阿里开源Qwen2.5-VL-32B,视觉推理能力大幅提升,数学能力增强,或成多模态Agent部署优选。
原文标题:阿里深夜开源Qwen2.5-VL新版本,视觉推理通杀,32B比72B更聪明
原文作者:机器之心
冷月清谈:
阿里通义千问团队开源了Qwen2.5-VL-32B-Instruct模型,该模型在回复人类偏好、数学推理能力和图像细粒度理解与推理方面都有显著提升。它优化了输出风格,使回答更详细、格式更规范,更符合人类偏好;复杂数学问题求解的准确性显著提升;在图像解析、内容识别以及视觉逻辑推导等任务中表现出更强的准确性和细粒度分析能力。相较于72B模型,32B版本可能是在多模态AI Agent部署实践中的最佳选择。在性能测试中,Qwen2.5-VL-32B-Instruct在多模态任务中表现突出,甚至超越了更大规模的72B模型,同时在纯文本能力上也达到了同规模的最优表现。官方Demo展示了其在细粒度图像理解与推理、数学推理以及图片内容识别等方面的能力。
怜星夜思:
1、Qwen2.5-VL-32B既然在某些方面超越了72B模型,那么模型参数量越大越好这个说法还成立吗?我们应该如何理解模型参数量和模型性能之间的关系?
2、Qwen2.5-VL-32B在数学推理能力上有所提升,这对实际应用有什么意义?除了做题以外,还有哪些场景能用到这种能力?
3、通义千问团队下一步将聚焦于长且有效的推理过程,以突破视觉模型在处理高度复杂、多步骤视觉推理任务中的边界。你认为在实现这个目标的过程中,会遇到哪些挑战?有什么可能的解决方案?
2、Qwen2.5-VL-32B在数学推理能力上有所提升,这对实际应用有什么意义?除了做题以外,还有哪些场景能用到这种能力?
3、通义千问团队下一步将聚焦于长且有效的推理过程,以突破视觉模型在处理高度复杂、多步骤视觉推理任务中的边界。你认为在实现这个目标的过程中,会遇到哪些挑战?有什么可能的解决方案?
原文内容
机器之心报道
机器之心编辑部
就在 DeepSeek V3「小版本更新」后的几个小时,阿里通义千问团队也开源了新模型。
择日不如撞日,Qwen2.5-VL-32B-Instruct 就这么来了。
相比此前的 Qwen2.5-VL 系列模型,32B 模型有如下改进:
-
回复更符合人类主观偏好:调整了输出风格,使回答更加详细、格式更规范,并更符合人类偏好。
-
数学推理能力:复杂数学问题求解的准确性显著提升。
-
图像细粒度理解与推理:在图像解析、内容识别以及视觉逻辑推导等任务中表现出更强的准确性和细粒度分析能力。
对于所有用户来说,在 Qwen Chat 上直接选中 Qwen2.5-VL-32B,即可体验:https://chat.qwen.ai/
32B 版本的出现,解决了「72B 对 VLM 来说太大」和「7B 不够强大」的问题。如这位网友所说,32B 可能是多模态 AI Agent 部署实践中的最佳选择:

