DeepSeek V3升级,代码能力大幅提升,开源免费,有用户测评认为可媲美Claude 3.5 Sonnet。
原文标题:DeepSeek V3深夜低调升级,代码进化令人震惊,网友实测可媲美Claude 3.5/3.7 Sonnet
原文作者:机器之心
冷月清谈:
DeepSeek V3于近日进行了更新,升级至「DeepSeek-V3-0324」版本,并采用了更宽松的MIT开源协议。新版本最引人注目的特点是其代码能力,有用户测试表明,DeepSeek-V3-0324在数学推理和前端开发方面的表现甚至优于Claude 3.5和Claude 3.7 Sonnet。用户使用DeepSeek-V3-0324轻松创建HTML5、CSS和前端代码,生成了包含图像和交互元素的响应式网站,仅用958行代码便实现了完整的前端功能,并且结果适用于移动设备。此外,DeepSeek-V3-0324在编写代码方面的能力突出,早期测试显示其为所有开源选项中最好的非推理模型。有用户通过测试发现,DeepSeek- V3-0324 已经有了一些思维链模型的影子,能够展示详细的推理步骤。另有用户将其与OpenAI的o1-pro进行比较,认为DeepSeek-V3-0324可以实现o1-pro约70%的性能,但它免费,且API价格更低。
怜星夜思:
1、DeepSeek V3这次升级在代码生成能力上的突破,你觉得对低代码/零代码平台会产生什么影响?
2、文章提到DeepSeek V3这次更新采用了更宽松的MIT开源协议,你认为这对开发者和整个AI社区意味着什么?
3、DeepSeek V3在某些方面已经可以媲美甚至超越Claude 3.5 Sonnet,你觉得国内大模型厂商在追赶国际领先水平时,还有哪些关键点需要突破?
2、文章提到DeepSeek V3这次更新采用了更宽松的MIT开源协议,你认为这对开发者和整个AI社区意味着什么?
