厦门大学提出CPPO算法,通过剪枝和动态资源分配,在保证精度的前提下,强化学习速度最高提升8倍!
原文标题:在GSM8K上比GRPO快8倍!厦大提出CPPO,让强化学习快如闪电
原文作者:机器之心
冷月清谈:
怜星夜思:
2、CPPO中提出的动态完成结果分配策略,是如何解决GPU利用率不足的问题的?这种策略在单GPU训练场景下是否适用?
3、CPPO在GSM8K和MATH数据集上表现出色,但在AMC2023和AIME2024上的泛化能力如何?这种剪枝策略是否会影响模型在复杂问题上的推理能力?
原文内容
编辑:Panda
DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。
不同于 PPO(近端策略优化),GRPO 是直接根据组分数估计基线,因此消除了对 critic 模型的需求。但是,这又需要为每个问题都采样一组完成结果,进而让训练过程的计算成本较高。
之后,GRPO 会使用一个基于规则的奖励函数来计算每个完成结果的奖励,并计算每个完成结果的相对优势。
为了保证训练的稳定性,GRPO 还会计算一组完成结果的策略模型、参考模型和旧策略模型的预测概率之比作为策略目标函数的一部分,这又会进一步提升强化学习的训练开销。GRPO 巨大的训练开销限制了其训练效率和可扩展性。而在实践中,提高训练效率是非常重要的。
总结起来,GRPO 训练的计算成本主要源自其核心设计:为了进行组内比较,会为每个提示词生成一大组完成结果。此外,GRPO 的前向计算会以完成数量的 3 倍的尺度扩展。
那么,问题来了:在这个强化学习过程中,每个完成结果的贡献都一样吗?
近日,厦门大学纪荣嵘团队研究发现,每个完成结果的贡献与其相对优势有关。也就是说,每个完成结果对策略模型训练的贡献并不相等。如图 1 所示,完成结果的数量增大时,准确度提升并不非常显著,但训练时间却会迅速增长。
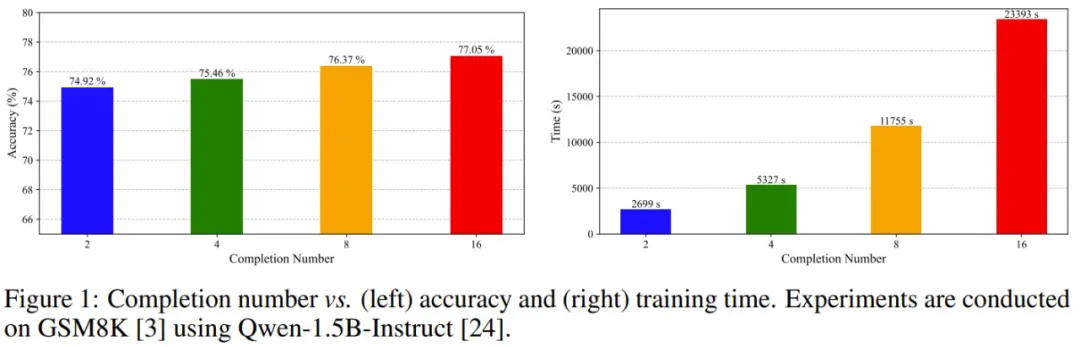
