深入解析Transformer模型中绝对位置编码、相对位置编码和旋转位置编码(RoPE)的原理与实现,附代码示例。
原文标题:独家 | 深入理解Transformer中的位置编码:从绝对位置编码到旋转位置编码
原文作者:数据派THU
冷月清谈:
1. **绝对位置编码**:通过为每个位置分配唯一的向量来编码序列顺序。分为学习式(如BERT)和固定式(正弦函数)两种。学习式方法简单,但泛化能力有限;固定式方法能处理未见过的序列长度。
2. **相对位置编码**:关注token之间的相对距离,而非绝对位置,更好地泛化到长序列。常用于Transformer-XL等模型,通过在注意力分数中添加相对位置偏差来实现。
3. **旋转位置编码(RoPE)**:结合了绝对和相对位置编码的优点,通过旋转高维空间中的向量来编码位置信息,实现高效且可扩展的位置编码。其核心在于为每个位置生成独特的旋转矩阵,使模型能够捕捉相对位置关系,同时具备处理长序列的能力。
文章还提供了代码示例,展示了如何在RoBERTa和Transformer-XL中实现这些位置编码技术。总结了各种位置编码的优缺点和适用场景,有助于读者深入理解Transformer模型。
怜星夜思:
2、相对位置编码通过引入相对位置偏差来改进注意力机制,那么,这种方法是否会引入新的问题?例如,是否会削弱模型对全局位置信息的捕捉能力?
3、旋转位置编码(RoPE)被认为结合了绝对和相对位置编码的优点,那么,在哪些具体的应用场景中,RoPE会比其他位置编码方式表现更好?
原文内容

作者:Mina Ghashami翻译:陈之炎校对:赵茹萱本文约4500字,建议阅读10分钟
深入解析绝对位置编码、相对位置编码和旋转位置编码的代码示例。
![]()
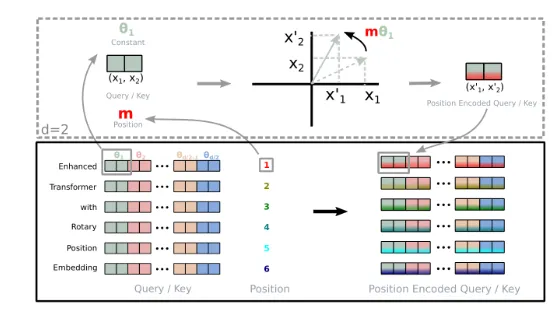
Transformer的核心组件之一是嵌入(embeddings)。你可能会问:为什么?因为Transformer的自注意力机制是置换不变的(permutation-invariant);它会计算序列中每个token相对其他token的注意力权重,但并未考虑token的顺序。实际上,注意力机制将序列视为token的无序集合。为此,需要用到一个称为位置嵌入(positional embedding)的组件,用于编码token的顺序信息并影响其嵌入表示。有哪些不同类型位置嵌入?它们又是如何实现的?
本博将探讨三种类型的位置嵌入,并深入解析其实现方式:
本文目录如下:
1. 背景与上下文
2. 绝对位置嵌入
-
2.1 学习式方法
-
2.2 固定式方法(正弦函数)
-
2.3 代码示例:RoBERTa实现
3. 相对位置嵌入
-
3.1 通俗解释
-
3.2 技术解析
-
3.3 代码示例:Transformer-XL实现
4. 旋转位置嵌入(RoPE)
-
4.1 通俗解释
-
4.2 技术解读
-
4.3 数学证明
-
4.4 高维旋转矩阵
-
4.5 代码片段:Reformer实现
5. 结论
6. 参考文献
1. 背景与上下文
在自然语言处理(NLP)中,序列中词语的顺序对理解语义至关重要,正如人类语言一样。如果打乱了语序,则语义会完全改变。例如:
"Sam坐在垫子上" vs. "垫子坐在Sam上"。
Transformer作为许多系统的核心架构,以并行方式处理所有词语。这种并行性体现在注意力机制中,每个token通过注意力分数与其他token进行语境交互。然而,并行性虽然高效,却会导致模型丢失词语顺序信息。为此,Transformer需要一个额外组件——位置嵌入,为每个token生成包含顺序信息的向量。
位置嵌入有多种类型,主要分为:绝对位置嵌入(Absolute Positional Embedding)、相对位置嵌入(Relative Positional Embedding)和旋转位置嵌入(Rotary Positional Embedding)。
2. 绝对位置嵌入
绝对位置嵌入类似于为每个位置分配唯一编号。在实际项目中,为序列的每个位置生成一个向量。最简单情况下,位置的编码是独热向量(one-hot vector):向量仅在当前token的位置为1,其余位置为0。然后将这些位置嵌入向量与token嵌入相加,再输入Transformer。
例如,句子"I am a student"包含4个token。
每个token获取唯一的位置嵌入向量。假设嵌入维度为3,则:第一个token "I" 的独热编码为[1, 0, 0];第二个token "am" 为[0, 1, 0],依此类推。
尽管独热编码直观体现了位置嵌入的概念,但实际应用中存在更优方法。绝对位置嵌入的简单实现虽有效,但难以处理超长序列或训练时未见过的序列长度。
以下分析具体实现。
实现方式
绝对位置嵌入通过创建一个大小为_vocab_size的查找表来实现,词汇表中的每个token对应查找表中的一个条目,每个条目的维度为_embed_dim。
主要有两类绝对位置嵌入:
2.1. 学习式方法
随机初始化嵌入向量,并在训练过程中更新。原始Transformer及BERT、GPT、RoBERTa等模型均采用此方法。其缺点是泛化能力受限——若序列长度超出训练时的最大位置数,由于在查找表中没有对应选项,模型将无法处理超出的位置。
2.2 固定式方法
此方法(又称正弦位置编码)首次提出于论文《Attention Is All You Need》,该方法利用不同频率的正弦和余弦函数为每个位置生成唯一模式。编码公式如下:
![]()

