开源音乐生成模型YuE媲美Suno AI,可生成5分钟歌曲,并支持歌声和伴奏,人人都能成为音乐家。
原文标题:这AI绝对偷了格莱美奖杯!直接把LLaMA喂成乐坛顶流:开源版Suno来了!
原文作者:机器之心
冷月清谈:
港科大和DeepSeek联合开源的音乐生成模型YuE,在GitHub上迅速走红。它采用双LLaMA架构,能够生成长达5分钟的高质量歌曲,并同时支持专业级歌声和伴奏。YuE通过独特的Dual-NTP和结构化渐进生成技术,在人声和伴奏的联合建模方面取得了突破,并在音乐性、生成时长和抄袭检测等方面表现出色。此外,YuE还具备风格克隆、声音克隆和风格迁移能力,能模仿多种歌手的风格。该模型的开源为音乐创作领域带来了新的可能性,降低了音乐创作的门槛。
怜星夜思:
1、YuE的开源会对音乐产业,特别是独立音乐人产生什么影响?是福音还是挑战?
2、文章提到YuE在抄袭检测方面表现良好,但AI生成的音乐是否真的能完全避免抄袭?如果AI只是模仿现有音乐的风格,这算不算另一种形式的抄袭?
3、YuE目前已经可以模仿王菲、碧梨等歌手的风格,未来是否会出现完全由AI模仿特定歌手的声音和风格创作的歌曲,并用于商业用途?这对歌手本人又会造成什么影响?
2、文章提到YuE在抄袭检测方面表现良好,但AI生成的音乐是否真的能完全避免抄袭?如果AI只是模仿现有音乐的风格,这算不算另一种形式的抄袭?
3、YuE目前已经可以模仿王菲、碧梨等歌手的风格,未来是否会出现完全由AI模仿特定歌手的声音和风格创作的歌曲,并用于商业用途?这对歌手本人又会造成什么影响?
原文内容

家人们震惊了!现在 AI 成精啦,不仅能写能画,现在连唱功都是格莱美级的了!
魅惑空灵电音女声,也太好听了吧!
酷佬街头说唱,怎么有一股八方来财的味儿?
强混嘹亮欧美女高,像极了阿黛尔~
极端的金属核嗓也不在话下!
日韩女团风,日韩英三语无缝切换!
还有这首 AI 新编版《世界赠与我的》!模仿王菲空灵仙嗓也太到位了吧,完全不一样的旋律,一样的嘎嘎好听,宁静中带一点哀伤的意境拿捏得简直了!
模仿碧梨的慵懒声线,确定不是碧梨本人在唱?
网友爆改 rap 版 YouTube 亿播神曲《Plastic Love》:
YuE(乐):开源版 Suno AI
上述所有让网友跪着听的炸裂神曲,全都出自港科大和音乐圈 DeepSeek —— Multimodal Art Projection(MAP)联手开源音乐生成基座 —— YuE(乐)。

-
论文标题:YuE: Scaling Open Foundation Models for Long-Form Music Generation
-
项目地址:https://github.com/multimodal-art-projection/YuE
-
Demo:https://map-yue.github.io
-
Arxiv:https://arxiv.org/abs/2503.08638
这个模型可太强啦,直接对标 Suno AI,自春节期间放出以来 GitHub 已飙星 4500+,推特累计浏览上百万次!老外刷着 demo 直接给 Suno 和 Udio 开起追悼会:闭源音乐生成这是药丸!