基于这一见解,他们发现可以通过对完成结果进行剪枝来加速 GRPO。然后,他们提出了一种加速版的 GRPO:CPPO(Completion Pruning Policy Optimization / 完成剪枝策略优化)。并且他们也已经开源发布了该算法的代码。

-
论文标题:CPPO: Accelerating the Training of Group Relative Policy Optimization-Based Reasoning Models
-
论文地址:https://arxiv.org/pdf/2503.22342
-
项目地址:https://github.com/lzhxmu/CPPO
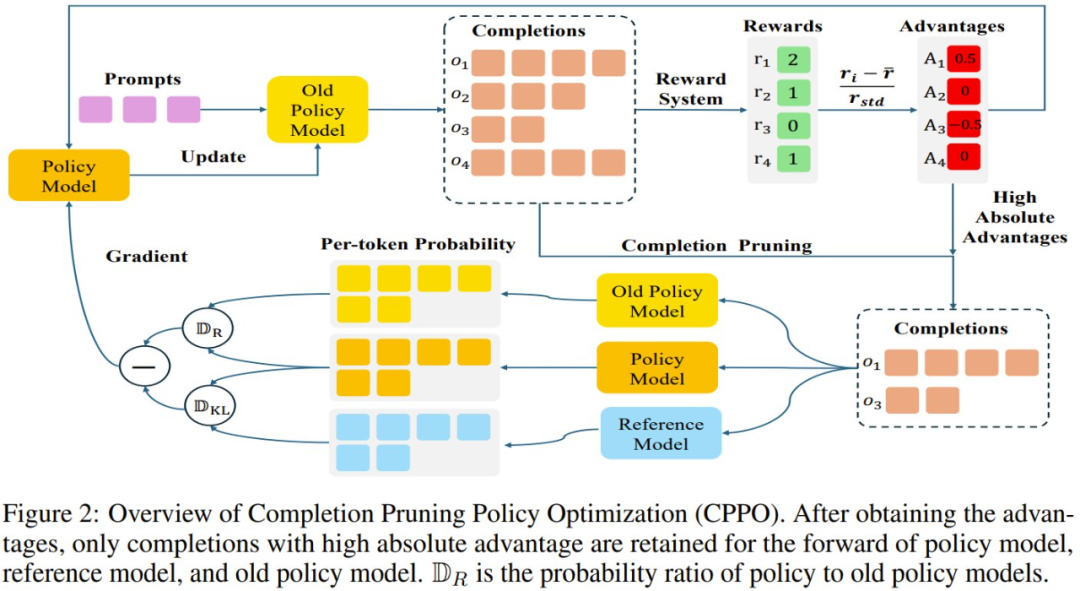
顾名思义,CPPO 会根据优势对完成结果进行剪枝,这样一来就可以提升强化学习过程的速度。
具体来说,一开始,策略模型会针对每个问题采样一组完成结果。随后,通过奖励函数计算每个完成结果的相对优势。然后,CPPO 会修剪掉绝对优势值较低的完成结果,仅保留绝对优势较高的完成结果来计算损失。此过程可大大减少训练所需的完成结果数量,从而加快训练过程。
此外,他们还观察到,由于完成剪枝会导致 GPU 资源利用率不足,从而导致资源浪费。为了解决这个问题,他们引入了一种动态完成结果分配策略。该策略会用新问题的完成结果填充每个设备,从而充分利用 GPU 资源并进一步提高训练效率。
实验证明,他们的方法是有效的。当使用 Qwen-2.5 系列模型时(包括 Qwen-2.5-1.5B-Instruct 和 Qwen-2.5-7B-Instruct),在保证了准确度相当的基础上,CPPO 在 GSM8K 基准上的速度比 GRPO 快 8.32 倍,在 MATH 基准上快 3.51 倍。
或者用网友的话来说,快如闪电!

CPPO:完成剪枝策略优化
要了解 CPPO,首先必须知道 GRPO,其公式如下:
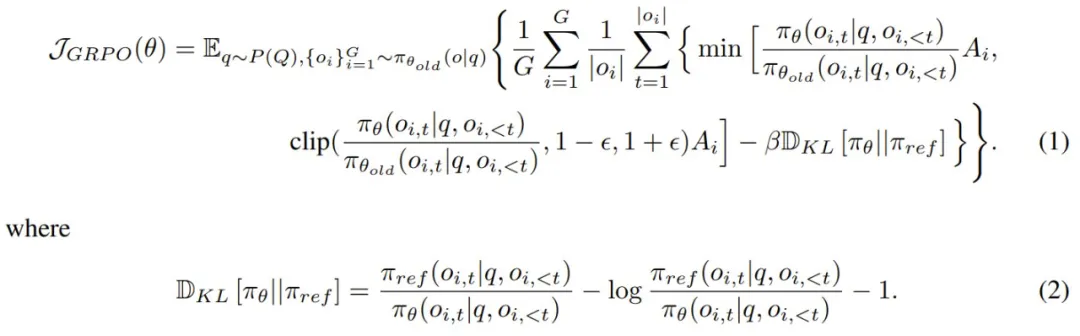
