清华开源Video-T1,首创视频生成Test-Time Scaling!无需重新训练,推理阶段计算量换质量,性能飙升。
原文标题:视频生成的测试时Scaling时刻!清华开源Video-T1,无需重新训练让性能飙升
原文作者:机器之心
冷月清谈:
清华大学、腾讯的研究团队提出了名为Video-T1的视频生成Test-Time Scaling方法,该方法无需重新训练或扩大模型规模,即可显著提升视频生成质量。通过将视频生成过程建模为高斯噪声空间到目标视频分布的轨迹搜索问题,并引入随机线性搜索作为基础实现方式,Video-T1在VBench上实现了最高5.86%的总分提升。为了提高搜索效率和视频质量,研究团队还提出了Tree-of-Frames方法,该方法通过自适应扩展和修剪视频分支,在计算成本与生成质量间实现动态平衡。实验结果表明,无论是基于Diffusion的模型还是Autoregressive范式的模型,均可通过Test-Time Scaling方法实现生成视频性能的全面提升,且Tree-of-Frames方法能够显著降低视频模型推理计算量。
怜星夜思:
1、Video-T1提出的Test-Time Scaling方法,在哪些实际应用场景中会更有优势?除了提升视频生成质量,它是否有可能应用于其他视频处理任务,例如视频修复或风格迁移?
2、文章中提到的Tree-of-Frames方法,通过自适应扩展和修剪视频分支来平衡计算成本和生成质量。那么,在实际应用中,如何确定最佳的扩展和修剪策略?是否存在一种通用的策略,还是需要根据具体的视频内容和生成模型进行调整?
3、文章中提到,首帧对于视频整体是否对齐影响较大,那么,除了文中的Text-to-Image生成首帧外,是否有其他方法可以进一步提高首帧的质量和文本对齐度?例如,利用用户提供的参考图像或视频片段作为首帧的引导?
2、文章中提到的Tree-of-Frames方法,通过自适应扩展和修剪视频分支来平衡计算成本和生成质量。那么,在实际应用中,如何确定最佳的扩展和修剪策略?是否存在一种通用的策略,还是需要根据具体的视频内容和生成模型进行调整?
3、文章中提到,首帧对于视频整体是否对齐影响较大,那么,除了文中的Text-to-Image生成首帧外,是否有其他方法可以进一步提高首帧的质量和文本对齐度?例如,利用用户提供的参考图像或视频片段作为首帧的引导?