上述公式中,PE为位置嵌入向量,d为模型嵌入维度,偶数索引由sin函数控制,奇数索引由cos函数控制。
此方法的优势在于能够泛化到训练时未见的序列长度,灵活处理不同规模的输入。
无论是学习式还是固定式,绝对位置嵌入生成后均与token嵌入相加:

![]() 图片由作者提供
图片由作者提供
2.3 代码示例
以RoBERTa模型代码为例展示学习式位置嵌入的实现:
![]()


注意__init__方法中利用下述代码通过随机值初始化学习式位置嵌入:
![]()

在forward方法中,将位置嵌入添加到token嵌入中:
![]()

通过具体输入示例运行代码:
![]()

从配置参数可见:"position_embedding_type": "absolute"最大位置嵌入长度为512("max_position_embeddings": 512)。实例化RobertaEmbedding层:
![]()
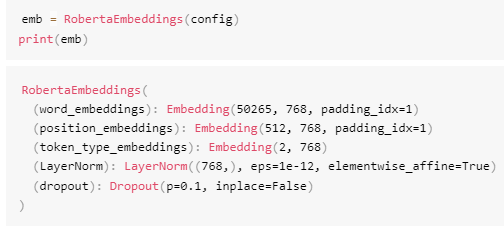
RobertaEmbedding层包含:word_embeddings: 形状为50265×768的嵌入矩阵(词表大小50265,每个嵌入向量768维)。position_embeddings: 为512×768的嵌入矩阵(仅支持512个位置)。若输入序列长度超过512,模型将无法处理超出部分的位置嵌入。
以下通过具体句子测试嵌入层:
![]()

输出如下:
![]()

注意到序列包含12个token,将输入ID传入嵌入层:

