CycleResearcher通过强化学习实现科研流程自动化,可自主进化,并开源代码和数据,加速科研进步。
原文标题:ICLR 2025 | 真正「Deep」的「Research」,通过强化学习实现可自主进化的科研智能体来了!
原文作者:机器之心
冷月清谈:
怜星夜思:
2、CycleResearcher目前还存在哪些局限性?未来有哪些可能的改进方向?
3、CycleResearcher的出现,对传统的科研人员的角色会产生什么影响?我们应该如何应对这种变化?
原文内容

CycleResearcher 研究团队成员包括:张岳教授,西湖大学人工智能系教授,工学院副院长,其指导的博士生朱敏郡、张鸿博、鲍光胜、访问学生翁诣轩;UCL 访问研究员杨林易博士,25 Fall 入职南方科技大学拟任独立 PI,博士生导师,研究员。
AI 技术不断进步,科研自动化浪潮正在深刻改变学术世界!近日,来自西湖大学、UCL 等机构的研究团队在自动化科研方向发布了一项突破性的成果:CycleResearcher 。 CycleResearcher 首次实现了可训练的科研流程的全链路端到端训练,覆盖智能文献检索、模型主动提问、强化学习迭代优化论文创新点、方法论架构设计、实验设计到论文自动生成的完整闭环。
值得一提的是,同类功能在 OpenAI 商业化方案中需支付高达 2 万美元 / 月的服务费用,而团队开源了所有代码、数据、和 Demo:

-
论文链接:https://openreview.net/forum?id=bjcsVLoHYs
-
网页链接:https://ai-researcher.net/
-
代码链接:https://github.com/zhu-minjun/Researcher
牛津大学教授 Will MacAskill 最新预言未来 AI 的增长率足以在不到 10 年的时间里,推动相当于 100 年的技术进步。如何让 AI 实现「递归自我改进」成为了解决这个问题的关键!然而,现有的一系列工作包括 SakanaAI 公司于去年 8 月发布的 AI Scientist、香港大学最近发布的 AI-Researcher 都是基于调用 API 构建推理的框架去实现自动化科研,而无法被训练优化。CycleResearcher(模型上传于 24 年 8 月)是全球首个通过强化学习迭代优化训练实现的 AI 科研智能体。

