OpenAI的GPT-4o图像生成原理引发热议,研究者猜测其可能采用“自回归+扩散”或“非扩散自回归”模型,但具体实现仍是谜。
原文标题:GPT-4o图像生成的秘密,OpenAI 没说,网友已经拼出真相?
原文作者:机器之心
冷月清谈:
* **自回归+扩散:** 该猜想认为GPT-4o首先生成视觉token,然后通过扩散模型将其解码为像素空间,类似于先生成模糊草图再逐步细化。有研究者认为GPT-4o使用了类似于Rolling Diffusion的分组扩散解码器,从上到下进行解码。
* **非扩散的自回归生成:** 另一种观点认为,GPT-4o像文本生成一样,按顺序逐个流式传输图像token,从图像顶部开始生成。这种方式的关键在于它不需要一次性生成整个图像,而是利用模型权重中嵌入的知识,逐步生成更连贯的图像。
此外,文章还提到一些研究者通过分析GPT-4o生成图像过程中的中间图像,发现图像是从上到下生成的,并且早期生成的像素在后续生成中可能会发生显著变化,这可能表明模型采用了某种连贯性优化。尽管有各种猜测,但GPT-4o图像生成的真正实现方式仍有待OpenAI官方揭晓。
怜星夜思:
2、文章提到GPT-4o在生成图像时会先出现上半部分,你觉得这是技术限制还是设计上的考虑?
3、如果让你来设计下一代图像生成模型,你会考虑哪些创新点?
原文内容
自从 OpenAI 发布 GPT-4o 图像生成功能以来,短短几天时间,我们眼睛里看的,耳朵里听的,几乎都是关于它的消息。
不会 PS 也能化身绘图专家,随便打开一个社交媒体,一眼望去都是 GPT-4o 生成的案例。
比如,吉卜力画风的特朗普「积极坦诚对话」泽连斯基:

然而,OpenAI 一向并不 Open,这次也不例外。他们只是发布一份 GPT-4o 系统卡附录(增补文件),其中也主要是论述了评估、安全和治理方面的内容。

地址:https://cdn.openai.com/11998be9-5319-4302-bfbf-1167e093f1fb/Native_Image_Generation_System_Card.pdf
对于技术,在这份长达 13 页的附录文件中,也仅在最开始时提到了一句:「不同于基于扩散模型的 DALL・E,4o 图像生成是一个嵌入在 ChatGPT 中的自回归模型。」
OpenAI 对技术保密,也抵挡不住大家对 GPT-4o 工作方式的热情,现在网络上已经出现了各种猜测、逆向工程。
比如谷歌 DeepMind 研究者 Jon Barron 根据 4o 出图的过程猜测其可能是组合使用了某种多尺度技术与自回归。
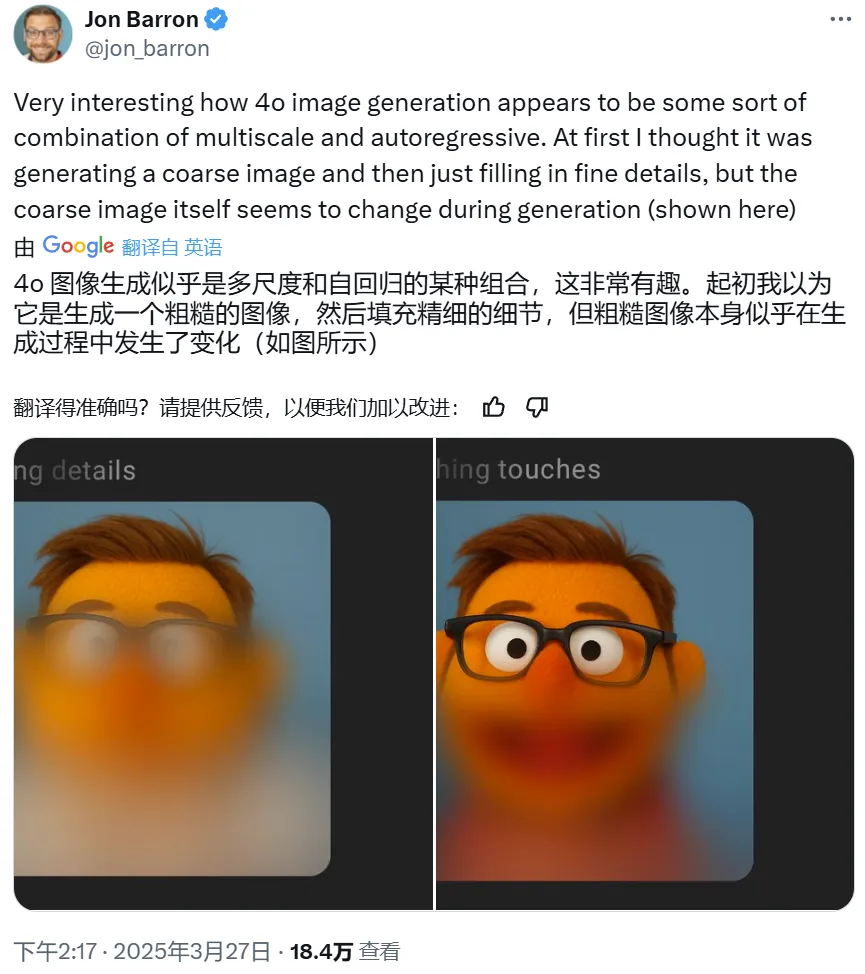
不过,值得一提的是,香港中文大学博士生刘杰(Jie Liu)在研究 GPT-4o 的前端时发现,用户在生成图像时看到的逐行生成图像的效果其实只是浏览器上的前端动画效果,并不能准确真实地反映其图像生成的具体过程。实际上,在每次生成过程中,OpenAI 的服务器只会向用户端发送 5 张中间图像。您甚至可以在控制台手动调整模糊函数的高度来改变生成图像的模糊范围!