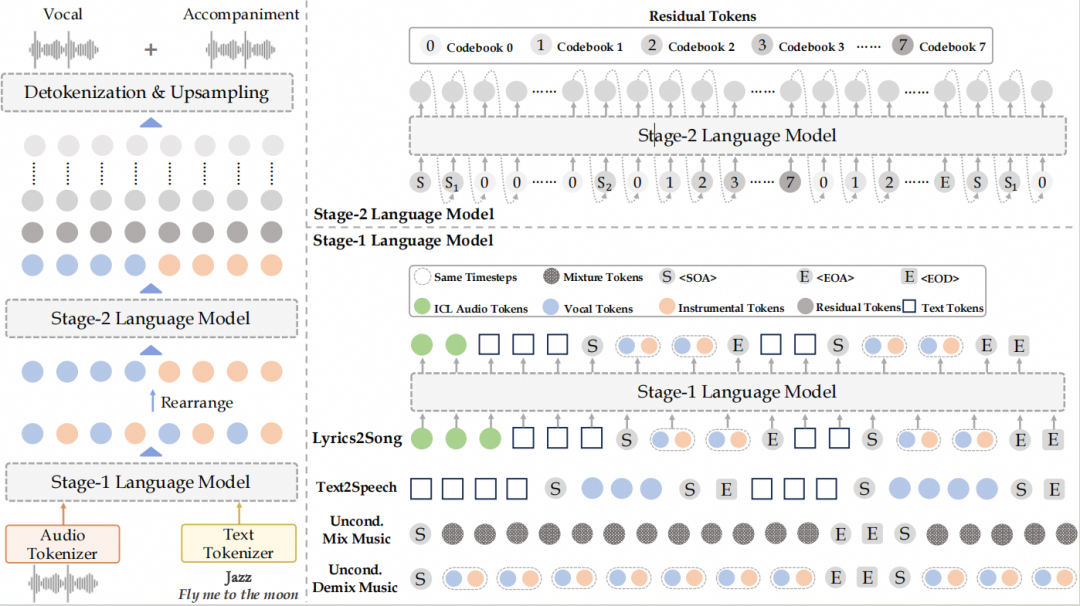
作为第一个开源的全曲级歌曲生成基座,YuE 做到了连 Google 家的 MusicLM、Meta 家的 MusicGen 都做不到的事:不仅能建模长达 5 分钟的歌曲,又能同时生成专业级歌声和伴奏!
这是怎么实现的呢?
YuE 其实是一个双 LLaMA 语言模型架构(下图),因此无痛适配大部分大语言基建,非常容易 scale up。
-
其中大的 Stage-1 LM 联合建模文本条件和粗粒度音频离散 token 序列。
-
而小的 Stage-2 LM 基于大 LM 给出的粗粒度离散 token 合成剩余的(残差)细粒度 token。
-
最后得到的多码本离散音频序列会送入 tokenizer decoder 重建回音频,并送入一个轻型上采样器重构 44.1khz 的音频。
在 YuE 之前,主要的学界工作还是把歌声合成(Singing Voice Synthesis)和音乐生成(Music Generation)分开做的,只有像 Suno AI、Udio 这样的闭源玩家们成功探索出来了端到端的歌曲生成,把两种任务合并到一起建模。有个别学界工作会分阶段对人声和伴奏分别建模,但是效果距离商业闭源还是差距较大,也没有开源。这里就不得不提 YuE 的双轨版 Next-Token Prediction(Dual-NTP)策略了。
