Databricks推出TAO,一种无需标注数据的模型调优方法,能将Llama模型提升至GPT-4o水平,且推理成本不变。
原文标题:模型调优无需标注数据!将Llama 3.3 70B直接提升到GPT-4o水平
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到 TAO 在训练阶段使用了测试时计算,但最终模型推理成本与原始模型相同。这种方式是如何实现的?是否存在一些trade off,例如训练成本的大幅增加?
3、TAO 方法依赖于任务相关的输入样本,并通过强化学习来优化模型。那么,如果提供的输入样本质量不高或者不够具有代表性,是否会影响 TAO 的调优效果?如何保证输入样本的质量?
原文内容
现阶段,微调大型语言模型(LLMs)的难点在于,人们通常没有高质量的标注数据。
最近,AI 公司 Databricks 推出了一种新的调优方法 TAO,只需要输入数据,无需标注数据即可完成。更令人惊喜的是,TAO 在性能上甚至超过了基于标注数据的监督微调。
众所周知,LLM 很难适应新的企业级任务。提示(prompting)的方式容易出错,且质量提升有限,而微调(fine-tuning)则需要大量的标注数据,而这些数据在大多数企业任务中是不可用的。
Databricks 提出的模型调优方法,只需要未标注数据,企业就可以利用现有的数据来提升 AI 的质量并降低成本。
TAO(全称 Test-time Adaptive Optimization)利用测试时计算(由 o1 和 R1 推广)和强化学习(RL)算法,仅基于过去的输入示例来教导模型更好地完成任务。
至关重要的是,尽管 TAO 使用了测试时计算,但它将其作为训练模型过程的一部分;然后,该模型以较低的推理成本(即在推理时不需要额外的计算)直接执行任务。
