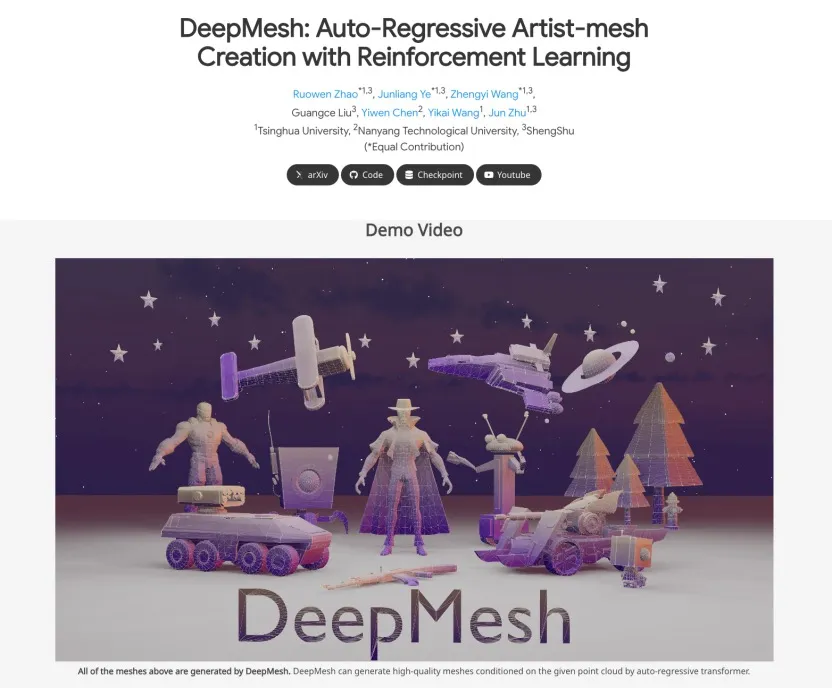
清华大学DeepMesh突破自回归生成瓶颈,可基于点云生成高达3万个面片的高质量三维网格,在生成质量和效率上实现显著提升,有望革新3D内容创作。
原文标题:清华朱军团队 | 从点云到高保真三维网格:DeepMesh突破自回归生成瓶颈
原文作者:机器之心
冷月清谈:
清华大学朱军团队提出了 DeepMesh 方法,用于解决三维数字内容生产中三角形网格生成效率和质量的问题。该方法基于自回归 Transformer 架构,通过逐步预测面片序列,从点云生成高质量三维网格,面片数量可达 3 万个,比现有技术提升一个数量级。DeepMesh 引入了三级块结构网格标记化方法,压缩序列长度,提升训练效率;通过双重筛选机制解决训练不稳定问题,并采用滑动窗口截断训练技术突破内存瓶颈。此外,DeepMesh 还引入了直接偏好优化(DPO)强化学习框架,结合几何指标与人类评价进行模型训练,提升生成结果的几何完整性和拓扑美观性。实验结果表明,DeepMesh 在细节保真、结构多样性和拓扑优化方面均表现出色,并在几何精度和拓扑质量上优于现有方法。
怜星夜思:
1、DeepMesh 使用了强化学习,这在三维网格生成中并不常见。你认为强化学习在提升网格质量方面起到了什么作用?除了DPO,还有哪些强化学习方法可能适用于这个任务?
2、DeepMesh 提到的三级块结构网格标记化方法,目的是压缩序列长度,提高训练效率。你认为这种方法还有哪些潜在的优点和缺点?在其他领域,是否也有类似的思想?
3、DeepMesh 在多样性生成方面表现出色,能够对同一输入生成多种风格各异的三维网格。你认为这种能力在实际应用中有多大的价值?除了文章中提到的影视制作和游戏设计,还有哪些领域可以应用?
2、DeepMesh 提到的三级块结构网格标记化方法,目的是压缩序列长度,提高训练效率。你认为这种方法还有哪些潜在的优点和缺点?在其他领域,是否也有类似的思想?
3、DeepMesh 在多样性生成方面表现出色,能够对同一输入生成多种风格各异的三维网格。你认为这种能力在实际应用中有多大的价值?除了文章中提到的影视制作和游戏设计,还有哪些领域可以应用?