其中,q 是从数据集分布 P (Q) 中采样的问题,{o_1, o_2, ... , o_G} 是 G 个完成结果,π_θ 是策略模型,π_θ_old 是旧策略模型,π_θ_ref 是参考模型,ϵ 和 β 是超参数,A_i 是使用一组奖励 {r_1, r_2, ... , r_G} 计算的优势。
相比于 GRPO,CPPO 引入了一个选择性条件,该条件仅会包括表现出足够高优势的完成结果。CPPO 的目标公式如下:
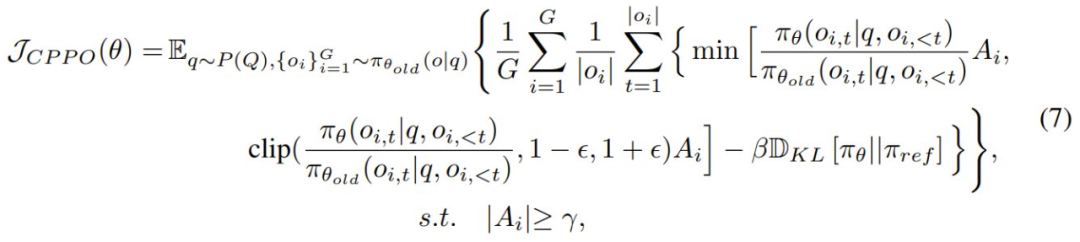
其中 γ 是一个预定义的阈值,用于确保在梯度更新中仅保留绝对优势高于 γ 的完成结果。需要注意的是,当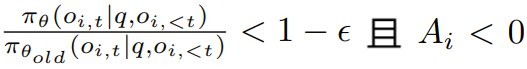 ,或者
,或者 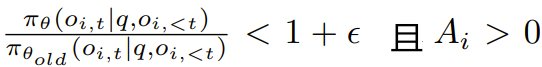 时,clip 函数会被激活。
时,clip 函数会被激活。
图 2 展示了 CPPO 的概况:
统一单/多 GPU 设置
在多 GPU 训练场景中,该团队观察到具有显著优势的完成结果的数量因设备而异。在这种情况下,整体训练效率会有设备处理最多完成结果数量的瓶颈 —— 这种现象称为「木桶效应(bucket effect)」。为了缓解这种情况,对于每台 GPU,该团队的选择是只保留每个问题具有最大绝对优势的 k 个完成结果,其中
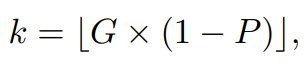
其中 P ∈ (0, 1] 表示剪枝率。在此策略下修改后的 CPPO 为:
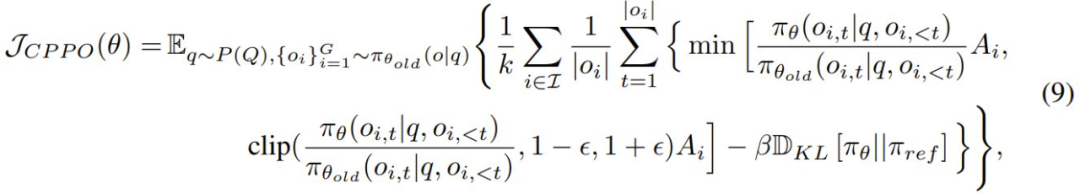
其中仅在具有最高绝对优势值的 k 个完成结果对应的索引集 I 上进行求和,即
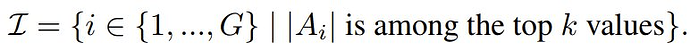
CPPO 算法的流程如下:
-
旧策略模型为每个问题采样一组完成结果;
-
奖励函数计算每个完成结果的奖励;
-
计算每个完成结果的相对优势;
-
CPPO 保留 k 个具有最高绝对优势的完成结果;
-
根据选定的完成结果更新策略模型。