![]() 输出为768维张量,包含token嵌入与位置嵌入的和。
输出为768维张量,包含token嵌入与位置嵌入的和。
3. 相对位置嵌入
相对位置嵌入关注token间的相对距离,而非绝对位置。
3.1 通俗解释
在句子"I am a student"中,“I”的实际距离是1,“Student”的实际距离是4,这是token 间的绝对距离。相对位置嵌入是这样考量的,"I"与"student"的相对距离为3,与"am"的相对距离为1。
相对位置嵌入的优势在于更好地泛化到长序列和未见过的序列长度。
采用相对位置嵌入的模型包括:Transformer-XL [1]、T5(Text-To-Text Transfer Transformer)[2]和DeBERTa(Decoding-enhanced BERT with Disentangled Attention)[3]可以查看位置编码具体实现相关的论文。
3.2 技术解析
与绝对位置嵌入不同,相对位置嵌入不直接叠加位置向量,而是创建反映token间相对距离的矩阵。例如,若token i位于位置3,token j位于位置5,则相对位置为2。
相对位置嵌入会修改注意力分数,以包含关于相对位置的信息。在自注意力机制中,注意力分数是根据一对标记之间的位置计算出来的,相对位置嵌入根据相对位置在注意力分数中添加一个偏置项,或者通过为每个可能的相对距离引入一个可学习的嵌入。
这种方法的实现为在注意力得分中添加一个相对位置偏差。如果A是注意力得分矩阵,则添加一个相对位置偏差矩阵Bis:
![]()
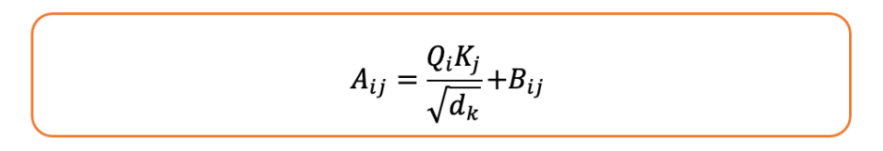
其中,Qij和Ki分别为token i 和token j的“query”值和“key”值,dk是“key”向量的维度,Bi是相对位置j−i的偏置。
3.3 代码示例:Transformer-XL实现
以下PyTorch代码展示了相对位置嵌入的核心实现(简化版),点击这里(github.com),查看代码仓库:
![]()

![]()

利用以下参数调用上述代码:
![]()

seq_len(序列长度)是指输入序列的实际长度,不同批次的seq_len(序列长度)不同。
Max_len(最大长度)是一个预定义值,表示模型相对位置距离的最大值,该值决定了模型嵌入的相对位置范围。如果max_len设置为20,则模型将从-19到19的相对位置实现嵌入。
注意,这也是为什么将self.relative_embeddings=mn.Embedding(2*max len-1,d model)也设置为这个大小,以容纳max_len定义范围内的所有可能相对位置。
代码解读:
如下所示的第一个类为大小为2*max_len-1的嵌入矩阵。在前向函数中,对于给定的序列,它从relative_embeddings矩阵中检索相应的嵌入。
![]()
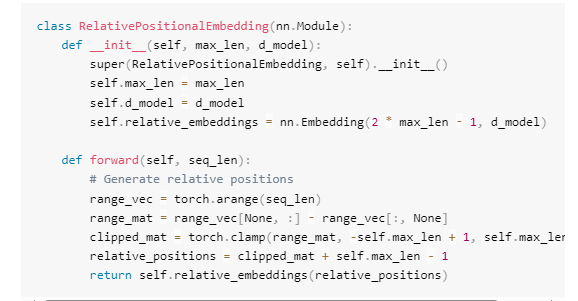
第二个类(即随后一个类)接受一个序列(即x),并计算Query、Key和Value矩阵。注意,每个注意力头都有自己的Q、K和V,这就是为什么这些矩阵的形状都是(batchsize,seq_len,self.numheads, self.d k)。
![]()

Line scores=torch.einsum('bhqd,bhkd->bhqk',Q,K)/(self.d k**0.5)是指定复杂张量操作的符号,它用于计算查询向量和密钥向量之间的点积,等式'bhqd,bhkd->bhqk' 可以解释为:
-
b:批量大小;
-
h:注意力的数量;
-
q:查询序列长度;
-
k:密钥序列长度(通常与自注意力中的查询序列长度的长度相同);
-
d:每个头部的深度(即self.d k)。
Einsum表示法'bhgd,bhkd->bhgk'指定在q和r的最后一个维度之间计算点积,同时保留其他维度。
下一行,rel_pos_embeddings=self.relative_posenbedding(seq_len)检索序列中所有现有相对距离的相对位置嵌入,它是(seq_len,seq_len,dk)。然后将其矩阵转置,将其更改为(d_k,seq_len,seg_len)。下一行rel scores=torch.einsum('bhqddqk->bhqk',Q,rel pos enbeddings)计算相对位置嵌入对自注意力机制中注意力得分的贡献。这就是之前看到的方程中的相对位置偏置矩阵 B。
最后,将矩阵B添加到原始注意力评分中:
![]()

