视觉自监督学习(SSL)新突破!Yann LeCun等研究表明,大规模视觉SSL在VQA任务中可媲美CLIP,逆转固有认知。
原文标题:视觉SSL终于追上了CLIP!Yann LeCun、谢赛宁等新作,逆转VQA任务固有认知
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到增加包含文本的图像训练比例可以提高OCR和图表性能,这是否意味着我们可以通过调整训练数据集的构成来有针对性地提升模型在特定领域的表现?
3、研究中发现,更大的模型和更多的数据能够提升视觉SSL的性能,但增加到一定程度后提升效果会减缓。那么,在实际应用中,我们应该如何平衡模型大小、数据规模和训练成本,才能获得最佳的性价比?
原文内容
机器之心报道
编辑:蛋酱、杜伟
扩展无语言的视觉表征学习。
在视觉问题解答(VQA)等多模态环境中,当前视觉自监督学习(SSL)的表现还比不上语言图像预训练(CLIP)。这种差距通常归因于语言监督引入的语义,尽管视觉 SSL 模型和 CLIP 模型通常在不同的数据上进行训练。
在最近的一项研究中,Yann LeCun、谢赛宁等研究者探讨了一个基本问题: 语言监督对于多模态建模的视觉表征预训练是否必要?

-
论文标题:Scaling Language-Free Visual Representation Learning
-
论文链接:https://arxiv.org/pdf/2504.01017
-
项目地址:https://davidfan.io/webssl/
「我们的目的不是要取代语言监督方法,而是要了解视觉自监督在多模态应用中的内在能力和局限性。为了进行公平的比较,我们在与最先进的 CLIP 模型相同的数十亿规模的网络数据(特别是 MetaCLIP 数据集)上训练 SSL 模型。在比较视觉 SSL 和 CLIP 时,这种方法可以控制数据的分布差异。」研究者表示。
论文共同一作 David Fan 表示,「视觉 SSL 终于可以在 VQA 任务上与 CLIP 匹敌了,即使在 OCR & Chart VQA 上也非常具有竞争力。我们的全新 Web-SSL 模型系列证明了这一点,并且仅仅基于网络图像训练,没有进行任何语言监督。」
在评估方面,研究者主要使用视觉问题解答(VQA)作为框架,大规模评估 SSL 模型的各种能力。具体来说,采用了 Cambrian-1 中提出的评估套件,跨越 4 个不同 VQA 类别的 16 项任务的性能: 通用、知识、OCR & 图表以及 Vision-Centric。
然后,他们使用上述设置训练了 Web-SSL,这是一个视觉 SSL 模型系列,参数范围从 10 亿到 70 亿不等,以便与 CLIP 进行直接和可控的比较。
通过实证研究,研究者提出了一些见解:
-
视觉 SSL 可以在广泛的 VQA 任务中,甚至在 OCR & 图表理解等语言相关任务中,匹配甚至超越语言监督的视觉预训练方法(图 3);