原文内容

论文有三位共同一作。赵若雯,清华大学一年级硕士生,主要研究生成模型、强化学习和具身智能,已在ICRA等会议发表论文。叶俊良,清华大学二年级硕士生,专注于3D生成和基于人类偏好的多模态强化学习研究,曾以第一作者身份在ECCV发表DreamReward,该成果能生成更符合人类偏好的3D资产。王征翊,清华大学四年级博士生,主要研究3D多模态生成模型,已在NeurIPS、ECCV、ICML、CVPR等顶级学术会议发表多篇论文。
在三维数字内容生产领域,三角形网格作为核心的几何表示形式,其质量直接影响虚拟资产在影视、游戏和工业设计等应用场景中的表现与效率。
传统的三维网格生成方式,如人工建模或 Marching Cubes 等算法,存在成本高、拓扑结构质量差等问题。
针对这一瓶颈,清华大学朱军团队近日提出了 DeepMesh 方法,通过引入创新的自回归生成框架,显著提升了高面片人造网格的生成能力。该方法支持生成高达 3 万个面片的三维网格,相比现有技术提升了一个数量级。
-
论文标题:DeepMesh: Auto-Regressive Artist-mesh Creation with Reinforcement Learning
-
论文主页:https://zhaorw02.github.io/DeepMesh/
-
论文地址:https://arxiv.org/abs/2503.15265
-
代码:https://github.com/zhaorw02/DeepMesh
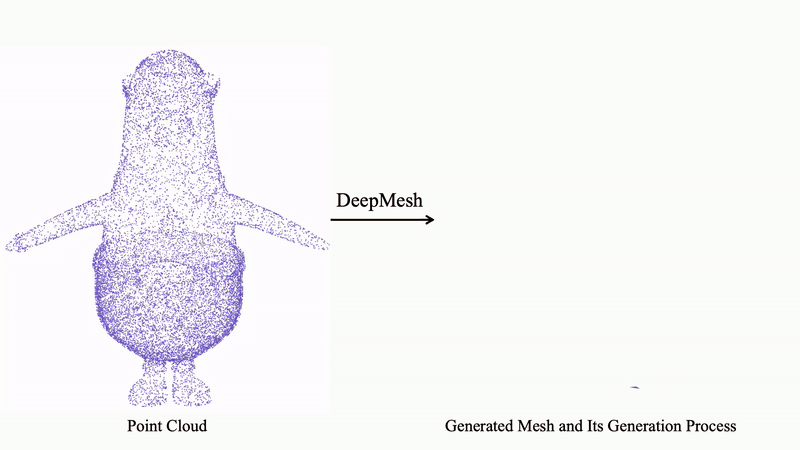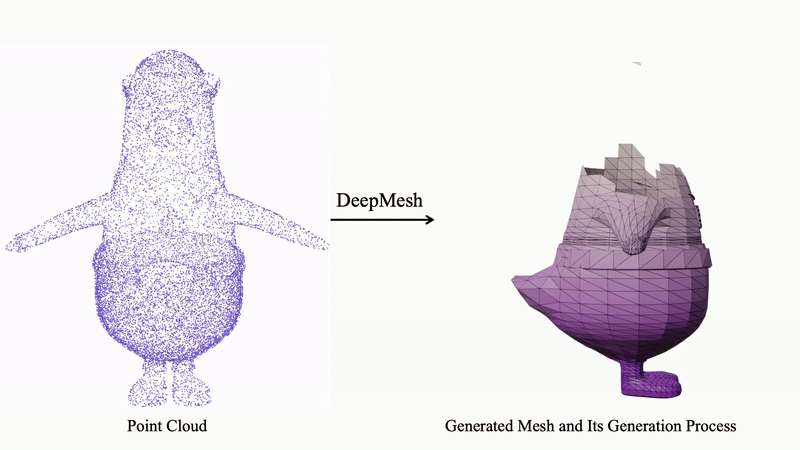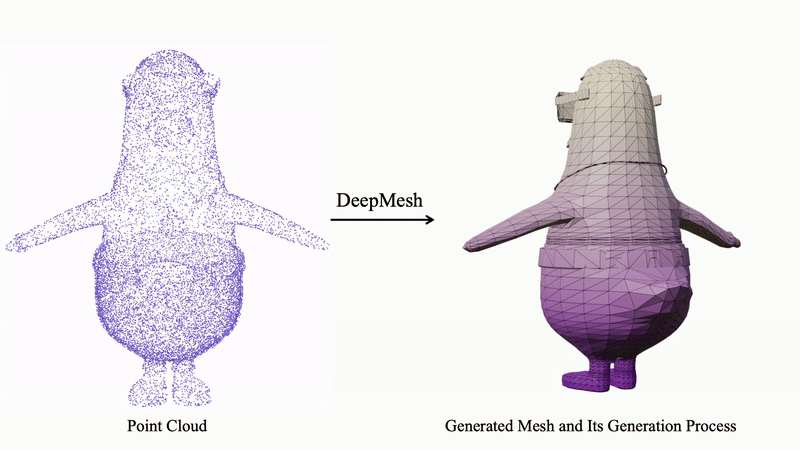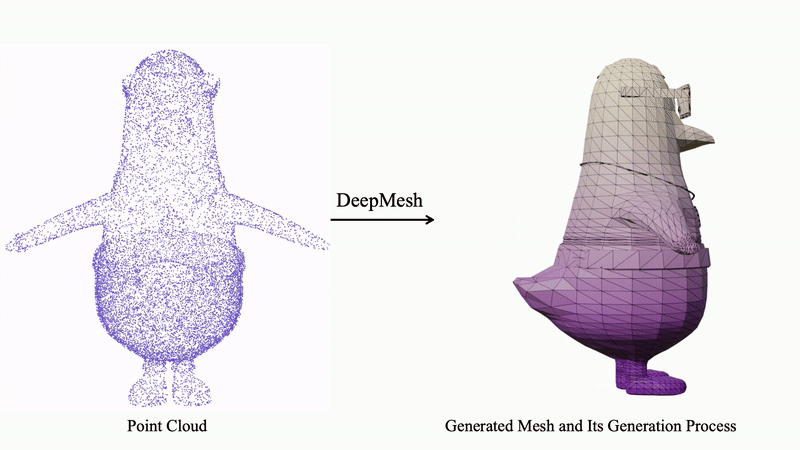
DeepMesh 基于输入点云,采用自回归的 Transformer 架构逐步预测面片序列,从而生成拓扑结构合理且视觉美观的高质量三维网格。



DeepMesh 架构如图所示,系统首先利用编码器对输入点云进行特征提取;提取到的特征随后被输入至自回归 Transformer 模块,该模块通过融合自注意力与交叉注意力机制,逐步预测网格的顶点或面片序列,最终生成结构完整的高质量三维网格。