乘以矩阵V的值,得到以下输出:
![]()

4. 旋转位置嵌入(RoPE)
旋转位置嵌入(Rotary Positional Embedding, RoPE)结合了绝对与相对位置嵌入的优点,通过旋转高维空间中的向量编码位置信息,实现位置编码。其核心思想是为每个位置生成唯一的旋转矩阵,使模型能捕获相对位置关系。
4.1 通俗解释
ROPE背后的思想是通过在高维空间中旋转字矢量来编码位置信息,旋转量取决于字或token在序列中的位置。
这种旋转具有一个整洁的数学性质:任何两个单词之间的相对位置可以通过一个单词的向量相对于另一个单词的旋转量来轻松计算。因此,虽然每个单词根据其绝对位置获得旋转量,模型可以轻松计算出相对位置。
ROPE有几个优点:它比绝对位置嵌入更有效地处理长序列,它自然地将绝对位置嵌入和相对位置嵌入二者结合到一起。而且,它计算效率高,易于实现。
4.2 技术解读
给定输入token和该token的位置信息,计算绝对位置嵌入,并将其添加到token嵌入中去:
![]()

图片由作者提供
在旋转位置嵌入中,给定一个token嵌入及其位置,会生成一个包含位置信息的新嵌入:
![]()

图片由作者提供
来看看是如何计算的。简而言之(很快会详细介绍):
给定一个token,ROPE会根据其在序列中的位置对其对应的key和query向量进行旋转,并通过用旋转矩阵乘以向量来实现旋转。使用旋转后的key和query向量以通常的方式(点积后应用softmax)计算注意力分数,照常计算其余的Transformer变量。
来看看什么是旋转矩阵,以及它是如何应用于key和query向量的。
旋转矩阵:二维空间中的旋转矩阵(最简单的情况)如下所示,其中0为任意角度:
![]()
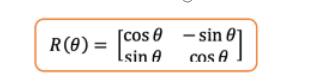
![]() 角的旋转矩阵-图片由作者提供
角的旋转矩阵-图片由作者提供
如果将二维矩阵上乘以一个向量,那么它只是改变了向量的角度,并保持了向量的长度,是这样的吧?
![]()
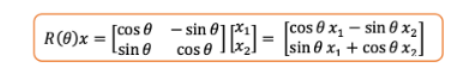
将向量X与旋转矩阵相乘--图片由作者提供
旋转后向量的范数和原始向量一样,来算一算:

旋转后向量的范数和原向量的范数一样--图片由作者提供
又是如何应用于key和query向量的呢?注意,query向量是query矩阵和token嵌入的乘积,即:
![]()

Query 向量---图片由作者提供
将它和旋转矩阵相乘,就是在旋转查询向量。
![]()
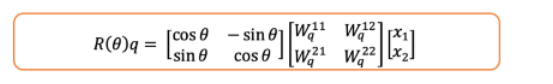
将旋转矩阵和query向量相乘-图片由作者提供
它究竟是如何包括位置信息的呢?
好问题。在所有上面的数学中,假定标记x发生在位置1!如果它发生在任意位置m,那么旋转矩阵将包含m:
当x位于m位置时,将旋转矩阵应用于二维query向量
![]()
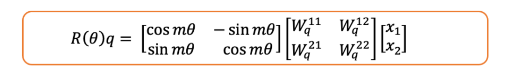
图片由作者提供
4.3 数学证明
接下来,证明旋转位置嵌入(ROPE)的相对性。要做到这一点,首先需要证明两个token之间的注意力得分只取决于它们的相对位置,而不是取决于它们的绝对位置。
1. 按照如下方式定义RoPE函数:
![]()
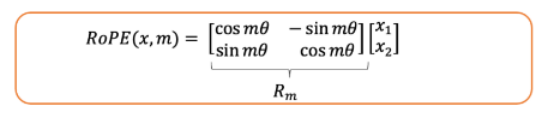
ROPE 函数定义-图片由作者提供
2. 在位置m和位置n 处的两个token
![]()