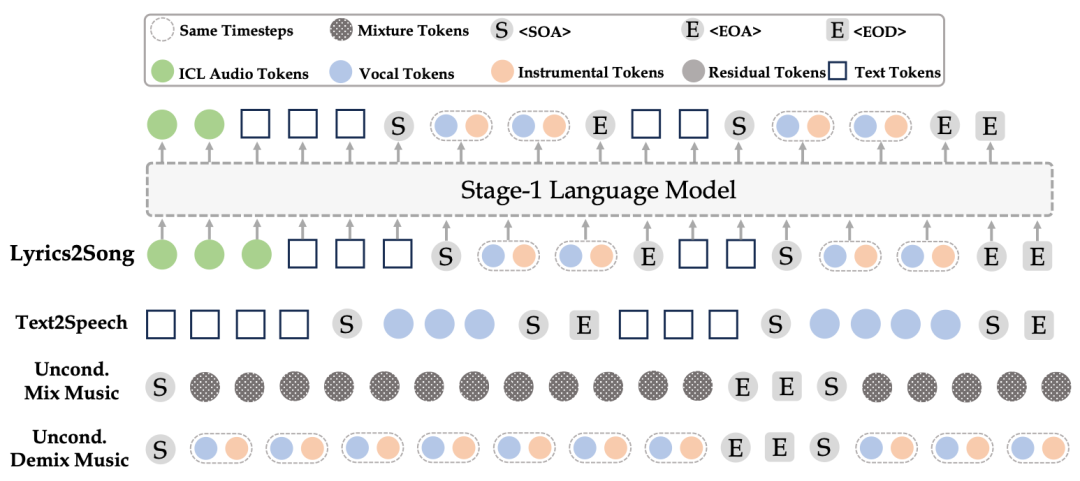
YuE 的 Stage-1 LM 利用声伴分离先验,把人声和伴奏轨在同一个时间步分别用两个 token 建模(上图虚线框),巧妙地实现了歌声合成和音乐伴奏生成的联合建模。这不仅避免了离散 token 的信息损失问题,得以精准捕捉细腻人声,还保证了轨间对齐和端到端。
-
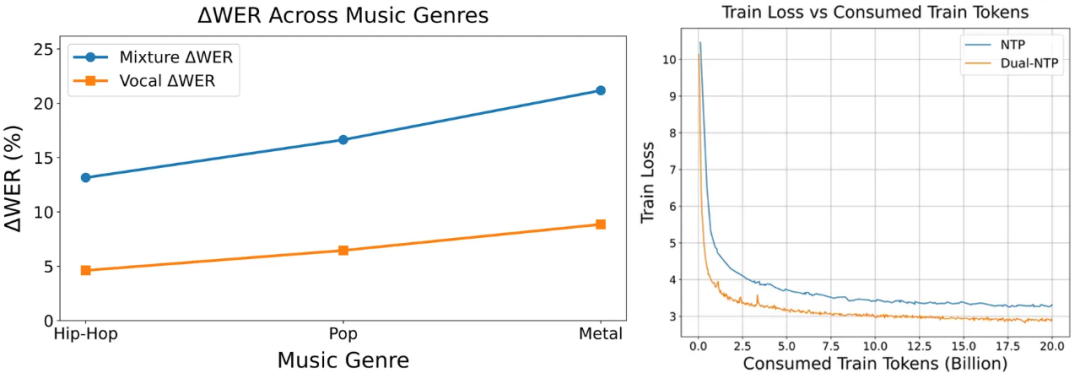
如果使用 ΔWER 来表示语音内容重构损失,那么利用分离先验得到的人声轨(下左图橙)的损失显著小于合轨(下左图蓝),甚至在极端的金属风格下也能维持较低的语音内容重构损失。
-
基于 Dual-NTP 训练的 LM 在相同的训练成本下也表现出比 NTP 更低的 loss(下右图橙 vs 蓝)。
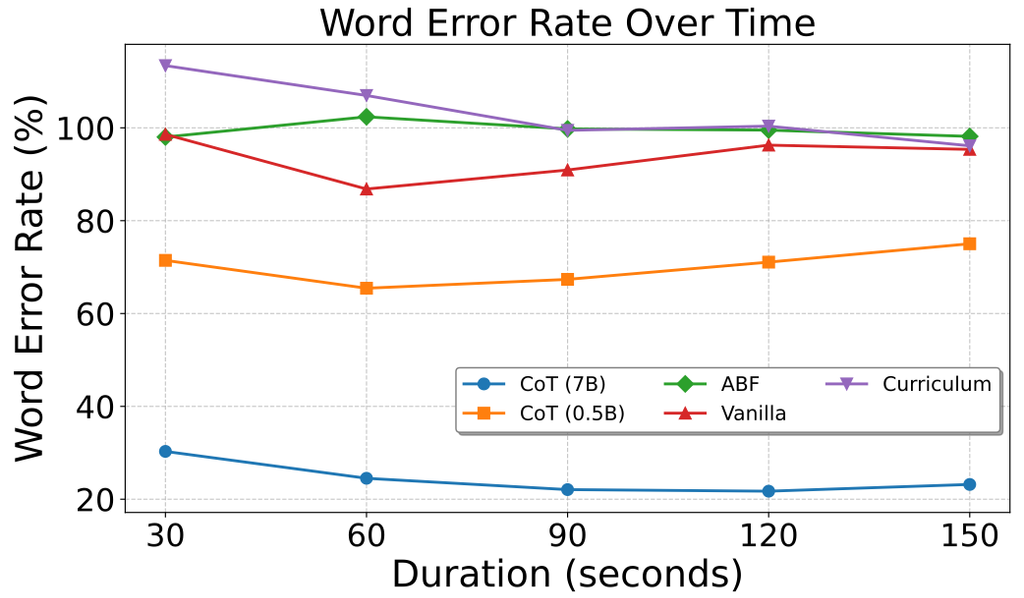
但为了达成数分钟级的歌曲建模,研究团队又对 Stage-1 LM 提出了另一个改进:结构化渐进生成(Structural Progressive Generation,缩写为 CoT),将歌曲拆分成主副歌段落后,通过文本 token(方形)、音频 token(圆形)在同上下文内交替排布的方式,避免了文本条件控制远程衰减的问题,使得人声轨能在全曲范围内准确跟随歌词控制。

