何恺明团队提出分形生成模型,递归调用同类模型逐像素建模高分辨率图像,效率提升4000倍!
原文标题:何恺明带队新作「分形生成模型」:逐像素建模高分辨率图像、效率提升4000倍
原文作者:数据派THU
冷月清谈:
何恺明团队提出了名为“分形生成模型”的全新架构,灵感来源于数学中的分形概念。该模型的核心在于通过递归调用同类生成模型,实现对高分辨率图像的逐像素建模。这种分而治之的策略将复杂任务分解为多个小块,显著降低了计算成本,效率提升高达4000倍。实验结果表明,该模型在高分辨率图像生成任务上表现出色,能够生成高保真度和细节丰富的图像。
怜星夜思:
1、分形生成模型通过递归调用子模型来提高效率,那么这种递归深度应该如何选择?更深的递归是否总是更好?是否存在过拟合的风险?
2、文章中提到分形生成模型灵感来源于自然界的分形结构,那么这种分形架构在其他领域,例如自然语言处理或者音频生成中,是否有应用潜力?
3、文章中提到该模型在ImageNet数据集上表现出色,那么在实际应用中,例如在低算力设备上部署,会遇到哪些挑战?如何解决?
2、文章中提到分形生成模型灵感来源于自然界的分形结构,那么这种分形架构在其他领域,例如自然语言处理或者音频生成中,是否有应用潜力?
3、文章中提到该模型在ImageNet数据集上表现出色,那么在实际应用中,例如在低算力设备上部署,会遇到哪些挑战?如何解决?
原文内容

这才过几天,大神何恺明又放出一篇新论文!
这次构建了一种全新的生成模型。类似于数学中的分形,研究者推出了一种被称为分形生成模型(Fractal Generative Models)的自相似分形架构。
何恺明团队提出了分形生成模型,一种基于递归调用同类生成模型的架构,灵感来源于数学中的分形概念。该模型通过分而治之的策略,将高分辨率图像分解为多个小块进行逐像素建模,显著降低了计算成本(效率提升4000倍),并在高分辨率图像生成任务上表现出色,能够生成高保真度和细粒度细节的图像。
在计算机科学领域,它的核心是模块化概念,比如深度神经网络由作为模块化单元的原子「层」构建而成。同样地,现代生成模型(如扩散模型和自回归模型)由原子「生成步骤」构建而成,每个步骤都由深度神经网络实现。
通过将复杂函数抽象为这些原子构建块,模块化使得可以通过组合这些模块来创建更复杂的系统。基于这一概念,研究者提出将生成模型本身抽象为一个模块,以开发更高级的生成模型。一作 Tianhong Li 为 MIT 博士后研究员、二作 Qinyi Sun 为 MIT 本科生(大三)。

-
论文标题:Fractal Generative Models
-
论文地址:https://arxiv.org/pdf/2502.17437v1
-
GitHub 地址:https://github.com/LTH14/fractalgen
具体来讲,研究者提出的分形生成模型通过在其内部递归调用同类生成模型来构建。这种递归策略产生了一个生成框架,在下图 1 中展示了其跨不同模块级别的具有自相似性的复杂架构。