因此,在推断 GPT-4o 的工作原理时,其生成时的前端展示效果可能并不是一个好依据。
尽管如此,还是让我们来看看各路研究者都做出了怎样的猜测。整体来说,对 GPT-4o 原生图像生成能力的推断主要集中在两个方向:自回归 + 扩散生成、非扩散的自回归生成。下面我们详细盘点一下相关猜想,并会简单介绍网友们猜想关联的一些相关论文。
猜想一:自回归 + 扩散
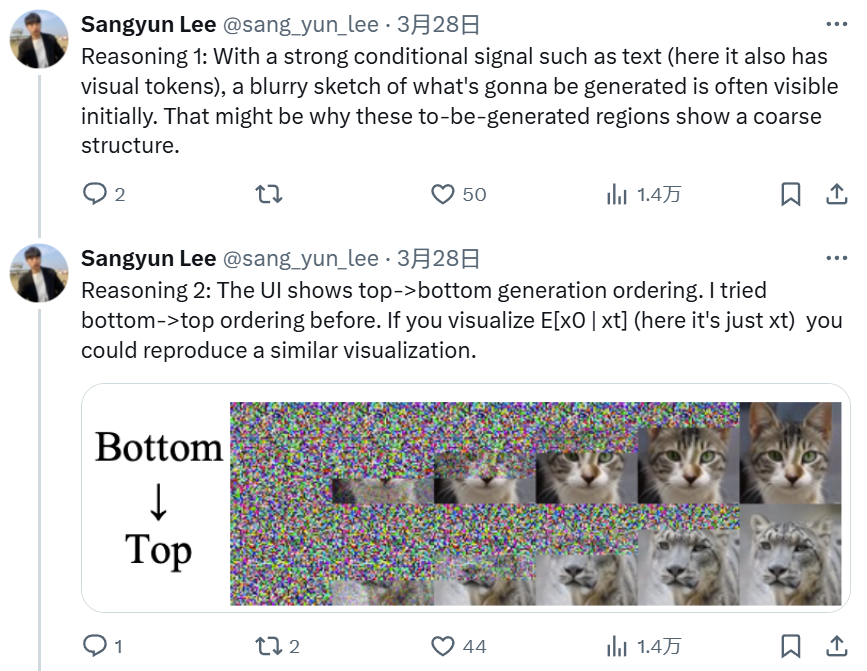
很多网友猜想 GPT-4o 的图像生成采用了「自回归 + 扩散」的范式。比如 CMU 博士生 Sangyun Lee 在该功能发布后不久就发推猜想 GPT-4o 会先生成视觉 token,再由扩散模型将其解码到像素空间。而且他认为,GPT-4o 使用的扩散方法是类似于 Rolling Diffusion 的分组扩散解码器,会以从上到下的顺序进行解码。

