上海交大&上海AI Lab提出NoRM算法,解决LoRA微调中幻觉噪声问题,通过去除冗余参数提升模型性能。实验表明,NoRM在多项任务上均优于现有方法。
原文标题:ICLR 2025 Spotlight | 参数高效微调新范式!上海交大联合上海AI Lab推出参数冗余微调算法
原文作者:机器之心
冷月清谈:
怜星夜思:
2、NoRM算法通过去除冗余参数来提升性能,那么在实际应用中,如何平衡参数效率和模型性能?是否存在一个“最佳冗余度”?
3、文章提到可以将NoRM的设计哲学迁移到强化学习中,具体可以如何操作?这样做有哪些潜在的优势和挑战?
原文内容

本文作者来自复旦大学、上海交通大学和上海人工智能实验室。一作江书洋为复旦大学和实验室联培的博二学生,目前是实验室见习研究员,师从上海交通大学人工智能学院王钰教授。本文通讯作者为王钰教授与张娅教授。
低秩适配器(LoRA)能够在有监督微调中以约 5% 的可训练参数实现全参数微调 90% 性能。然而,在 LoRA 训练中,可学习参数不仅注入了知识,也学习到了数据集中的幻觉噪声。因为这种特性的存在,大多数的 LoRA 参数都将可学习秩设置为一个较小的值(8 或者 16),通过减小知识学习程度来避免幻觉,而这也限制了 LoRA 的性能上限。
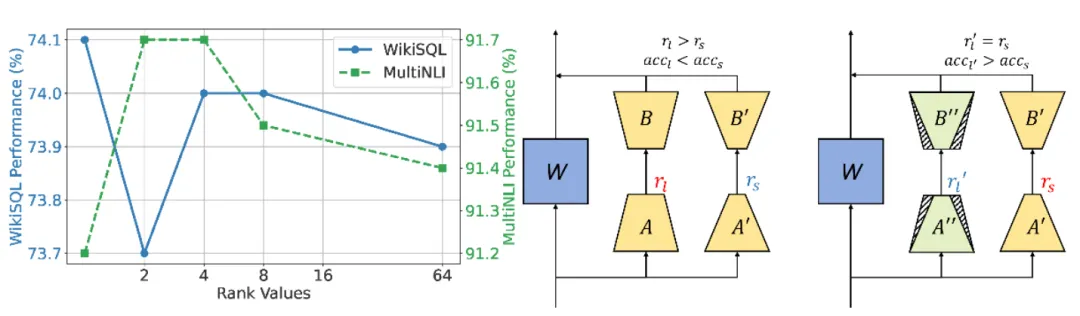
图 1 普通的 LoRA 微调随着秩的增大性能无法同步增加,而参数冗余微调能够以冗余参数提升性能。
为了解决这个问题,上海交通大学人工智能学院、复旦大学和上海人工智能实验室的团队提出了参数冗余微调范式以及一种创新性的微调算法:NoRM(Noisy Reduction with Reserved Majority)。参数冗余微调范式下,可以以普通的 LoRA 训练方式进行训练,并使用特定的方法在将 LoRA 参数合并回基模型参数前将冗余部分去除。NoRM 通过 SVD 将 LoRA 参数分解为主成分和冗余成分,并提出了 Sim-Search 方法,以子空间相似度动态决定主成分的数量。评估结果显示,NoRM 在指令微调、数学推理和代码生成的任务上一致性强于 LoRA 和其他参数冗余微调方法,实现无痛涨点。

-
论文链接:https://openreview.net/pdf?id=ZV7CLf0RHK
-
开源代码:https://github.com/pixas/NoRM
-
论文标题:FINE-TUNING WITH RESERVED MAJORITY FOR NOISE REDUCTION
研究动机
