FANformer通过融合傅里叶分析网络,提升了LLM的性能和泛化能力,尤其在处理周期性模式和数学推理任务时表现突出,为LLM架构创新提供了新思路。
原文标题:FANformer:融合傅里叶分析网络的大语言模型基础架构
原文作者:数据派THU
冷月清谈:
本文深入探讨了FANformer这一新型大语言模型架构。该架构创新性地将傅里叶分析网络(FAN)融入Transformer的注意力机制,通过显式地建模数据中的周期性模式,有效提升了模型性能和泛化能力。实验结果表明,在同等参数规模和训练数据量下,FANformer优于传统Transformer架构,并在数学推理等任务中展现出更强的泛化能力。FANformer的成功为解决大语言模型的扩展性挑战提供了一个新的方向,预示着其在未来的大规模语言模型中具有广阔的应用前景。
怜星夜思:
1、FANformer通过傅里叶分析增强了LLM对周期性模式的理解,那么在实际应用中,哪些领域的数据具有明显的周期性,FANformer能发挥更大的优势?
2、文章提到FANformer在训练初期损失下降较慢,但后期收敛速度加快。这是否意味着FANformer对训练数据的预处理有更高的要求,例如需要更多的数据清洗或特征工程?
3、FANformer通过将傅里叶分析融入注意力机制,实现了性能提升。那么,是否可以将其他数学工具(例如小波变换、希尔伯特变换等)也融入到LLM的架构中,以进一步提升模型的能力?
2、文章提到FANformer在训练初期损失下降较慢,但后期收敛速度加快。这是否意味着FANformer对训练数据的预处理有更高的要求,例如需要更多的数据清洗或特征工程?
3、FANformer通过将傅里叶分析融入注意力机制,实现了性能提升。那么,是否可以将其他数学工具(例如小波变换、希尔伯特变换等)也融入到LLM的架构中,以进一步提升模型的能力?
原文内容

来源:Deephub Imba本文约2000字,建议阅读6分钟本文将深入探讨FANformer的工作原理及其架构创新,分析使其在性能上超越传统Transformer的关键技术要素。
国内首个原生AI IDE(集成开发环境),来自字节,实测在此:
近期大语言模型(LLM)的基准测试结果引发了对现有架构扩展性的思考。尽管OpenAI推出的GPT-4.5被定位为其最强大的聊天模型,但在多项关键基准测试上的表现却不及某些规模较小的模型。DeepSeek-V3在AIME 2024评测中达到了39.2%的Pass@1准确率,在SWE-bench Verified上获得42%的准确率,而GPT-4.5在这两项基准测试上的得分分别仅为36.7%和38%。
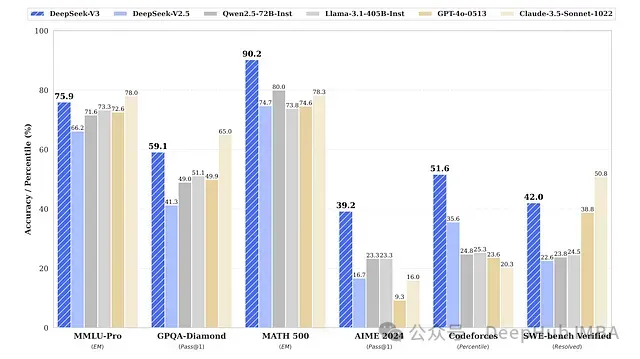
DeepSeek-V3与其他LLM的性能对比(数据来源:ArXiv研究论文《DeepSeek-V3 Technical Report》)
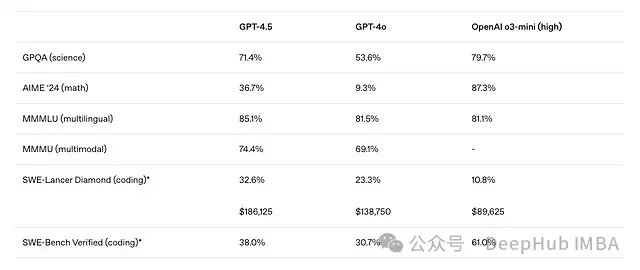
GPT-4.5与其他OpenAI模型的性能对比(数据来源:OpenAI博客文章《Introducing GPT-4.5》)
这一现象促使研究者思考:现有的LLM架构是否需要根本性的改进以实现更高水平的扩展性能?
