《大模型应用开发极简入门》第二版重磅升级,快速掌握GPT-4、RAG、Agent,新增DeepSeek案例!
原文标题:热销 2 万册!大模型应用开发入门书全新升级
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、书中提到了 DeepSeek 应用开发案例,那么 DeepSeek 和 OpenAI 的 API 在使用上有什么异同?对于开发者来说,选择哪个平台更好?
3、书中提到了可以通过LLM教你Python,那么对于零基础的同学,完全通过LLM学习编程是否可行?有哪些需要注意的地方?
原文内容
今天给大家推荐的这本书是大模型领域最受读者喜爱的 LLM 应用开发图书,第 1 版销量 2 万册。读者对这本书的喜爱源于其简单、示例多、图文并茂,知识点全。你可以认为它是一份 LLM 应用开发的 MVP(最小可用知识)。
如今,大语言模型已经不再是一个单一的产品,而是一个完整的技术生态。无论是 GPT-4、DeepSeek、Claude,还是未来的 GPT-5 还是 DeepSeek 新版本的发布,它们的核心架构、API 交互方式、提示工程、RAG(检索增强生成)、LangChain 等技术框架,都有很强的共性。
如果你已经掌握了如何调用 GPT-4 API,如何高效设计提示词,如何结合外部知识库增强大模型的能力,如何使用 LangChain 构建复杂的 AI 应用,那么不管未来出现什么新模型,你都可以快速适应,而不是从零开始。
从 2023 年到 2024 年,我们见证了 AI 领域的一次次突破,但有一件事始终没有改变:模型会不断升级,但它们的应用开发逻辑不会被颠覆。真正的技术壁垒,不是会用某个具体模型,而是能将 LLM 技术转化为真正落地的应用。
如果你对大模型应用开发感兴趣,却不知道如何入门,那么 Olivier Caelen 和 Marie-Alice Blete 合著的《大模型应用开发极简入门:基于GPT-4和ChatGPT(第2版)》将是你的最佳入门指南。
许多开发者初识大语言模型时,往往只停留在“输入提示词,获取结果”的阶段,但真正的 LLM 开发远不止于此。这本书不仅帮你掌握 API 调用,还通过清晰的图解与代码示例,深入解析 GPT-4 的架构演进,揭示模型如何生成文本、理解上下文的底层机制。理解这些核心原理,才能有效规避幻觉(hallucination)、优化响应质量,甚至为特定业务场景定制模型,从而真正发挥大模型的潜力。
附赠本书思维导图,可以提前概览新版内容:
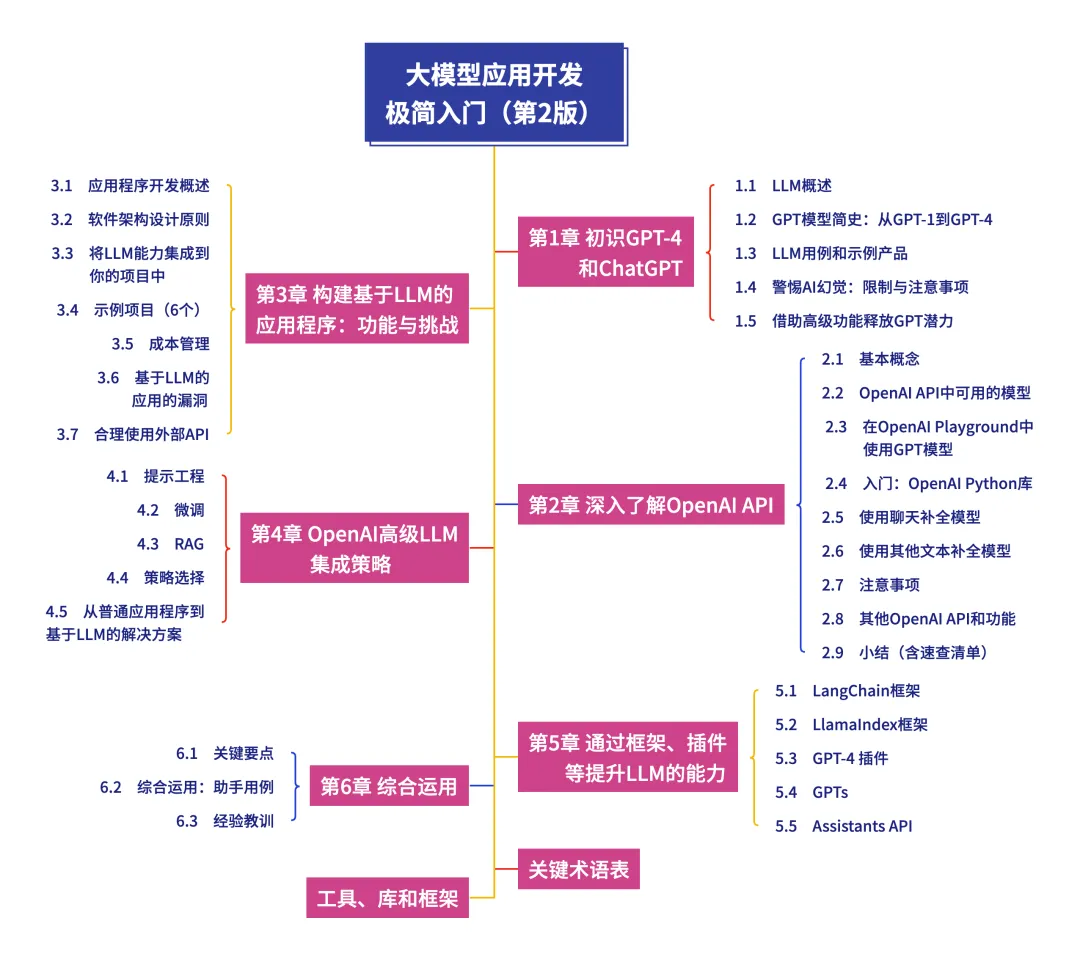
任何对 LLM 应用开发感兴趣的读者,都可以来参考这本书来入门。书中提供了一份清晰、全面的“最小可用知识”,带领你快速了解 LLM 的工作原理,并在此基础上使用流行的编程语言 Python 构建 LLM 应用。
-