研究者首先在 Llama3-8B-Instruct 上进行预备实验,使用 MetaMathQA-395K 数据集对模型进行微调,并在 SVAMP 上进行测试。研究者通过三个方面探究微调过程中的冗余现象:(1)随机删除 10%~90% 的 LoRA 参数通道;(2)使用(1)中的方法,对 Transformer 中的不同层的 LoRA 参数进行随机删除;(3)使用(1)的方法,对 Transformer 中的不同模块的 LoRA 参数进行随机删除。实验结果发现,不仅随机删除 LoRA 参数能够提升下游模型的性能,不同层之间和模块之间删除 LoRA 参数对性能的影响呈现一定的规律。
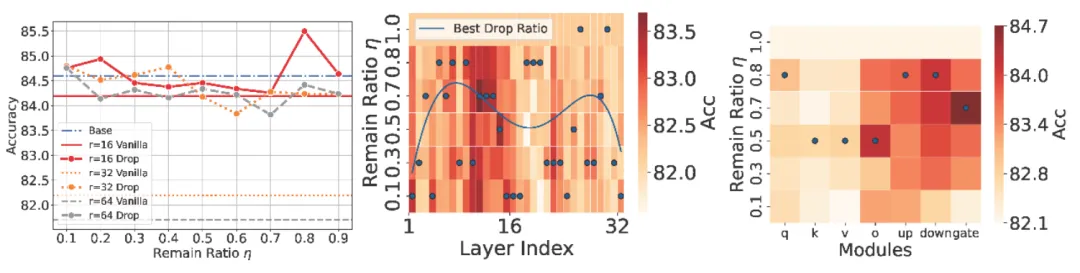
图 2 随机删除比例(a)的性能变化曲线和模型层索引(b)以及模块(c)上的性能分布。对达成最好性能的保留比例用深蓝色重点展示。
方法概述
在 LoRA 微调中,并不是直接更新参数 ,而是更新一个低秩表达: 。这个表达假设了参数的更新过程中,只在秩以内进行变化。在参数冗余微调中,为了高效减小参数冗余度,并能够根据不同模块和层之间的冗余不同去设计算法,研究者们首先考虑直接使用奇异值分解(SVD)对参数更新部分进行分解:
其中 为左右奇异矩阵, 是包含了 奇异值的对角矩阵。一种朴素的思想是保留最大的 个奇异值和响应的奇异向量:
然而,通过这种方法只能得到整体的更新参数 ,无法得到两个 LoRA 参数分别去除冗余后的分量。为了能够获得一个在预处理和参数存储上都更加高效的算法,研究者转向使用随机 SVD 来分别近似 和 。特别地,随机 SVD 以高斯分布初始化一个随机矩阵 :
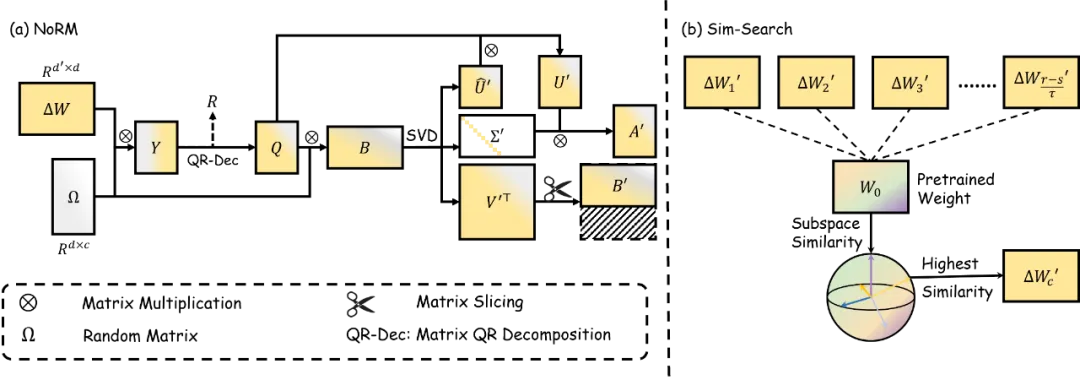
图 3 NoRM 的算法总览。其使用随机奇异值分解来提取 delta 参数的主成分,并使用(b)Sim-Search 基于裁剪后的 delta 权重和预训练权重间的子空间相似度决定拥有最小幻觉成分的 c 个通道。
接着,计算 的主要列子空间: 来近似特征空间。在此之后,通过对 的QR分解 得到 的正交基的近似 。基于此正交基,可以在 的低维空间上得到delta权重的投影 :
那么在这个小矩阵 上执行标准SVD就可以得到:
其中 ,然后将 转化回去来近似奇异向量: 。基于上述计算量,可以重构近似处理后的低秩参数:
确定好整个计算流程后,研究者们通过一种Sim-Search的方法来确定要保留的分量。这种方法通过预先设置好的两个搜索超参数,搜索步数 和搜索步长 ,得到一组不同 下的低秩分量,以及所对应的delta权重 。研究者对每一个delta权重使用SVD计算主要的 个奇异矩阵:
并使用同样的公式对基模型的权重进行同样的分解得到 。通过提取 个 和 的左奇异向量来计算子空间相似度:
其中
实验结论
NoRM 通过在三种不同的基模型以及三个不同的微调任务上进行实验,展现出强大的性能。
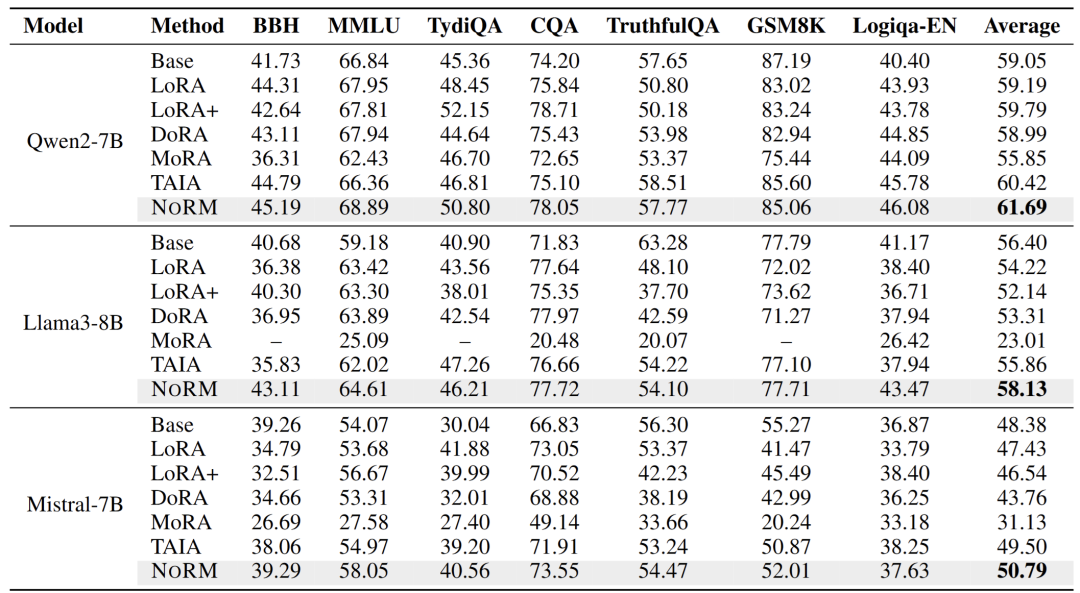
实验 1:指令微调实验
该任务主要测试,对 Instruct 模型进行微调后,如何保证多任务间的泛化性。通过和不同的 PEFT 基线进行比较,NoRM 在所有基模型上相比于最好的 PEFT 方法有着约 5 个点的提升。和之前最强的冗余微调方法 TAIA 相比,也有着 1~3 个点的提升,展现了 NoRM 强大的冗余去除能力。
实验 2:专域微调实验
该任务主要测试通过 NoRM 去除了冗余成分后,是否会对下游知识的学习造成影响。该实验选择 Llama3-8B 作为基模型,在数学推理和代码生成上进行测试。实验结果表明,由于 NoRM 可以使用更大的秩进行微调,在下游知识的吸收上,也优于之前的 PEFT 方法约 4 个点,领先 TAIA 约 3 个点。

实验 3:可学习参数对 NoRM 的影响
NoRM 通过对可微调参数中的冗余部分进行自适应去除降低微调幻觉。本实验中,通过改变秩的大小,NoRM 的性能随着可微调参数的增加而增加,而 LoRA 的性能并没有这样的趋势,这也映证了微调参数中存在大量冗余,这也是 LoRA 无法使用大秩提升性能的原因之一。

图 4 NoRM 可以从大秩中受益,但基础的 LoRA 在秩增大后反而降低性能。
实验 4:NoRM 的学忘比
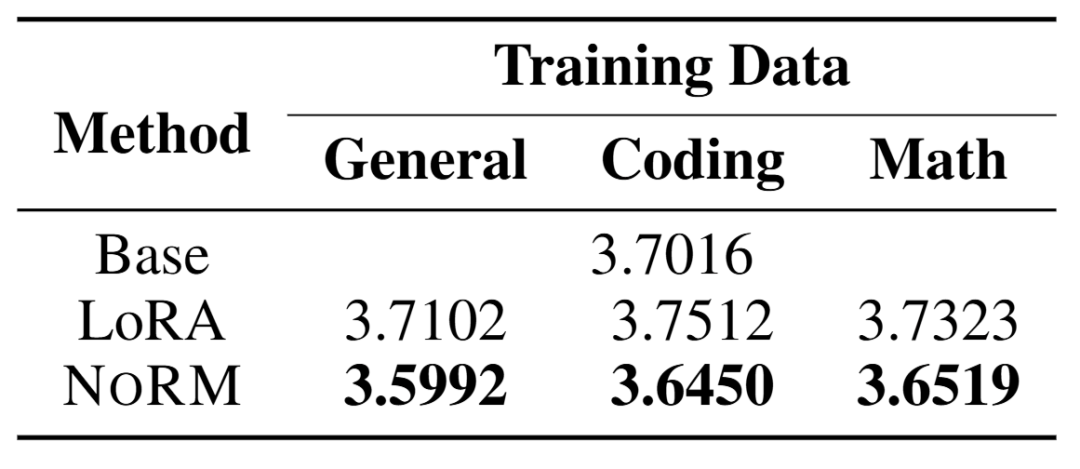
通过对 LoRA 和 NoRM 在记住预训练知识的能力上进行比较,可以证实 NoRM 的设计哲学在于尽可能保留下游语料中和预训练参数中重叠最大的部分。通过测试在 WikiText-103 测试集上的损失函数值,可以看到 NoRM 的损失降低,而 LoRA 相比于基模型都有着一定程度上的升高。
结论和展望
这篇工作发现了有趣的高效参数冗余现象,并提出了 NoRM 算法来智能识别并保留最有价值的参数,同时去除有着负面作用的冗余参数,给微调参数做了一次 “减重手术”。在目前强化学习微调盛行的当下,可以将 NoRM 的设计哲学迁移到强化学习中,通过去除数据中会带来噪声的成分,提升模型下游任务的适配性和多任务之间的泛化性。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com