-
视觉 SSL 在模型容量(图 3)和数据(图 4)方面都有很好的扩展性,这表明 SSL 还有巨大的潜力有待挖掘;
-
视觉 SSL 可以在分类和分割方面保持传统视觉性能的竞争力,同时在 VQA 方面也有所改进(图 7);
-
对包含文本的图像进行更高比例的训练对于提高 OCR 和图表性能尤为有效(问题 4)。探索数据构成是一个很有前景的方向。

随后,研究者介绍了本文的实验设置,它通过以下方式扩展了之前的 SSL 工作:
(1)将数据集规模扩展到十亿级图像(第 2.1 节);
(2)将模型规模扩展到 1B 参数以上(第 2.2 节);
(3)除了 ImageNet-1k 和 ADE20k 等经典视觉基准之外,还使用开放式 VQA 任务(第 2.3 节)评估视觉模型。
扩展 Visual SSL
研究者也探讨了视觉 SSL 模型在模型和数据大小方面的扩展行为,这是仅对 MC-2B 图像进行训练的结果。这一部分重点讨论 DINOv2 作为视觉 SSL 方法,下一部分会重点讨论 MAE。
-
扩展模型大小:研究者将模型大小从 1B 增加到 7B,同时将训练数据固定为 20 亿张 MC2B 图像。他们对每种方法都使用了现成的训练代码和配方,为了控制混杂变量,没有因模型规模不同而改变配方。
-
扩展所见样本:研究者将重点转移到对固定模型大小的总数据进行缩放,并分析当训练过程中看到的图像数量从 10 亿增加到 80 亿时,性能是如何变化的。
扩展模型大小
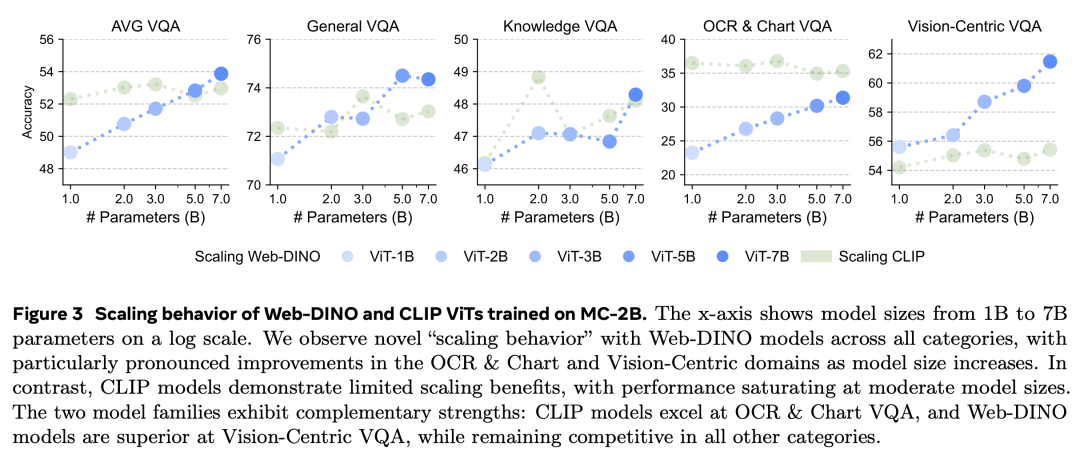
研究者使用来自 MC-2B 的 20 亿张 224×224 分辨率的未标记图像,并且没有进行高分辨率适应,对 DINOv2 ViT 模型进行了预训练,参数范围从 1B 到 7B,以确保与 CLIP 的公平比较。他们使用 VQA 来评估每个模型,结果如下图 3 所示,包含了整体性能趋势和特定类别性能。
研究者表示,这是仅使用视觉自监督训练的视觉 encoder 第一次在 VQA 上取得与语言监督 encoder 相当的性能,即使是传统上被认为高度依赖文本的 OCR 和 Chart 类别也是如此。
关于性能变化趋势,图 3 还比较了模型容量增加时的性能趋势。WebDINO’s Average、DINOOCR & Chart 和 Vision-Centric VQA 的性能随着模型大小的增加几乎呈现对数线性提升,而通用(General)和知识(Knowledge)的提升程度较小。
相比之下,CLIP 在所有 VQA 类别中的表现在 3B 参数后基本饱和。这表明了,虽然较小规模的 CLIP 模型可以更高效地利用数据,但较大规模的 CLIP 模型基本丧失了这一优势。