全面升级,紧跟大模型最新趋势:新增自第 1 版以来 GPT-4 的核心更新、API 应用解析,及 RAG、Agent 等读者最为关注的技术点,让你掌握 LLM 最新核心发展。
-
从理论到实战:作者介绍了 LLM 开发的三大范式:提示工程 + 微调 + RAG,并着重解析 GPT-4 的核心机制。从 API 调用到构建智能应用,确保你学得会、用得上。
-
6大案例,快速上手:本书还提供了 6 个高质量案例,涵盖多个应用场景:
✅ YouTube 视频摘要——快速提炼长视频核心信息
✅ 游戏专家——训练 AI 成为游戏助手
✅ 个人助理——构建专属智能助手
✅ 文档组织——高效管理和检索文本资料
✅ 情感分析——分析用户反馈,挖掘情绪倾向
-
示例丰富,简单易学:书中包含大量可直接运行的 Python 代码示例,并配套 GitHub 开源代码库,所有示例均基于真实业务场景,覆盖开发者最常见的需求,帮助你快速理解并应用到自己的项目中。
-
覆盖 LLM 生态热门平台与框架:OpenAI、LangChain、LlamaIndex、DeepSeek、Dify。
-
随书附赠:要说这本书英文版有啥遗憾,那么可能是不涵盖大家非常关注的 DeepSeek 应用开发案例,现在中文版全世界独家,也弥补了这个遗憾,案例基于大家超级热爱的 Dify,闭源最强 OpenAI + 开源双雄 DeepSeek × Dify,教你一步步教你部署私有化 AI 助手!
作者 Olivier Caelen 不仅是布鲁塞尔大学机器学习课程讲师,更在世界级支付公司Worldline主导 AI 研发,具有“教育+产业”的双重背景,让本书既规避了纯理论书的空洞,又超越了碎片化教程的局限。而 Marie-Alice Blete 在 AI 系统延迟与性能瓶颈领域的深耕,则为书中每一个案例都注入了工业级落地的可靠性。
译者何文斯:知名大模型创业公司 Dify 产品经理、公众号“何文斯”作者,致力于研究大模型中间件技术和AI应用工程化的实际落地。业余时间撰写大模型相关技术的科普文章,期待共同见证通用人工智能的实现。
-
希望将 LLM 能力无缝嵌入现有系统的 Python 全栈开发者
-
试图用 AI 改造内容生成、客服、数据分析等场景的创业者
-
渴望从“调参工程师”进阶为“AI应用架构师”的开发者
业内专家书评
本书邀请业内一线大模型开发者、创业者试读了预览版,各位业内专家提前审阅,给出了专家书评。此外,各位还在书中分享了他们的一线 LLM 冲浪经验,及学习 LLM 相关技能的感悟,非常宝贵的资源。
在 AI 技术红利窗口期缩短的当下,等待意味着落后。《大模型应用开发极简入门:基于 GPT-4 和 ChatGPT(第2版)》提供的不仅是简单的代码片段,更是一套完整的“认知-工具-实践”体系。
还等什么?立即行动,开启你的 LLM 开发革命!👇

最后再啰嗦一句!要是觉得独自摸索大模型太费劲,想找搭子一起交流,扫码进群就对啦!群里能畅聊图书内容、技术难题,还能抢先读新书,紧跟领域新进展,更有专属福利。别等了,快进群,咱们抱团学习,一起进步!
