北大&阿里提出UFO:一种统一的细粒度视觉感知框架,无需SAM,16个token让MLLM实现精准分割,支持检测、分割等多种任务。
原文标题:统一细粒度感知!北大&阿里提出UFO:无需SAM,16个token让MLLM实现精准分割
原文作者:机器之心
冷月清谈:
北京大学和阿里通义万相实验室提出了UFO,一种统一细粒度感知的多模态大模型。该方法基于特征检索,将分割任务重新定义为计算token特征和图像特征的相似度,无需SAM,仅需少量token即可实现精细分割。UFO还支持文本格式的目标框输出,通过并行解码高效支持密集检测和分割。相较于依赖复杂任务解码器的传统MLLM,UFO充分挖掘了多模态大模型的图像表征能力,将目标框转换为文本坐标,统一了检测和分割任务的输出形式。针对密集感知场景,UFO采用并行解码策略,简化任务难度并加速推理。实验结果表明,UFO在多任务基准、视觉定位、推理分割和视网膜血管分割等任务上均表现出色,证明了其在细粒度视觉感知方面的有效性和优越性。
怜星夜思:
1、UFO方法中,将分割任务转化为计算token特征和图像特征的相似度,这种思路的优势是什么?它相比传统分割方法有哪些改进?
2、UFO在密集感知场景中采用并行解码策略,将多个预测拆分成多个单目标的子任务,这种策略是如何简化任务难度并加速推理的?
3、UFO是如何通过将目标框转换为文本格式的坐标,来实现检测和分割任务的统一的?这种统一表示方式的优势是什么?
2、UFO在密集感知场景中采用并行解码策略,将多个预测拆分成多个单目标的子任务,这种策略是如何简化任务难度并加速推理的?
3、UFO是如何通过将目标框转换为文本格式的坐标,来实现检测和分割任务的统一的?这种统一表示方式的优势是什么?
原文内容

本文作者来自北京大学和阿里通义万相实验室。其中论文第一作者是汤昊,北京大学 2022 级博士生,目前主要关注统一的多模态任务建模算法。指导教授是王立威老师,北京大学智能学院教授,曾获 NeurIPS 2024 最佳论文奖、ICLR 2023 杰出论文奖及 ICLR 2024 杰出论文提名奖。
无需 SAM 和 Grounding DINO,MLLM 也能做分割和检测!统一细粒度感知的多模态大模型 UFO 来了!

