谷歌发布Gemini 2.5 Pro,号称在推理、编码、数学等方面超越OpenAI和DeepSeek,拥有百万token上下文窗口。
原文标题:谷歌又超越DeepSeek了和OpenAI?深夜祭出Gemini Pro 2.5,号称推理、编码、数学能力遥遥领先
原文作者:AI前线
冷月清谈:
怜星夜思:
2、Gemini 2.5 Pro号称具有100万token的上下文窗口,未来还将升级到200万token。超长上下文窗口对于AI模型来说,到底意味着什么?它能解决什么问题,又会带来什么新的挑战?
3、谷歌强调Gemini 2.5 Pro的推理能力是其取得巨大进步的关键。那么,你认为AI的“推理”能力,和人类的“推理”有什么本质区别?未来AI的推理能力会发展到什么程度?
原文内容

刚刚,谷歌正式推出新一代 AI 模型 Gemini 2.5,主打“思考 - 验证 - 回答”的智能推理能力,官方称其为“目前最智能的 AI 模型”。
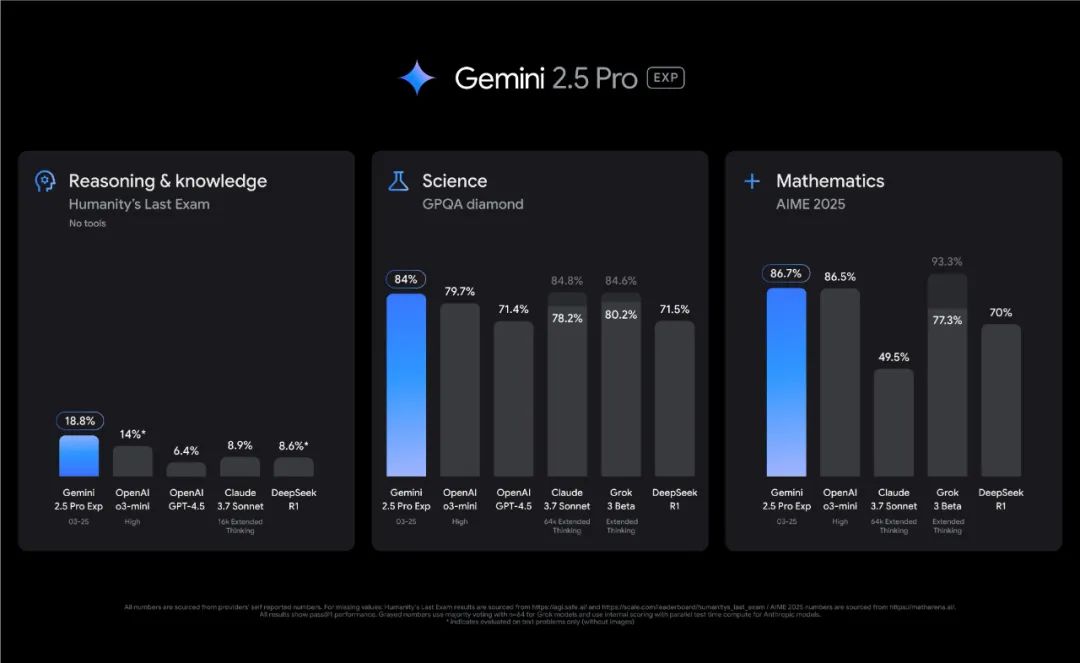
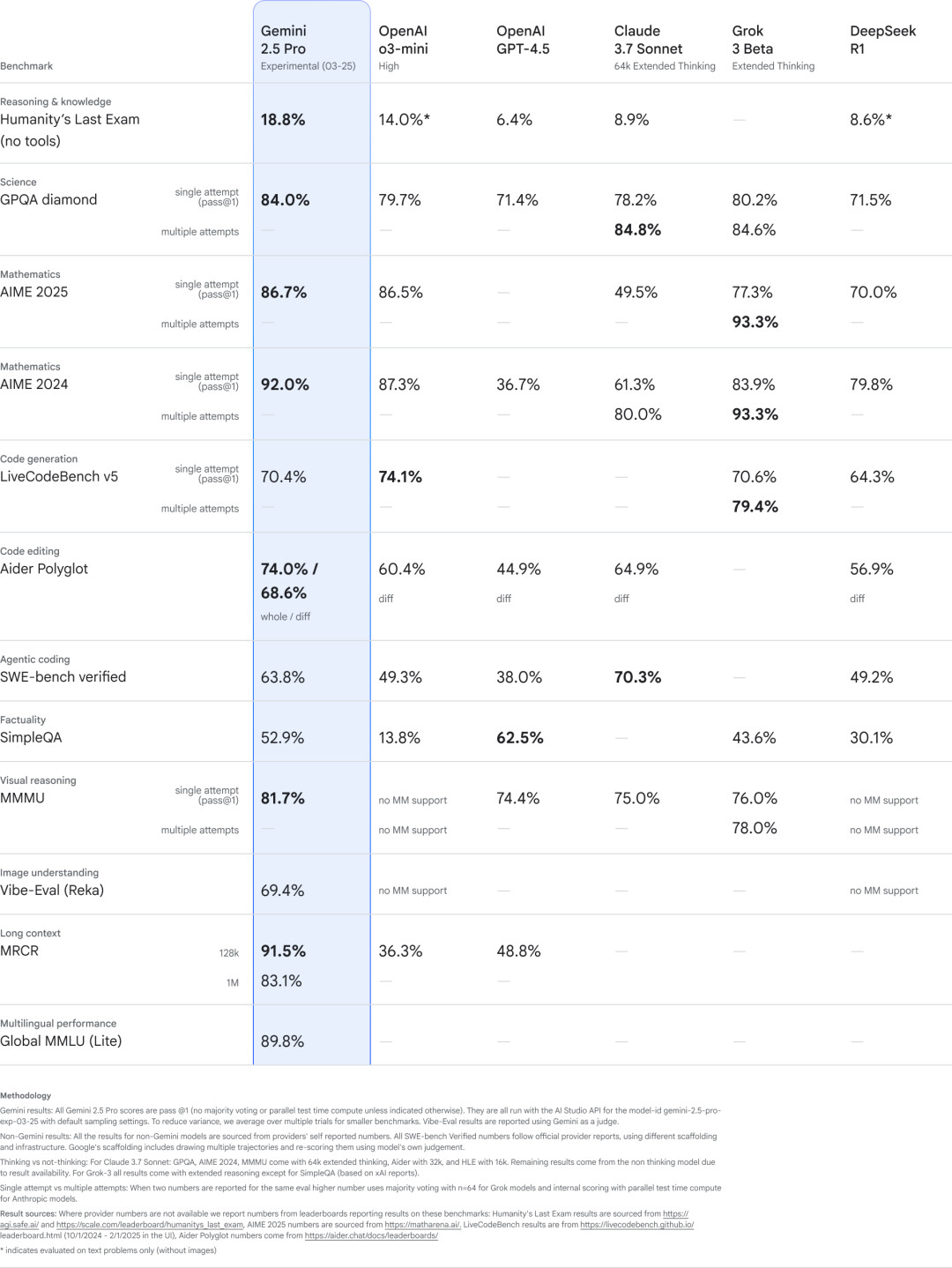