原文内容

视频作为包含大量时空信息和语义的媒介,对于 AI 理解、模拟现实世界至关重要。视频生成作为生成式 AI 的一个重要方向,其性能目前主要通过增大基础模型的参数量和预训练数据实现提升,更大的模型是更好表现的基础,但同时也意味着更苛刻的计算资源需求。
受到 Test-Time Scaling 在 LLM 中的应用启发,来自清华大学、腾讯的研究团队首次对视频生成的 Test-Time Scaling 进行探索,表明了视频生成也能够进行 Test-Time Scaling 以提升性能,并提出高效的 Tree-of-Frames 方法拓展这一 Scaling 范式。
目前,这项工作的代码已经开源,感兴趣的小伙伴可以开 Issue 提问,也欢迎共同探索视频和多模态生成。

-
论文标题:Video-T1: Test-Time Scaling for Video Generation
-
论文地址:https://arxiv.org/pdf/2503.18942
-
Github 仓库: https://github.com/liuff19/Video-T1
-
项目主页: https://liuff19.github.io/Video-T1/
视频生成的 Test-Time Scaling 范式
继 DeepSeek-R1 爆红后,在视觉 / 多模态等不同领域都涌现了大量 Test-Time Scaling (TTS) 研究,Video-T1 则是首次将 Test-Time Scaling 引入视频生成领域,突破了传统方式 Scaling up 视频模型需要大量资源重新训练或显著扩大模型规模的局限性。
研究团队通过增加推理阶段计算来显著提升视频生成质量,在 VBench 上实现了最高 5.86% 的总分提升,同时发现模型能力随着推理阶段选取的样本数目增加而增长,体现出持续 Scale Up 的特性。
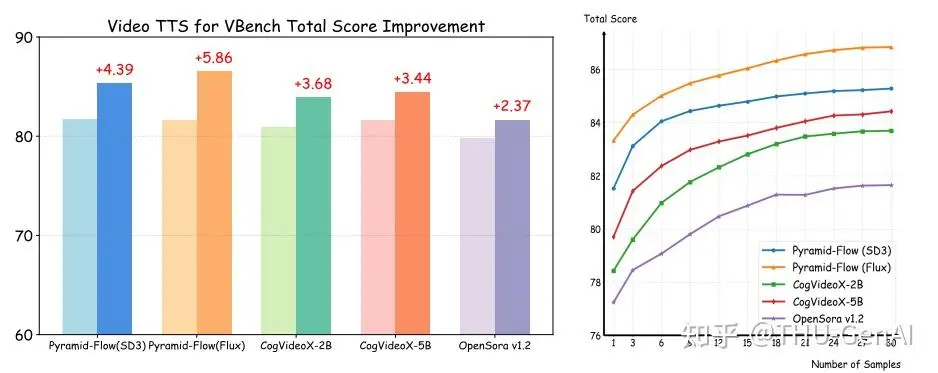
研究团队创新性地将视频生成中的 Test-Time Scaling 问题建模为从高斯噪声空间到目标视频分布的轨迹搜索问题,为优化视频生成引入了新的理论框架。同时构造了随机线性搜索作为 Test-Time Scaling 的基础实现方式,即随机地取样多个视频生成样本,利用 VLM 进行评分选出最优的视频样本作为输出。