Web-DINO 模型增加带来的持续性能提升表明了,视觉 SSL 会从更大规模的模型中受益,并且继续将视觉 SSL 扩展到 7B 以上是一个有潜力的方向。
关于特定类别的性能,随着模型大小的增加,DINO 在 Vision-Centric VQA 上的表现越来越优于 CLIP,在 OCR & Chart 和 Average VQA 上与 CLIP 的差距也大大缩小。
扩展所见样本
研究者探究了训练 Web-DINO ViT-7B 过程中增加所见样本的数量对性能变化有哪些影响,并将来自 MC-2B 中的图像数量从 1B 增加到 8B。
随着所见样本的增加,General 和 Knowledge VQA 的性能逐渐提升,并分别在 4B 和 2B 样本时达到饱和。Vision-Centric VQA 的性能在样本从 1B 增加到 2B 过程中急剧提升,并在 2B 以上达到饱和。相比之下,OCR & Chart 是唯一一个随着所见样本增加而持续改进的类别。
这表明了,随着模型所见样本的增加,它会学习到一种越来越适合文本任务的表征,而其他能力不会明显下降。
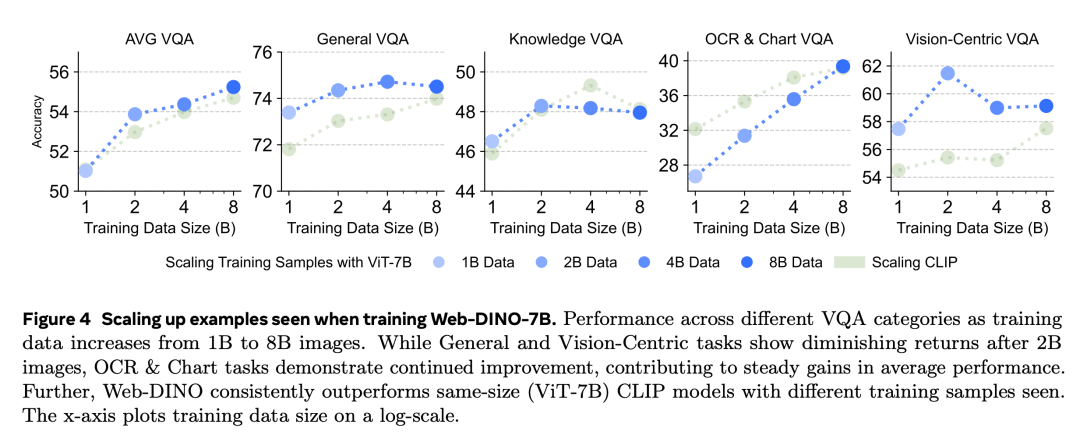
总的来说,上图 3 和图 4 的结果表明,随着模型大小和样本的增加,视觉 SSL 学习到的特征对于 VQA 越来越有效,尤其是在 OCR & Chart 类别。并且,基于 CLIP 的模型相较于视觉 SSL 没有绝对的优势。
Web-SSL 模型系列
研究者使用 VQA 和经典视觉基准分析了整体性能最佳的视觉编码器。表 3 展示了视觉编码器在 VQA 和经典视觉任务方面与近期现成的视觉编码器相比所取得的最佳结果。
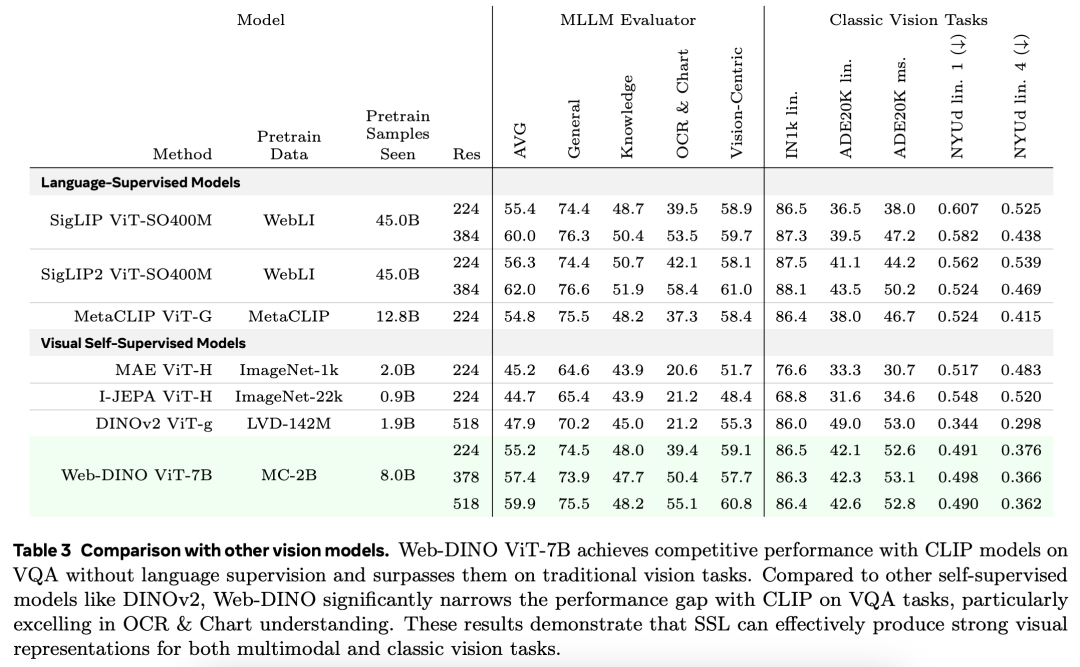
在 VQA 和传统视觉任务中,Web-DINO 的表现都优于现成的 MetaCLIP。在 VQA 上,Web-DINO 的性能甚至可以与 SigLIP 和 SigLIP2 相媲美,尽管它看到的数据少了 5 倍,而且没有语言监督。总体而言,Web-DINO 在传统视觉基准测试中的表现优于所有现成的语言监督 CLIP 模型。
在所有 VQA 类别中,Web-DINO 也优于现成的视觉 SSL 方法,包括 DINOv2。在传统的视觉基准测试中,Web-DINO 也具有很强的竞争力。
从 224 分辨率到 378 分辨率再到 518 分辨率,Web-DINO 在平均 VQA 上稳步提升,在 OCR 和图表性能方面也有显著提高。传统视觉性能随着分辨率的提高而略有提高。在 384 分辨率下,Web-DINO 落后于 SigLIP。在 518 分辨率下,Web-DINO 在很大程度上弥补了这一差距。结果表明,Web-DINO 可从进一步提高高分辨率适应性中获益。
更多研究细节,可参考原论文。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com