VBench-2.0引领视频生成评测新方向,从“表面真实”迈向“内在真实”,关注物理规律、常识推理等深层能力,推动AI视频生成更进一步。
原文标题:VBench-2.0:面向视频生成新世代的评测框架
原文作者:机器之心
冷月清谈:
AI视频生成技术飞速发展,但仅关注视觉效果的“表面真实性”已不足够。VBench-2.0由南洋理工大学S-Lab和上海人工智能实验室联合推出,旨在评估视频生成的“内在真实性”,包含人体动作与结构、可控性、创造性、物理规律和常识推理五个关键维度。它通过大量精细化测评场景与自动化评估策略,力求评测结果与人的直觉判断保持一致。VBench-2.0已全面开源,研究者可同时使用VBench-1.0与VBench-2.0对模型进行评估,以便更全面地了解模型的实际潜力。评估结果显示,开源与闭源模型各有亮点,技术进步依赖社区共建。VBench-2.0不仅评估模型,更重要的是发现问题,为下一代视频生成模型发展提供洞见,也为不同需求提供模型选择建议,并指出基础动作和属性变化,故事级长文本引导生成有待突破,平衡文本优化器与创造力是挑战。VBench-2.0引导我们从更全面的角度来认识与衡量模型。
怜星夜思:
1、VBench-2.0 强调的“内在真实性”对视频生成的未来发展有哪些更深远的影响?除了文中提到的几个维度,你觉得还有哪些因素可以纳入考量?
2、文章提到“平衡文本优化器(Prompt Refiner)与创造力”是一个挑战。你认为有哪些方法可以解决这个问题,既能保证视频质量,又能激发AI的创造力?
3、文章提到目前模型在处理基础动作和属性变化上存在短板,你认为造成这一现象的原因是什么?除了文中提到的解决方法,你还有什么其他的建议?
2、文章提到“平衡文本优化器(Prompt Refiner)与创造力”是一个挑战。你认为有哪些方法可以解决这个问题,既能保证视频质量,又能激发AI的创造力?
3、文章提到目前模型在处理基础动作和属性变化上存在短板,你认为造成这一现象的原因是什么?除了文中提到的解决方法,你还有什么其他的建议?
原文内容

近一年以来,AI 视频生成技术发展迅猛。自 2024 年初 Sora 问世后,大家惊喜地发现:原来 AI 可以生成如此逼真的视频,一时间各大高校实验室、互联网巨头 AI Lab 以及创业公司纷纷入局视频生成领域。
闭源模型(如 Kling、Gen、Pika)在视觉效果方面令人惊叹,近期也有 HunyuanVideo、Wanx 等完全开源的模型在 VBench 榜单上表现出色,让我们看到了社区在推动技术革新上的无限潜力。
然而,当大家都在惊呼「视觉效果太牛了」的同时,难免会产生新的思考:视频生成的下一步究竟该往哪里走?表面逼真度真的就代表一切吗?还能有哪些更深层次的能力值得我们深挖?