3、DeepSeek V3在某些方面已经可以媲美甚至超越Claude 3.5 Sonnet,你觉得国内大模型厂商在追赶国际领先水平时,还有哪些关键点需要突破?
原文内容
机器之心报道
机器之心编辑部
昨夜,DeepSeek V3 毫无征兆地来了一波更新,升级到了「DeepSeek-V3-0324」版本。
目前,新版本在 Hugging Face 上可以下载并部署。
-
Hugging Face 地址:https://huggingface.co/deepseek-ai/DeepSeek-V3-0324/tree/main
不过,DeepSeek-V3-0324 没有公布详细的模型卡。我们只能看到它的参数为 6850 亿以及张量类型。

此外,DeepSeek-V3-0324 支持了更宽松的 MIT 开源协议。

模型放出来后,DeepSeek-V3-0324 的代码能力让所有人震惊了!
有人表示,经过自己的测试,DeepSeek-V3-0324 在数学推理和前端开发方面的表现优于 Claude 3.5 和 Claude 3.7 Sonnet。
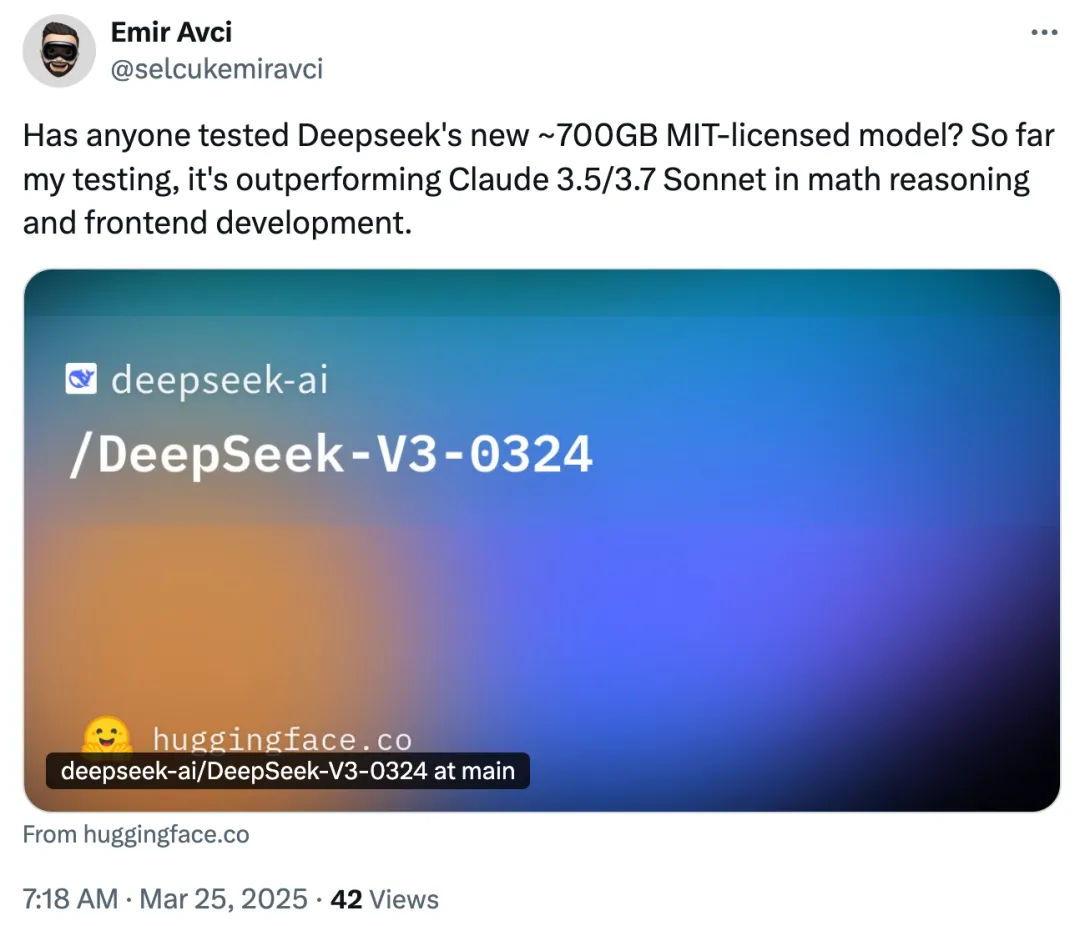
图源:https://x.com/selcukemiravci/status/1904311856313028870
X 博主「@KuittinenPetri」表示,Anthropic 和 OpenAI 陷入了困境。更新后的 DeepSeek-V3-0324 可以轻松免费地创建漂亮的 HTML5、CSS 和前端。
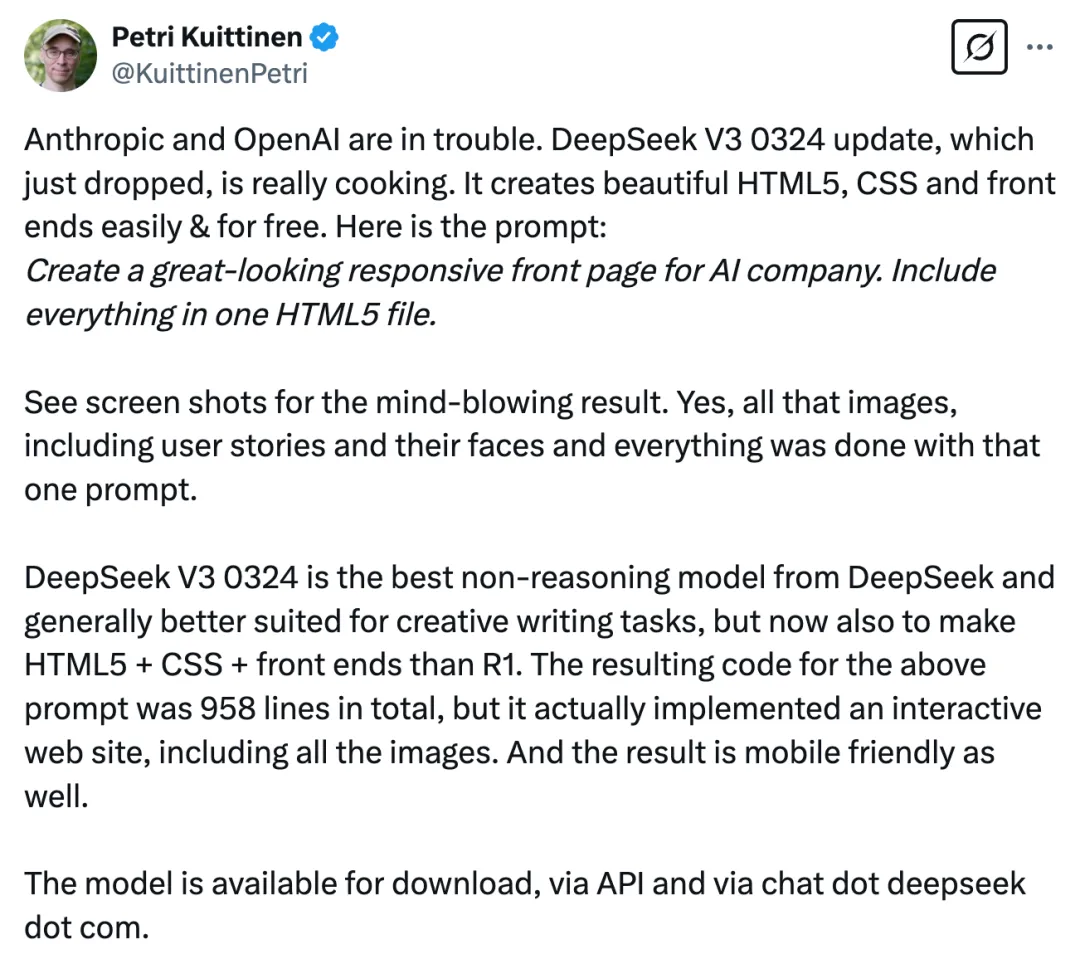
图源:https://x.com/KuittinenPetri/status/1904224441384771909
提示词如下:为 AI 公司「NexusAI」创建一个外观精美的响应式首页,将所有内容包含在一个 HTML5 文件中。结果如下图所示,所有图像,包括用户故事和他们的面孔,一切都是用这个提示完成的。