如前文所述,本文分形生成模型类似于数学中的分形概念。分形是使用被称为「生成器」的递归规则构建的自相似模式。同样地,本文框架也是通过在生成模型中调用生成模型的递归过程构建的,并在不同层次上表现出自相似性。因此,研究者将其命名为「分形生成模型」。
本文的分形生成模型的灵感来自于生物神经网络和自然数据中观察到的分形特性。与自然的分形结构类似,研究者设计的关键组件是定义递归生成规则的生成器,比如这样的生成器可以是自回归模型,如图 1 所示。在此实例中,每个自回归模型都由本身就是自回归模型的模块组成。
具体而言,每个父自回归块都会生成多个子自回归块,每个子块都会进一步生成更多自回归块。由此产生的架构在不同级别上表现出类似分形的自相似模式。
在实验环节,研究者在一个具有挑战性的测试平台上(逐像素图像生成)检验了这个分形实例。 结果显示,本文的分形框架在这一具有挑战性的重要任务上表现出色,它不仅可以逐像素生成原始图像,同时实现了准确的似然估计和高生成质量,效果如下图 2 所示。
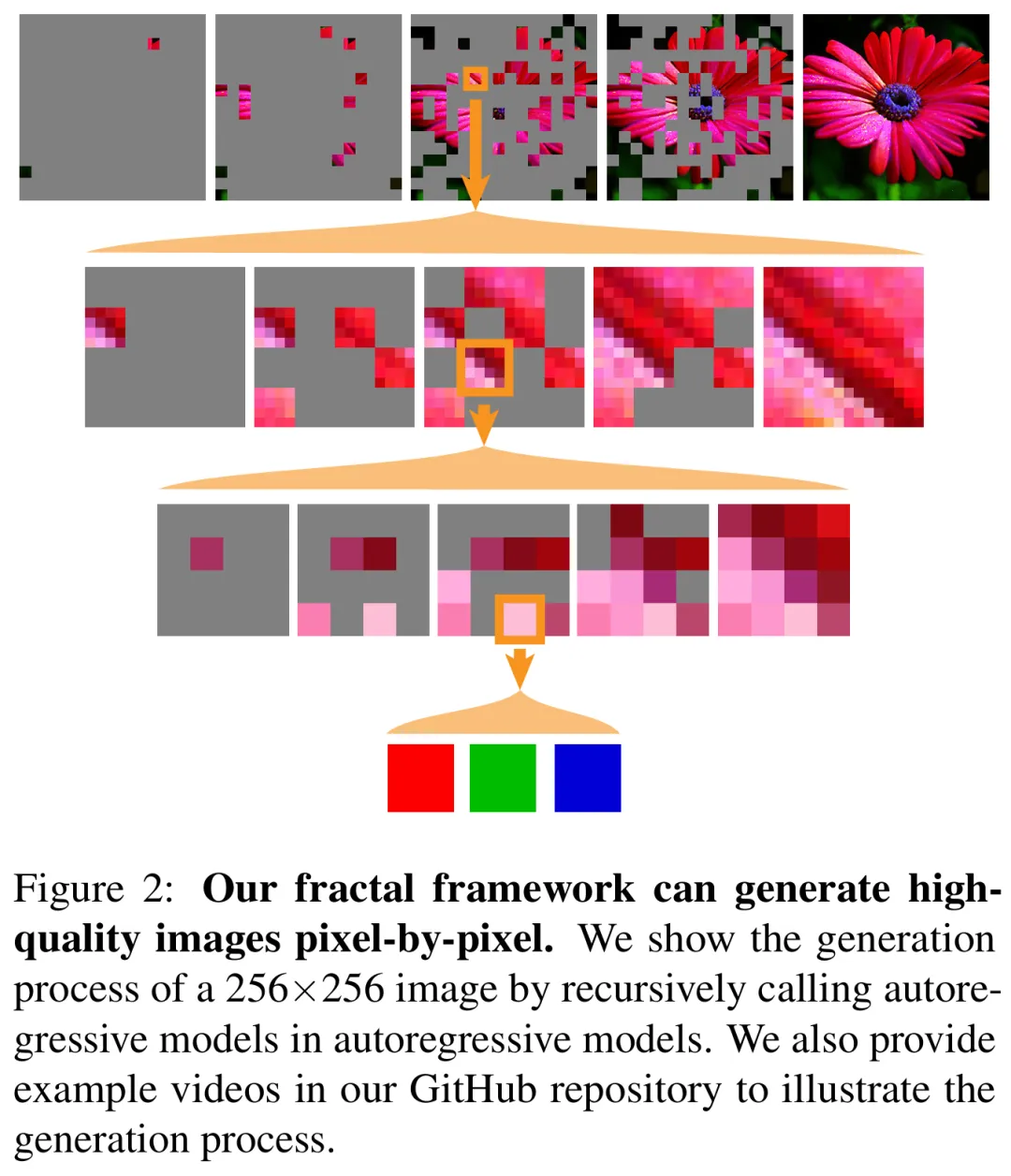
研究者希望这一充满潜力的的结果能够激励大家进一步研究分形生成模型的设计和应用,最终在生成建模中建立一种全新的范式。
有人评论道,「分形生成模型代表了AI领域一个令人兴奋的前沿。自回归模型的递归性质反映了学习如何反映自然模式。这不仅仅是理论,它是通往更丰富、适应性更强的AI系统的途径。」

分形生成模型详解
研究者表示,分形生成模型的关键思路是「从现有的原子生成模块中递归地构建更高级的生成模型。」
具体来讲,该分形生成模型将一个原子生成模块用作了参数分形生成器。 这样一来,神经网络就可以直接从数据中「学习」递归规则。通过将指数增长的分形输出与神经生成模块相结合,分形框架可以对高维非序列数据进行建模。
接下来,研究者展示了如何通过将自回归模型用作分形生成器来构建分形生成模型。 他们将自回归模型用作了说明性原子模块,以演示分形生成模型的实例化,并用来对高纬数据分布进行建模。
假设每个自回归模型中的序列长度是一个可管理的常数 k,并使随机变量的总数为 N = k^n,其中 n = log_k (N) 表示分形框架中的递归级别数。然后,分形框架的第一个自回归级别将联合分布划分为 k 个子集,每个子集包含 k^n−1 个变量。
在形式上,研究者进行了如下解耦:
接着每个具有 k^n−1 个变量的条件分布 p (・・・|・・・) 由第二个递归级别的自回归模型建模,并依此类推。
研究者表示,通过递归地调用这种分而治之(divide-and-conquer)的过程,分形框架可以使用 n 级自回归模型高效地处理 k^n 个变量的联合分布,并且每个模型都对可管理的序列长度 k 进行操作。
这种递归过程代表了一种标准的分而治之策略。通过递归地解耦联合分布,本文分形自回归架构不仅相较于单个大型自回归模型显著降低了计算成本,而且还捕获了数据中的内在层次结构。 从概念上讲,只要数据表现出可以分而治之的组织结构,就可以在该分形框架内自然地对其进行建模。
实现:图像生成实例化
研究者展示了分形自回归架构如何用于解决具有挑战性的逐像素图像生成任务。
架构概览
如下图 3 所示,每个自回归模型将上一级的生成器的输出作为其输入,并为下一级生成器生成了多个输出。该模型还获取一张图像(也可以是原始图像的 patch),将其分割成 patch,并将它们嵌入以形成一个 transformer 模型的输入序列。这些 patch 也被馈送到相应的下一级生成器。
接下来,transformer 模型将上一个生成器的输出作为单独的 token,放在图像 token 的前面。基于此组合序列,transformer 为下一级生成器生成多个输出。
研究者将第一级生成器 g_0 的序列长度设置为 256,将原始图像分成 16 × 16 个 patch。然后,第二级生成器对每个 patch 进行建模,并进一步将它们细分为更小的 patch,并继续递归执行此过程。为了管理计算成本,他们逐步减少较小 patch 的宽度和 transformer 块的数量,这样做是因为对较小 patch 进行建模通常比对较大 patch 更容易。
在最后一级,研究者使用一个非常轻量级的 transformer 来自回归地建模每个像素的 RGB 通道,并在预测中应用 256 路交叉熵损失。