Tree-of-Frames 方法提升推理效率
然而,随机线性搜索的复杂度较高,需要较多的推理时计算,研究团队发现,许多视频在生成的过程中就会出现内容与提示词不对应或者不符合现实规律等诸多问题,为了进一步提高搜索速度和视频质量,研究团队提出了「帧树」(Tree-of-Frames, ToF),通过自适应扩展和修剪视频分支,在计算成本与生成质量间实现动态平衡。
类似于在推理模型中使用 score model,研究团队提出使用测试时验证器(test-time verifiers)评估中间结果质量,并结合启发式算法高效导航搜索空间,在视频生成的适当位置进行评估,选取符合要求的生成轨迹,显著提升生成效率和质量。

相比于直接进行随机线性搜索,Tree-of-Frames 方法能够在取得相同效果的情况下显著提高搜索效率,降低视频模型的推理计算需求。
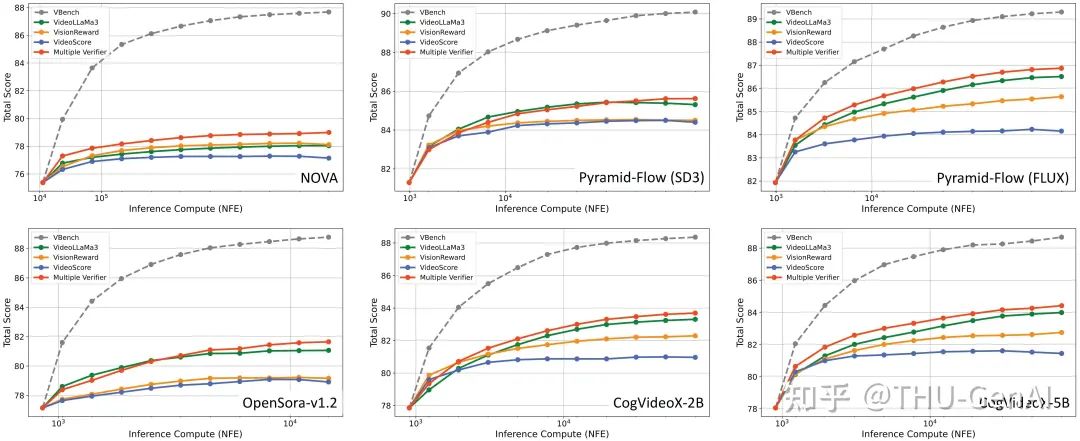
研究团队通过比较不同 Test-Time Scaling 方法和不同样本数量对应的 Number of Function Evaluations (NFE) 及对应的表现,发现使用 Tree-of-Frames 方法能够在相同 NFE 的情况下更为显著地提高视频表现。
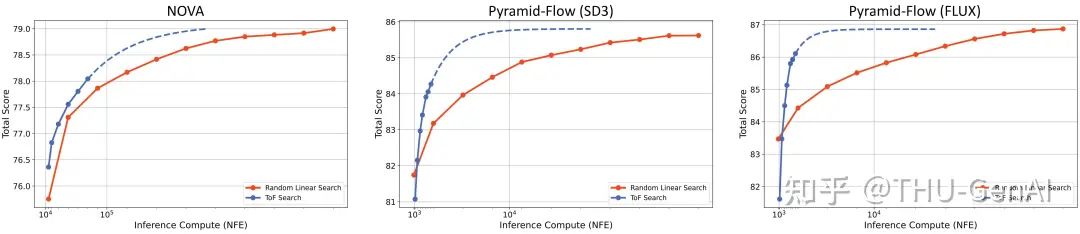
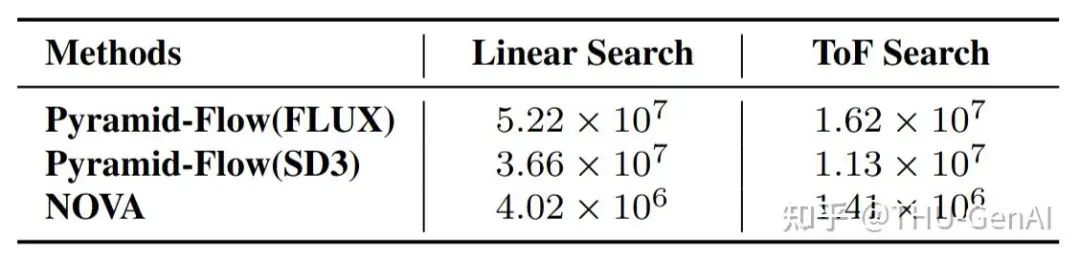
研究团队选取了三种视频生成模型实现 Tree-of-Frames 方法,并计算其视频模型的推理计算需求,在 VBench 总分相同的情况下进行比较,发现 Tree-of-Frames 显著降低了视频模型推理计算量。
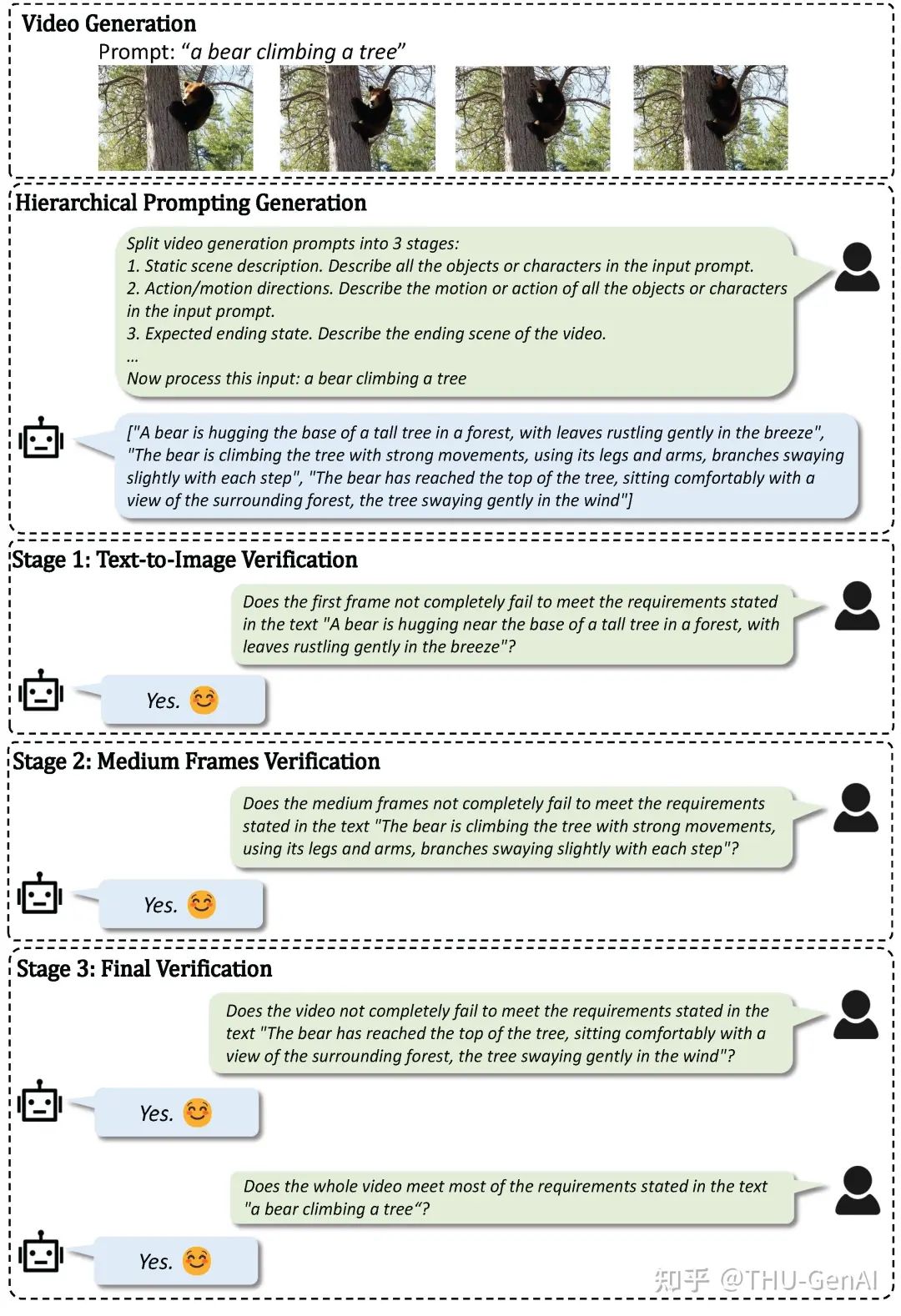
此外,研究团队注意到首帧对于视频整体是否对齐影响较大,视频的前中后部分存在一定程度不同的提示词对齐需求,因此利用单帧的图片生成思维链 (Image Generation Chain-of-Thought) 和层次化提示词 (Hierarchical Prompting) 等方法,对帧的生成和提示词对齐进行增强,构建了 Tree-of-Frames 总体流程。