他认为:DeepSeek-V3-0324 是 DeepSeek 最好的非推理模型,通常更适合创意写作任务,但现在也比 R1 更适合制作 HTML5 + CSS + 前端。上述提示的结果代码总共 958 行,但它实际上实现了一个交互式网站,包括所有图像。并且结果也适用于移动设备。
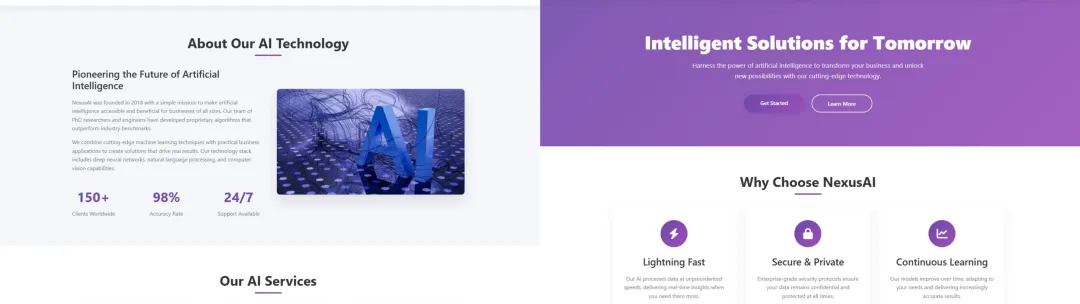
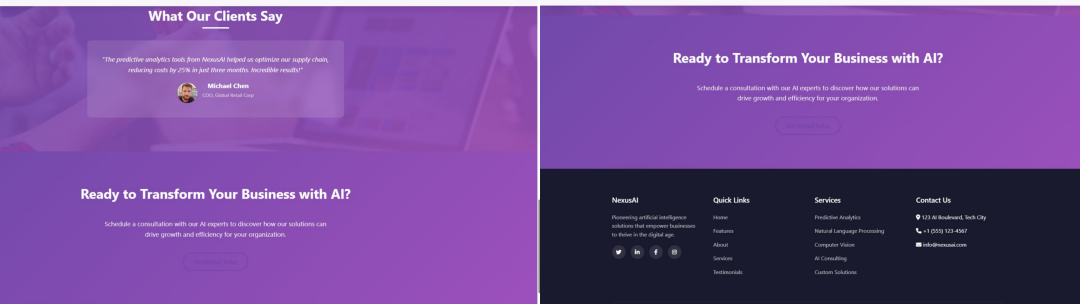
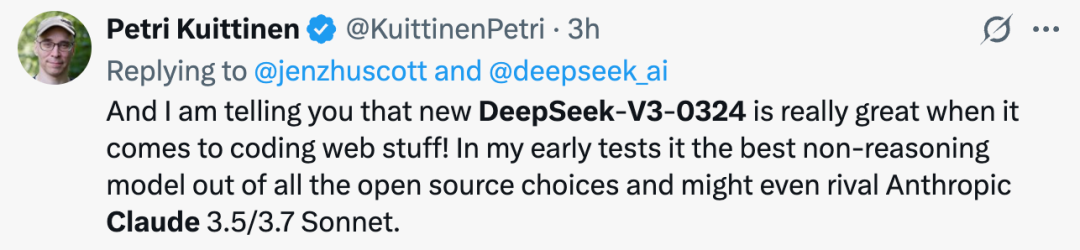
他还称,DeepSeek-V3-0324 在编写代码方面确实很棒!早期测试显示,它是所有开源选择中最好的非推理模型,甚至可以与 Claude 3.5/3.7 Sonnet 相媲美。
另一位网友也让 DeepSeek-V3-0324 创建网站,只见该模型一口气写了 800 多行代码,中途一次都没卡壳,生成的网站布局也非常完美。