更令人惊讶的是,即使没有标注数据,TAO 也能实现比传统调优模型更好的质量,并且它可以将像 Llama 这样的开源模型提升到与专有模型(如 GPT-4o 和 o3-mini)相当的质量水平。
借助 TAO,Databricks 已经取得了三项突破性成果:
-
在文档问答和 SQL 生成等专业企业任务中,TAO 的表现优于需要数千标注样本的传统微调方法。它让 Llama 8B/70B 等高效开源模型达到了 GPT-4o/o3-mini1 等商业模型的同等水平,且无需任何标注数据;
-
在零标注数据条件下,TAO 将 Llama 3.3 70B 模型在企业综合基准测试中的表现提升了 2.4%;
-
增加 TAO 训练阶段的算力投入,可以在相同数据条件下获得更优模型质量,且不会增加推理阶段的成本消耗。
图 1 展示了 TAO 在三个企业级任务中对 Llama 模型的提升效果:尽管仅使用原始输入数据,TAO 不仅超越了需要数千标注样本的传统微调 (FT) 方法,更让 Llama 系列模型达到了商业模型的性能水准。
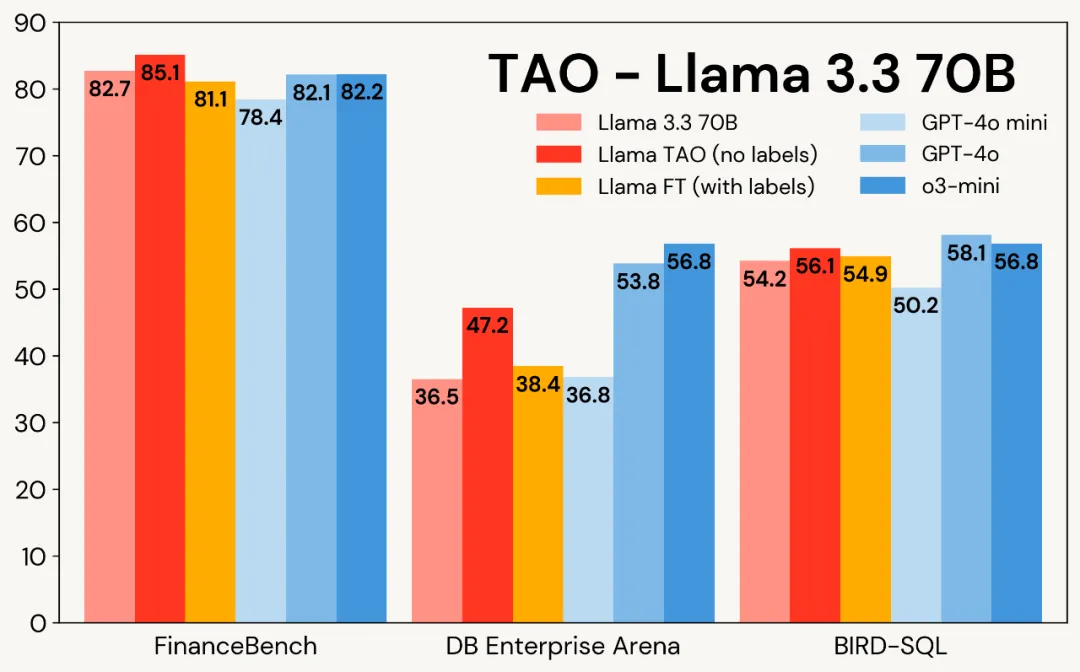
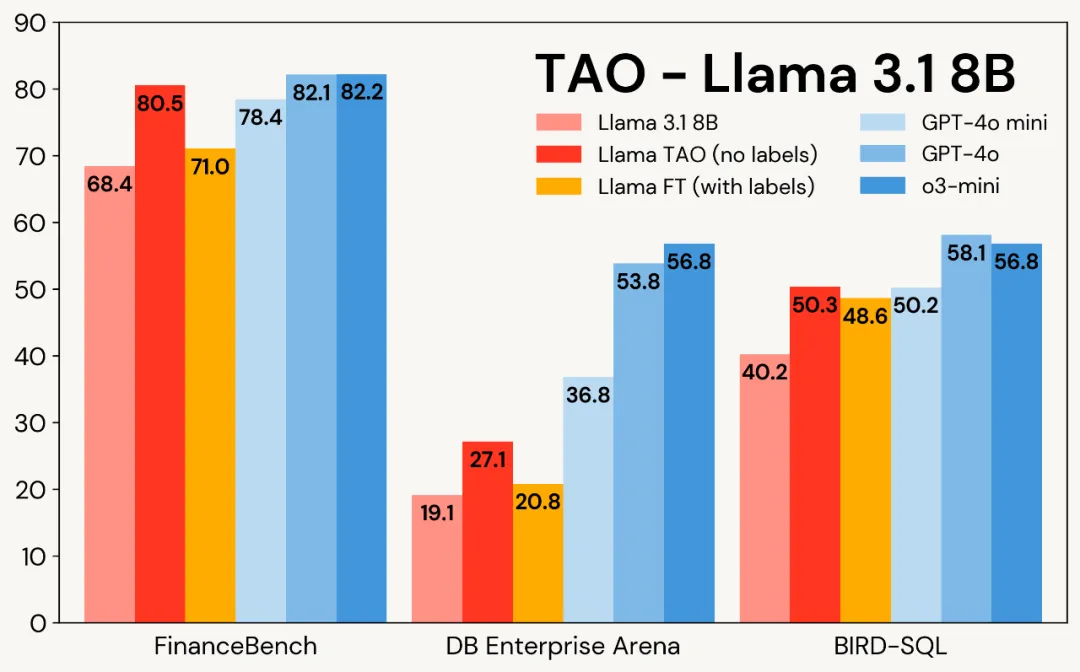
图 1:Llama 3.1 8B 与 Llama 3.3 70B 在三大企业级基准测试中应用 TAO 的效果对比。TAO 带来显著的性能提升,不仅超越传统微调方法,更直指高价商业大语言模型的性能水平。
TAO 工作原理
基于测试时计算与强化学习的模型调优
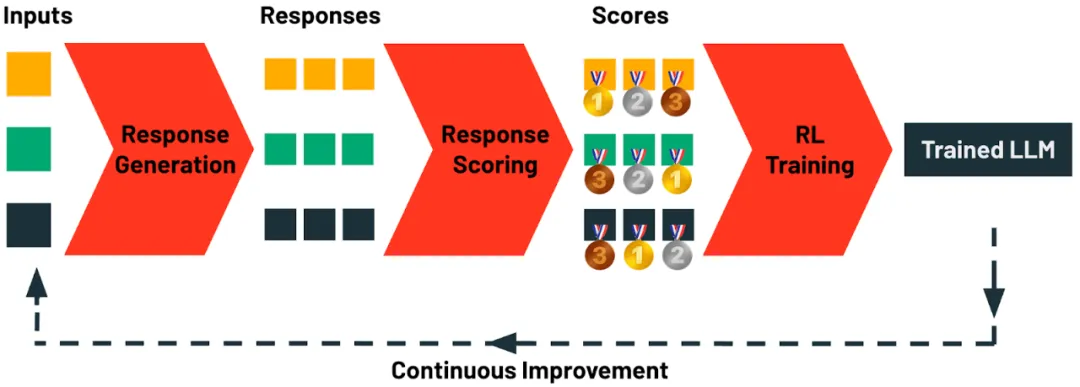
TAO 的核心创新在于摒弃了人工标注数据,转而利用测试时计算引导模型探索任务的可能响应,再通过强化学习根据响应评估结果更新模型参数。