他进一步给出了自己得出如此猜想的依据。
-
理由 1:如果有一个强大的条件信号(如文本,也可能有视觉 token),用户通常会先看到将要生成的内容的模糊草图。因此,那些待生成区域会显示粗糙的结构。
-
理由 2:其 UI 表明,图像是从顶部到底部生成的。Sangyun Lee 曾在自己的研究中尝试过底部到顶部的顺序。
Sangyun Lee 猜想到,这样的分组模式下,高 NFE(函数评估数量)区域的 FID 会更好一些。但在他研究发现这一点时,他只是认为这是个 bug,而非特性。但现在情况不一样了,人们都在研究测试时计算。
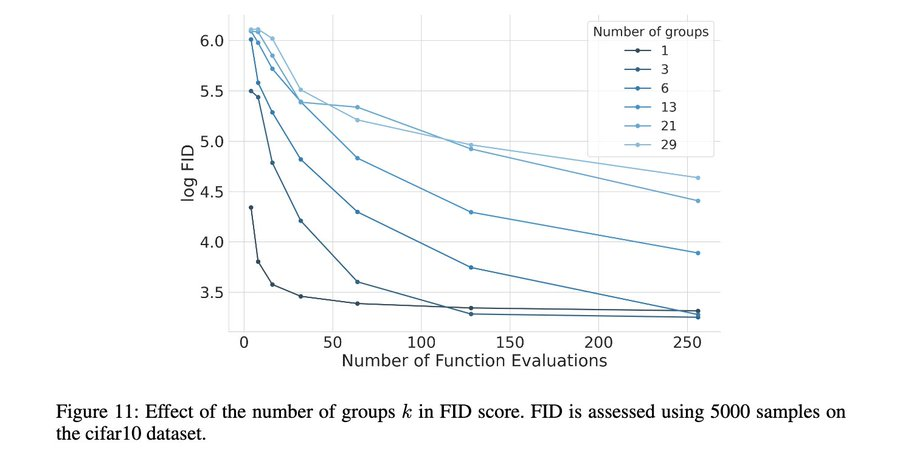
最后,他得出结论说:「因此,这是一种介于扩散和自回归模型之间的模型。事实上,通过设置 num_groups=num_pixels,你甚至可以恢复自回归!」
另外也有其他一些研究者给出了类似的判断:

如果你对这一猜想感兴趣,可以参看以下论文:
-
Rolling Diffusion Models,arXiv:2402.09470;
-
Sequential Data Generation with Groupwise Diffusion Process, arXiv:2310.01400
-
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model,arXiv:2408.11039
猜想二:非扩散的自回归生成
使用过 GPT-4o 的都知道,其在生成图像的过程中总是先出现上半部分,然后才生成完整的图像。
Moonpig 公司 AI 主管 Peter Gostev 认为,GPT-4o 是采用从图像的顶部流 token 开始生成图像的,就像文本生成方式一样。

来源:https://www.linkedin.com/feed/update/urn:li:activity:7311176227078172674/
Gostev 表示,与传统的图像生成模型相比,GPT-4o 图像生成的关键区别在于它是一个自回归模型。这意味着它会像生成文本一样,按顺序逐个流式传输图像 token。相比之下,基于扩散过程的模型(例如 Midjourney、DALL-E、Stable Diffusion)通常是从噪声到清晰图像一次性完成转换。

