贾佳亚团队提出MoTCoder,用模块化思维提升AI代码生成能力,在复杂编程任务中准确率刷新SOTA,代码可维护性更强。
原文标题:让AI替码农卷复杂任务,贾佳亚团队提出MoTCoder,准确率刷新SOTA
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到MoTCoder可以自动检测并修正代码错误,那么这种自我反思机制是如何实现的?如果出现模型无法自我修正的错误,应该如何处理?
3、MoTCoder在解决不同难度问题时会采用不同的模块化策略。那么,如何准确判断问题的复杂度,并选择合适的模块化程度?是否存在一种通用的复杂度评估方法?
原文内容

论文一作李靖瑶,香港中文大学博士生(DV Lab),师从贾佳亚教授。主要研究方向是大语言模型,包括模型预训练、后训练、推理优化。作者陈鹏光、夏彬等均为 DV Lab 成员。
大模型写代码早就是基操了,但让它写算法竞赛题或企业级系统代码,就像让只会煮泡面的人去做满汉全席 —— 生成的代码要么是 “铁板一块” 毫无章法,要么是 “一锅乱炖” 难以维护。
如何让大模型像工程师一样思考,用模块化思维拆解复杂问题?
近日,贾佳亚团队提出 MoTCoder(Module-of-Thought Coder),通过创新的模块化思维指令微调(MoT Instruction Tuning),显著提升了模型在复杂编程任务中的准确率与可维护性。实验显示,在 APPS 和 CodeContests 等权威编程基准上,MoTCoder 的 pass@1 准确率直接刷新记录,甚至超越 SOTA 6%,让大模型在 “疯狂打码” 时更接近「人类智慧」。

-
论文标题:MoTCoder: Elevating Large Language Models with Modular of Thought for Challenging Programming Tasks
-
论文链接:https://arxiv.org/abs/2312.15960
目前,团队已发出程序员快乐包 —— 代码、模型与数据集通通开源,欢迎在线体验:
-
代码库:https://github.com/dvlab-research/MoTCoder
-
32B 模型:https://huggingface.co/JingyaoLi/MoTCoder-32B-V1.5
-
7B 模型:https://huggingface.co/JingyaoLi/MoTCoder-7B-v1.5
-
350K 训练数据集:https://huggingface.co/datasets/JingyaoLi/MoT-Code-350K
复杂编程的解耦神器
当前主流代码生成模型(如 Qwen2.5-Coder)生成的代码往往就是这种单块式的结构,虽然在简单任务上表现良好,但面对复杂场景时难掩缺陷:
-
拆解复杂任务:不存在的!让它写个分布式系统,输出代码堪比灾难现场;
-
维护成本爆炸:生成的代码注释比程序员(bu shi)头发还少,debug 时被同事怀疑是祖传咒语。
试想象一下,你让模型写个自动驾驶算法,结果它吐出几千行密密麻麻的代码,像一团乱麻根本无从下手。这就是传统模型的单块式代码 —— 把所有逻辑塞进一个函数,不讲章法地一锅乱炖。

图 1a: 传统模型生成的单块式代码
而 MoTCoder 则能 “遇招拆招”,把复杂任务拆成 “输入解析”、“核心算法”、“异常处理” 等标准化模块,像乐高积木般严丝合缝组装,每个模块还自带 “说明书”,强迫症患者看完都直呼舒适!

图 1b: MoTCoder 生成的模块化代码

图 2:MoTCoder 的两阶段模块化设计流程
MoTCoder 的三大核心突破
(1)性能开挂:复杂任务准确率刷新 SOTA
得益于模块化思维对复杂逻辑的拆解能力,在 APPS 数据集上,MoTCoder-32B 的 pass@1 超越同等规模模型 5.8%;在 CodeContests 数据集上,MoTCoder-32B 更是直接上演「屠榜」戏码,超越 SOTA 5.9%!

图 3:MoTCoder 的战斗力曲线
(2)大模型代码质检员
MoTCoder 通过多轮自我反思机制,能自动检测并修正代码错误。实验显示:
-
未修正状态下,MoTCoder 可达到 SOTA 模型 5 轮人工修正后的效果
-
开启自检后,准确率更进一步提升 4%
(3)代码质量全面碾压传统模型
通过专业的代码质量分析工具 Radon 对 APPS 和 CodeContests 数据集上的生成代码进行评估,MoTCoder 在所有难度级别中都保持了明显更高的可维护性指数(Maintainability Index)。
实验数据显示,相比普通微调模型和基线模型,MoTCoder 生成的代码具有更低的复杂度、更精简的代码量和更合理的注释比例。
程序员狂喜:简直好用哭了!
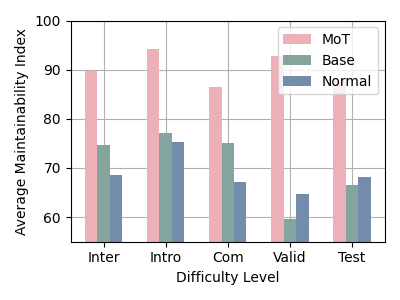
图 4:MoTCoder 生成的代码具有更优的可维护性特征
智能调度:简单题极简模式,难题乐高模式
这种优势源于 MoTCoder 的模块化训练方法,使生成的代码结构更清晰、逻辑更简明。在时间和内存消耗的对比中(图 5),MoTCoder 生成的代码展现出显著优势。虽然其运行时间与普通微调模型相当,但在内存占用上始终低于基准模型。这得益于 MoTCoder 对全局变量和函数局部变量的智能区分,能够及时释放未使用的内存资源。

图 5:MoTCoder 生成的代码具有更低的内存消耗

图 6:不同难度的代码函数数量与准确率关系
贾佳亚团队在开发过程中发现了一个有趣的现象(图 6):
- 入门题:函数数量增加,准确率反而下降(简单问题无需拆解)
- 面试题:函数数量变化对准确率影响较小(保持稳定)
- 竞赛题:函数数量与准确率呈正相关(复杂问题必须模块化)
MoTCoder 自带智能调度系统,问题复杂度决定了其模块化策略:面对两行代码就能搞定的题目,启动极简模式;而遭遇代码量堪比毕业论文的变态需求,则秒切乐高模式。而这种思维方式已达到人类工程师的解题路径。
这种特性也使得 MoTCoder 可覆盖从算法竞赛到工业级开发多个落地场景:
-
算法竞赛:秒解 Codeforces/LeetCode 难题,生成带注释的标准答案;
-
大型系统设计:自动生成微服务架构代码,接口清晰、模块解耦;
-
企业级应用开发:生成可长期维护性的代码库,降低技术债务累积速度。
MoTCoder 让代码生成从 “功能实现” 跃迁至 “工程实践”,或许是时候重新定义智能编程了 —— 不仅要生成代码,更要生成好代码。贾佳亚团队表示,将继续深化智能编程的研究,并探索其在更多工业界场景的深度应用。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com