不过团队也介绍了,Qwen2.5-VL-32B 在强化学习框架下优化了主观体验和数学推理能力,但主要还是基于「快速思考」模式。
下一步,通义千问团队将聚焦于长且有效的推理过程,以突破视觉模型在处理高度复杂、多步骤视觉推理任务中的边界。
32B 可以比 72B 更聪明
先来看看性能测试结果。
与近期的 Mistral-Small-3.1-24B、Gemma-3-27B-IT 等模型相比,Qwen2.5-VL-32B-Instruct 展现出了明显的优势,甚至超越了更大规模的 72B 模型。
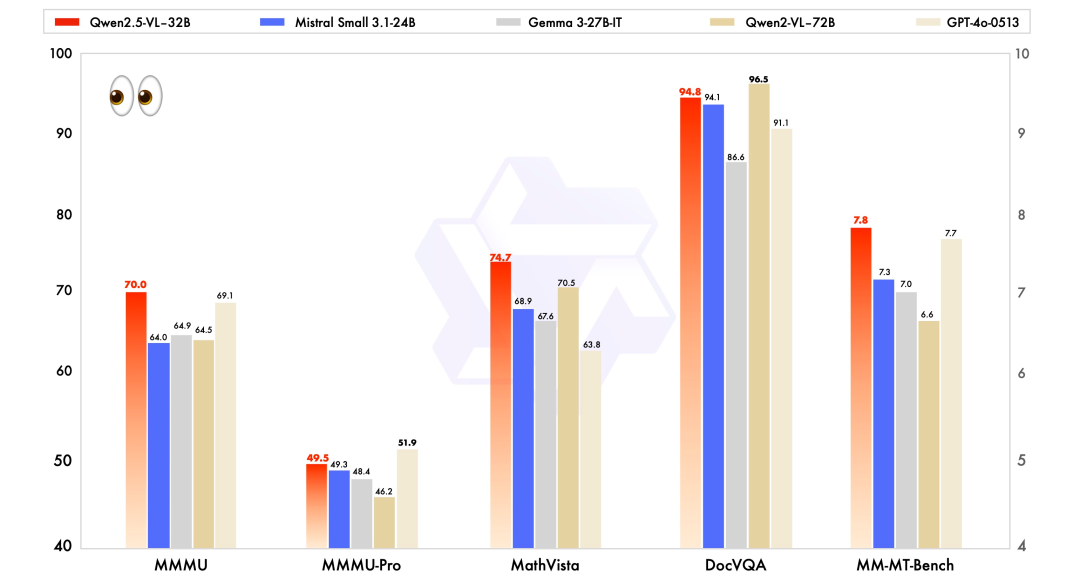
如上图所示,在 MMMU、MMMU-Pro 和 MathVista 等多模态任务中,Qwen2.5-VL-32B-Instruct 均表现突出。
特别是在注重主观用户体验评估的 MM-MT-Bench 基准测试中,32B 模型相较于前代 Qwen2-VL-72B-Instruct 实现了显著进步。
视觉能力的进步,已经让用户们感受到了震撼:

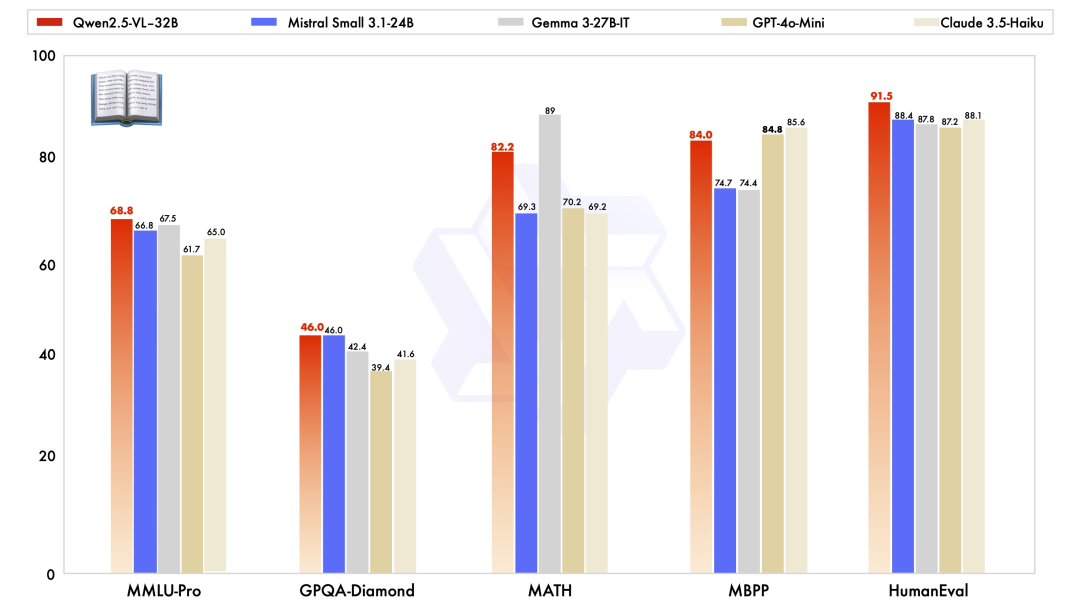
除了在视觉能力上优秀,Qwen2.5-VL-32B-Instruct 在纯文本能力上也达到了同规模的最优表现。
实例展示
或许很多人还好奇,32B 版本的升级怎么体现呢?
关于「回复更符合人类主观偏好」、「数学推理能力」、「图像细粒度理解与推理」这三个维度,我们通过几个官方 Demo 来体会一番。
第一个问题,是关于「细粒度图像理解与推理」:我开着一辆卡车在这条路上行驶,现在是 12 点,我能在 13 点之前到达 110 公里外的地方吗?

