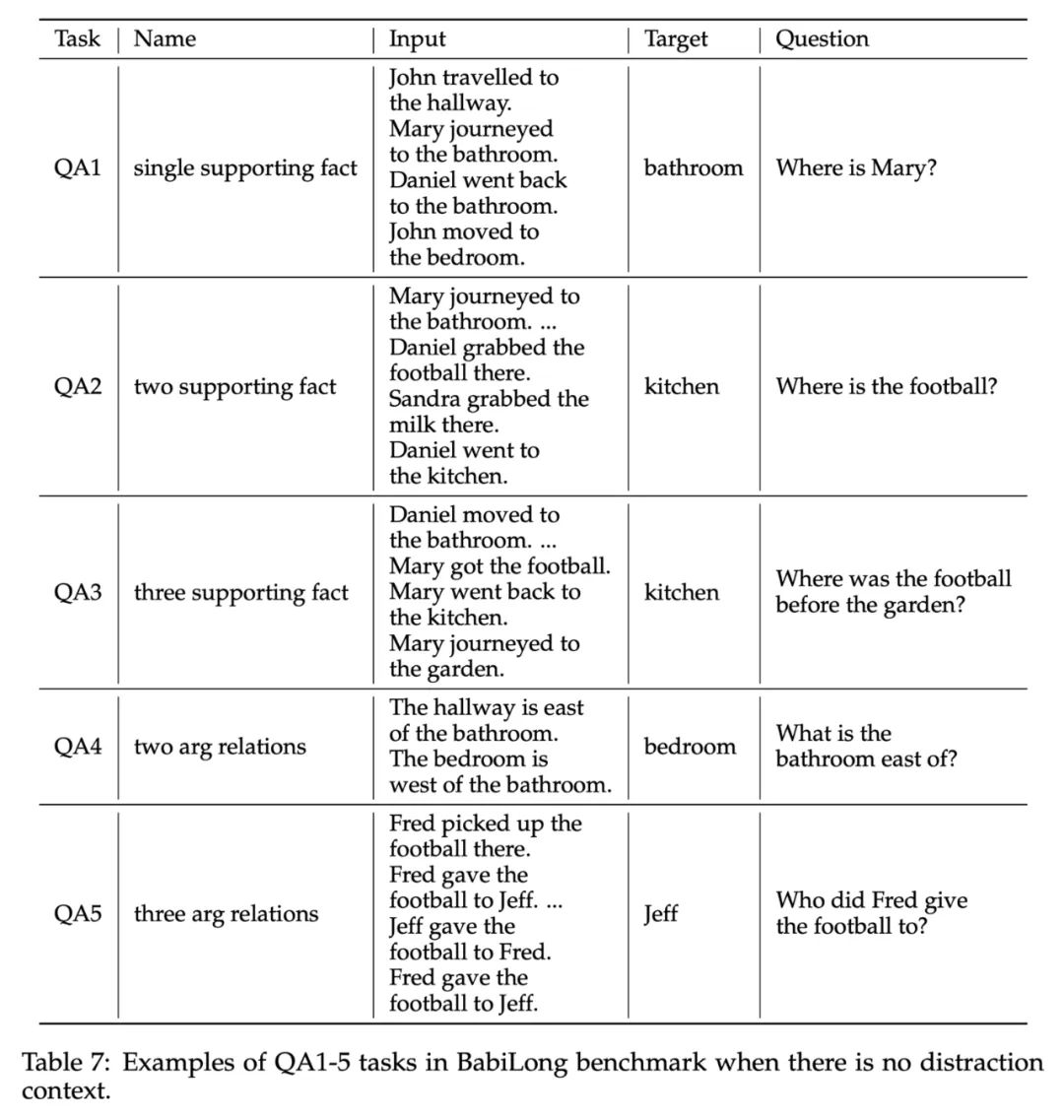
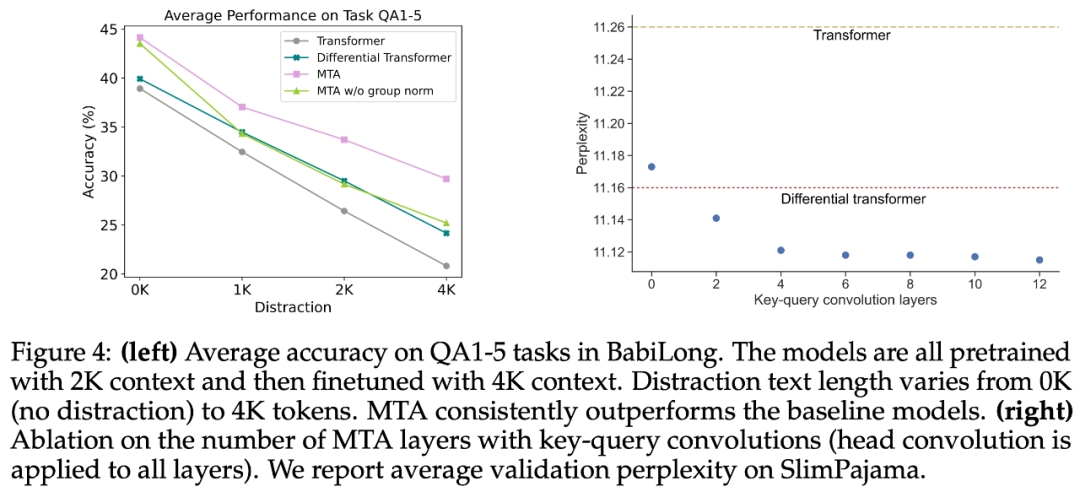
图 4(左)展示了平均准确率,附图 5 展示了每个任务的准确率。与其他模型相比,MTA 模型表现良好,尤其是当输入中有较多干扰文本(4K token)时。
更多实验结果请查看原论文。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com