CPPO 和 GRPO 之间的关键区别是:CPPO 不会将所有完成结果用于策略模型、参考模型和旧策略模型的前向计算。相反,通过仅保留具有高绝对优势的完成结果进行梯度更新,CPPO 可显著降低前向传递期间的计算开销,从而加速了训练过程。
通过动态完成结果分配进行并行处理
该团队还提出了一种新的动态完成结果分配策略,以进一步优化 CPPO 的训练效率。
由于 GPU 内存限制,传统方法(如 GRPO 采用的方法)面临固有的局限性。具体而言,单台设备每批最多可以处理 B 个问题,每个问题生成 G 个候选完成结果。剪枝操作之后,每台设备保留的完成结果总数减少到 B × k,进而导致 GPU 利用率不理想,并行计算能力未得到充分利用。
为了解决这种低效率问题,该团队的方法是将来自其他问题的剪枝后的完成结果动态分配到设备的处理管道中,如图 3 所示。
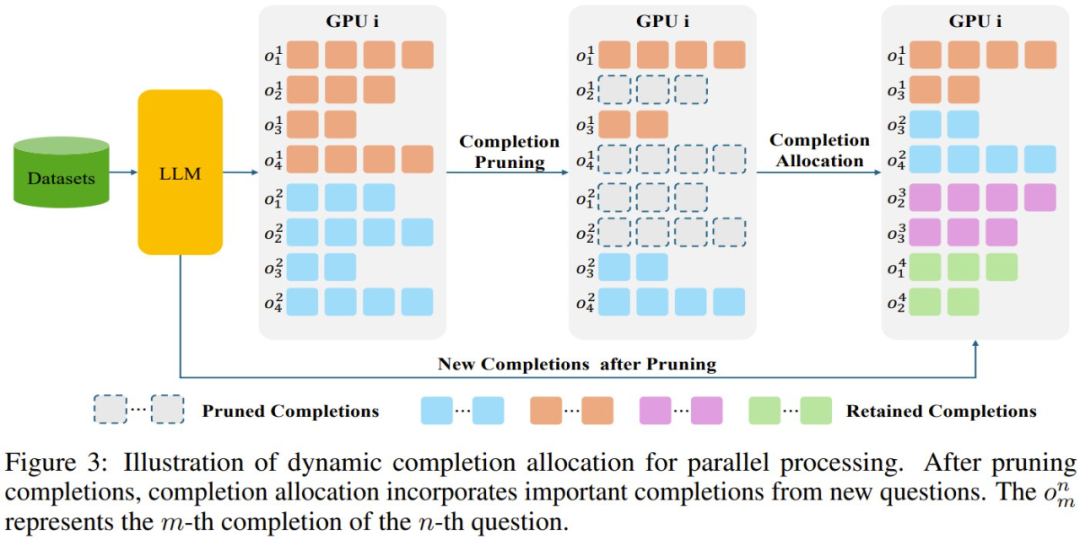
此策略通过不断用来自原始问题和新引入问题的高质量完成结果填充其内存,确保每个设备都能以满负荷运行。至关重要的是,所有新合并的完成结果都经过相同的严格剪枝过程,以保持一致性和相关性。
这种方法的好处有两个:
-
通过充分利用设备的并行计算潜力,它能最大化 GPU 利用率。
-
它能使每台设备每批处理更多的问题,从而减少实现收敛所需的总训练步骤数。
有这两大优势,CPPO 便可在保证训练质量的同时提高训练效率。
CPPO 的实验效果
使用 Qwen2.5-1.5B-Instruct 和 Qwen2.5-7B-Instruct 模型,该团队在 GSM8K 和 MATH 数据集上对 CPPO 进行了实验评估。此外,为了评估模型的分布外推理能力,他们还引入了 AMC2023 和 AIME2024 作为测试基准。
在 GSM8K 上的结果如表 1 所示,CPPO 在准确度和加速比上都明显优于 GRPO。值得注意的是,CPPO 在各种剪枝率下都达到了与 GRPO 相当甚至更高的准确度。在 87.50% 的剪枝率下,CPPO 的准确度达到 80.41%,比 GRPO 的 77.05% 高出 3.36%。