消融显示,这种带有文本中间态的 CoT 在 0.5B 下比其它方法(原版、课程学习、ABF)具有更低的 Whisper 转录歌词错误率(橙线),并在 scale up 到 7B 之后得到更显著的收益(蓝线)。受限于 Whisper 的歌声转录性能,20% 的错误率已经接近 groundtruth 原曲的错误率。
不仅如此,团队还专门为音乐开发了特有的上下文学习(Music In-Context Learning,Music ICL)。与此前 TTS 领域的续写型 ICL 不同,音乐创作常常要求从一个动机出发向左右两边发展构造成曲,要避免抄袭鼓励创作。为此,Music ICL 将曲中任意 20~40 秒片段的音乐拼接到 CoT 数据开头,并在 Stage-1 LM 退火阶段利用约 2% 的计算量延迟激活这种格式。
团队发现,过早地激活 Music ICL 容易导致捷径学习(Shortcut Learning),让模型成为洗歌机器,对音乐创作能力有损。而延迟激活策略极大地节约了计算量,并且保护了模型的音乐性和创造力。这也带来了本文开头的风格克隆(Style Cloning)、声音克隆(Voice Cloning)、风格迁移(Style Transfer)的相应能力,模仿王菲、碧梨甚至爆改 Rap 版 City Pop。在测试时开启 ICL 和 CFG(Classifier Free Guidance)模式后,模型音乐性暴涨!