从「表面真实性」到「内在真实性」
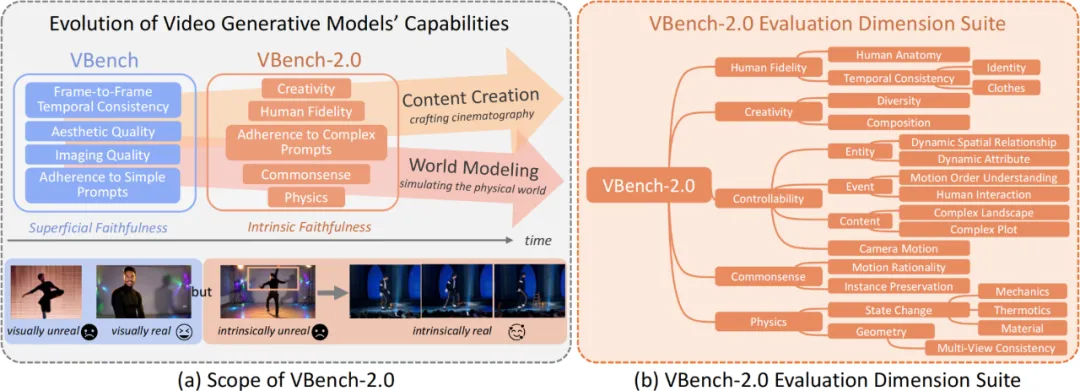
初代 VBench 作为业内权威的视频生成评测体系,主要关注视频的视觉观感,例如每一帧的清晰度、帧与帧之间的平滑衔接,以及视频和文本描述间的基本一致性。这些要素也被称为表面真实性(Superficial Faithfulness),它解决了视频「看起来是否逼真」和「好不好看」的问题,并为现阶段模型提供了统一衡量标尺。
然而,要让视频生成真正迈向更高层次的应用——例如 AI 辅助电影制作、复杂场景模拟等,就不仅需要视频「看起来逼真」,更需要它具备对物理规律、常识推理、人体解剖、场景组合等世界模型(World Model)层面的深度理解,也就是内在真实性(Intrinsic Faithfulness)。只有能够遵循现实世界规则的模型,才有可能在长剧情、复杂动作和内容创作中更具潜力。
VBench-2.0:向「内在真实性」进发
为引领视频生成技术从表面逼真迈向内在逼真,南洋理工大学 S-Lab 和上海人工智能实验室联合推出 VBench-2.0。

-
论文标题:VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
-
论文链接:https://arxiv.org/abs/2503.21755
-
视频:https://www.youtube.com/watch?v=kJrzKy9tgAc
-
代码:https://github.com/Vchitect/VBench
-
网页:https://github.com/Vchitect/VBench-2.0-project
在继承 VBench-1.0 对「表面真实性」关注的同时,VBench-2.0 更强调以下关键评测维度:
-
Human Fidelity(人体动作与结构)
关注做体操时动作是否连贯、角色动作是否合乎人体解剖常识等。
-
Controllability(可控性)
考察模型能否精确地执行用户给出的指令,例如相机运动、人物位置等微调效果。
-
Creativity(创造性)
观察模型在场景组合和故事情节拓展等方面的想象力。
-
Physics(物理规律)
浮力、重力、碰撞效果是否合理?模型能否生成符合物理定律的动作或场景变化?
-
Commonsense(常识推理)
在日常情景或逻辑推断中是否展现出合理性,例如「吃东西」时,食物是否真的进入了口中,角色行为是否合乎常理等。
VBench-2.0 针对以上维度提出了大量的精细化测评场景与自动化评估策略,其中包含通用的多模态模型(VLMs、LLMs)及在特定领域表现优异的「专家」方法(如针对人体异常动作的检测)等。为了确保评测结果的可靠性,我们与真实人类打分结果进行了大规模对照,力求让自动评测与人的直觉判断保持一致。