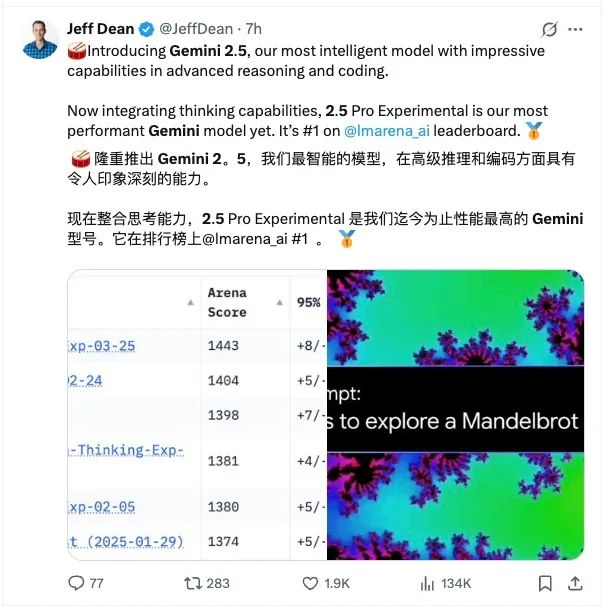
据谷歌称,这个最新版本将“显著增强的基础模型与经过改进的后训练设计”结合起来,由此获得更好的整体性能。该公司宣称,Gemini 2.5 Pro 实验版在理解能力、数学能力、编码能力等常见的 AI 基准测试指标上均已领先于 OpenAI、Anthropic、xAI 乃至 DeepSeek。
据悉,谷歌对该模型进行了多项核心能力升级。
多模态理解方面,支持文本、图像、音频、视频、代码混合输入,可同时分析不同模态的信息并关联推理;100 万 token 上下文窗口(约 75 万单词),能一次性解析《指环王》三部曲的全部文本,未来将升级至 200 万 token,进一步强化长文档处理能力。
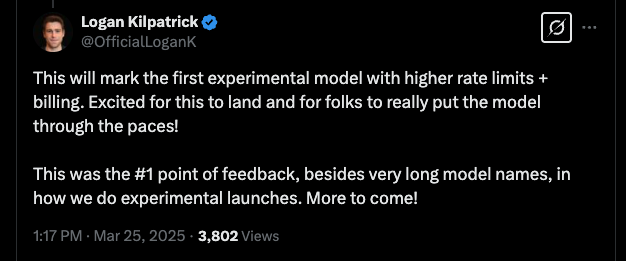
Google AI Studio 产品经理 Logan Kilpatrick 在 X(原 Twitter)上表示,Gemini 2.5 Pro 是“首个支持更高请求速率限制和计费的实验性模型”。
