Adobe 提出 ObjectMover 模型,结合视频扩散模型和虚幻引擎数据,实现图像中物体的真实感移动、删除和插入,显著提升编辑质量和真实感。
原文标题:Adobe黑科技:视频扩散降维图像编辑,ObjectMover秒懂物理规律
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 ObjectMover 将物体移动任务视为序列到序列的预测任务,这具体是怎么实现的?为什么这种方法能够提升编辑的真实感?
3、ObjectMover 在处理透明物体(如酒杯)的移动时,表现出了对材质的深入理解。这种理解是如何实现的?对其他图像编辑任务有什么启发?
原文内容

论文第一作者为余鑫,香港大学三年级博士生,通讯作者为香港大学齐晓娟教授。主要研究方向为生成模型及其在图像和 3D 中的应用,发表计算机视觉和图形学顶级会议期刊论文数十篇,论文数次获得 Oral, Spotlight 和 Best Paper Honorable Mention 等荣誉。此项研究工作为作者于 Adobe Research 的实习期间完成。
近年来,图像生成与编辑技术的快速发展,特别是扩散模型(Diffusion Models)的兴起,使得图像编辑任务取得了显著进展。然而,现有技术在实现图像中物体的移动、插入和移除时,仍存在诸多问题:比如物体在新位置的光照与阴影无法与环境真实协调,物体身份特征发生失真,以及物体移动产生的空缺区域无法自然地补全。这些问题在复杂的真实场景中尤为突出。
为解决上述难题,Adobe 联合香港大学提出了一种新型图像编辑模型 ——ObjectMover。该模型首次结合视频扩散模型(Video Diffusion Model)的强大先验知识,并创新性地使用虚幻引擎(Unreal Engine)合成数据进行训练,从而实现单张图像内物体的真实感移动。


-
论文题目:ObjectMover: Generative Object Movement with Video Prior
-
论文链接:https://arxiv.org/abs/2503.08037
-
项目主页:https://xinyu-andy.github.io/ObjMover
实验结果与效果分析
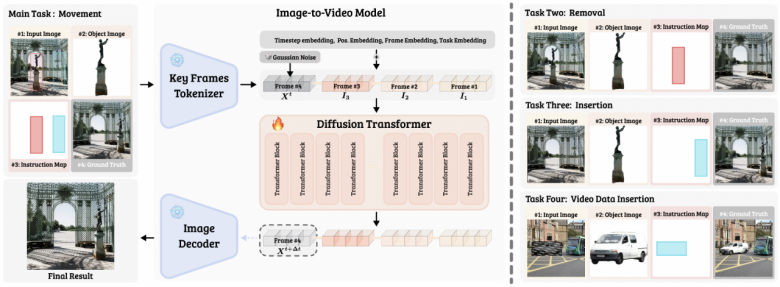
ObjectMover 可统一地处理图像编辑中的三个常见任务:物体移动、物体删除与物体插入。与以往方法不同的是,本文仅需用户使用边界框(Bounding Box)指定待编辑的物体及目标位置,无需额外标注(如文本指令或阴影标注),模型即可自动同步处理相关的物理效果(例如阴影、反射等)。
真实感的光影同步调整
如下图所示,当移动水中人物时,ObjectMover 能够自动同步调整水中倒影,并识别并调整人物身上的太阳光,使太阳光准确地照射在水面。

再例如下面这个异常困难的具有复杂阴影的例子。当雕像被移动后,其投射在地上的影子也被同步移动。需要注意的是,模型能够识别哪一部分阴影属于雕像,而不会移除其他物体的影子,并且还能补全之前被雕像阴影覆盖的其他物体的阴影。此外,移动后雕像呈现出的透视角度也会随位置变化而自然调整,且雕像背部原先被遮挡的区域自然地被新位置的太阳光照射。

此外,模型还能有效理解物体的材质特性。例如,下图展示了透明酒杯移动的实例。当透明酒杯被移动后,模型不会简单地复制酒杯原位置上透视看到的背景内容,而是精确地去除背景,仅保留酒杯自身的透明材质属性。当酒杯被移动至新位置时,模型又能准确地透过酒杯重新生成与目标位置环境一致的新背景内容。这充分体现了模型对透明物体材质的深入理解。同时,模型还能够自动补全原本不完整的酒杯杯体,生成完整的物体外观。

综上,ObjectMover 不仅实现了物体位置的简单变化,更表现出显著的物理规律理解能力。
多任务处理,一个统一模型
得益于统一的条件输入框架和多任务训练机制,ObjectMover 还能有效完成物体删除与插入任务。如图所示,删除任务中,模型能够真实地填充被移除物体的背景,而非生成不相干的新物体,并准确地移除光影;而在插入任务中,模型能精准保持被插入物体的身份特征,自动生成与环境一致的光影效果。


实验对比
实验结果表明,ObjectMover 在物体移动、删除和插入三个任务中均取得了明显优于现有方法的图像质量与真实感。

研究方法与主要创新点
将视频扩散模型用于单帧图像编辑任务
传统图像编辑方法一般微调单帧图像扩散模型,这些模型的预训练阶段仅关注单张图像,没有学习到物体动态变化过程中的光影调整。而本文提出的核心创新在于,将物体移动任务视为序列到序列(Sequence-to-Sequence)的预测任务,首次应用了预训练的视频扩散模型。
具体而言,本文通过将输入图像、待移动物体、用户指令与目标位置统一编码为视频序列形式,以不改变模型原架构的前提下直接进行微调,充分利用了视频模型预训练时习得的物理规律及物体对应关系(Object Correspondence),从而在图像编辑任务中实现了精确的光影同步与身份特征保持。
首个利用虚幻引擎(Unreal Engine)生成合成数据进行图像编辑训练
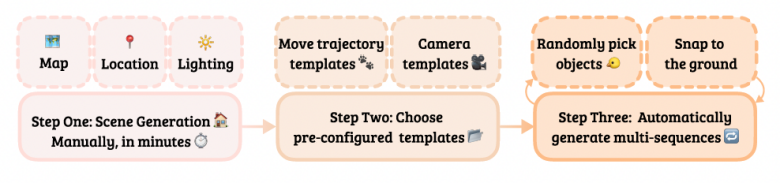
由于真实环境中难以获取大规模精准标注的物体移动数据,传统方法多依赖人工标注或数据改造,存在数据量不足和质量限制。为此,本文首次利用虚幻引擎生成了丰富、高质量的合成数据集,涵盖了复杂的光照环境、多样的物体类型及真实的物体与环境交互。

通过合成数据,本文得以模拟现实世界中多样的物体移动场景,例如光照强弱变化、物体透视变化及遮挡区域真实补全效果等。此外,本文设计了多种移动轨迹与光照条件,确保模型学习到高度泛化的视觉先验。
实验结果证明,虚幻引擎生成的数据与视频预训练模型的结合,有效提高了模型在真实图像编辑任务中的泛化能力。同时,本文提出了基于真实视频与合成数据的多任务训练策略,进一步增强模型的泛化表现。