-
分层与解耦的 18 个评测维度
-
开源 Prompt List 体系
-
与人类观感对齐的自动评测
-
多视角观察助力下一代视频生成
在下面这些常被网友吐槽的场景中,模型往往暴露了缺乏「内在真实度」的短板。VBench-2.0 能系统地评判这些一直被网友诟病的视频生成模型的缺陷,而且很准哦!
VBench 评测体系:双剑合璧,覆盖更全面
-
VBench-1.0:适用于评估视频生成的「表面真实性」,如视觉质量、文本匹配与整体流畅度等。在现阶段为各家模型的进步提供了强力支持。
-
VBench-2.0:在保留 VBench-1.0 优势的同时,进一步聚焦视频的「内在真实性」。当我们想真正判断一个模型有没有「世界模型」,能否用在更深层次的创作和应用场景时,VBench-2.0 的评测就尤为关键。
我们建议研究者同时使用 VBench-1.0 与 VBench-2.0 对模型进行评估:前者能直观地衡量视频的视觉效果和基础一致性,后者则深入探讨模型在物理、常识、复杂行为等领域的表现,帮助你更好地理解模型的实际潜力。
现有模型表现:开源与闭源,皆有亮点
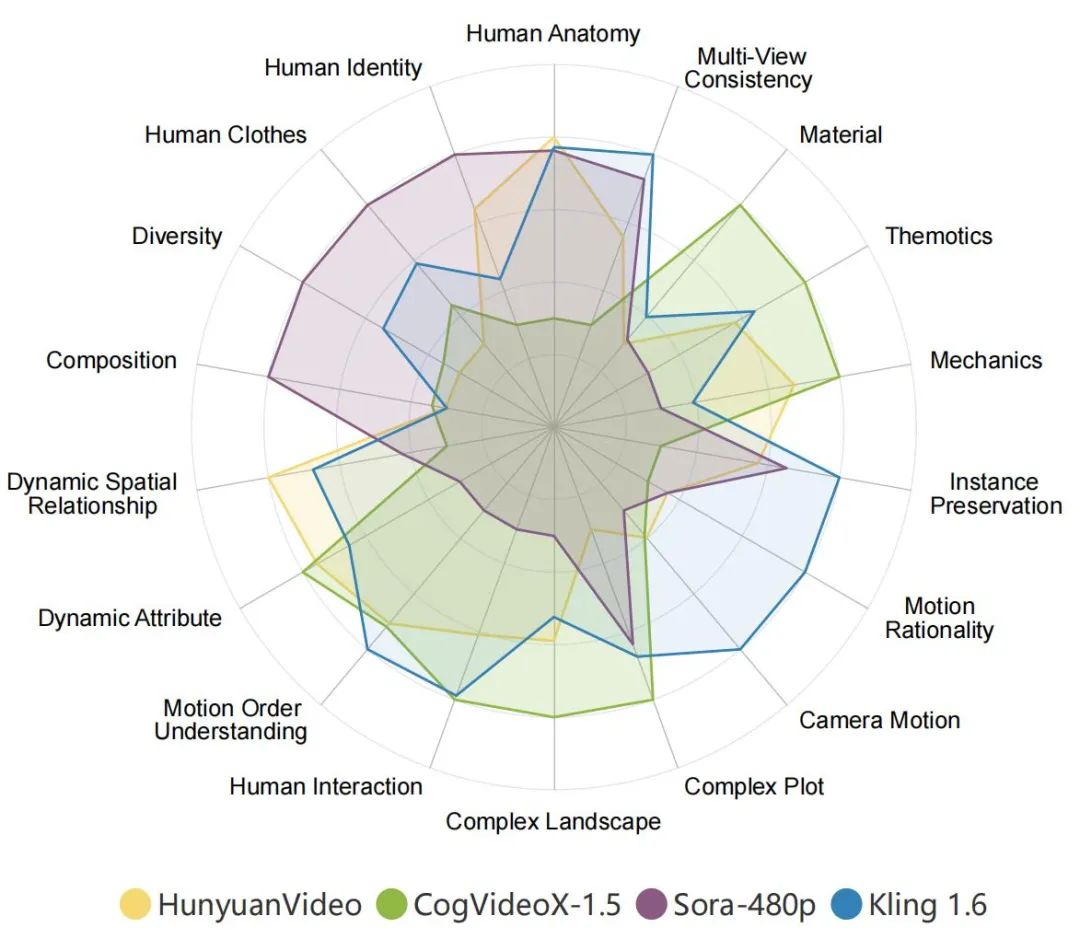
各家 AI 视频生成模型在 VBench-2.0 上的表现。在雷达图中,为了更清晰地可视化比较,我们将每个维度的评测结果归一化到了 0.3 与 0.8 之间。
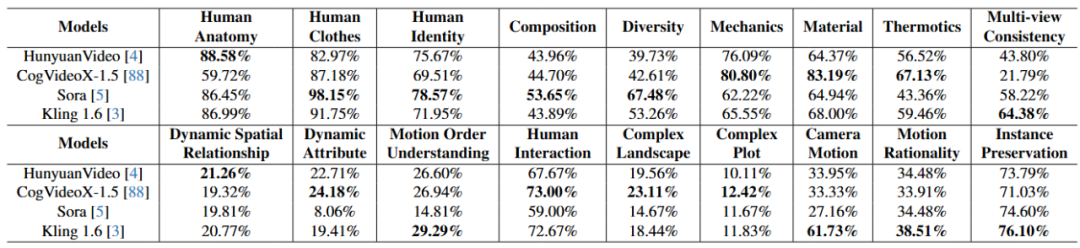
各家AI 视频生成模型在 VBench-2.0 上的表现。
在 VBench-2.0 的「内在真实性」评测中,并未出现明显的「开源或闭源即占绝对优势」的现象。很多社区开源项目在复杂场景中表现得并不比商用闭源模型差,说明技术进步依赖社区共建是完全可行的。
全面开源,欢迎加入社区,共同推动视频生成新未来
VBench-2.0 已全面开源,让你可以轻松测试并对比感兴趣的模型。我们也非常期待你在实际使用中的反馈与建议,共同助力 AI 视频生成生态的成长和进化。
我们也开源了一系列 Prompt List:https://github.com/Vchitect/VBench/tree/master/VBench-2.0/prompts

左边词云展示了我们 Prompt Suites 的高频词分布,右图展示了不同维度的 prompt 数量统计。无论你是模型研发者、应用开发者,或对前沿技术感兴趣的爱好者,都欢迎加入我们的行列,携手探索视频生成从「看起来很真」到「本质上真」的精彩进化。让我们一起,让下一代视频生成模型更具想象力,也更贴近真实世界!