该流程通过可扩展的测试时计算(而非昂贵的人工标注)实现质量提升,并能灵活融入领域知识(如定制规则)。令人惊讶的是,在高质量开源模型上应用该方法时,其效果往往优于依赖人工标注的传统方案。
TAO pipeline
TAO 包含四个核心阶段:
-
响应生成:该阶段首先收集任务相关的输入提示或查询样本。在 Databricks 平台上,这些提示可通过 AI Gateway 自动采集;
-
响应评分:系统化评估生成响应的阶段。评分方法包含多种策略,例如基于奖励模型、偏好评分,或利用 LLM 评判器及定制规则进行任务特异性验证,确保每个响应都做到最优;
-
强化学习(RL)训练:最终阶段采用基于强化学习的方法更新大语言模型,引导模型生成与高分响应高度契合的输出。通过这一自适应学习过程,模型持续优化预测能力以提升质量;
-
持续改进:TAO 仅需 LLM 输入样本作为数据源。用户与 LLM 的日常交互自然形成该数据 —— 一旦模型部署使用,即可自动生成下一轮 TAO 训练数据。在 Databricks 平台上,借助 TAO 机制,模型会随着使用频次增加而持续进化。
虽然 TAO 在训练阶段使用了测试时计算,但最终产出的模型在执行任务时仍保持低推理成本。这意味着经过 TAO 调优的模型在推理阶段 —— 与原版模型相比 —— 具有完全相同的计算开销和响应速度,显著优于 o1、o3 和 R1 等依赖测试时计算的模型。实验表明:采用 TAO 训练的高效开源模型,在质量上足以比肩顶尖的商业闭源模型。
TAO 为 AI 模型调优提供了一种突破性方法:
-
不同于耗时且易出错的提示工程;
-
也区别于需要昂贵人工标注数据的传统微调;
-
TAO 仅需工程师提供任务相关的典型输入样本,即可实现卓越性能。

LLM 不同调优方法比较。
实验及结果
接下来,文章深入探讨了如何使用 TAO 针对专门的企业任务调优 LLM。本文选择了三个具有代表性的基准。

