阿里云函数计算 FC 部署 QwQ-32B 开源模型,三步快速上手!支持Web界面和Chatbox客户端交互,弹性伸缩,按量付费,降本增效。
原文标题:仅3步!即刻拥有 QwQ-32B,性能比肩全球最强开源模型
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章中使用的是 QwQ-32B 模型,这个模型有什么特点?和其他开源模型相比,优势在哪里?
3、文章中提到 CAP 平台可以实现弹性伸缩,那么在实际使用中,如何根据业务负载动态调整 Ollama 模型服务的预留实例数?有什么最佳实践吗?
原文内容
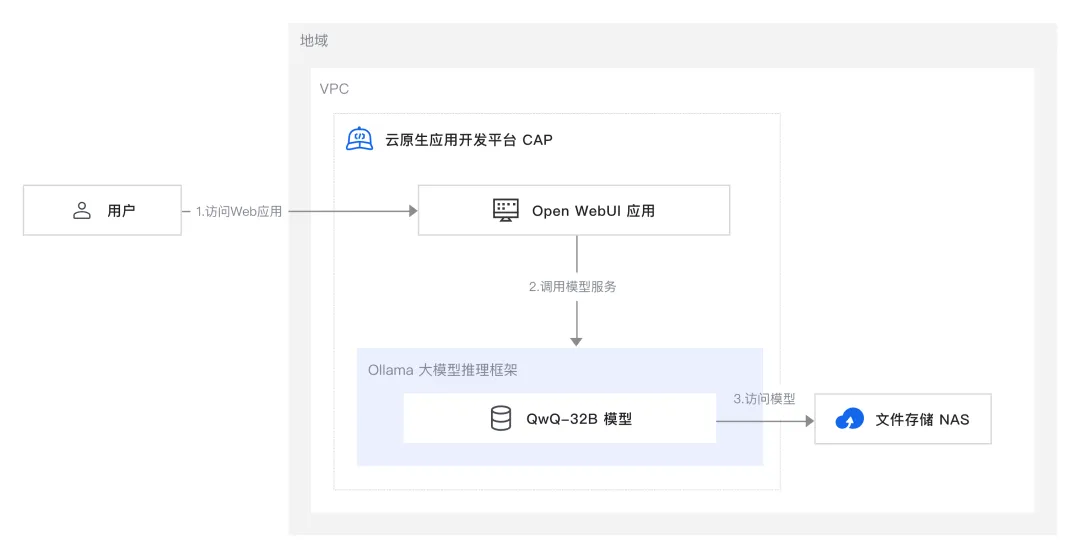
本文详细介绍如何将 QwQ-32B 开源模型部署到函数计算 FC(Function Compute),并通过云原生应用开发平台 CAP(Cloud Application Platform)实现 Ollama 和 Open WebUI 两个 FC 函数的部署。具体来说,Ollama 负责托管 QwQ-32B-GGUF 模型,而 Open WebUI 则用于提供用户界面,支持与模型的交互。
通过 CAP 平台,用户可以快速便捷地完成模型部署,无需担心底层资源管理和运维问题,从而能够专注于应用的创新和开发。CAP 提供了一个免运维的高效开发环境,具备弹性伸缩和高可用性,确保系统在负载变化时仍能保持稳定运行。此外,CAP 采用按量付费模式,用户只需为实际使用的资源付费,有效降低了资源闲置成本。
方案架构
本方案的技术架构包括以下云服务:
-
1 个云原生应用开发平台 CAP 项目:全托管的 Serverless 计算服务,用于部署模型服务与 Web 应用。
-
1 个文件存储 NAS:存储模型。
按照本方案提供的配置完成部署后,会在阿里云上搭建一个如下图所示的运行环境:
部署 QwQ-32B 模型
准备账号
如果您还没有阿里云账号,请访问阿里云账号注册页面[1],根据页面提示完成注册。
2. 开通后,登录函数计算服务控制台,完成阿里云服务授权。
说明
函数计算提供的试用额度(链接[3]领取)和文件存储提供的试用额度(链接[4]领取)可以完全覆盖本教程所需资源消耗。
假设您未领取或免费试用额度已耗尽,预计体验费用将不超过 9 元/小时。实际使用中可能会因您调整实例数而导致费用有所变化,请以控制台显示的实际报价以及最终账单为准。
重要
在函数计算中创建的 GPU 函数,计费基于函数规格乘以实际运行时长。如果没有请求调用,仅收取闲置预留模式下的快照费用。
若不用于生产环境,建议在体验后按提示清理资源,避免继续产生费用。
模型部署
说明
首次使用云原生应用开放平台 CAP 会自动跳转到访问控制快速授权页面,滚动到浏览器底部单击确认授权,等待授权结束后单击返回控制台。
-
部署完成后,类似下图所示。

应用体验
-
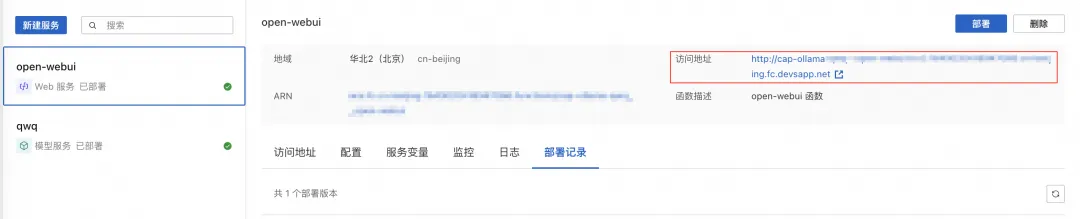
应用部署完成之后按照下图找到访问地址。
-
点击访问地址,即可打开示例应用。

二、与模型对话
在文本输入框中可以进行对话交互。输入问题你是谁?或者其他指令后,调用模型服务获得相应的响应。

三、修改 Ollama 模型服务配置
按照下图所示,通过修改模型服务预留实例数的配置,来实现实例伸缩。

四、使用 Chatbox 客户端配置 Ollama API 进行对话
-
获取 API 接入地址,按照下图所示,复制访问地址。

2. 访问 Chatbox 下载地址[6]下载并安装客户端,本方案以 macOS M3 为例。

-
运行并配置 Ollama API ,单击设置。

-
下拉选择模型提供方Ollama API,填写 API 域名(步骤 1 中获取的访问地址),下拉选择模型cap-qwq:latest,最后单击保存。

-
在文本输入框中可以进行对话交互。输入问题你是谁?或者其他指令后,调用模型服务获得相应的响应。

清理资源
登录云原生应用开发平台 CAP 控制台[7],在左侧导航栏,选择项目,找到部署的目标项目,在操作列单击删除,然后根据页面提示删除项目。

参考链接:
[7]https://cap.console.aliyun.com/
函数计算 FC 部署 QwQ-32B 模型
本方案旨在介绍如何将 QwQ-32B 开源模型部署到函数计算 FC。通过云原生应用开发平台 CAP 部署 Ollama 和 Open WebUI 两个 FC 函数。借助 CAP,用户可以快速便捷地部署模型,而无需担心底层资源管理和运维问题,从而专注于应用的创新和开发。同时 CAP 提供了免运维的高效开发环境,具备弹性伸缩和高可用性,并采用按量付费模式,有效降低资源闲置成本。
点击阅读原文开始部署吧!