-
论文标题:UFO: A Unified Approach to Fine-grained Visual Perception via Open-ended Language Interface
-
论文链接:https://arxiv.org/abs/2503.01342
-
开源代码:https://github.com/nnnth/UFO
-
开源模型:https://huggingface.co/kanashi6/UFO
具体来说,UFO 提出了一种基于特征检索的分割方法,将分割任务重新定义为计算 token 特征和图像特征的相似度,无需 SAM,最多仅需输出 16 个 token 即可实现 MLLM 的精细分割。UFO 还支持文本格式的目标框输出,通过并行解码高效支持密集检测和分割。
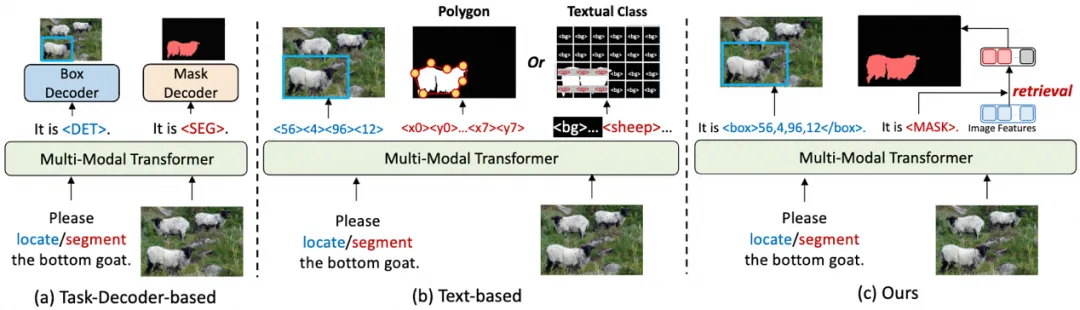
背景介绍
多模态大模型(MLLM)统一了视觉-语言任务,但在细粒度感知任务中(如检测、分割)仍依赖任务解码器(如 SAM、Grounding DINO),结构和训练非常复杂。
基于文本的方法采用粗糙的多边形表示,表达能力不足,且在密集场景(如 COCO 数据集)中性能不佳。因此,亟需开发无需额外解码器、与视觉-语言任务统一且性能优异的细粒度感知方法。
为此,研究团队提出了基于特征检索的方式来支持分割:模型通过预测<MASK>标记,计算其特征与图像特征的相似度实现分割。
这种方式有效地挖掘了多模态大模型的图像表征能力。研究团队认为,既然多模态大模型可以回答物体的类别和位置,那么图像特征中已经包含物体的分割信息。
对于检测任务,UFO 将目标框转换成文本格式的坐标,使得检测和分割的任务输出都可以通过文本统一。
针对密集感知场景,研究团队提出了一种并行解码策略,将多个预测拆分成多个单目标的子任务,通过局部图像特征进行区分。这种方式可以大大简化任务难度,同时加速推理。
方法细节
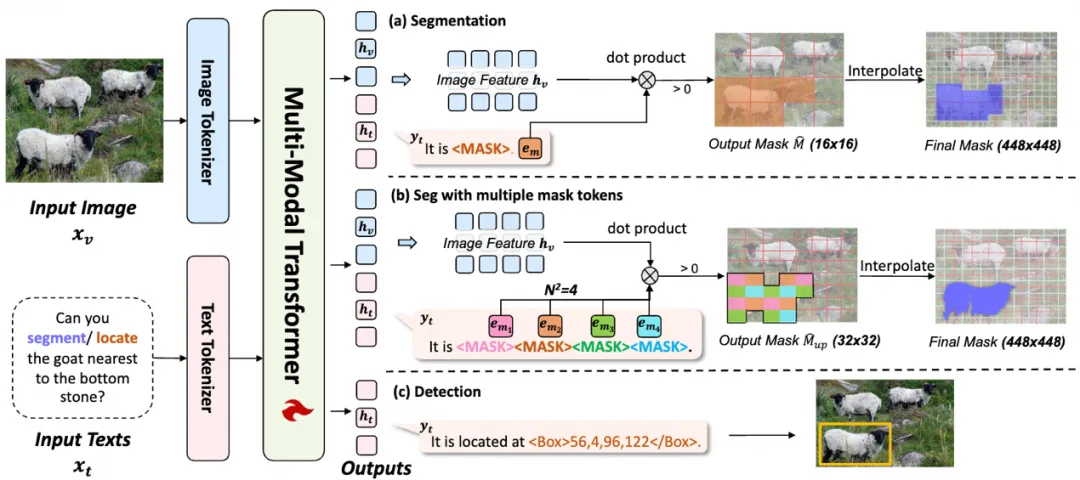
基于特征检索的分割方式
在执行分割时,模型被训练输出<MASK>标记,如上图(a)所示。给定输入图像 和分割提示