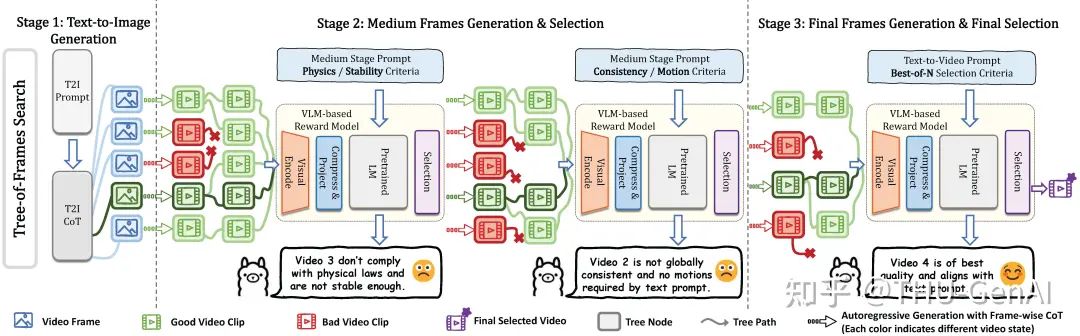
在上图所示的流程中,第一阶段执行 Text-to-Image (First Frame) 生成,进行图像级别的对齐,让首帧能够包含正确且足够的关于物体、场景的语义信息;第二阶段在测试时 Verifier 中应用层次化提示词 (Hierarchical Prompting),关注运动稳定性与物理合理性等方面,从而提供反馈,指导启发式搜索过程;最后一阶段评估视频的整体质量,并选择与文本提示词最高对齐度的视频。
不同模型的 Test-Time Scaling 实验
研究团队进行了大量 Test-Time Scaling 实验,使用不同的视频生成模型、VLM 模型进行测试,得到这些模型相比于基线在 VBench 上各方面指标的提升。
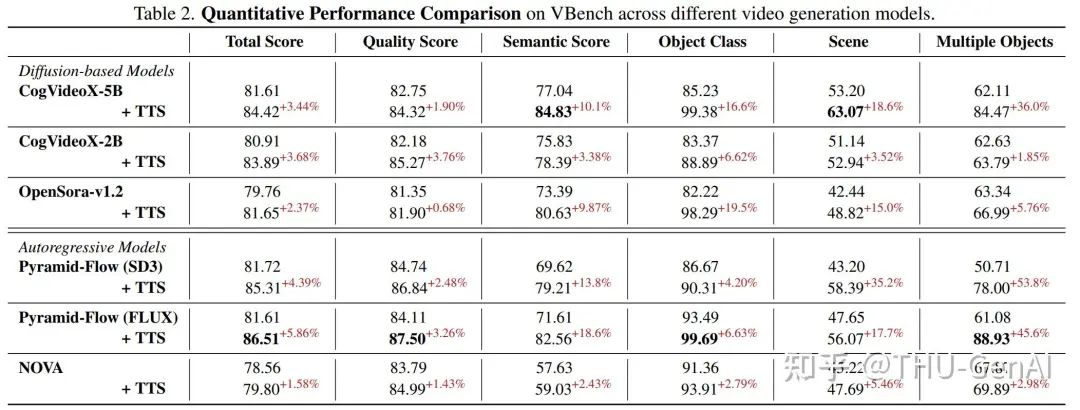
实验结果表明,无论是基于 Diffusion 的模型还是 Autoregressive 范式的模型,都能够通过 Test-Time Scaling 方法实现生成视频性能的全面提升,而无需重新训练一个视频生成模型。
研究团队还注意到,使用不同的 VLM 作为 Verifier 对视频生成质量在多种维度的提升效果有所不同。
因此,为了更充分地发挥 Test-Time Scaling 的潜力并为后续增强 VLM 能力的探索提供思路,研究团队将不同的 Verifier 进行综合,用于 Test-Time Scaling 过程,发现在相同的 NFE (Number of Function Evaluations) 下 Multiple Verifier 相比于单个 Verifier 效果更好。不同 VLM 和视频生成模型对应的结果如下:
可视化结果
研究团队提供了 Tree-of-Frames 层次化提示词和过程中验证的可视化结果:
研究团队还提供了视频生成基础模型和 TTS 结果的对比,更多的可视化请参阅原论文和项目主页。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com