SeeGround提出了一种全新的零样本3D视觉定位框架,无需3D训练数据,仅通过2D视觉语言模型即可实现精准的3D物体定位,为相关领域提供了更高效的解决方案。
原文标题:CVPR 2025 | Qwen让AI「看见」三维世界,SeeGround实现零样本开放词汇3D视觉定位
原文作者:机器之心
冷月清谈:
香港科技大学(广州)等机构的研究团队提出了名为SeeGround的零样本3D视觉定位(3DVG)框架。该框架无需任何3D训练数据,仅利用2D视觉语言模型(VLM)即可实现3D物体定位。其核心在于透视自适应模块(PAM)和融合对齐模块(FAM),前者通过动态视角选择,确保VLM准确理解物体的空间关系,后者通过视觉提示增强技术,将2D图像中的物体与3D坐标信息对齐。实验结果表明,SeeGround在多个基准测试中显著超越了现有零样本方法,该方法通过创新设计,成功解决了现有零样本方法在视觉细节和空间推理上的不足,为增强现实、机器人导航和智能家居等领域提供了更高效、灵活的3D物体定位方案。
怜星夜思:
1、SeeGround 框架如何解决 VLM 在 3D 物体定位中遇到的空间关系推理难题?
2、SeeGround 如何将 2D 视觉信息与 3D 空间坐标对齐,以提高定位精度?
3、SeeGround 在哪些实际应用场景中具有潜力?它相比于传统的 3D 视觉定位方法有哪些优势?
2、SeeGround 如何将 2D 视觉信息与 3D 空间坐标对齐,以提高定位精度?
3、SeeGround 在哪些实际应用场景中具有潜力?它相比于传统的 3D 视觉定位方法有哪些优势?
原文内容

3D 视觉定位(3D Visual Grounding, 3DVG)是智能体理解和交互三维世界的重要任务,旨在让 AI 根据自然语言描述在 3D 场景中找到指定物体。
具体而言,给定一个 3D 场景和一段文本描述,模型需要准确预测目标物体的 3D 位置,并以 3D 包围框的形式输出。相比于传统的目标检测任务,3DVG 需要同时理解文本、视觉和空间信息,挑战性更高。


之前主流的方法大多基于监督学习,这类方法依赖大规模 3D 标注数据进行训练,尽管在已知类别和场景中表现优异,但由于获取 3D 标注数据的成本高昂,同时受限于训练数据分布,导致它难以泛化到未见过的新类别或新环境。为了减少标注需求,弱监督方法尝试使用少量 3D 标注数据进行学习,但它仍然依赖一定数量的 3D 训练数据,并且在开放词汇(Open-Vocabulary)场景下,模型对未见物体的识别能力仍然受限。
最近的零样本 3DVG 方法通过大语言模型(LLM)进行目标推理,试图绕开对 3D 训练数据的需求。然而,这类方法通常忽略了 3D 视觉细节,例如物体的颜色、形状、朝向等,使得模型在面对多个相似物体时难以进行细粒度区分。这些方法就像让 AI “闭着眼睛” 理解 3D 世界,最终导致模型难以精准定位目标物体。
因此,如何在零样本条件下结合视觉信息与 3D 空间关系,实现高效、准确的 3DVG,成为当前 3D 视觉理解领域亟待解决的问题。

为此,来自香港科技大学(广州)、新加坡 A*STAR 研究院和新加坡国立大学的研究团队提出了 SeeGround:一种全新的零样本 3DVG 框架。该方法无需任何 3D 训练数据,仅通过 2D 视觉语言模型(VLM)即可实现 3D 物体定位。其核心创新在于将 3D 场景转换为 2D-VLM 可处理的形式,利用 2D 任务的强大能力解决 3D 问题,实现对任意物体和场景的泛化,为实际应用提供了更高效的解决方案。
SeeGround 已被 CVPR 2025 接收,论文、代码和模型权重均已公开。