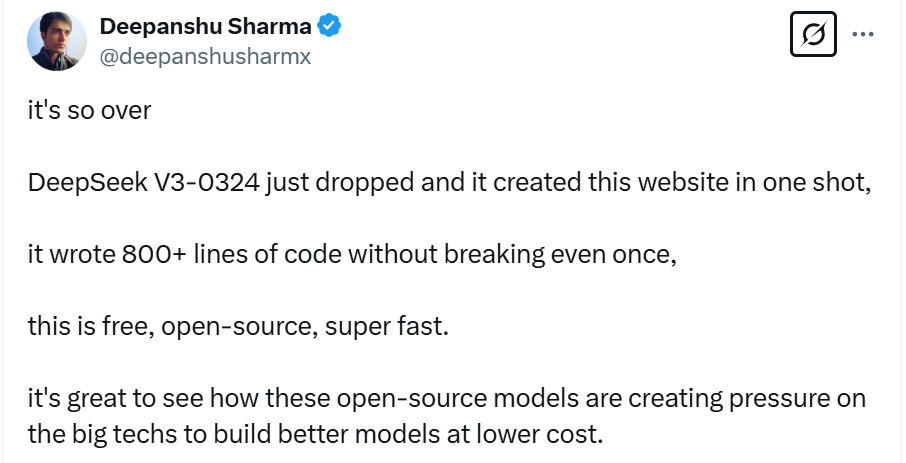
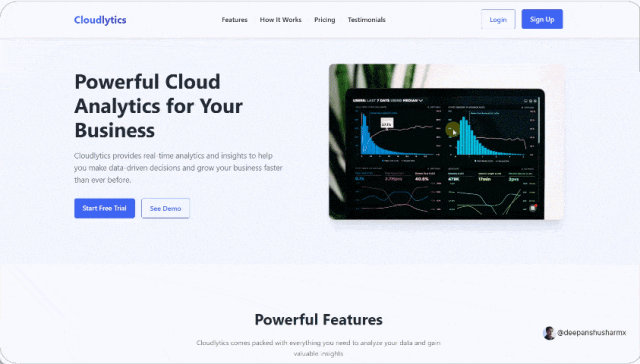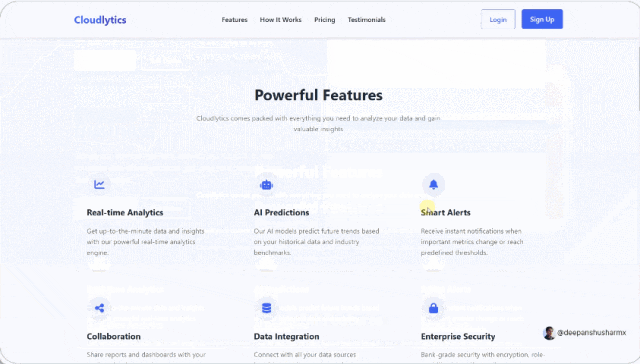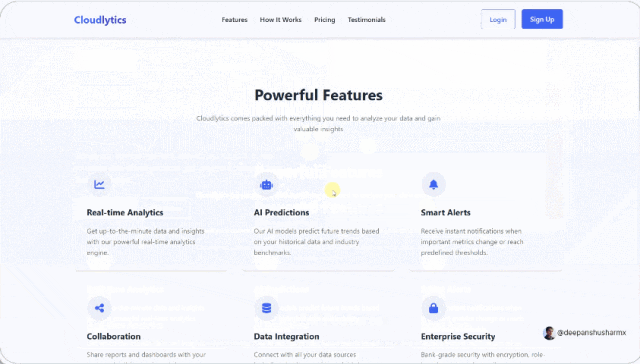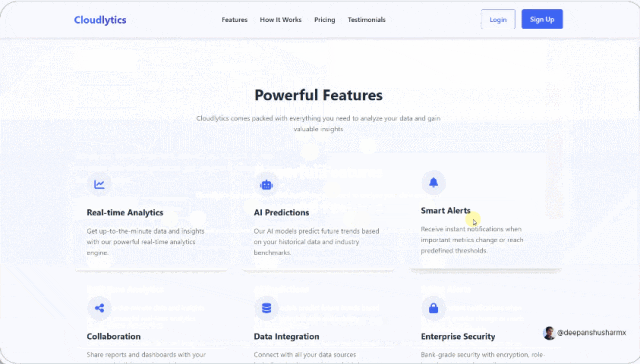
这位网友还把提示语放出来了,简单的几行字,大家可以前去一试。
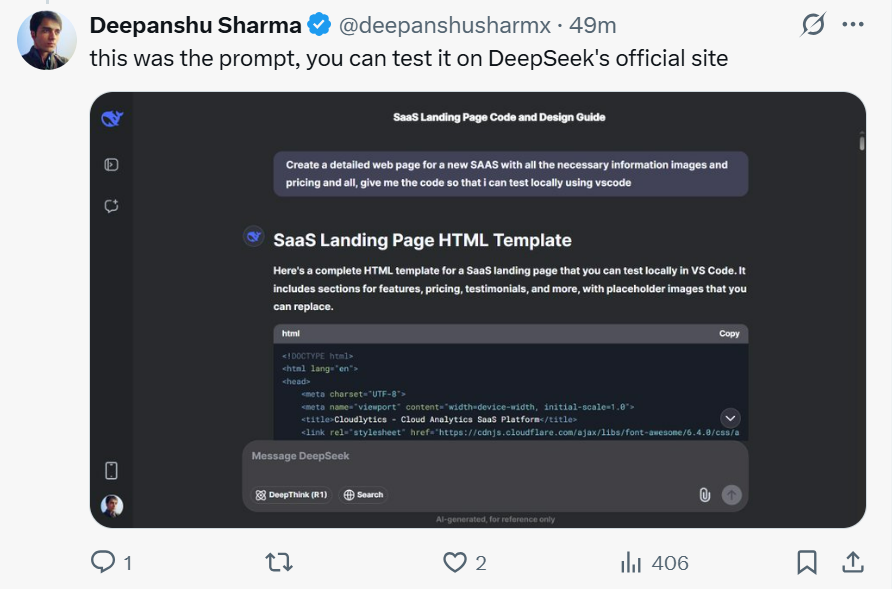
Hyperbolic 联合创始人兼 CTO Yuchen 称自己的氛围测试显示,DeepSeek- V3-0324 已经有了一些思维链模型的影子。
他测试了题目「strawberry 中有多少个 r」,可以看到,DeepSeek-V3-0324 展示了详细的推理步骤。他表示,真正的「Open AI」又赢了。