和分割提示 ,模型生成文本响应
,模型生成文本响应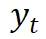 以及相应的文本特征
以及相应的文本特征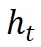 和图像特征
和图像特征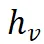 :
:
从中提取与<MASK>标记对应的掩码标记特征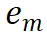 。然后通过缩放点积计算掩码标记特征
。然后通过缩放点积计算掩码标记特征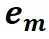 与图像特征
与图像特征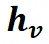 之间的相似性。检索正分数以形成二值掩码
之间的相似性。检索正分数以形成二值掩码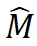 。该过程表示为:
。该过程表示为:
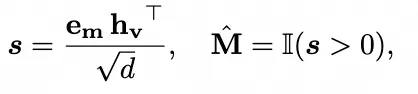
其中 d 是特征维度,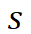 表示相似性分数,
表示相似性分数,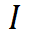 是指示函数,将相似性分数转换为二值掩码。
是指示函数,将相似性分数转换为二值掩码。
通过多个掩码标记上采样
在上述方法中,相似度使用下采样的图像特征计算,导致生成的掩码分辨率低。
为此,研究团队提出了一种通过预测多个掩码标记进行上采样的方法。
给定图像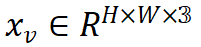 ,下采样后的图像特征为
,下采样后的图像特征为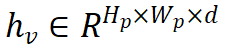 ,模型需要自回归地预测
,模型需要自回归地预测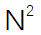 个<MASK>标记,其特征表示为