这种自回归模型的主要优势在于,模型不需要一次性生成整个全局图像。相反,它可以通过以下方式来生成图像:
-
利用其模型权重中嵌入的通用知识;
-
通过按顺序流式传输 token 来更连贯地生成图像。
更进一步的,Gostev 认为,如果你使用 ChatGPT 并点击检查(Inspect),然后在浏览器中导航到网络(Network)标签,就可以监控浏览器与服务器之间的流量。这让你能够查看 ChatGPT 在图像生成过程中发送的中间图像,从而获得一些有价值的线索。
Gostev 给出了一些初步的观察结果(可能并不完整):
-
图像是从上到下生成的;
-
这个过程确实涉及流 token,与扩散方法截然不同;
-
从一开始,就可以看到图像的大致轮廓;
-
先前生成的像素在生成过程中可能会发生显著变化;
-
这可能表明模型采用了某种连贯性优化,尤其是在接近完成阶段时更加明显。
最后,Gostev 表示还有一些无法直接从图像中看到的额外观察结果:
-
对于简单的图像生成,GPT-4o 速度要快得多,通常只有一个中间图像,而不是多个。这可能暗示使用了推测解码或其他类似方法;
-
图像生成还具备背景移除功能,从目前的情况来说,最初 GPT-4o 生成图片会呈现一个假的棋盘格背景,直到最后才移除实际背景,这会略微降低图像质量。这似乎是一个额外的处理过程,而不是 GPT-4o 本身的功能。
开发者 @KeyTryer 也给出了自己的猜想。他说 4o 是一种自回归模型,通过多次通过来逐像素地生成图像,而不是像扩散模型那样执行去噪步骤。
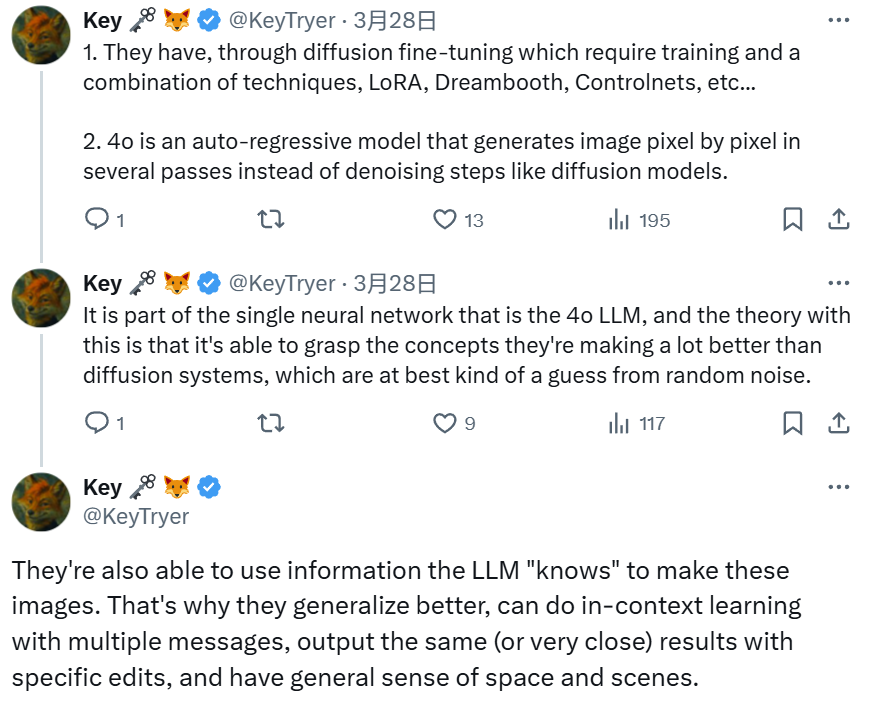
而这种能力本身就是 GPT-4o LLM 神经网络的一部分。理论上讲,它能够比扩散系统更好地掌握它们正在操作的概念,而扩散系统只是对随机噪声的一种猜测。
GPT-4o 还能够使用 LLM「知道」的信息来生成图像。也因此,它们具有更好的泛化能力,能够使用多条消息进行上下文学习,通过特定的编辑输出相同(或非常接近)的结果,并且具有广义的空间和场景感。
芬兰赫尔辛基的大学副教授 Luigi Acerbi 也指出,GPT-4o 基本就只是使用 Transformer 来预测下一个 token,并且其原生图像生成能力一开始就有,只是一直以来都没有公开发布。
不过,Acerbi 教授也提到,OpenAI 可能使用了扩散模型或或一些修饰模型来为 GPT-4o 生成的图像执行一些清理或添加小细节。
GPT-4o 原生图像生成功能究竟是如何实现的?这一点终究还得等待 OpenAI 自己来揭秘。对此,你有什么自己的猜想呢?
参考链接
https://x.com/karminski3/status/1905765848423211237
https://x.com/iScienceLuvr/status/1905730169631080564
https://x.com/AcerbiLuigi/status/1904793122015522922
https://x.com/Hesamation/status/1905762746056278278
https://x.com/jie_liu1/status/1905761704195346680
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com