图片由作者提供
3. 计算二者的点积作为attention 分值
![]()
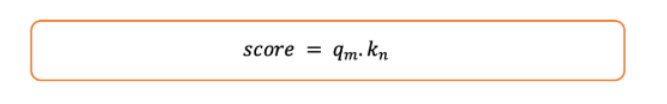
Attention 分值-图片由作者提供
将公式展开如下:
![]()
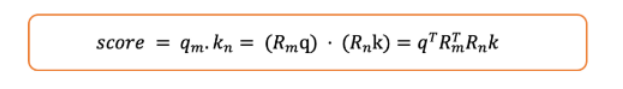
Attention 分值-图片由作者提供
4. 旋转矩阵有如下优良特性
![]()
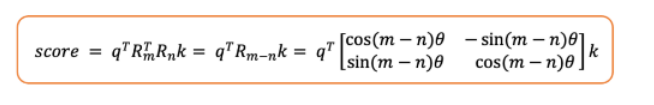
Attention 分值-图片由作者提供
可见,attention分值是相对位置的函数,即m和n之间的位置差。
4.4 高维旋转矩阵
通常情况下,模型的嵌入维度不是2,而是比2大得多。那么旋转矩阵会如何变化?Roformer论文的作者[6]建议如下:
![]()
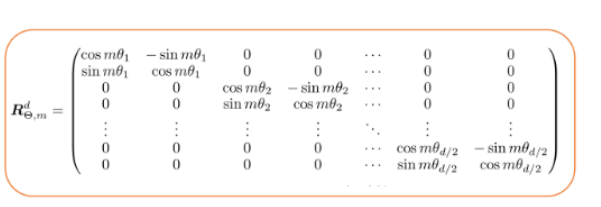
d维旋转矩阵-图片由作者提供
也就是说,对于位置m和嵌入维度d,旋转矩阵由d/2旋转矩组成,每个旋转矩是2比2。此外,由于这种结构是稀疏的,作者[6]推荐一种计算效率高的方法,用标记嵌入向量x计算token嵌入。
![]()
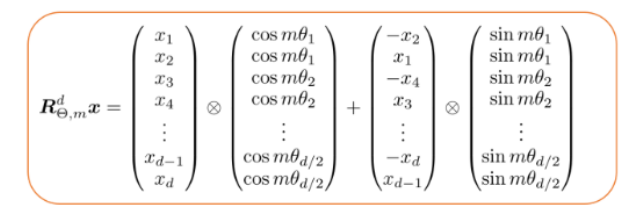
旋转矩阵和X向量相乘的高效计算方法-图片由作者提供
4.5 代码片段:Roformer实现
旋转位置嵌入(ROPE)的代码实现相当全面,如需了解详情,请参阅完整的代码库,这里列出了负责计算ROPE的核心功能,该功能封装在以下方法中:
![]()

注意,此行query_layer=querylayer*cos_pos+rotate halfquery_layer*sin_pos是根据上一节中提到的高效计算方法进行计算的。
结论
本文分析了三种位置嵌入:绝对位置嵌入、相对位置嵌入和旋转位置嵌入(RoPE)。绝对位置嵌入简单直接,但泛化能力受限,绝对位置嵌入有两种方法:学习式绝对位置嵌入和固定式绝对位置嵌入;相对位置嵌入关注token间的相对距离,适合Transformer-XL和DeBERTa长序列;旋转位置嵌入(RoPE):结合绝对位置嵌入与相对位置嵌入的优势,高效且可扩展。
感谢拨冗垂阅。
如有问题或建议,请随时联系我:电子邮件:
mina.ghashami@gmail.com LinkedIn:https://www.linkedin.com/in/minghashami/
参考文献
1. "Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context" by Zihang Dai et al.
2. "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer" by Colin Raffel et al.
3. "DeBERTa: Decoding-enhanced BERT with Disentangled Attention" by Pengcheng He et al.
4. "Enhancing Pre-trained Language Representations with Rich Supervision" by Fangxiaoyu Feng et al.
5. "Attention Is All You Need" by Ashish Vaswani et al.
6. Roformer: Enhanced Transformer With Rotary Position Embedding
Understanding Positional Embeddings in Transformers: From Absolute to Rotary
作者简介

转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