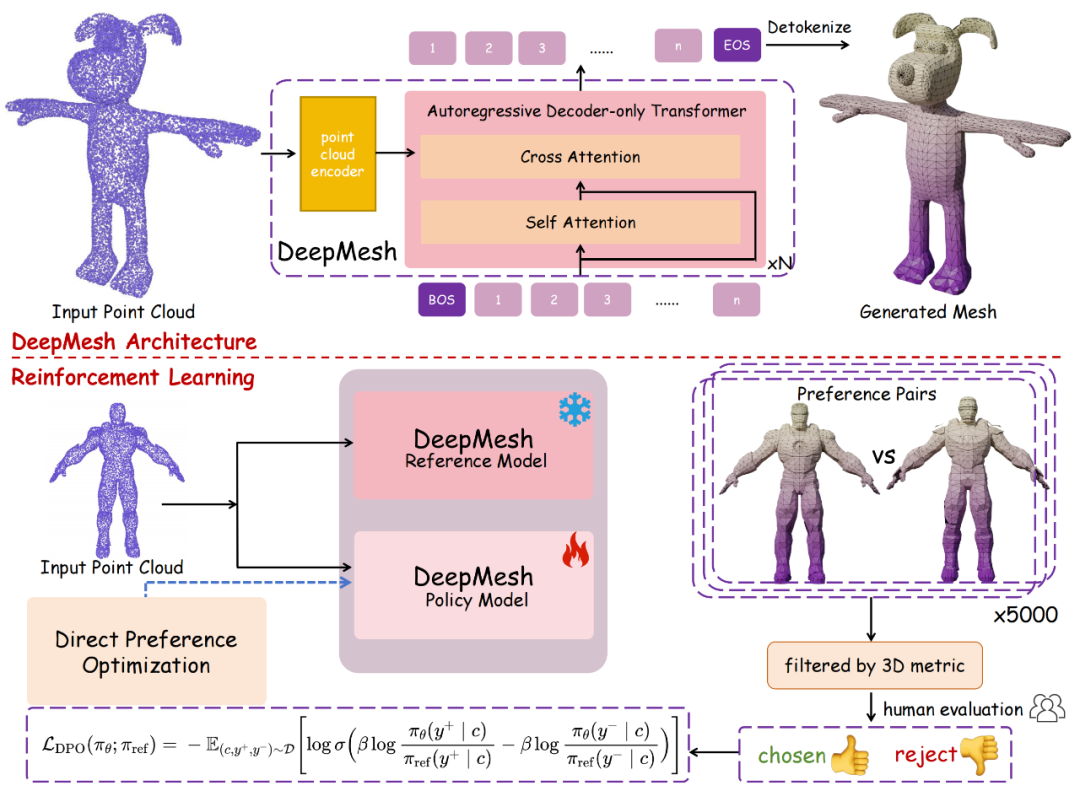
在预训练阶段,DeepMesh 引入了三级块结构网格标记化方法:根据面片之间的连通性对网格进行分解,并将其划分为粗、中、细多个空间层级。在此基础上,将面片中各顶点的坐标映射为相对于所属层级块的偏移索引,并对重复索引进行合并处理。
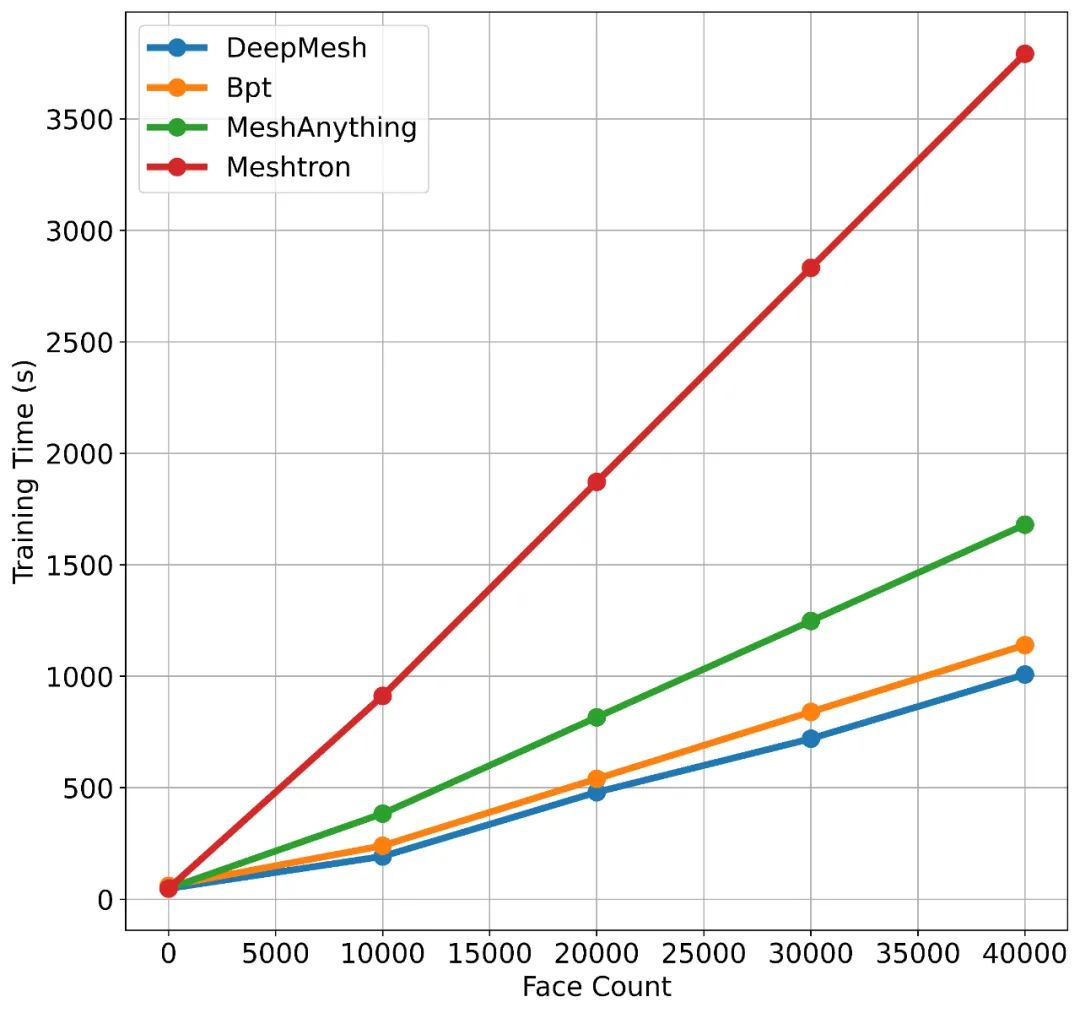
该方法在确保几何精度的同时,显著压缩了序列长度,从而大幅提升了训练效率。图中展示了采用 DeepMesh 网格标记化方法与其他方法,在训练不同面片数量的网格数据时的耗时对比情况。
通过对训练数据进行封装处理,并引入融合几何质量与结构规整度的双重筛选机制,DeepMesh 有效解决了异常样本引发的训练不稳定问题,同时实现了训练过程中的动态负载均衡。为突破长序列带来的内存瓶颈,模型还采用了滑动窗口截断训练技术,支持单个网格生成高达 3 万个面片,显著提升了建模能力。
此外,DeepMesh 创新性地引入了「直接偏好优化(DPO)」强化学习框架,并构建了一个结合客观几何指标与主观人类评价的分阶段数据标注系统。