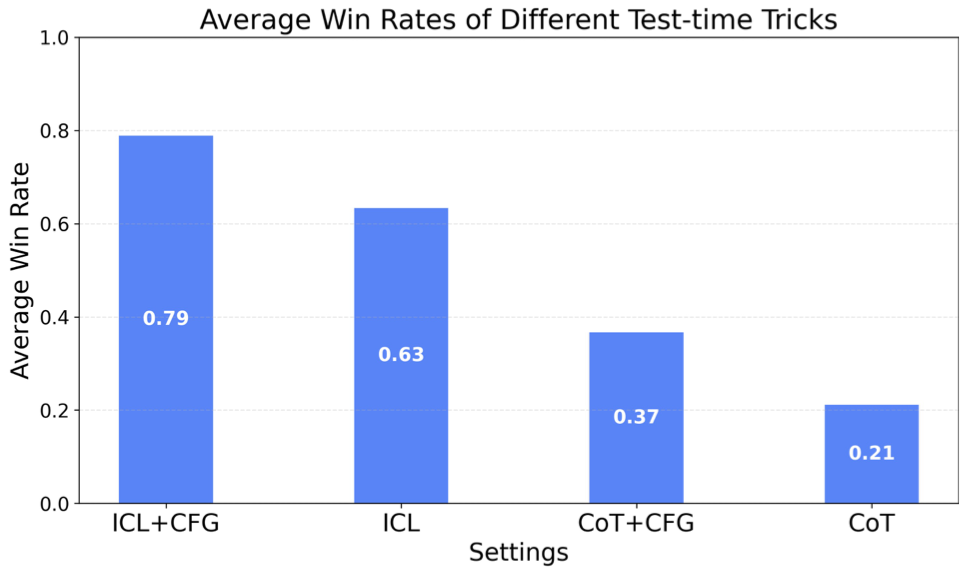
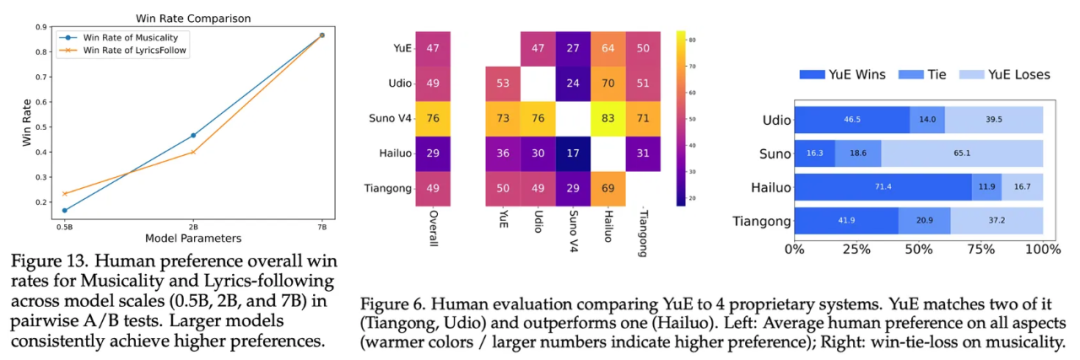
团队将 Stage-1 LM 扩展到 1.75T token,7B 的规模后,在人类偏好评测中获得了闭源级的音乐性和综合评分。
在人声音域上(下图数字越大音域越宽广),YuE 与国际领先的 Suno、Udio 处于同一水平线。
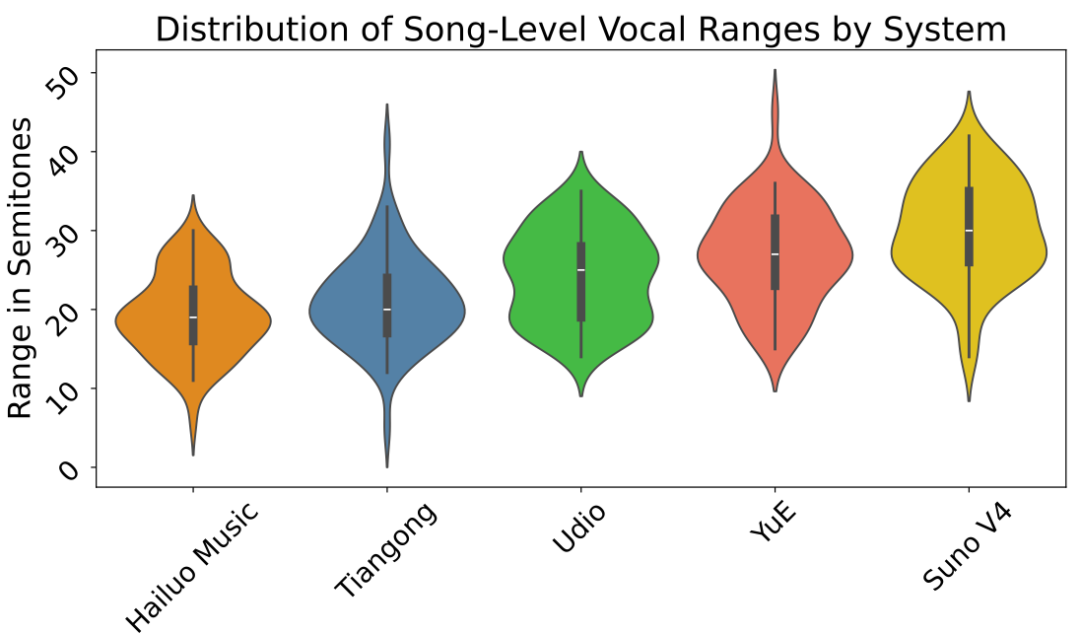
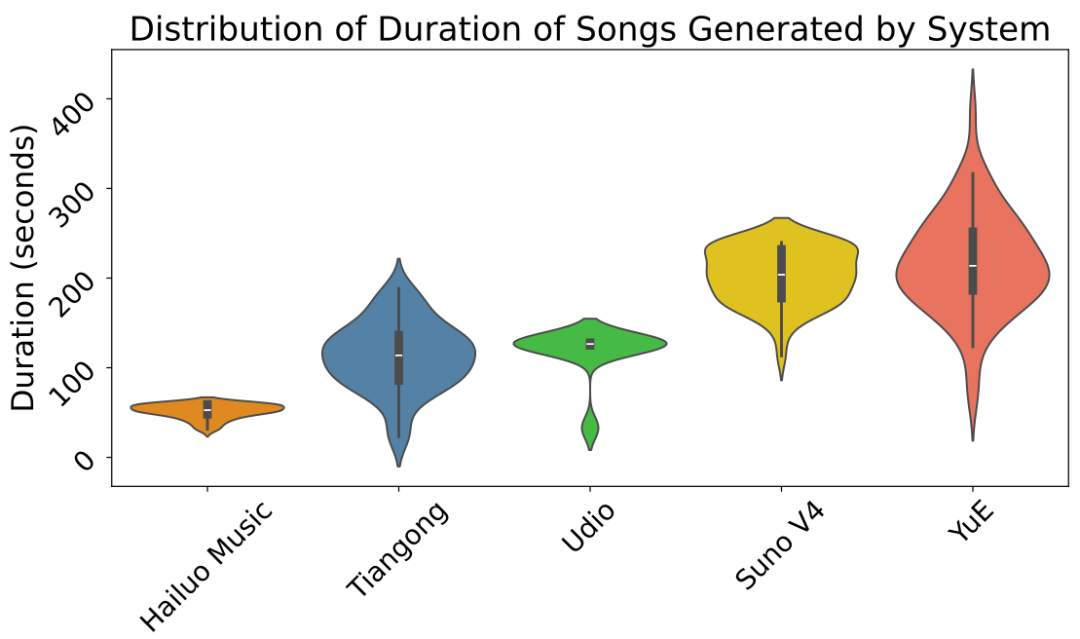
在生成时长上,YuE 也位于国际领先水平。