不同递归级别和分辨率下,每个 transformer 的精确配置和计算成本如下表 1 所示。值得注意的是,通过本文的分形设计,建模分辨率为 256×256 图像的计算成本仅为建模分辨率为 64×64 图像的两倍。

本文方法支持不同的自回归设计。研究者主要考虑了两种变体:光栅顺序、类 GPT 的因果 transformer (AR) 和随机顺序、类 BERT 的双向 transformer (MAR),具体如下图 6 所示。

尺度空间自回归模型
最近,一些模型已经提出为自回归图像生成执行下一尺度(next-scale)预测。这些尺度空间自回归模型与本文方法的一个主要区别是:它们使用单个自回归模型来逐尺度地预测 token。
相比之下,本文分形框架采用分而治之的策略,使用生成式子模块对原始像素进行递归建模。 另一个关键区别在于计算复杂性:尺度空间自回归模型在生成下一尺度 token 的整个序列时需要执行完全注意力操作,这会导致计算复杂性大大增加。
举例而言,在生成分辨率为 256×256 的图像时,在最后一个尺度上,尺度空间自回归模型每个注意力块中的注意力矩阵大小为 (256 ×256)^2 即 4,294,967,296。相比之下,本文方法在对像素 (4×4) 相互依赖性进行建模时对非常小的 patch 执行注意力,其中每个 patch 的注意力矩阵只有 (4 × 4)^2 = 256,导致总注意力矩阵大小为 (64 × 64) × (4 × 4)^2 = 1,048,576 次操作。
这种减少使得本文方法在最精细分辨率下的计算效率提高了 4000 倍,从而首次能够逐像素建模高分辨率图像。
长序列建模
之前大多数关于逐像素生成的研究都将问题表述为长序列建模,并利用语言建模的方法来解决。与这些方法不同,研究者将此类数据视为由多个元素组成的集合(而不是序列),并采用分而治之的策略以递归方式对具有较少元素的较小子集进行建模。
这种方法的动机是观察到大部分数据都呈现出了近乎分形的结构。图像由子图像组成,分子由子分子组成,生物神经网络由子网络组成。因此,设计用于处理此类数据的生成模型应该由本身就是生成模型的子模块组成。
实验结果
本文在 ImageNet 数据集上进行了实验,图像分辨率分别为 64×64 和 256×256。评估包括无条件和类条件图像生成,涵盖模型的各个方面,如似然估计、保真度、多样性和生成质量。
因此,本文报告了负对数似然(NLL)、Frechet Inception Distance(FID)、Inception Score(IS)、精度(Precision)和调回率(Recall)以及可视化结果,以全面评估分形框架。
似然估计。 本文首先在无条件 ImageNet 64×64 生成任务上进行了评估,以检验其似然估计能力。为了验证分形框架的有效性,本文比较了不同分形层级数量下框架的似然估计性能,如表 2 所示。

再来看生成质量评估。 研究者在分辨率为 256×256 的类条件图像生成这一挑战性任务上,使用四个分形级别对 FractalMAR 进行了评估。指标包括了 FID、Inception Score、精度和召回率,具体如下表 4 所示。

值得注意的是,本文方法实现了强大的 Inception Score 和精度,表明它能够生成具有高保真度和细粒度细节的图像,如下图 4 所示。

最后是条件逐像素预测评估。
研究者进一步使用图像编辑中的常规任务来检验本文方法的条件逐像素预测性能。下图 5 提供了几个具体示例,包括修复、去除修复、取消裁剪和类条件编辑。
结果显示,本文方法可以根据未遮蔽区域来准确预测被遮蔽的像素,还可以有效地从类标签中捕获高级语义并将其反映在预测像素中。

