时序数据库和关系型数据库各有侧重,前者擅长处理时序数据,后者擅长处理关系数据。选择时需考虑数据特点和业务需求。
原文标题:时序数据库和关系型数据库的区别是?
原文作者:数据派THU
冷月清谈:
本文深入对比了时序数据库与关系型数据库在事务机制、写入模式、存储压缩、查询模式和数据流通五个关键维度上的设计差异。时序数据库主要应用于工业物联网等场景,专注于处理按时间顺序生成的数据,强调高吞吐量和高效的存储压缩,而关系型数据库则在电商、物流等领域广泛应用,凭借其通用性优势,强调事务处理和数据一致性。选择数据库时,需要根据数据特点、业务需求和系统环境等因素进行综合考量。
怜星夜思:
1、在实际应用中,除了文章中提到的工业物联网和电商、物流领域,你觉得时序数据库和关系型数据库还可以在哪些场景下发挥各自的优势?
2、文章提到了时序数据库在端边云协同方面的优势,那么在实际部署时,如何权衡端、边、云三端的计算和存储资源,才能最大化时序数据库的性能和效率?
3、文章中提到了多种时序数据的压缩算法,例如RLE、差分编码等。那么,在选择压缩算法时,除了压缩率,还需要考虑哪些因素?
2、文章提到了时序数据库在端边云协同方面的优势,那么在实际部署时,如何权衡端、边、云三端的计算和存储资源,才能最大化时序数据库的性能和效率?
3、文章中提到了多种时序数据的压缩算法,例如RLE、差分编码等。那么,在选择压缩算法时,除了压缩率,还需要考虑哪些因素?
原文内容

本文约2600字,建议阅读5分钟
五大主要功能点,一文让你搞懂时序数据库与关系型数据库的区别。

在大数据时代,各类数据如潮水般涌现,数据处理与存储需求日趋复杂,数据类型的多元化直接推动了专用数据库的发展。
作为数据管理领域的两种核心引擎,时序数据库与关系型数据库分别服务于不同的数字化场景:前者专精于处理按时间生成的时序数据,主要应用于工业物联网、金融等领域;后者凭借其通用性优势,广泛支撑着电商、物流、企业管理系统等业务。
本文将从五大维度系统对比两类数据库的设计差异,深入解析其背后的技术理念与应用场景特性。