该系统首先利用几何质量指标筛除存在明显缺陷的 3D 样本,随后由人工对剩余数据进行标注,评估其拓扑结构的合理性与视觉观赏性。基于这套高质量的标注数据,团队对模型进行了强化训练,从而显著提升了生成结果在几何完整性与拓扑美观性方面的表现。


DeepMesh 在细节保真与结构多样性方面表现出色,并具备对传统生成方法所生成网格进行拓扑优化的能力。与现有方法相比,DeepMesh 在几何精度与拓扑质量两个维度均实现最优性能,生成的三维网格不仅在结构合理性上表现卓越,也在视觉美观性上更具吸引力。


在多样性生成方面,DeepMesh 能在保持输入点云几何一致性的前提下,对同一输入生成多种具有高保真度且外观风格各异的三维网格方案,展现出强大的创意生成与精度控制的能力。这一特性对于影视制作、游戏设计等需进行多版本快速迭代的应用场景具有显著价值。

针对传统方法(如 TRELLIS)生成的拓扑结构混乱问题,DeepMesh 可对其输出结果进行有效的拓扑优化,显著提升网格结构的有序性与合理性。


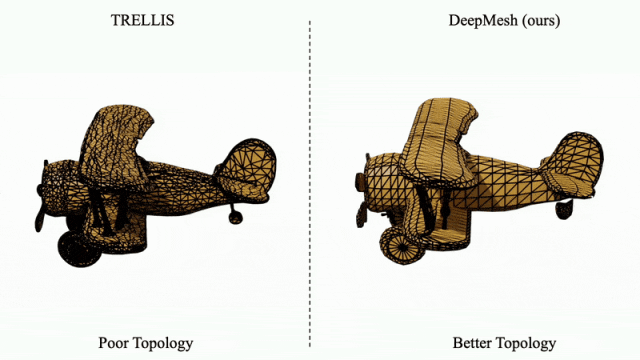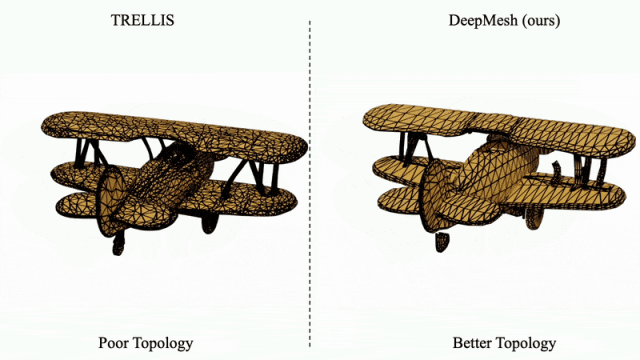