个<MASK>标记,其特征表示为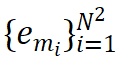 。每个标记对应于 NxN 上采样网格中的一个位置,如上图(b)所示。
。每个标记对应于 NxN 上采样网格中的一个位置,如上图(b)所示。
。每个标记对应于 NxN 上采样网格中的一个位置,如上图(b)所示。
对于每个掩码标记特征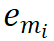 ,计算其与视觉特征
,计算其与视觉特征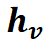 的相似性,得到
的相似性,得到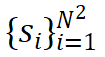 然后,这些分数被连接并重塑为上采样后的相似性图:
然后,这些分数被连接并重塑为上采样后的相似性图:
然后,这些分数被连接并重塑为上采样后的相似性图:
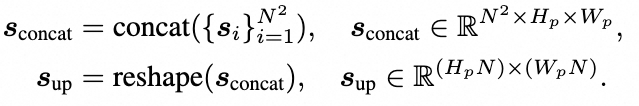
最后在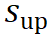 中检索正分数,以生成上采样后的二值掩码
中检索正分数,以生成上采样后的二值掩码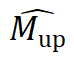 。默认情况下,N 设置为 4,预测 16 个<MASK>标记,这将输出掩码上采样 4 倍。
。默认情况下,N 设置为 4,预测 16 个<MASK>标记,这将输出掩码上采样 4 倍。
。默认情况下,N 设置为 4,预测 16 个<MASK>标记,这将输出掩码上采样 4 倍。
多任务数据模版
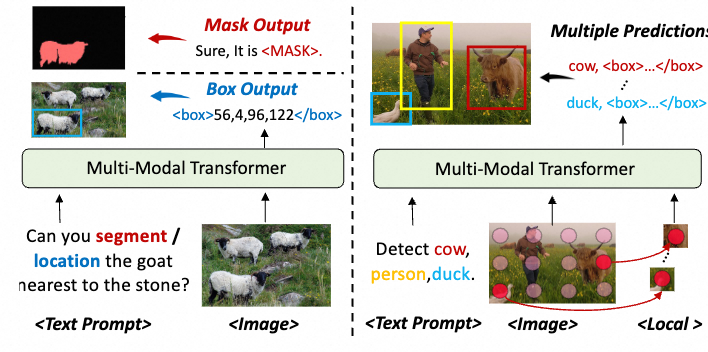
对于单一预测的任务,任务模板为:<Text Prompt><Image><Text Response>。
对于多预测任务,比如目标检测和实例分割,UFO 将其拆分为多个单一预测的独立子任务,使得他们能在同一个批处理内并行。模板结构是:<Text Prompt><Image><Local><Text Response>。其中<Local>指局部图像特征,作为局部视觉提示,用于区分不同子任务。
