MTGS方法通过融合多轨迹数据,解决了自动驾驶场景重建中视角局限和动态失真问题,实现厘米级细节还原和实时渲染。
原文标题:细节厘米级还原、实时渲染,MTGS方法突破自动驾驶场景重建瓶颈
原文作者:机器之心
冷月清谈:
怜星夜思:
2、MTGS方法中,利用激光雷达点云颜色作为“锚点”进行外观对齐,这个思路有什么巧妙之处?其他方法难以达到同样效果的原因是什么?
3、MTGS方法在自动驾驶仿真领域的应用前景如何?除了文章中提到的优势,你认为它还有哪些潜在的应用价值?
原文内容

在自动驾驶领域,高精度仿真系统扮演着 “虚拟练兵场” 的角色。工程师需要在数字世界中模拟暴雨、拥堵、突发事故等极端场景,反复验证算法的可靠性。
然而,传统仿真技术往往面临两大难题:首先是视角局限,依赖单一轨迹数据,如一条固定路线的摄像头录像,重建的场景只能在有限视角内逼真,无法支持车辆 “自由探索”。其次是动态失真,同一路口在不同时间可能停满车辆或空无一人,这些变化使得生成画面脱离现实。
为解决这一问题,上海创智学院联合香港大学等机构联合提出 MTGS (Multi-Traversal Gaussian Splatting)方法,通过多轨迹数据融合,构建既能还原真实道路细节又能动态响应环境变化的超高精度仿真场景。

日常通勤中,车辆往往会以不同的轨迹反复经过同一路段;而用于采集驾驶数据的车队也往往会在同一街区多次遍历,每辆车在不同时间从不同的角度记录了当前街区的信息。因此,使用多轨迹数据能获取到更多周围环境的信息。然而,实验发现,简单地堆叠数据并不能带来重建效果的提升,反而可能损伤单轨迹下重建的场景模型,原因之一是这些数据在天气、光照上有较大差异,无法很好地对齐。而 MTGS 的核心创新,正是将这些碎片化的 “数字拼图” 智能整合,使不同轨迹采集到的几何信息能互相补足,重建出几何信息更精准的驾驶场景。

-
arXiv 链接:https://arxiv.org/abs/2503.12552
-
代码、checkpoint 等即将开源
基于多个轨迹的场景异质图
MTGS 将同一个场景中的元素集合在一个异质图中,并针对不同场景元素的特点分成三类节点,静态节点、外观节点、瞬态节点。这种 “分而治之” 的设计,使得 MTGS 既能还原道路的原有特征,又能灵活地呈现瞬息万变的车流与环境。
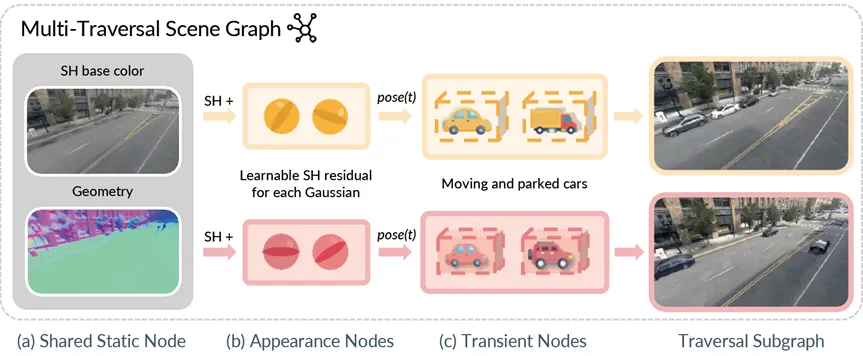
静态节点 - 所有轨迹共享的静态背景,如沥青路面、交通标志。
外观节点 - 通过球谐函数系数调整光照、阴影,适配多轨迹对应不同时段的天气变化和光照差异。
瞬态节点 - 各次轨迹独有的移动物体,如穿梭的车辆、临时停靠的快递车。
其中,静态节点和外观节点共同决定表征静态背景的高斯球,前者提供高斯球的位置、旋转四元数、尺寸、透明度和球谐函数的首个参数,后者则决定球谐函数的其他参数。这一设计源自球谐函数自身的特性:第一个球谐函数 Y_0,0 具备旋转不变性,可用于表征物体的本色或底色;其他球谐函数则会随着观察视角的变化而有所变化,更适合表征物体在不同轨迹不同视角上的色彩变化,如阴影、反光等细节。
同一轨迹中的外观对齐
除了多轨迹间的光照差异,同一轨迹内部也存在外观不对齐的情况,如部分相机过度曝光、不同相机间的色调差异。MTGS 创新性地利用激光雷达点云颜色作为 “锚点”,将同一空间点在同一时刻不同相机中的颜色对齐,并为每个相机学习独立的仿射变换,确保不同时刻采集的图片色调统一。
此外,为避免模型产生 “浮空碎片” 等失真现象,MTGS 还引入多重约束:(1)用激光雷达点云矫正三维形状,确保路沿、护栏等结构精确对齐;(2)使用 UniDepth 对图像进行深度估计,使用估计深度计算得到每个像素的法向量方向,从而通过相邻像素的法向量约束,让曲面过渡更自然(如车顶弧度);(3)将移动物体的阴影从背景中分离,防止 “鬼影” 残留。这些技术让重建效果提升 46.3%,合成画面中的锯齿、重影等问题显著减少。
实测效果:数字与现实的 “像素级逼近”
在 nuPlan 大规模自动驾驶数据集上的测试显示,MTGS 在多项指标上刷新纪录。在画面质量方面,感知相似度(LPIPS)提升 23.5%。在几何精度方面,深度误差降低 46.3%,护栏间距、车道宽度等细节厘米级还原。在动态响应方面,支持每秒 60 帧的实时渲染,车流密度变化、行人突然穿行等场景流畅呈现。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com