传神语联发布任度双脑深度思考大模型T1,以9B参数实现媲美千亿参数模型的性能,强调自主可控和深度思考能力,已在多领域落地应用。
原文标题:用 9B 参数做推理?任度双脑深度思考大模型 T1 发布,创始人:和大厂 PK 的底气来自“根原创”
原文作者:AI前线
冷月清谈:
怜星夜思:
2、文章提到任度大模型T1在解决问题时能够进行结构化思考,并以图形化方式展示结果。这种能力在实际应用中能带来哪些具体价值?
3、传神语联推出双脑一体机,同时融合了自研的9B模型和DeepSeek的671B模型,企业应该如何选择适合自己的大模型方案?
原文内容

近日,传神语联重磅发布了任度双脑深度思考大模型 -T1(以下简称任度大模型 -T1),为大模型领域贡献了又一创新性成果。
在大模型层出不穷的今天,传神语联为什么还执着于推出大模型?底气来自哪里?发布当天,传神语联创始人何恩培、传神语联研究院院长何征宇通过一场深度对话带来了上述问题的答案。
何恩培: 我们并非刚刚入局。早在 GPT 火起来之前,我们已经在法律、语言服务等领域研究和应用大模型技术。去年 5 月份,OpenAI 的 Sam Altman 提到在 GPT5、GPT6 中将数据和推理做分离,这一点还是刺激了我,因为我们已经实现了技术,我觉得还应该更自信一点站出来。因为我们主要 TOB,没有做过什么公开发布,于是我们在 2024 年 11 月正式发布了任度双脑大模型。最新的深度思考版本 T1 早在 2 月就出来了,只是在传神 A 纪元一周年向大家公开发布,进一步巩固我们在大模型领域的技术优势。
何恩培: 准确的说我们的底气来自根原创,这是我们过去、现在以及未来所有创新的基石和底气。我们从底层算法框架到模型架构,完全自主研发,且通过了中国信通院 0 开源依赖的验证,做到了完全独立自主。当然更重要的是“根原创”技术还做到了“更先进”,我们一次次走在大模型时代的前列,验证了我们的技术先进性,这才是真正的底气。
当然,数推分离是我们的大模型的架构设计。基于数推分离架构,任度大模型 -T1 实现了“双脑”联合推理,以仅 9B 的小参数规模实现了大智能,性能可媲美参数量为其几十倍,甚至一两百倍的大模型。同时,基于此架构,我们的大模型成长出了实时学习、长效记忆能力,可以实现数据不离场(私域)、无需专业技术人员情况下与企业数据深度融合,并可以持续实时学习客户新数据。
何征宇: 任度大模型 -T1 在继承任度双脑大模型实时学习、长效记忆、高性参比等核心能力的基础上,实现了在深度思考、高效能等多维度上的新突破,解决了当前 AI 如何具备真正的结构化思考能力、如何降低模型部署能耗和成本、如何确保数据安全与可控等诸多行业问题,是企业数字化转型的理想选择。
总结来说,任度大模型 -T1 依托自研的 zANN 神经网络架构,做到像人类一样深度理解并处理信息,实现复杂逻辑推理和抽象思考。
结构化思考:推理更透明、更高效。任度大模型 -T1 能够将复杂问题分解为多个逻辑清晰的步骤,并逐步分析和解决。其思考过程更加透明和可解释,不再是难以理解的“流水账”形式。例如,在解决数学问题时,任度大模型 -T1 会从问题分析、已知信息提取、列方程组到最终求解,每一步都清晰可见。不仅让用户更容易理解模型的推理过程,还显著提升了问题解决的效率和准确性。