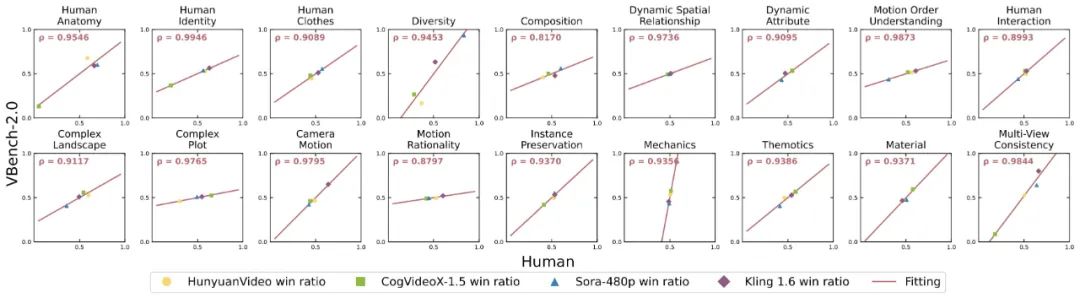
VBench-2.0 准不准?
针对每个维度,我们计算了 VBench-2.0 评测结果与人工评测结果之间的相关度,进而验证我们方法与人类观感的一致性。
下图中,横轴代表不同维度的人工评测结果,纵轴则展示了 VBench-2.0 方法自动评测的结果,可以看到我们方法在各个维度都与人类感知高度对齐。
带给视频生成的更多思考
VBench-2.0 不仅可以对现有模型进行评测,更重要的是,还可以发现不同模型中可能存在的各种问题,为下一代视频生成模型的发展提供有价值的洞见。
不同需求,选用不同模型
-
比较天马行空的创意性的生成:Sora
-
想要生成人相关的运动镜头:HunyuanVideo 或者 Kling 1.6
-
想要实现精确的相机控制:Kling 1.6
-
想要生成严格遵从文本指示的视频:CogVideoX-1.5
-
想要模拟基础的物理定律:CogVideoX-1.5
会有全能模型出现吗?蹲守一波 2025 与 2026 年的发展。
基础动作和属性变化仍是短板
我们发现在非常简单的位置移动或者属性变化上,所有模型的效果都不好,这说明现在的模型的训练数据中并没有显式包括位置、属性变化这一类的文本。这可能是 video caption 模型能力上的缺陷。
可能的解决办法包括:
-
用提示词或者 In-context 学习的范式来提示 video caption 模型
-
人工添加部分该类型文本数据
故事级长文本引导生成有待突破
现在主流视频生成时长普遍只有几秒,但未来在电影、动画等更长场景中,如何保持剧情连贯仍是重大挑战。
现在的模型都还不支撑故事级别(5 个连续的小情节)的视频生成,其中最主要的原因是现在的视频生成模型的时长都还在 5-10 秒这个级别,还远远没有到考虑分钟级别的故事叙述。
这将是未来内容、电影创作中非常重要的一个能力。
平衡文本优化器(Prompt Refiner)与创造力
文本优化器有助于提高视频与描述的精确对齐,但也可能抑制模型的多样性输出。如何兼顾高质量与高创造力值得研究者深入探讨。
现在先进的模型都会使用文本优化器来规范或者细粒度化用户的文本输入。但是我们发现使用文本优化器会在一定程度上提高生成的视频的视觉质量,更贴近于文本的描述。但是会在一定程度上影响生成的多样性以及创造力。
因此,如果你想要针对一个文本生成风格差异比较大的视频,在能关闭文本优化器的情况下请关闭它;而如果你想要更高质量、与文本输入更吻合的视频,那么使用文本优化器是更好的选择。
而对于研究者来说,如何构建一个既能提高视频质量,又不会影响其创造力的优化器是一个挑战。
从表面到内核,全面评估
有些模型的 Demo 虽然炫酷,但在物理、逻辑推断或叙事性上仍有不足。正如 VBench-2.0 所强调的「内在真实度」,我们不能只凭第一观感就匆忙下定论。
表面真实性(例如,电影摄影能力)是观看视频时的第一印象,这也是为什么许多人会将高美学评分、高流畅度等特点与优秀模型联系在一起。
然而,情况并非总是如此。内在真实性(例如,叙事能力、世界模拟能力)也是决定一个视频生成模型是否能够在未来应用于真实场景的关键因素。比如 CogVideoX 在 VBench 中的视频质量得分不算最高,视觉体验可能也不如最近一两个月新出的最强模型,但在 VBench-2.0 的许多关注内在真实性(Intrinsic Faithfulness)的维度上表现良好。
由此可见,想要真正评估一个视频生成模型的全方位能力和潜力,单看 Demo 远远不够。VBench-2.0 引导我们从更全面的角度来认识与衡量模型。
进一步了解
我们诚挚邀请所有对视频生成领域感兴趣的研究者与开发者共同参与 VBench 体系的评测(VBench-1.0 和 VBench-2.0),一起探索视频生成从「看起来很真」到「本质上真」的跨越。让我们携手推动下一代视频生成模型在表面与内核上同时进化。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com