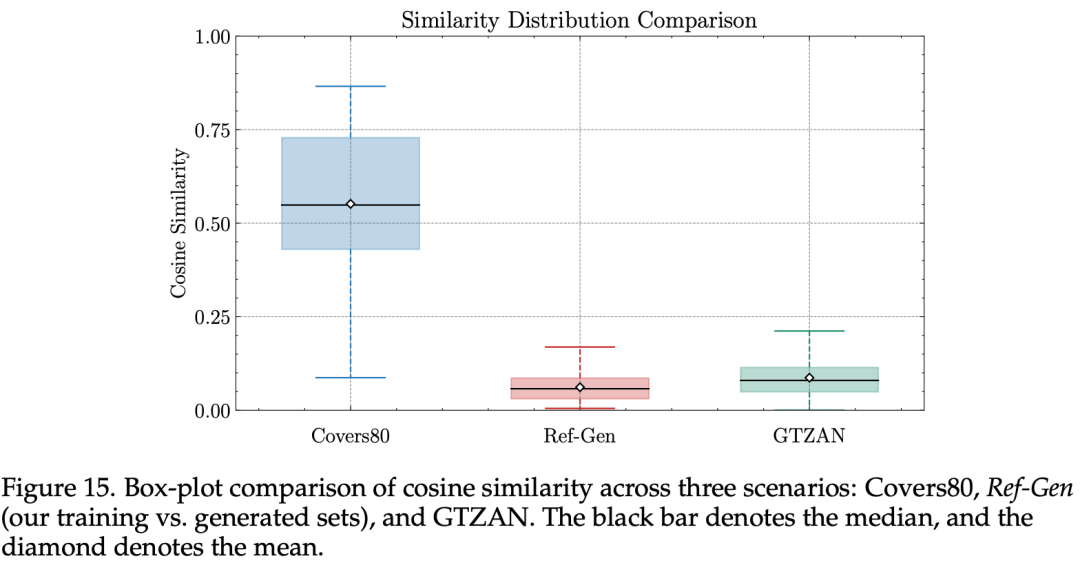
抄袭检测显示,即使提供训练集内样本,YuE 的查重率甚至低于学术数据集 GTZAN 的同流派内不同曲目相似度,更是远低于人类翻唱、改编曲目。
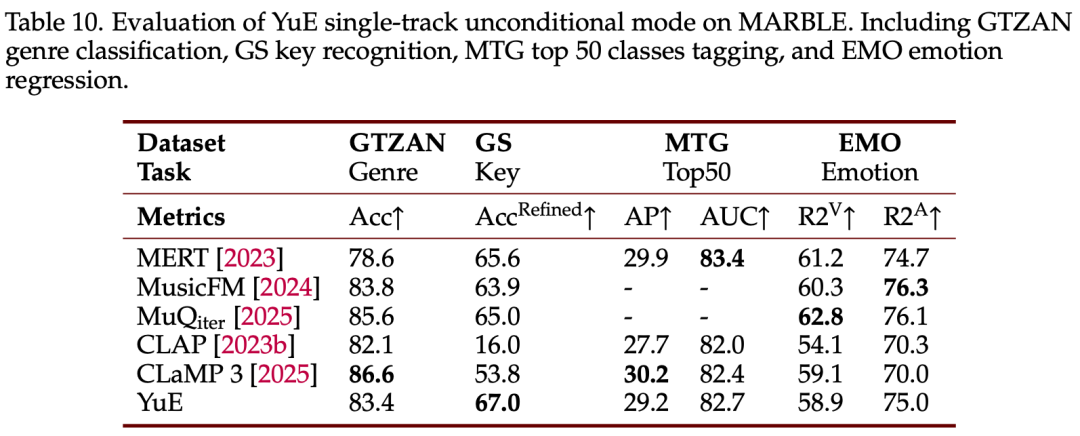
不仅如此,YuE 还有非常不错的 embedding 质量。作为一个生成模型,它的单轨无条件模式可用于抽取全曲级 embedding,而且表征质量和 SOTA 表征学习模型处于同一水平,甚至在调性识别上还超过了最新自监督学习 SOTA MuQ。这下确认 YuE 唱歌不会跑调啦!
还等什么,快来玩玩看吧~
-
项目地址:https://github.com/multimodal-art-projection/YuE
-
Demo:https://map-yue.github.io
-
Arxiv:https://arxiv.org/abs/2503.08638
-
B 站讲解:https://b23.tv/YaYtvVi
交互式 Demo(非官方):
-
https://huggingface.co/spaces/fffiloni/YuE
-
https://yueai.app/zh/playground
-
https://yueai.ai
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com