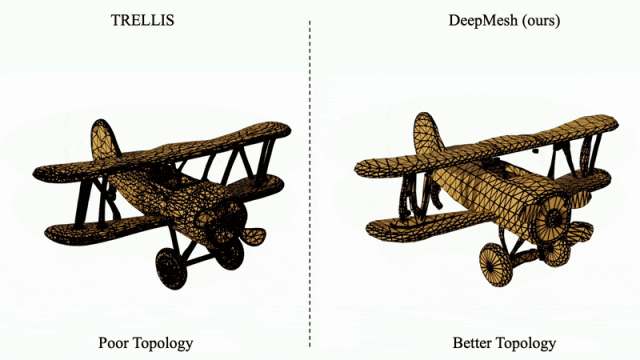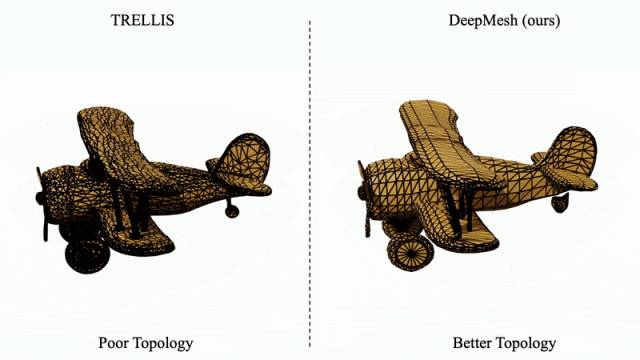
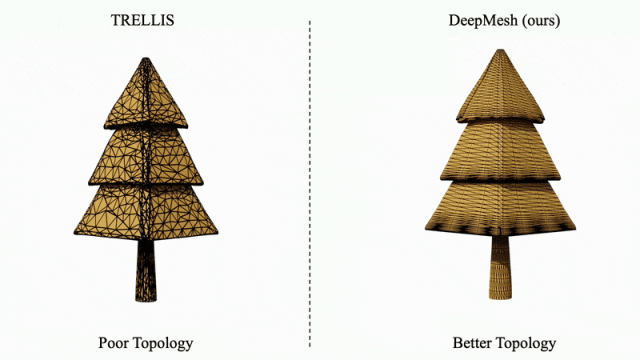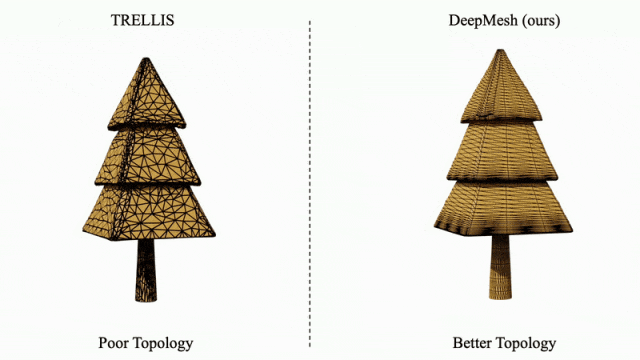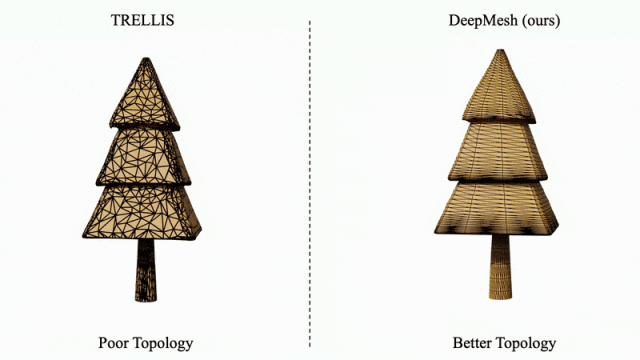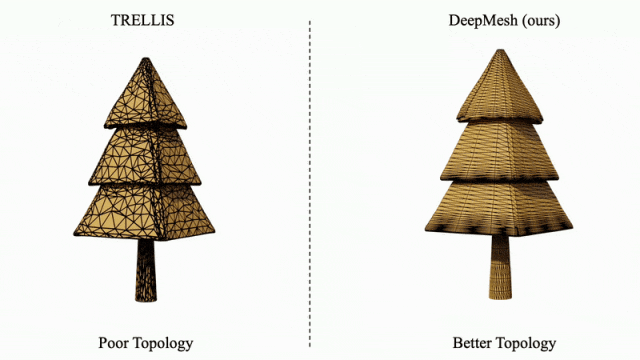
凭借在高保真、多样性与拓扑优化方面的突出表现,DeepMesh 展现出在 3D 内容创作领域的颠覆性潜力,特别适用于数字游戏、虚拟现实、影视制作等对创意表达与建模效率要求极高的行业。
该研究成果发布后迅速引发广泛关注,知名推特博主 AK 第一时间转发支持,相关内容获得上千点赞,引发业内与社群的热烈讨论与积极反馈。

以下展示更多由 DeepMesh 生成的三维网格示例,进一步体现模型在细节还原、拓扑合理性及多样性方面的强大能力。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com