图 1: AI Researcher 功能展示图
CycleResearcher 首次实现了通过强化学习进行科研过程的自动迭代改进,它能够模拟完整的科研流程,包括文献综述、研究构思、论文撰写,以及模拟实验结果。
研究团队主要干了三件事情:
1)数据集: 发布了两个大规模数据集 Review-5k 和 Research-14k,用于评估和训练学术论文评审和生成模型。
2)CycleResearcher 模型: 可以生成质量接近人类撰写预印本的论文(评分 5.36 分),实现 31.07% 的接受率。
3)CycleReviewer 模型: 一个做论文评审的模型,在平均绝对误差 (MAE) 方面显示出令人鼓舞的结果,与人类评审员相比,平均绝对误差(MAE)降低了 26.89%。
利用商业大型语言模型(LLMs)作为研究助理或想法生成器已经取得了显著进展,但在多达上万次模拟同行评议中通过反馈而自我进化的自动科研大模型从未实现过。这项研究的提出旨在解决了这个领域难题。
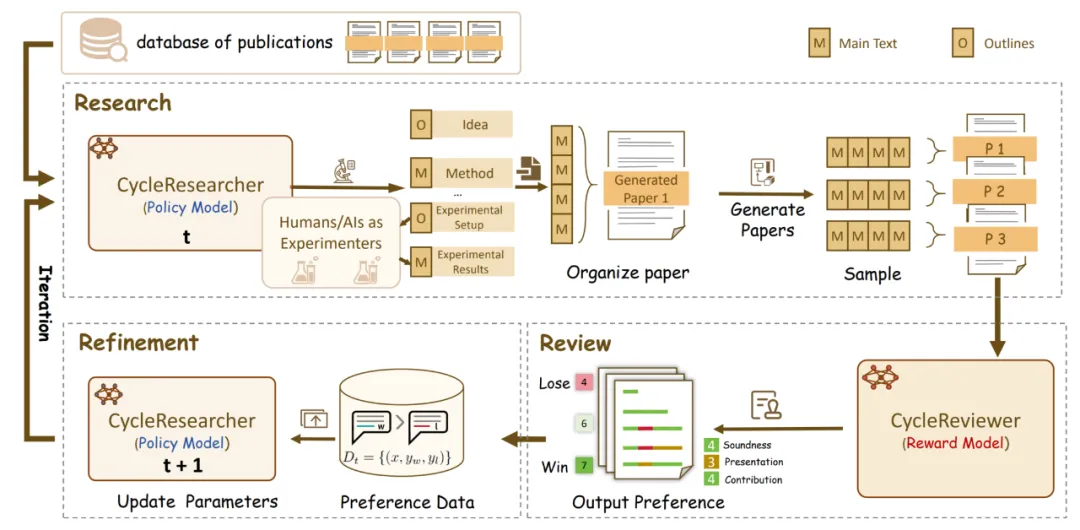
图 2: CycleResearcher 训练框架图
创新点详细解读:
1. 高质量数据集与模型规模化:为训练 CycleResearcher,研究团队专门构建了包含近 1.5 万篇高质量学术论文的数据集(Research-14K),数据来源覆盖了 ICLR、NeurIPS、ICML、ACL、EMNLP、CVPR 和 ICCV 等顶级会议。提供了多个不同规模的模型(12B、72B、123B),满足不同科研需求。
2. 强化学习与迭代反馈机制:如图二所示,CycleResearcher 的核心技术,在于其采用迭代式偏好优化(Iterative SimPO)的训练框架,这一方法使得在线强化学习(Online RLHF)成为了可能。这个框架包含两个关键模型:策略模型 (CycleResearcger) 和奖励模型 (DeepReveiwer)。
3. 指令微调(SFT)热身阶段:策略模型 CycleResearcher 负责生成论文的各个部分,它首先会进行广泛的文献综述,从输入的 bib 文件中获取所有参考文献及其摘要,全面了解研究背景。然后,它会交替生成论文的大纲和正文,确保逻辑流畅。具体来说,它会先生成动机和大纲中的主要思想,然后生成标题、摘要、引言和方法部分。接下来,概述实验设置和结果,随后生成实验设计和模拟结果(注意,这里的实验结果是模拟的)。最后,它会分析实验结果并形成结论。整个过程就像一位经验丰富的科研人员在撰写论文一样,有条不紊,逻辑清晰。奖励模型 CycleReviewer 则负责模拟同行评议,对生成的论文进行评估和反馈。它会从多个维度对论文进行打分,并给出具体的评审意见。
4. 迭代反馈训练阶段:研究人员首先通过拒绝采样获取样本,通过 CycleReviewer 的打分构成偏好对,两个模型相互配合,通过强化学习的方式不断优化,CycleResearcher 根据 CycleReviewer 的反馈不断改进自身的论文生成策略,CycleReviewer 则根据 CycleResearcher 生成的论文不断提高自身的评审能力。两个模型交互反馈,不断优化策略。在 Iterative SimPO 算法中,SimPO 算法虽然可以帮助 AI 区分 “好” 论文和 “坏” 论文,但它不能保证 AI 生成的文本是流畅的。因此,我们将 SimPO 损失和 NLL 损失结合起来,让 AI 模型既能写出高质量的论文,又能保证文本的流畅性。
5. 实验结果:CycleResearcher 生成论文的模拟评审平均得分达到 5.36 分,超过目前 AI Scientist 的 4.31 分,且十分接近人类真实预印本的平均水平(5.24 分)。同时,CycleResearcher 论文的接受率达到了 35.13%,远高于 AI Scientist 的 0%。
总结
1: 这篇工作首次提出了一个用于自动化整个研究生命周期的迭代强化学习框架 通过集成 CycleResearcher(策略模型)和 CycleReviewer(奖励模型),该框架能够模拟真实世界的研究 - 评论 - 改进的迭代循环。
2: 团队发布了两个大规模数据集,用于学术论文生成和评论的评估与训练 Review-5k 和 Research-14k 数据集专为捕捉机器学习中同行评审和研究论文生成的复杂性而设计,为评估和训练学术论文生成和评审模型提供了宝贵的资源。
3: CycleResearcher 在研究构思和实验设计方面表现出一致的性能,可以达到人类撰写预印本的论文质量,接近会议接受论文的质量。 这表明 LLM 可以在科学研究和同行评审过程中做出有意义的贡献。
我们坚信科研工具应当开放共享,因此提供了完整的开源资源套件:
pip install ai_researcher
开源套件包含:
1. 不同规模模型:所有模型均支持本地部署
-
CycleResearcher:提供 12B、72B 和 123B 三种规模
-
CycleReviewer:提供 8B、70B 和 123B 三种规模
-
DeepReviewer:提供 7B 和 14B 两种规模
2. 大规模训练数据集:
-
Review-5K:包含 4,989 篇论文的专业评审数据
-
Research-14K:包含 14,911 篇高质量论文的结构化数据
-
DeepReview-13K:包含 13,378 篇论文的多维度深度评审数据
3. 详尽教程:
-
CycleResearcher 教程:https://github.com/zhu-minjun/Researcher/blob/main/Tutorial/tutorial_1.ipynb
-
CycleReviewer 教程:https://github.com/zhu-minjun/Researcher/blob/main/Tutorial/tutorial_2.ipynb
-
DeepReviewer 教程:https://github.com/zhu-minjun/Researcher/blob/main/Tutorial/tutorial_3.ipynb
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com