阿里开源 Qwen2.5-Omni,一款7B参数的旗舰级多模态大模型,支持文本、图像、音频、视频输入,以及实时语音和视频聊天。采用Apache 2.0协议,免费商用。
原文标题:阿里深夜开源Qwen2.5-Omni,7B参数完成看、听、说、写
原文作者:机器之心
冷月清谈:
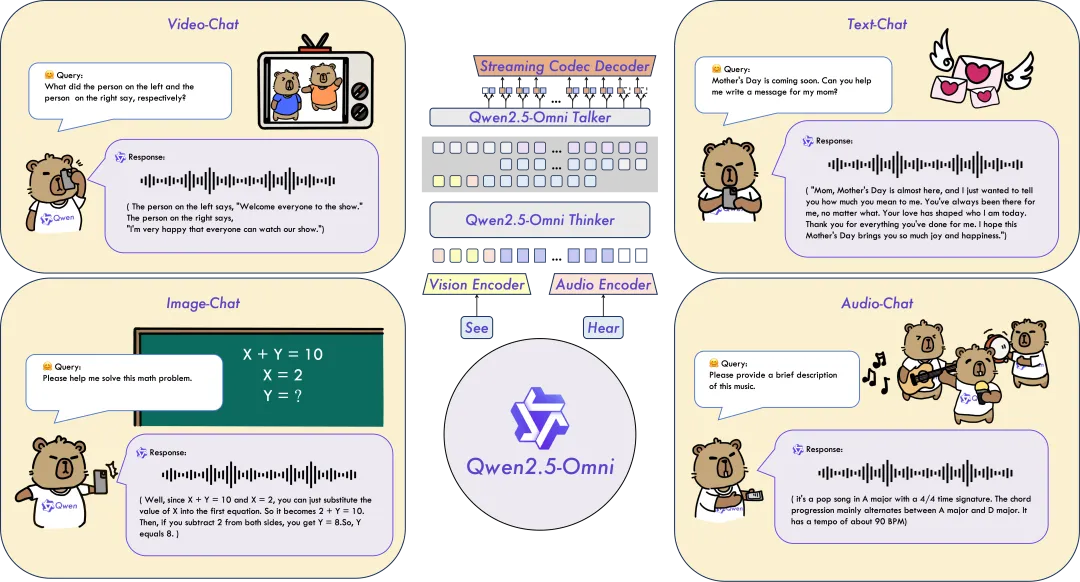
1. **全模态感知**:能够无缝处理文本、图像、音频和视频等多种输入,并支持流式文本生成和自然语音合成输出,实现实时的语音和视频聊天交互。
2. **创新架构**:采用了 Thinker-Talker 架构,类似于大脑和嘴巴的分工,Thinker 负责处理和理解多模态输入,生成高级表示和文本,Talker 则负责流式输出语音。
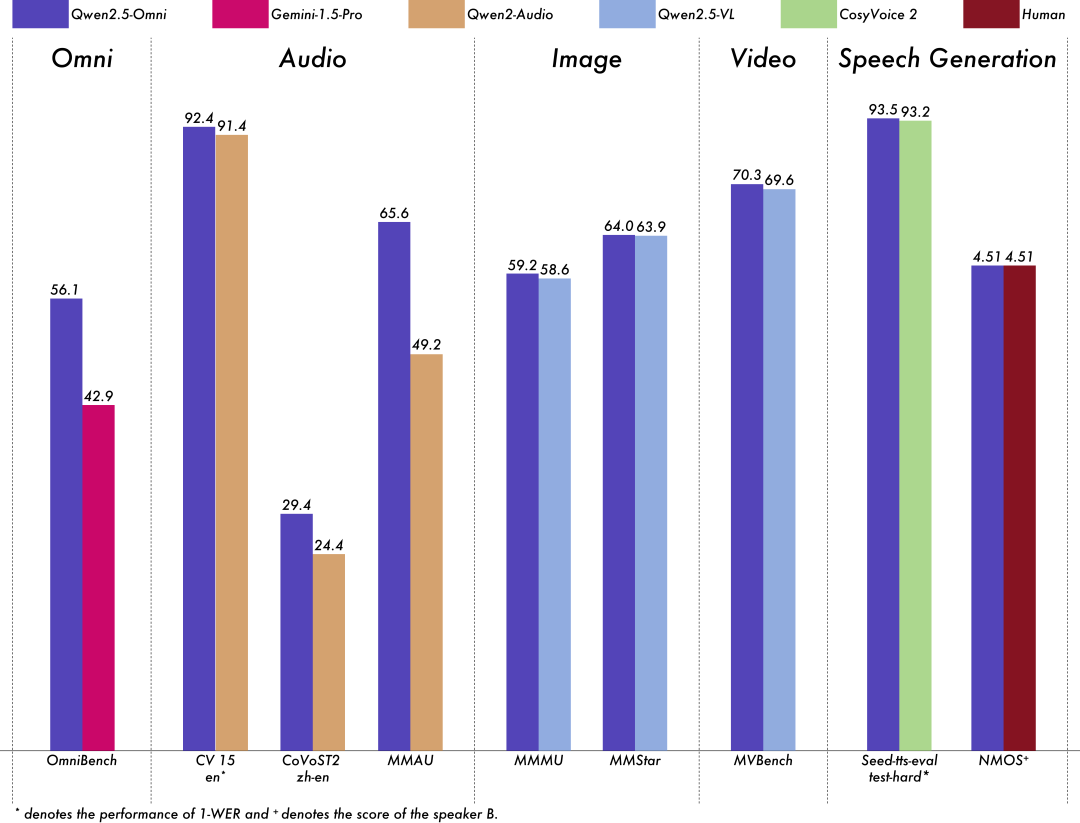
3. **卓越性能**:在多模态和单模态任务中均表现出色,超越了同等规模的单模态模型,例如 Qwen2.5-VL-7B、Qwen2-Audio 和 Gemini-1.5-pro。
4. **完全开源**:Qwen2.5-Omni-7B 模型采用 Apache 2.0 许可证,并且发布了技术报告,开发者和企业可以免费下载商用,并部署在手机等终端设备上。