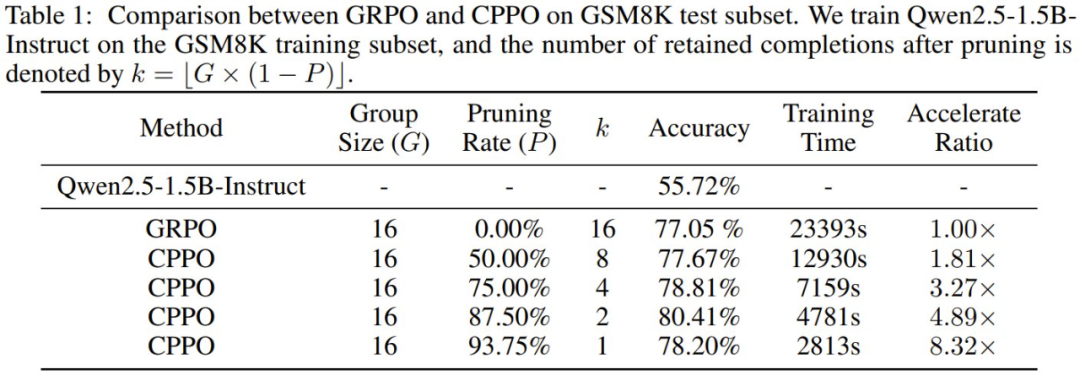
在效率方面,CPPO 大大加快了训练速度。在 93.75% 的剪枝率下,其加速比达到 8.32 倍。这些结果表明,CPPO 不仅能保持或提高准确度,还可显著提高训练效率。因此,CPPO 有潜力成为大规模推理模型训练的实用有效解决方案。
在 MATH 上的表现见表 2。可以看到,CPPO 可以很好地扩展到更大的模型 —— 在不牺牲准确度的情况下在 MATH 上实现了高达 3.51 倍的加速。例如,在 87.5% 的修剪率下,CPPO 保持了与 GRPO (75.20%) 相当的准确度,同时还将训练时间减少了 3.51 倍。
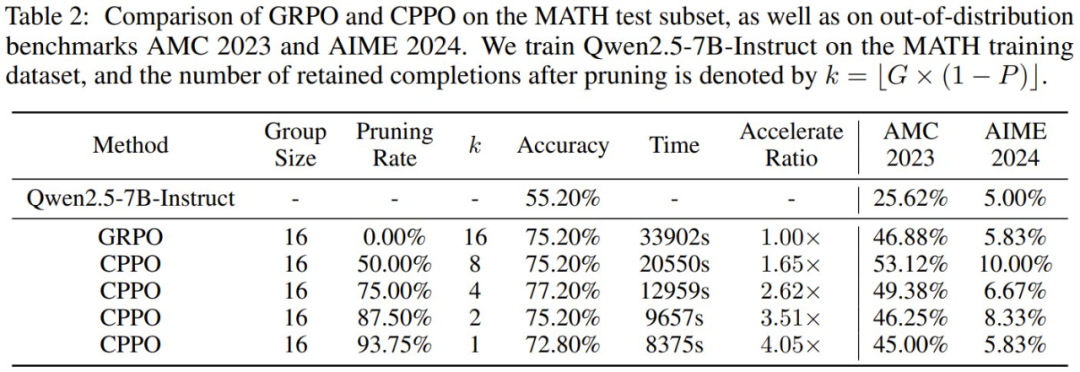
此外,在 AMC2023 和 AIME2024 基准上的评估表明,尽管 CPPO 仅在高绝对优势完成结果上进行训练,但它仍保留了模型在分布外任务上的泛化能力。因此,CPPO 不仅在增强推理能力方面匹敌甚至超越了 GRPO,而且还很好地减少了训练时间,使其成为一种更有效的替代方案。
该团队也研究了 CPPO 的稳定性和收敛性。图 4 展示了在 GSM8K 和 MATH 数据集上训练时的奖励曲线。
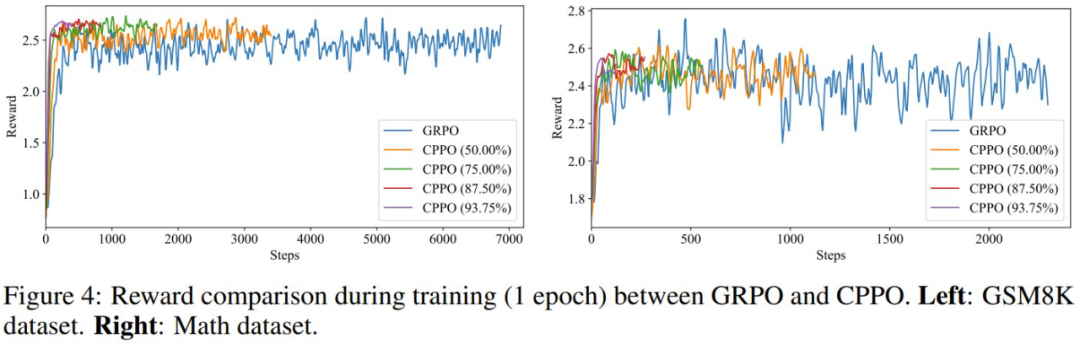
总体而言,奖励曲线证明 CPPO 在提高收敛速度的同时可保证 GRPO 的训练稳定性:CPPO 的奖励曲线不会崩溃或出现剧烈波动,这对于稳定训练至关重要。这些结果表明 CPPO 具有稳健而稳定的训练稳定性。此外,CPPO 的奖励曲线显示出了明显的上升趋势,能比 GRPO 更快地达到更高的奖励值。奖励值的更快增长表明 CPPO 的收敛速度更快。
你有兴趣在自己的强化学习训练流程中尝试这种更快的 CPPO 吗?

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com