图:任度双脑 -T1-9B 与 600B+ 开源大模型的结构化思考能力对比
智能判断:简单问题直接解决,复杂问题深度思考。任度大模型 -T1 能够自动识别问题的复杂度。对于简单问题,直接给出答案,避免了不必要的深度思考过程。例如,当被问及“hello”是什么意思时,任度大模型 -T1 会直接给出答案,而不会启动复杂的深度思考流程。相比之下,不少大模型即使面对简单问题,仍然会进行复杂的思考过程,效率低、能耗高。
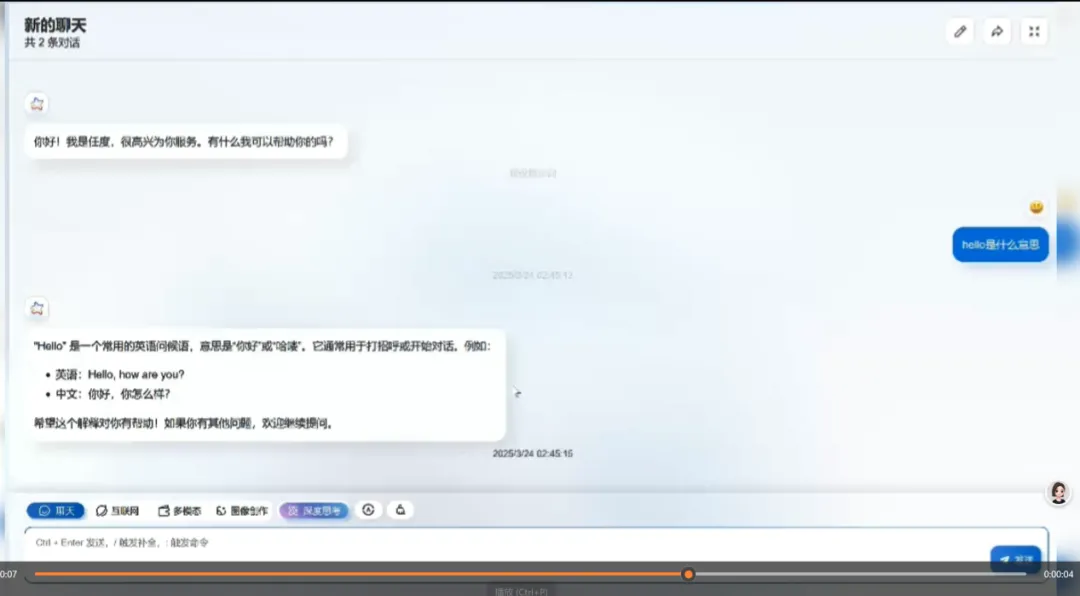
图:任度双脑 -T1-9B 智能判断演示图
图形化展示:直观清晰,易于理解。任度大模型 -T1 在输出结果时,采用了图形化展示的方式,让复杂的信息更加直观和易于理解。例如,当被要求分析水分子和二氧化碳分子的关系时,任度大模型 -T1 会直接以图示的方式呈现,不仅让用户一目了然,还显著提升了信息的传达效率,而不少大模型只能以代码或文字形式进行描述。
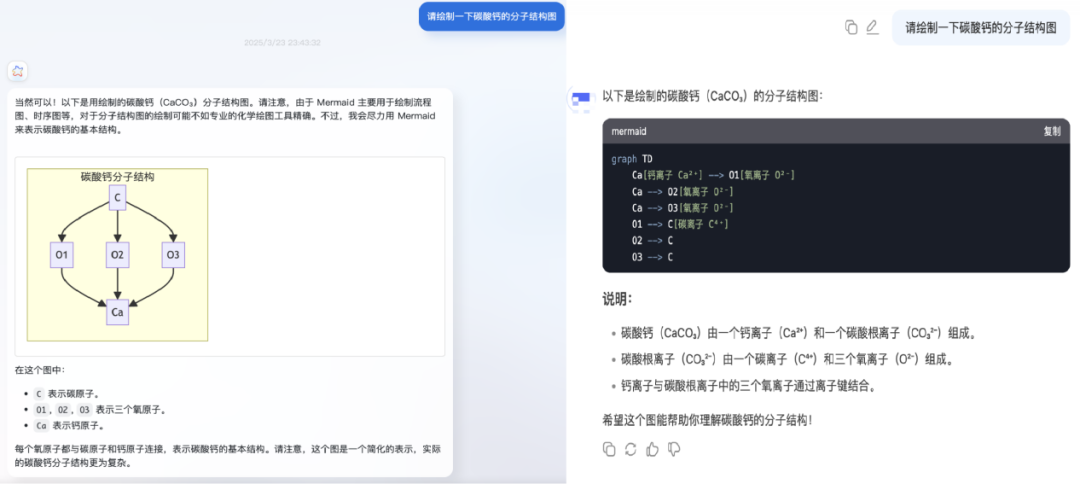
图:任度双脑 -T1-9B 与 600B+ 开源大模型结构化图形展示对比
何恩培: 基于深厚的数据应用能力,任度大模型 -T1 在航天航空、生物医药、金融、法律等多个领域,已经形成了典型案例,展现了强大的数据处理和分析能力。
何恩培:AI For Science 是我们重点且擅长的领域,比如我们与全球顶尖的干细胞科学家合作,构建干细胞综合研究大模型,进行干细胞综合研究,并开发面向健康伴侣的端侧小模型——“为能”,将干细胞生物治疗和人工智能有机结合,实现发现 - 诊断 - 分析研究 - 治疗方案全健康链的大模型赋能。
何征宇: 准确的说不是“接入”Deepseek,而是推出了首义任度双脑一体机,深度融合了任度双脑 9B 大模型、DeepSeek-R1 671B 大模型的能力,帮助企业形成知识沉淀 - 分析 - 决策的闭环。我们是从多个角度考虑的。对用户来说,他们有选择使用哪个大模型的自由度。但同时,用户也需要保障自身数据的安全可控。因此,我们推出了双模型一体机,这样一来,敏感数据层使用任度大模型,应用层则可以选择 DeepSeek 或其他大模型,确保数据安全和业务灵活性。
何恩培: 在业务定位上,传神有根原创的深度学习框架和模型架构,这非常利于我们向两个方向发展,一个是为科学研究赋能,也就是正在流行的方向 AI For Science,一个是向端侧发展,实现从万物互联到“万脑互联”,让人工智能赋能服务我们生活每个角落。从产业生态上我们正在联合一些原创公司发起原创联盟,向合作伙伴开放技术,共同构建国产原创的 AI 研究和应用生态,通过自主研发和根原创技术,摆脱对国外技术的依赖,确保核心技术的自主可控,为国家构建一个安全、可靠的 AI 生态体系。
任度双脑深度思考大模型 -T1 的发布,不仅是对参数竞赛时代的终结宣言,更是开启 AI"质效革命"新纪元的里程碑。我们坚信,任度双脑深度思考大模型 -T1 将进一步展现出差异化竞争优势,以超强的性能,卓越的深度思考能力,成为企业数字化转型的新质生产力。