01 事务机制:必要 vs 不必要
关系型数据库支持事务处理,其事务机制一般将一系列数据库操作组合成一个逻辑单元。比如银行转账场景中,A 账户转出 10 元,B 账户转入 10 元,该事务中的所有操作只能全部成功执行或全部不执行。
这种事务机制能够在各种异常情况下(如系统崩溃、网络故障等)保障数据一致性和完整性。否则,多个操作进行数据修改可能部分成功、部分失败,导致数据不一致。因此,分布式系统中关系型数据库的事务机制需要记录数据过程状态,并提供失败回滚机制,进行并发控制。
而时序数据库主要应用的工业物联网场景中,传感器采集的数据只来自单一数据源,每条数据都是传感器对该时刻测点数值(如温度、风力)的真实记录,不存在同时修改两个数值的场景,也没有写写冲突的场景(多个人同时修改同一条数据),因此事务在时序数据库中是不必要的。时序数据库需要优先保证的是大量数据的高效稳定写入。
02 写入模式:强调一致性 vs 强调高吞吐
关系型数据库主要记录配置信息、人员信息等静态数据,数据主要来源于人类行为,多类场景数据通过人工表单录入(如 OA 系统)。数据写入需要严格遵循预先定义好的表结构,每一行数据必须匹配各列的数据类型、约束条件等。同时为符合事务机制,一系列写入操作可以全部成功提交,或在出现错误时进行事务回滚,数据库状态保持不变,以此确保数据的一致性。
时序数据库则面向工业物联网场景,数据由传感器设备产生,其接入终端规模可能达到数万至百万量级,数据采集频率可达秒级、毫秒级。因此,时序数据库需稳定维持每秒数十万至千万级的数据写入吞吐,针对高通量、高并发的写入需求进行性能优化。
比如,时序数据库 IoTDB 可通过底层文件 Apache TsFile 支持列式数据写入,达到毫秒级数据接入,并首创乱序分离存储引擎,大幅提升弱网环境产生的乱序数据处理效率,稳定实现千万级/秒数据写入。
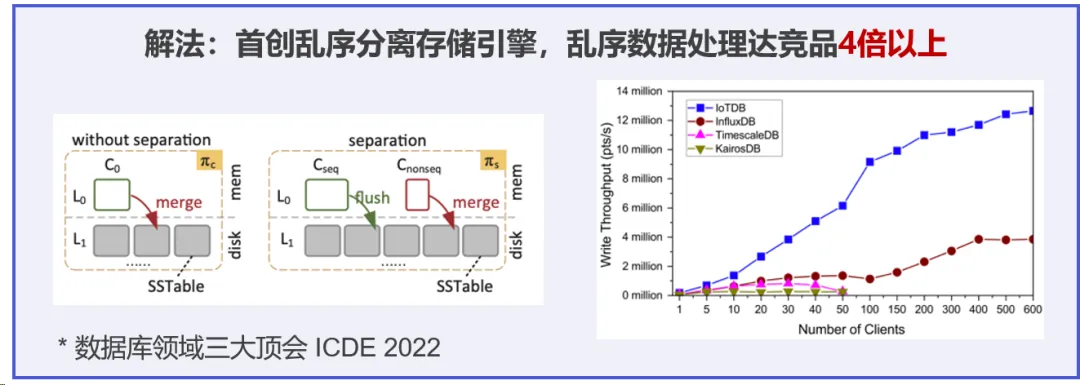
03 存储压缩:通用结构 vs 时序标准文件