Qwen2.5-Omni 的开源,无疑为多模态大模型的研究和应用带来了新的机遇,降低了开发和部署的门槛,有望加速多模态技术的普及。
怜星夜思:
2、Qwen2.5-Omni 开源会对多模态大模型领域带来哪些影响?
3、Qwen2.5-Omni 支持多种模态的输入和语音输出,你认为它在哪些场景下具有最大的应用潜力?
原文内容
机器之心报道
机器之心编辑部
现在,开发者和企业可免费下载商用Qwen2.5-Omni,手机等终端智能硬件也可轻松部署运行。

-
论文地址:https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
-
博客地址:https://qwenlm.github.io/blog/qwen2.5-omni/
-
GitHub 地址:https://github.com/QwenLM/Qwen2.5-Omni
-
Hugging Face 地址:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
-
ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
-
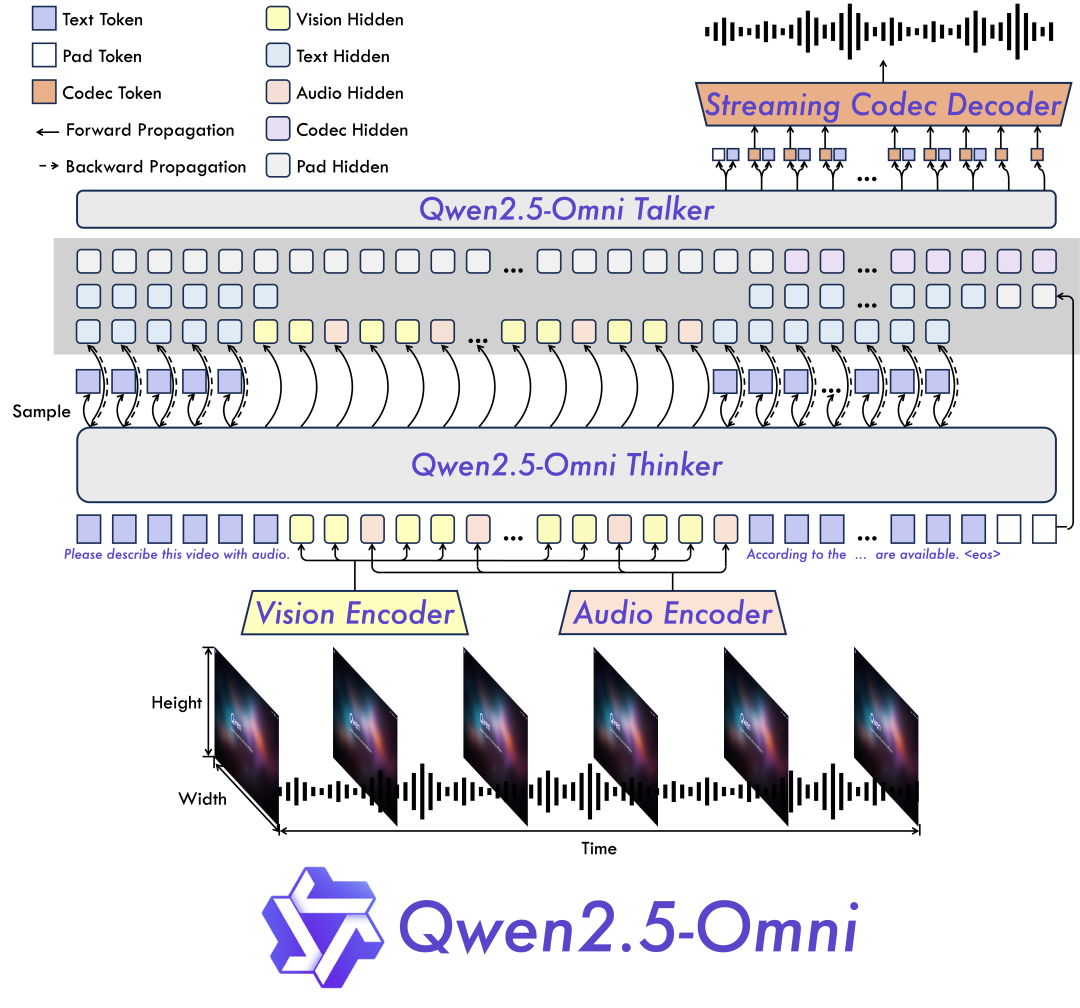
Omni 和创新架构:团队提出了 Thinker-Talker 架构,这是一个端到端的多模态模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式方式生成文本和自然语音响应。此外,团队还提出了一种名为 TMRoPE(Time-aligned Multimodal RoPE)的新型位置嵌入,用于同步视频输入与音频的时间戳;
-
实时语音和视频聊天:该架构专为完全实时交互而设计,支持分块输入和即时输出;
-
自然且稳健的语音生成:在语音生成方面,Qwen2.5-Omni 超越了许多现有的流式和非流式替代方案,展现出卓越的稳健性和自然性;
-
多模态性能强劲:在与同样大小的单模态模型进行基准测试时,Qwen2.5-Omni 在所有模态上均展现出卓越的性能。Qwen2.5-Omni 在音频能力上超越了同样大小的 Qwen2-Audio,并且达到了与 Qwen2.5-VL-7B 相当的性能;
-
出色的端到端语音指令遵循能力:Qwen2.5-Omni 在端到端语音指令遵循方面的表现可与文本输入的有效性相媲美,这一点在 MMLU 和 GSM8K 等基准测试中得到了证明。