在代码生成能力方面,Aider Polyglot 代码编辑测试:得分 68.6%,超越 OpenAI 和 Anthropic 的同类模型;SWE-bench Verified 测试(真实代码任务测试):以 63.8% 的准确率仅次于 Claude 3.7 Sonnet(70.3%)。
在数学与科学推理方面,在“人类最后考试”(多模态综合测试)中,以 18.8% 的准确率领先多数竞品,且无需依赖外部计算工具,完全依靠模型自身推理能力。
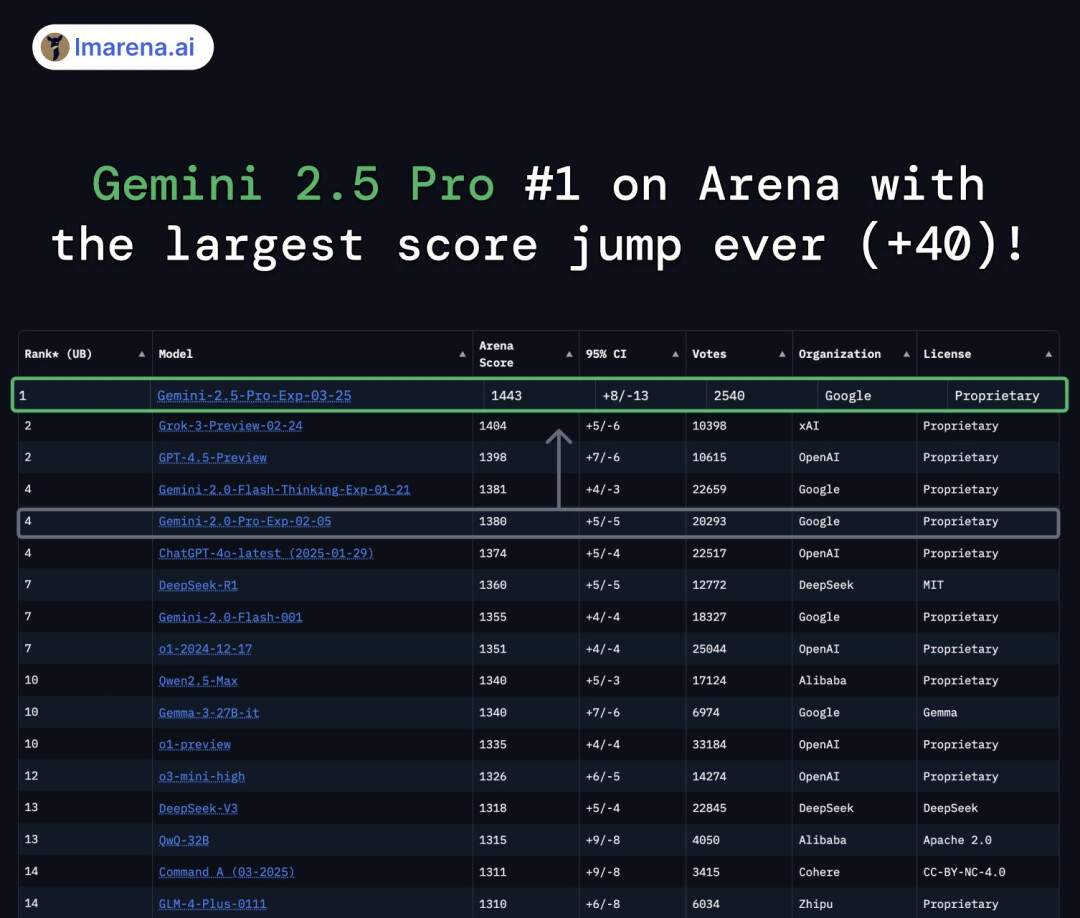
DeepMind CEO Demis Hassabis 在 X 上发帖称,Gemini 2.5 Pro 是“一款非常棒的先进模型,在 LMArena 上以惊人的 +39 ELO 得分排名第一,而且在多模态推理、编码与 STEM 等方面均实现了显著改进。”
谷歌还提到,此番在质量上的巨大飞跃,正是由于 Gemini 新版本“推理”模型的基本属性。其能够逐步处理任务并做出更明智的决策,能够根据复杂的提示词提供更好的答案和响应结果。