关系型数据库为了支持通用查询和事务处理,在存储结构上使用 B+ 树索引实现多维数据查询,存储引擎不再需要全表扫描获取数据。其压缩策略多采用 LZ77、DEFLATE 等通用算法,根据数据库的使用情况和性能要求选择是否启用压缩及压缩级别。
时序数据库则针对时序数据特点,采用紧凑、高效的存储结构,如列式存储格式,以优化按时间范围的查询和数据插入性能。除使用通用算法外,时序数据库还会根据时序数据的特点,采用专门的压缩算法,如游程编码(RLE)、差分编码等,以提高压缩率。
比如,时序数据库 IoTDB 底层存储采用自研时序标准文件格式 Apache TsFile,通过设备、传感器和时间维度索引,实现基于特定时间范围的时序数据快速过滤和查询,相比通用文件格式,查询吞吐可提升 5-10 倍。同时,TsFile 采用先进的压缩技术,可最大限度地减少存储需求磁盘空间消耗并提高系统效率,相比通用文件格式,压缩比可提升 15 倍以上。
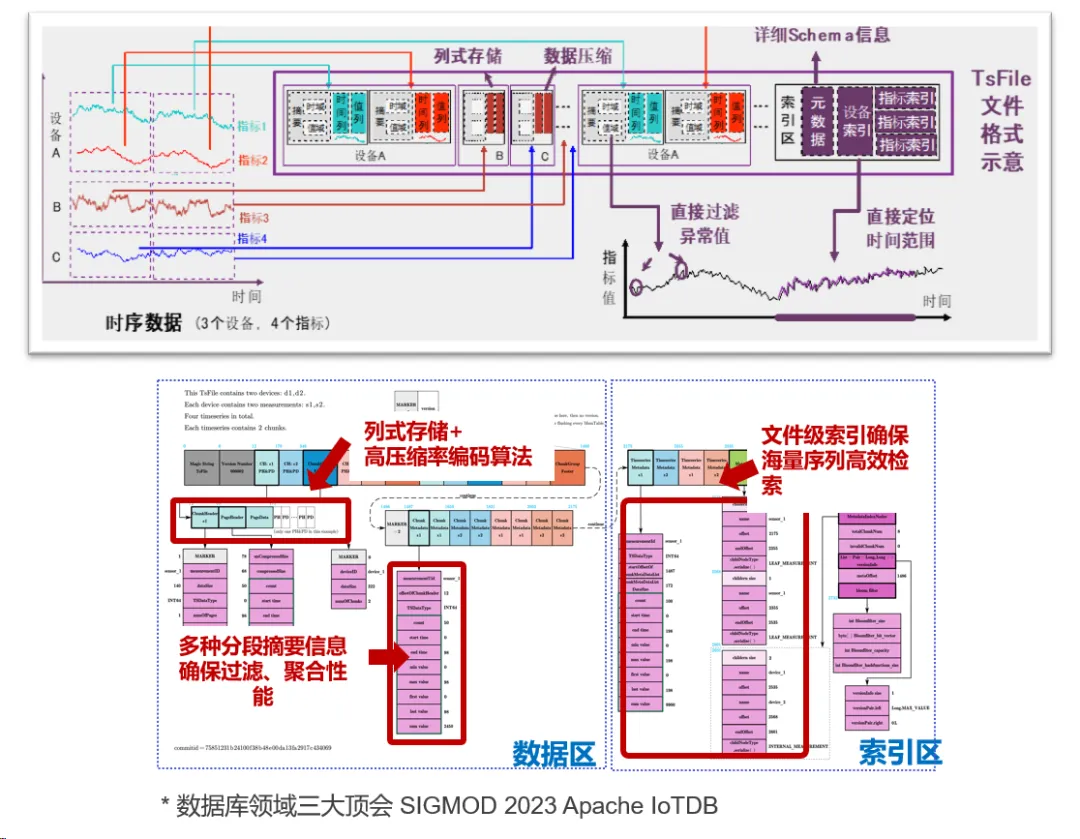
04 查询模式:精准检索 vs 时间维度分析
借助 SQL 的各类子句,如 SELECT 用于指定要查询的列,FROM 明确数据来源表,WHERE 设置筛选条件,关系型数据库可实现精准的数据筛选,从海量数据中快速定位所需信息。而且,关系型数据库支持多表关联查询,通过外键关系将不同表的数据进行连接,能全面获取相关联的信息,满足复杂业务逻辑的查询需求。
时序数据库的查询场景则有所区别:其查询通常涉及一个设备某个点位过去一月、数月、一年的变化趋势,数据量级可达到数十万甚至百万级。工业监控场景下,组态大屏每秒钟可能需要刷新几百个点位的最新状态,涉及数据量也十分可观。因此,用户对于时序数据库的查询吞吐往往要求较高。同时,用户常需执行时间维度强相关查询,比如把一条时间序列进行分段,对序列进行时间维度的规整等,时序数据库也需要针对这类特色需求进行支持。
以时序数据库 IoTDB 为例,其基于 TsFile 文件格式实现高吞吐查询,也可通过降采样查询降低查看数据趋势所需的数据量。同时,时序数据库 IoTDB 支持近百种时序处理函数,能够帮助用户快速实现时序分段查询、数据补齐、数据修复、时频变换等需求。