研究人员最近提出的FANformer架构为这一问题提供了一个可能的解决方案。该架构通过将傅里叶分析网络(Fourier Analysis Network, FAN)整合到Transformer的注意力机制中,形成了一种创新的模型结构。实验数据显示,随着模型规模和训练数据量的增加,FANformer始终表现出优于传统Transformer架构的性能。特别值得注意的是,拥有10亿参数的FANformer模型在性能上超过了同等规模和训练量的开源LLM。
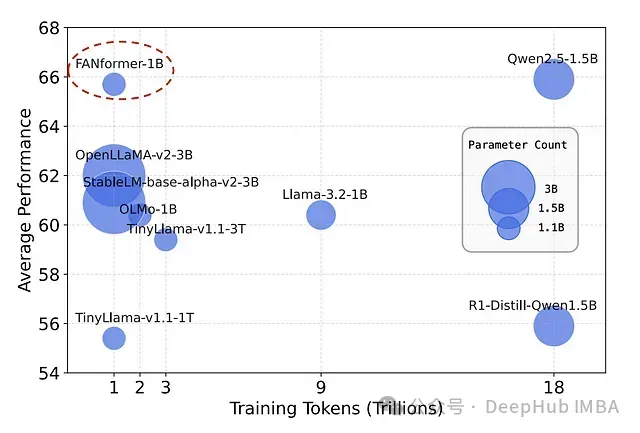
傅里叶分析网络基础
标准深度神经网络(MLP)在捕获和建模训练数据中的大多数模式方面表现良好,但在处理数据中的周期性模式时存在明显的不足。由于实际数据中通常包含隐含的周期性特征,这一局限性会影响传统神经网络的学习效率。
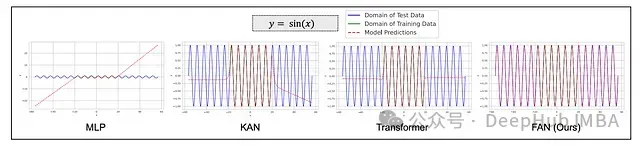
下图展示了一个典型案例,即使在充足的训练资源条件下,Transformer也难以有效地对简单的mod函数进行建模。
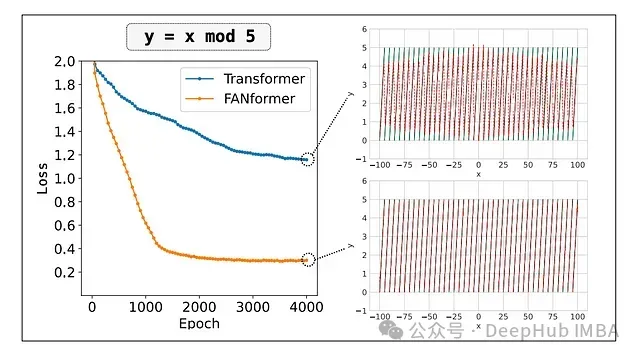
傅里叶分析网络(FAN)通过将傅里叶分析原理直接整合到神经网络结构中,有效解决了这一问题。如下图所示,相较于MLP、KAN和Transformer,FAN能够更准确地对周期性sin函数进行建模。
FAN层可通过以下数学公式表示:
其中:
-
X为输入数据
-
W(p)和W(p̄)为可学习的投影矩阵
-
B(p̄)为偏置项
-
σ表示非线性激活函数
-
||表示向量连接操作
与MLP层应用简单的线性变换后进行非线性激活不同,FAN层明确地将周期性变换(正弦和余弦函数)与线性变换和非线性激活相结合,从而增强了捕获数据中周期性模式的能力。
下图展示了MLP和FAN层在架构和数学表达上的差异:
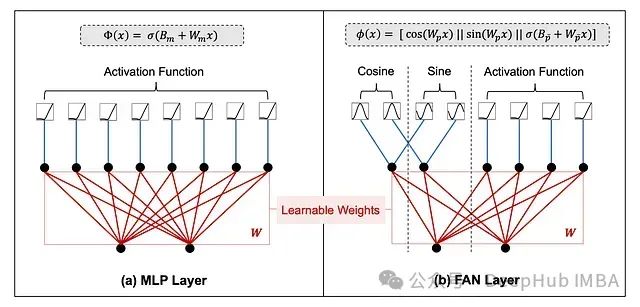
MLP和FAN层的架构差异对比(数据来源:ArXiv研究论文《FAN: Fourier Analysis Networks》)

MLP和FAN层的数学表达差异(数据来源:ArXiv研究论文《FAN: Fourier Analysis Networks》)
FANformer的注意力机制设计
当前主流的LLM基于仅解码器的Transformer架构。FANformer通过从FAN借鉴周期性捕获原理,并将其应用于Transformer架构的注意力机制,形成了一种称为注意力-傅里叶(ATtention-Fourier, ATF)模块的新型结构。
对于长度为l的输入序列s = {s(1), s(2), ..., s(l)},首先将其映射为输入嵌入X(0) = {x(1), x(2), ..., x(l)}。该嵌入通过模型的多个层处理,最终获得输出X(N),其中N为模型的总层数。
具体而言,每一层的处理过程如下:
给定输入嵌入X,其傅里叶变换表示计算为:
注意,此转换使用经过修改的FANLayer',其中原始FANLayer公式中的激活函数σ被替换为恒等函数σ(x) = x。
随后,通过线性变换计算查询(Q)、键(K)和值(V):
其中W(Q)、W(K)和W(V)为可学习权重矩阵,分别用于计算查询(Q)、键(K)和值(V)。
接下来,使用傅里叶变换后的Q、K和V计算缩放点积注意力:
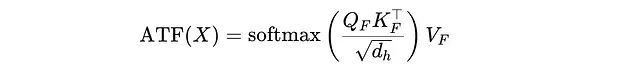
其中d(h)为模型的隐藏维度。
值得注意的是,ATF(X)在数学上等价于Attention(FANLayer′(X)),这意味着傅里叶变换并不改变注意力机制本身,而是改变了输入表示的计算方式。这种设计使FANformer能够与FlashAttention等高级注意力优化技术兼容。
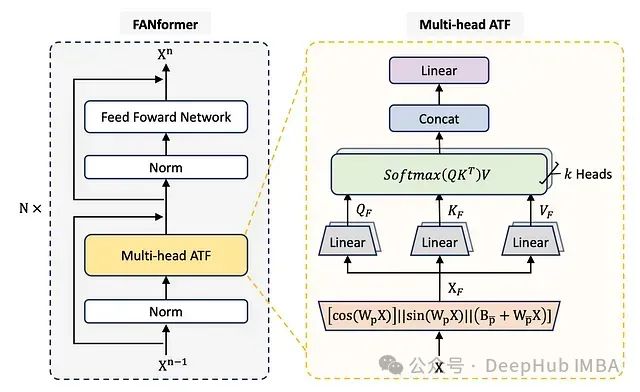
多头ATF机制实现
注意力模块进一步扩展为多头结构,类似于传统的多头注意力机制。对于给定输入X,首先使用ATF模块将其投影到k个独立的注意力头:
对于第i个注意力头:
-
W(Q)(i)、W(K)(i)、W(V)(i)为每个头计算查询(Q(i))、键(K(i))和值(V(i))的可学习权重矩阵,计算如下:
-
d(k)为使用k个注意力头时每个头的维度,计算为d(k) = d(h) / k,其中d(h)为模型的隐藏维度。
所有注意力头的输出经过连接后,通过输出权重矩阵(W(O))进行线性变换:
FANformer的整体架构如下图所示:
与传统多头注意力对比,传统机制中的查询、键和值直接从输入嵌入计算,而不经过任何傅里叶变换处理:
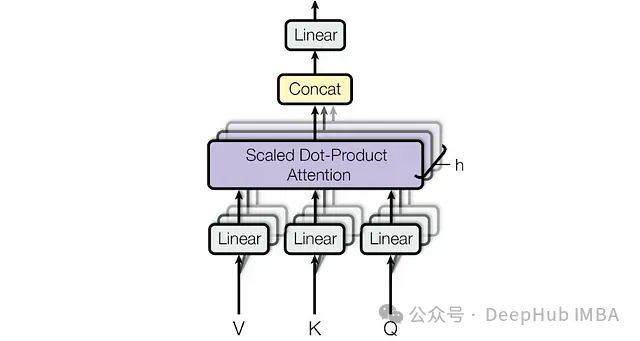
传统多头注意力机制,其中Q、K、V通过每个头的可学习权重矩阵直接从输入嵌入X计算(数据来源:研究论文《Attention Is All You Need》)
多头ATF的伪代码实现如下:

参数p作为一个超参数,控制输入X通过周期性(X_p)与非周期性分量(X_p̄)处理的比例,遵循FANLayer'公式。在实验中,p默认设置为0.25。
FANformer的层级结构
FANformer通过堆叠N个FANformer层构建,每层包含:
-
一个多头ATF(注意力-傅里叶)模块
-
一个前馈网络(FFN)模块
多头ATF输出基于前述公式计算:
每层的处理采用预归一化(Pre-Norm)策略处理输入(X(n)),并将原始输入添加到从MultiHeadATF计算的输出中:
随后前馈网络(FFN)模块对Y(n)进行转换:
其中FFN采用SwiGLU激活函数:
其中W(1)、W(2)和W(3)为可学习权重矩阵,⊗表示元素级乘法操作。
FANformer性能评估
研究人员通过将ATF模块集成到开源LLM OLMo中构建FANformer,并以OLMo作为基准Transformer模型进行比较。实验使用从OLMo的训练数据集Dolma中采样的tokens,预训练了不同规模的FANformer模型。