表 2:该研究使用的基准测试概览。
如表 3 所示,在所有三个基准测试和两种 Llama 模型中,TAO 显著提升了基础 Llama 的性能,甚至超过了微调的效果。

表 3:在三个企业级基准测试中使用 TAO 的 Llama 3.1 8B 和 Llama 3.3 70B 实验结果。
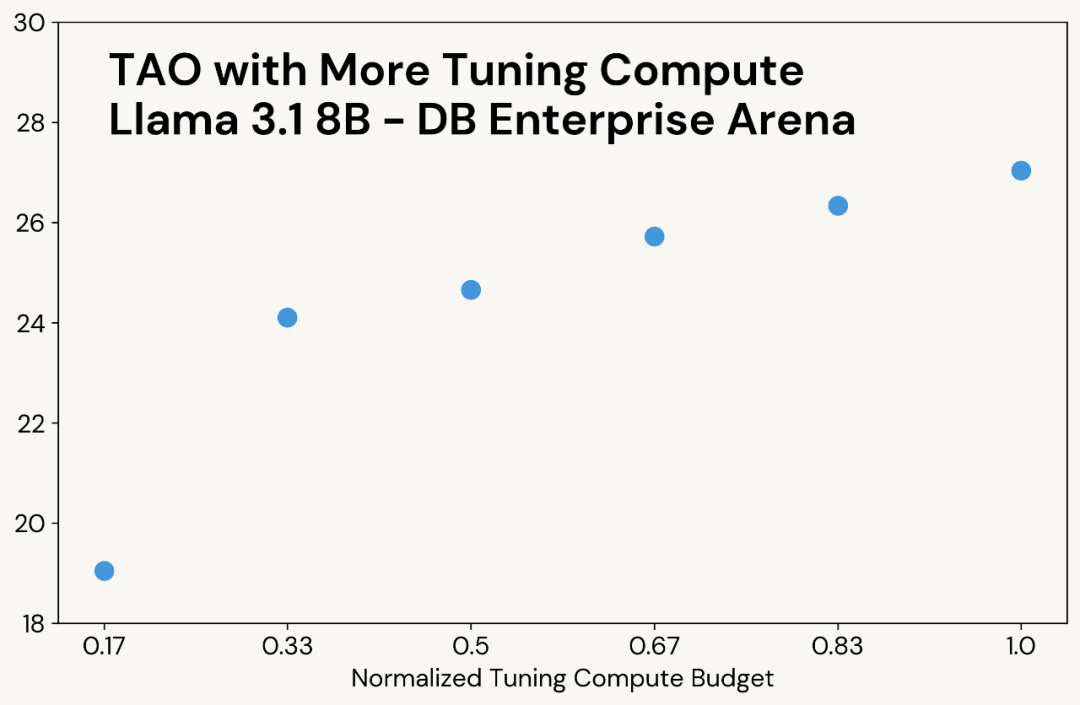
与经典的测试时计算类似,当 TAO 能够使用更多的计算资源时,它会产生更高质量的结果(见图 3 中的示例)。然而,与测试时计算不同的是,这种额外的计算资源仅在调优阶段使用;最终的语言模型的推理成本与原始语言模型相同。例如,o3-mini 生成的输出 token 数量比其他模型多 5-10 倍,因此其推理成本也相应更高,而 TAO 的推理成本与原始 Llama 模型相同。
利用 TAO 提高模型多任务性能
到目前为止,该研究已经使用 TAO 来提升语言模型在单一任务(例如 SQL 生成)上的表现。接下来,该研究展示了 TAO 如何广泛提升模型在一系列企业任务中的性能。
结果如下,TAO 显著提升了两个模型的性能,将 Llama 3.3 70B 和 Llama 3.1 70B 分别提升了 2.4 和 4.0 个百分点。TAO 使 Llama 3.3 70B 在企业级任务上的表现显著接近 GPT-4o,所有这些改进都没有产生人工标注成本。

原文链接:https://www.databricks.com/blog/tao-using-test-time-compute-train-efficient-llms-without-labeled-data
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com