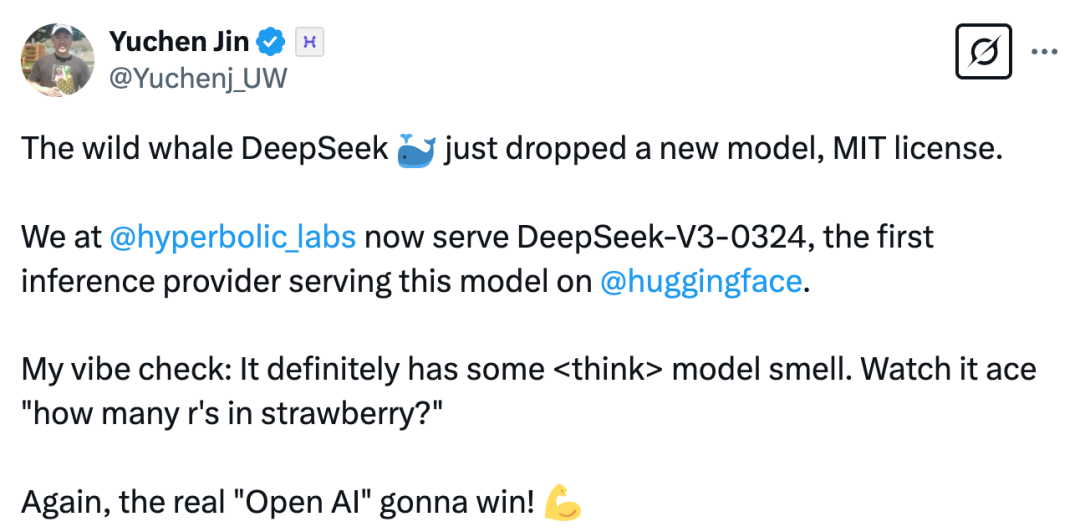
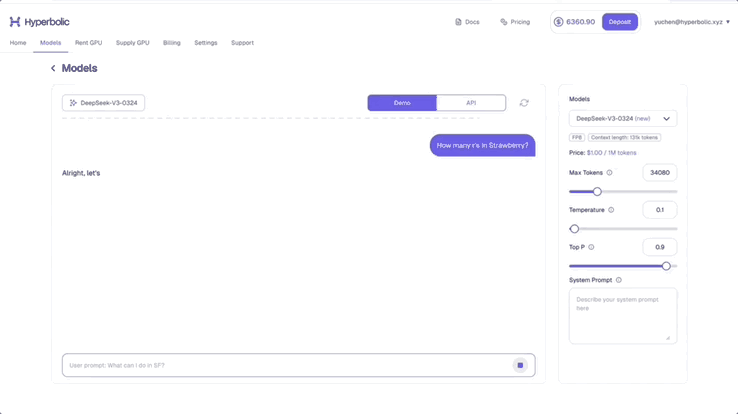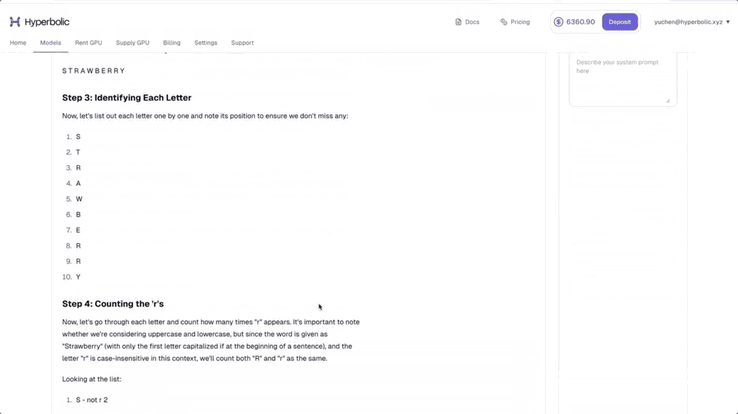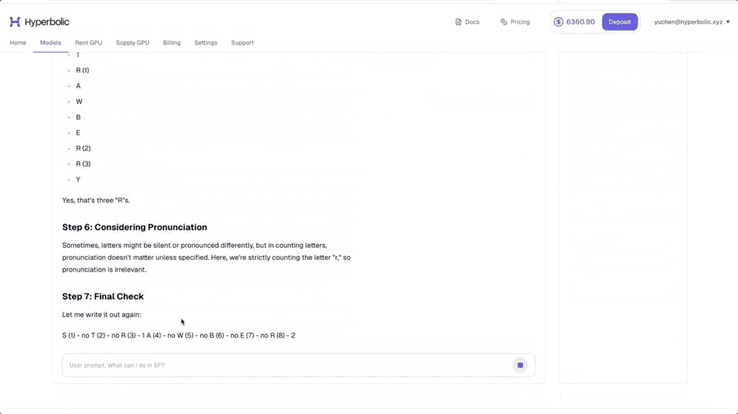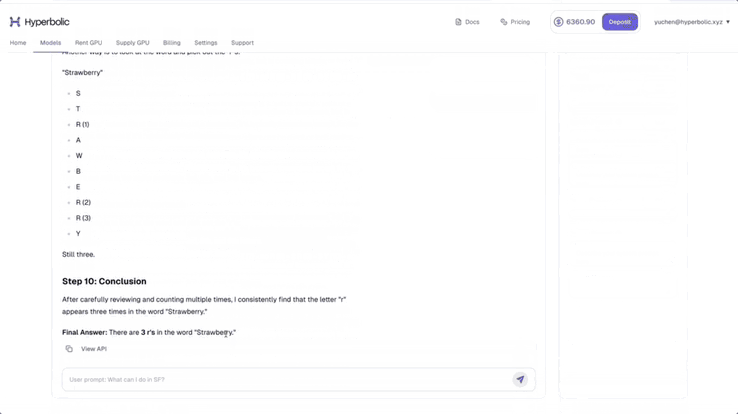
图源:https://x.com/Yuchenj_UW/status/1904223627509465116
还有人将 DeepSeek-V3-0324 与 OpenAI o1-pro 生成小球的效果进行了比较。下面是 o1-pro 的效果:

他表示,DeepSeek-V3-0324 大约可以实现 o1-pro70% 的性能,但它免费并且 API 价格比后者便宜了至少 50 倍。二者选谁一目了然!