如上图右侧所示,UFO 在整个图像上均匀采样网格点,并在每个网格位置插值局部图像特征。每个网格点预测最近的目标,如果没有则预测结束标记。
实验结果
多任务训练
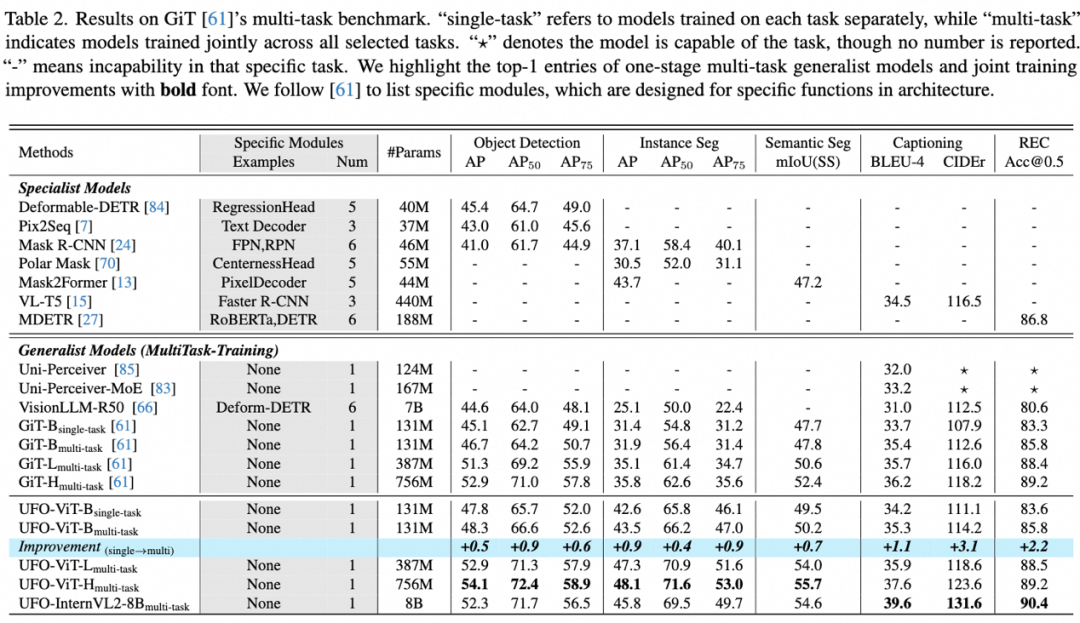
UFO 在 GiT 提出的多任务基准上取得显著提升,在 COCO 实例分割上相比 GiT-H 提升 12.3 mAP,在 ADE20K 语义分割上提升 3.3 mIoU。
视觉定位
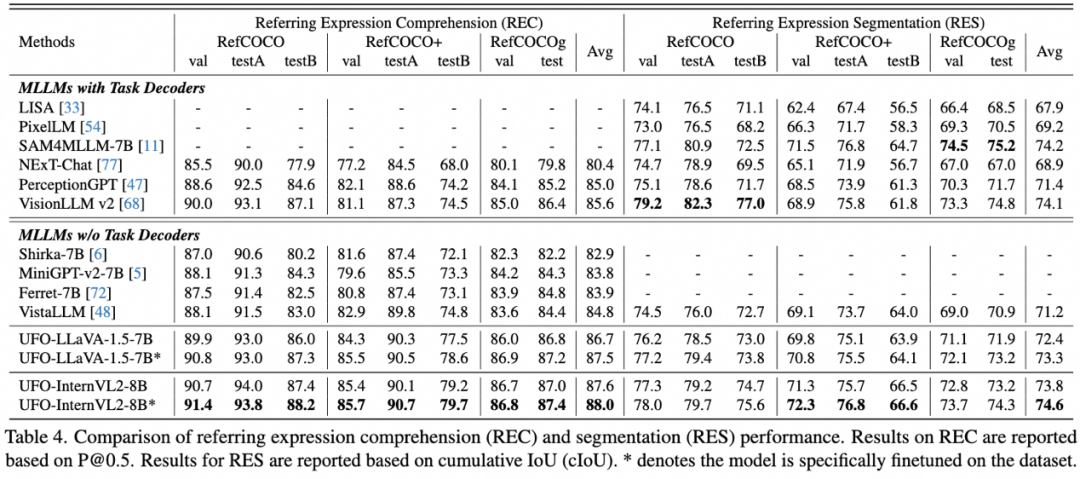
无需任务解码器,UFO 在引用表达式理解(REC)和分割(RES)两种任务展现出优越的性能。
推理分割
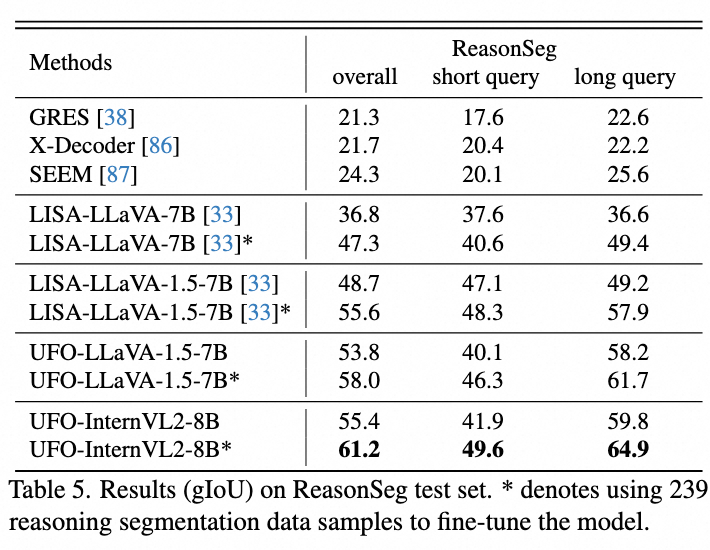
推理分割要求模型进行深层推理得出分割目标,更加困难。UFO 可以深度融合文本推理和分割能力,性能超过基于 SAM 的 LISA。
视网膜血管分割
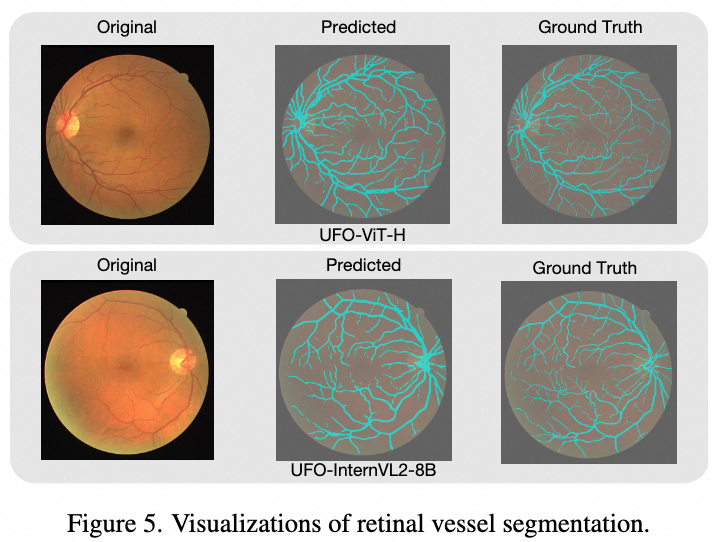
视网膜血管形状不规则且狭窄,难以用多边形表示。UFO 在 DRIVE 上进行了训练,取得了 77.4 的 Dice 系数,验证了在极细粒度结构上的有效性。
深度估计
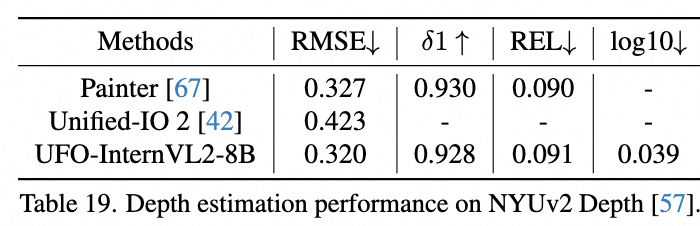
UFO 可以用类似分割的方式支持深度估计,取得具有竞争力的性能。
可视化结果
UFO 可以适应任意数量的预测和任意形式的描述。

采用 4 个<MASK>标记时,每个掩码标记能捕捉不同细节,使得融合的掩码更精细。

结论
UFO 提出了一种统一的细粒度感知框架,通过开放式语言界面处理各种细粒度的视觉感知任务,无需修改架构即可在多模态大模型上实现出色的性能。
UFO 的核心创新是一种新颖的特征检索方法用于分割,有效利用了模型的图像表征能力。
UFO 的统一方式完全对齐视觉-语言任务,提供了一种灵活、有效且可扩展的解决方案,以增强多模态大模型的细粒度感知能力,为构建更通用的多模态模型铺平了道路。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com