显然,从人类的角度去快速判断,在限速 100 的前提下,卡车无法在 1 小时内抵达 110 公里之外的地方。
Qwen2.5-VL-32B-Instruct 给出的答案也是「否」,但分析过程更加严谨,叙述方式也是娓娓道来,我们可以做个参考:

第二个问题是「数学推理」:如图,直线 AB、CD 交于点 O,OD 平分∠AOE,∠BOC=50.0,则∠EOB=()
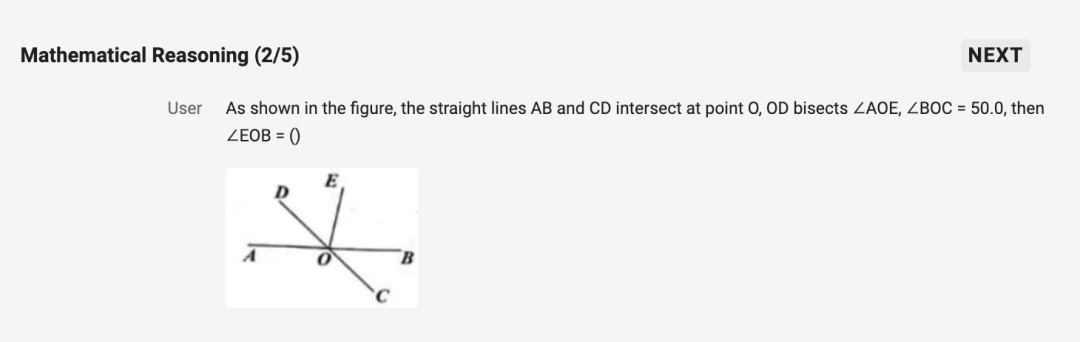
答案是「80」:


第三个题目的数学推理显然更上难度了:
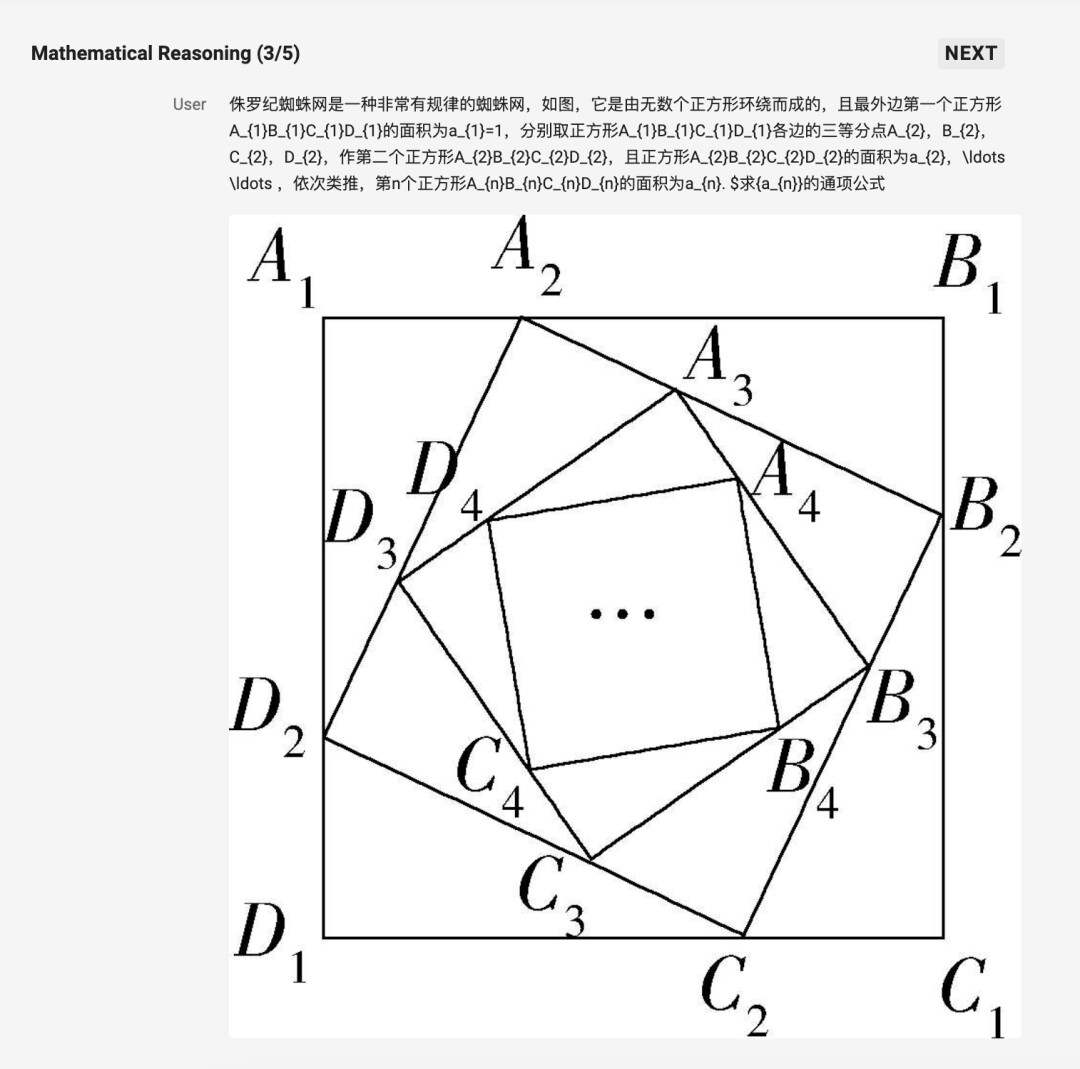
模型给出的答案特别清晰,解题思路拆解得很详细:



在下面这个图片内容识别任务中,模型的分析过程也非常细致严谨:
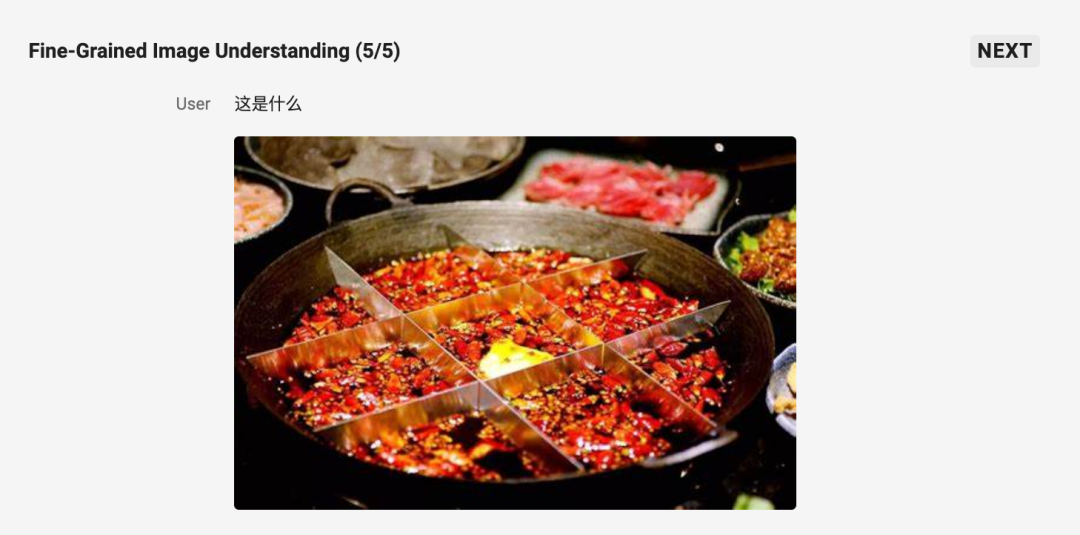


关于 Qwen2.5-VL-32B-Instruct 的更多信息,可参考官方博客。
博客链接:https://qwenlm.github.io/zh/blog/qwen2.5-vl-32b/

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com