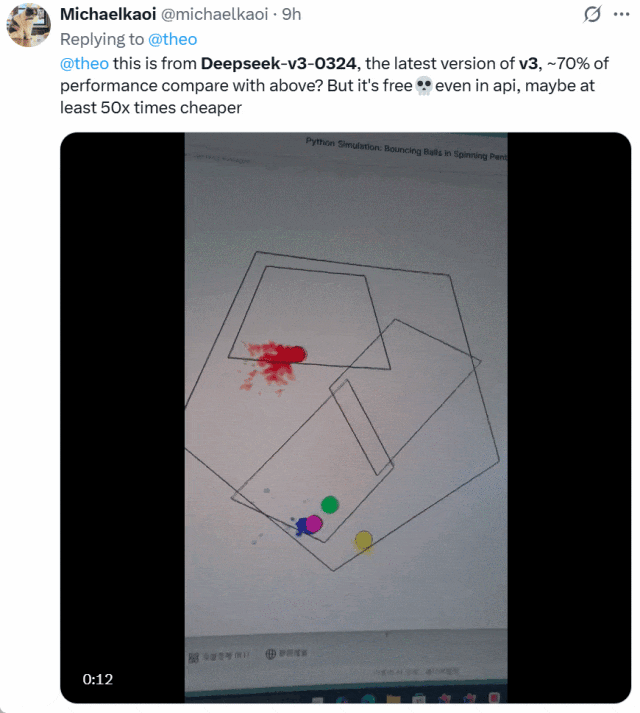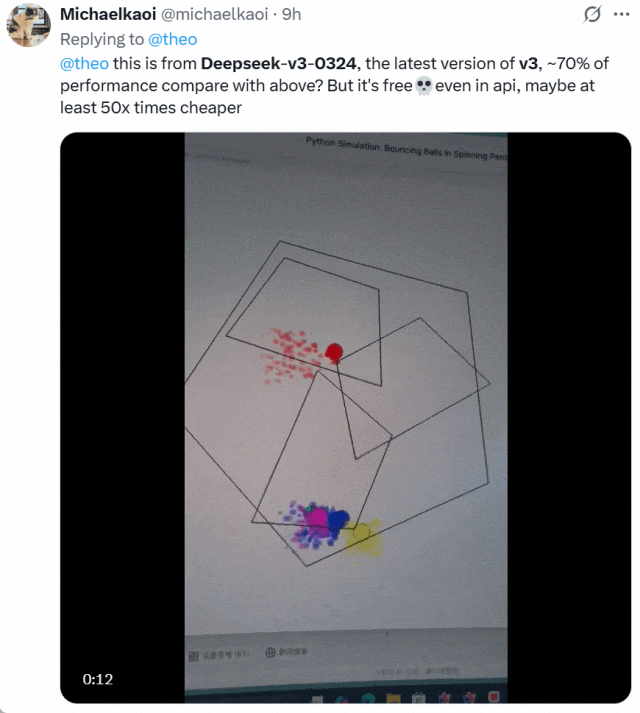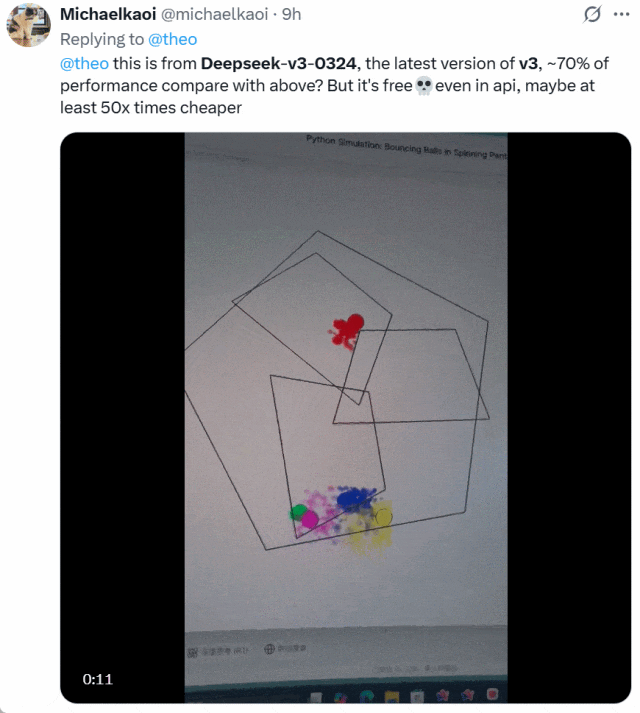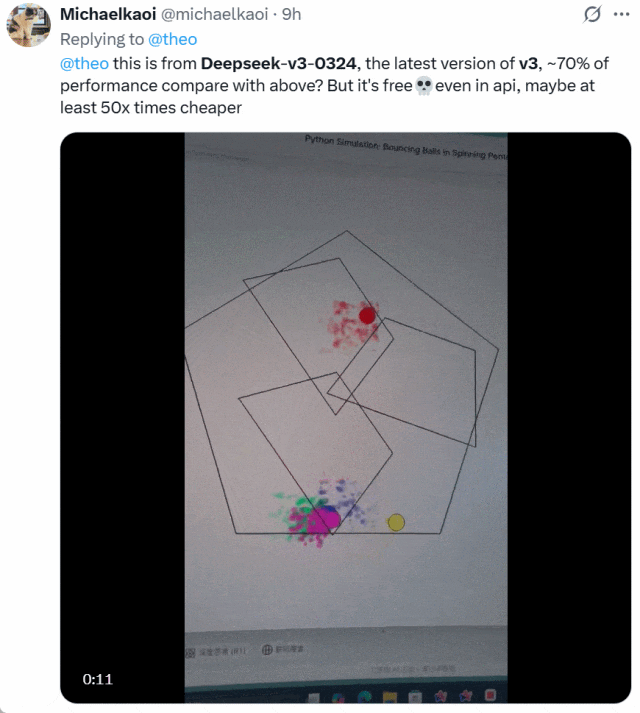
图源:https://x.com/michaelkaoi/status/1904178015833297342
X 博主「orange.ai」对 DeepSeek V3、DeepSeek-V3-0324 与 Claude Sonnet 3.7 的海报设计结果进行了比较,同样表示前端代码能力相比上代有了显著增强。

图源:https://x.com/oran_ge/status/1904306405823467526
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com