模型规模扩展性分析
在模型规模扩展实验中,FANformer在所有参数规模上始终优于标准Transformer,且仅使用标准Transformer 69.2%的参数即可达到相当的性能水平。
研究还评估了一个名为Transformer + ATM的FANformer变体,该变体使用MLP层替代FAN层。结果显示,其扩展曲线与标准Transformer非常接近,这表明周期性捕获能力的架构改进是FANformer性能提升的关键因素。
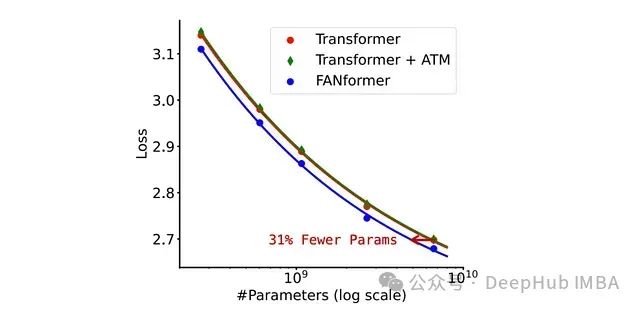
进一步的实验表明,FANformer仅需使用比标准Transformer少20.3%的训练数据即可达到相当的性能水平。
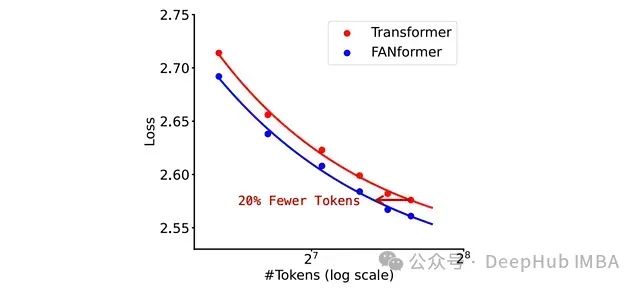
下游任务性能评估
FANformer-1B的零样本(zero-shot)性能与7个相似规模/训练量的开源LLM在8个下游任务基准上进行了对比,这些基准包括:
-
ARC-C和ARC-E(高级推理)
-
BoolQ(布尔问题回答)
-
HellaSwag(常识推理完成)
-
OBQA(开放书籍问题回答)
-
PIQA(物理推理)
-
SCIQ(科学问题回答)
-
WinoGrande(共指消解)
实验结果表明,FANformer-1B在较少训练数据条件下持续优于其他同等参数规模的LLM。特别值得注意的是,FANformer-1B的性能与当前10亿参数级别最先进的LLM之一Qwen2.5-1.5B相当。
研究还将FANformer与从DeepSeek-R1提炼出的模型R1-Distill-Qwen1.5B进行了对比。结果显示,尽管后者在推理任务上表现优异,但在大多数非推理常识任务上无法超越FANformer,这凸显了预训练过程的重要性,并表明模型提炼技术本身不足以确保下游任务上的全面性能优势。
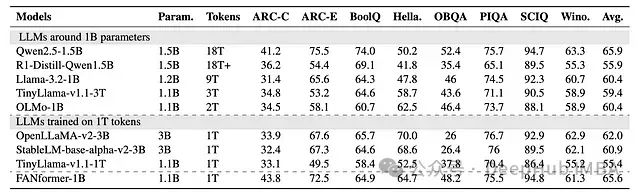
FANformer-1B与其他同等级开源LLM在下游任务上的零样本性能对比。
训练动态分析
在训练初期阶段,FANformer的损失下降速度相对较慢,可能是因为模型尚未有效识别数据中的周期性模式。然而,随着训练进行,FANformer的收敛速度超过了标准Transformer。
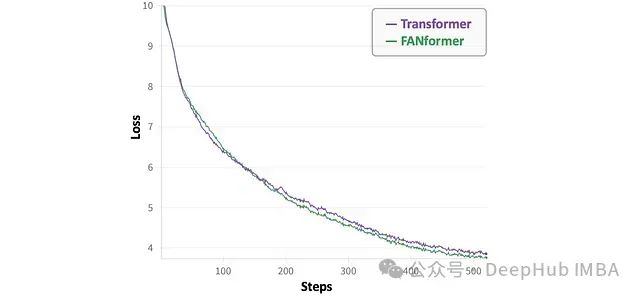
指令遵循能力评估
预训练的FANformer-1B模型在tulu-3-sft-olmo-2-mixture数据集上进行了监督微调(SFT),形成FANformer-1B-SFT。同样,OLMo的10亿参数版本OLMo-1B-SFT也在相同数据集上进行了监督微调。
这些模型在以下四个基准上进行了评估:
-
MMLU(通用知识和推理能力)
-
TruthfulQA(回答真实性和信息性)
-
AlpacaEval(指令遵循质量)
-
ToxiGen(有害内容过滤能力)