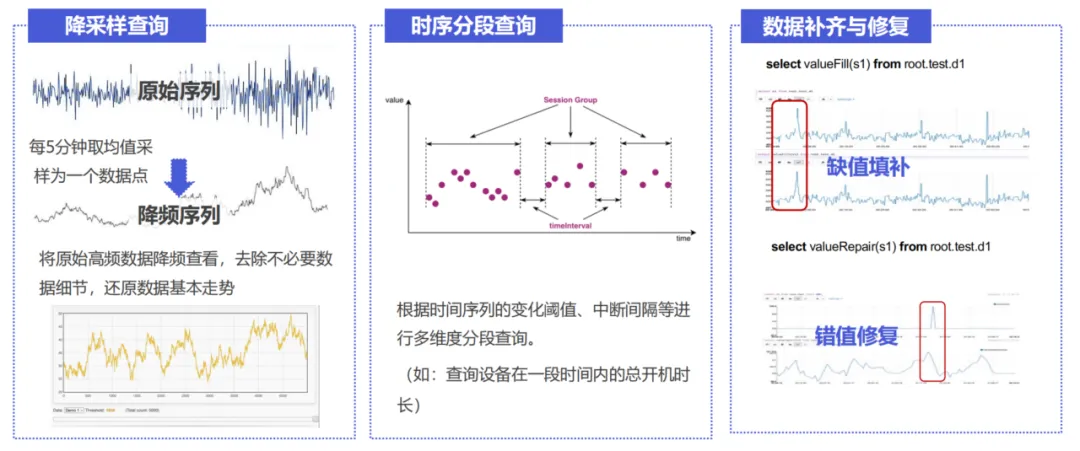
05 数据流通:集中管理 vs 端边云协同
关系型数据库多用于平台系统内部数据管理,底层文件多采用私有存储格式,仅服务于数据库内部读写。在业务架构改动、技术栈更新等场景中,关系型数据库可能需要进行数据迁移或上云。
而时序数据库存储的是待分析的业务数据,这些业务数据往往从外部批量或流式导入,存储后还要分发给不同部门或集团中心进行分析,因此数据迁入迁出较为频繁,需要构建简便、高效的跨终端实时数据同步链路。
工业物联网场景中,数据从设备产生、经过省域厂站边侧处理、汇聚到集团云侧,数据的流动跨越端边云。在电力领域,还可能遇到生产网和办公网通过单向网闸进行隔离,同一份数据在生产网和办公网都需要进行存储和使用的场景。时序数据库能否在端边云数据协同和跨网闸传输场景中优化数据同步成本,降低资源消耗,是用户非常重要的考量点。
时序数据库 IoTDB 在这方面具备突出优势。基于统一的底层数据文件 TsFile,数据可以在外部生成,加载至数据库内,也可以订阅数据库文件进行分发,数据互通非常便捷。基于消息或 TsFile 传输协议,一份数据可以一次处理、多次使用,低成本实现端边云协同,网络带宽节省 90%,接收端 CPU 节省 95%。生产网 IoTDB 生成的 TsFile,传输到办公网的 IoTDB 依然能直接使用,不需要重新组织和重复写入。

06 总结
时序数据库与关系型数据库的功能差异本质上源于其服务的数据类型差异:前者面向持续产生、具备强时间关联的物联网时序数据,后者处理以实体关系为核心的业务数据。
用户在选择时需重点考量数据产生模式(时序特征强度)、业务场景需求(写入吞吐量、查询复杂度)以及系统环境(端边云协同需求)等核心要素。
我们将时序数据库与关系型数据库的上述区别总结如下:
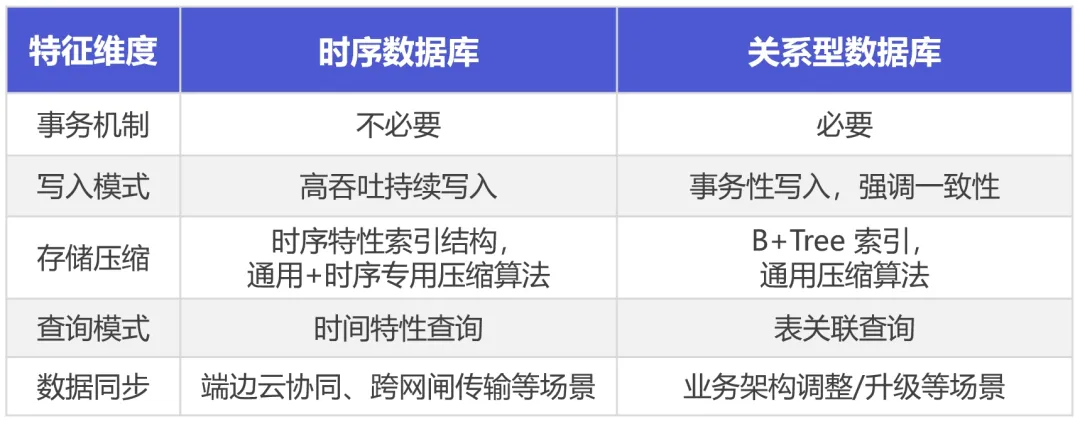
编辑:文婧