评估结果再次表明,FANformer-1B-SFT在MMLU、AlpacaEval和TruthfulQA基准上的性能优于OLMo-1B-SFT。

FANformer-1B和OLMo-1B的评估结果对比。对于MMLU、AlpacaEval和TruthfulQA,数值越高表示性能越好;对于ToxiGen,数值越低表示性能越好。
数学推理能力分析
2024年的一项研究表明,基于Transformer的LLM主要通过基于案例的推理解决数学问题,即记忆训练数据中的特定示例,并在推理过程中通过寻找相似案例进行泛化。这与基于规则的推理不同,后者涉及学习潜在数学规则并系统性地应用这些规则来解决问题。
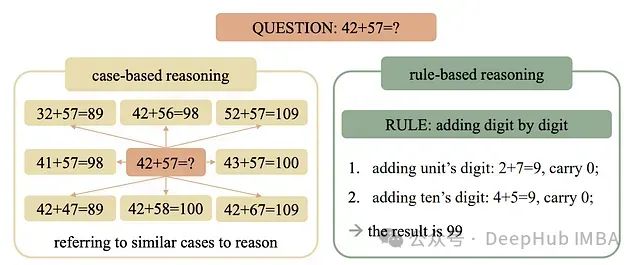
基于案例的推理与基于规则的推理对比(数据来源:ArXiv研究论文《Case-Based or Rule-Based: How Do Transformers Do the Math?》)
为分析FANformer的数学推理机制,研究人员对OLMo-1B和FANformer-1B在两种数学任务上进行了评估:
-
模加法:求解c = (a + b) mod 113,其中a, b ∈ [0, 112]
-
线性回归:求解c = a + 2b + 3,其中a, b ∈ [0, 99]
评估采用留方块法(leave-square-out):从训练集中移除一个方形区域的数据点,并在剩余数据上训练模型,确保模型未接触到该方形区域。随后在测试阶段评估模型对这些未见数据点的预测能力。
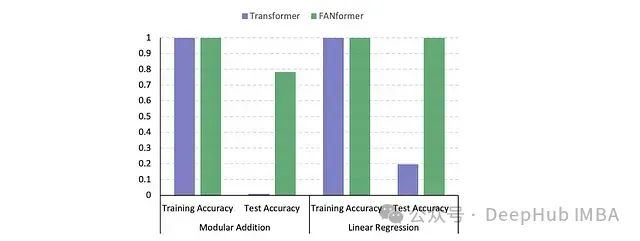
实验显示,两种架构在训练数据集上都达到了接近完美的准确率。然而,在测试数据上,Transformer表现出明显的性能下降。
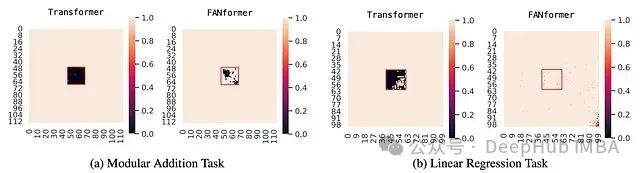
Transformer在留方块测试中表现出"黑洞"现象,即在未见过的数据上准确率接近零,这证实了它可能未能有效应用基于规则的推理来解决数学问题。
相比之下,FANformer的测试结果显著不同。在测试图中未观察到明显的"黑洞"现象,这表明FANformer能够学习并应用解决问题的数学规则,从而实现更好的泛化性能。
FANformer和Transformer在模加法和线性回归任务上的性能对比
总结
FANformer通过将周期性捕获能力显式编码到深度神经网络架构中,实现了相较于传统Transformer架构的显著性能提升。尽管仍需更全面的实验验证,但FANformer已展现出在未来大规模语言模型中的应用潜力。在相同参数规模和训练资源条件下,FANformer能够提供更高的性能和更强的泛化能力,特别是在涉及周期性模式和数学推理的任务中。这种架构创新为解决大语言模型的扩展性挑战提供了一种有前景的新方向。
论文:
https://www.arxiv.org/abs/2502.21309
编辑:王菁