-
论文标题:SeeGround: See and Ground for Zero-Shot Open-Vocabulary 3D Visual Grounding
-
论文主页:https://seeground.github.io
-
论文地址:https://arxiv.org/pdf/2412.04383
-
代码:https://github.com/iris0329/SeeGround
SeeGround:用 2D 视觉大模型完成 3D 物体定位
如图所示,SeeGround 主要由两个关键模块组成:透视自适应模块(PAM)和融合对齐模块(FAM)。PAM 通过动态视角选择,确保 VLM 能够准确理解物体的空间关系;FAM 则通过视觉提示增强技术,将 2D 图像中的物体与 3D 坐标信息对齐,提升定位精度。
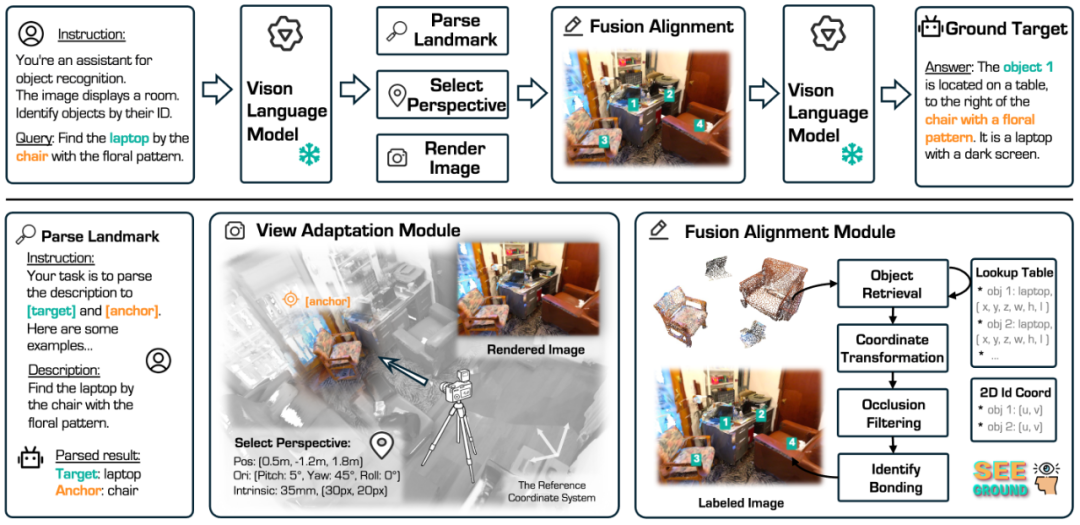
透视自适应模块(Perspective Adaptation Module, PAM)
在 3D 物体定位任务中,直接使用一个固定视角将 3D 场景渲染为 2D 图像(如俯视图)虽然能提供物体的颜色、纹理等信息,但却存在一个关键问题 ——VLM 本质上是基于平面的视觉感知模型,它只能 “看到” 图像中的物体,而无法推理 3D 物体的空间位置,比如前后、左右关系。
因此,如果描述中涉及相对空间位置(如 “桌子右边的椅子”),VLM 很可能误判。例如,在俯视视角下,桌子和椅子的相对位置可能会因透视投影而发生变化,原本在桌子右边的椅子可能会被误认为在左边,而 VLM 只能依赖 2D 图像中的视觉特征,无法推断物体在三维空间中的实际位置。直接使用固定视角渲染的 2D 图像作为输入,会导致模型在涉及空间位置关系的任务上表现不佳。
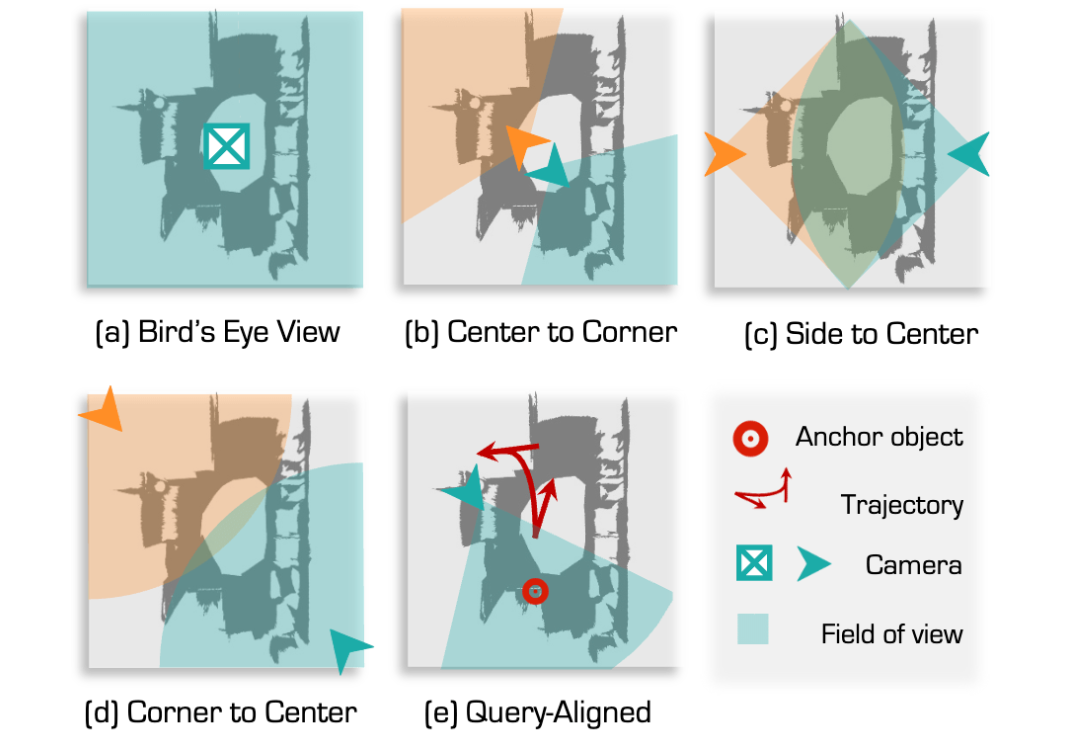
为了解决这个问题,SeeGround 设计了一个动态视角选择策略,先解析用户输入的文本,识别出描述中涉及的锚定物体(anchor object),即用于参考空间关系的对象。随后,系统根据锚定物体的位置计算最佳观察角度,调整虚拟摄像机,使其从更符合人类直觉的角度捕捉场景,确保 VLM 可以准确理解物体的空间关系。最终,SeeGround 生成一张符合查询语义的 2D 图像,该图像能够更清晰地呈现目标物体与其参考物体的相对位置,使 VLM 具备更强的 3D 关系推理能力。这一策略不仅提高了 VLM 在 3D 物体定位任务中的准确率,同时也避免了因固定视角导致的方向性误判和遮挡问题,使得零样本 3DVG 任务在复杂环境下依然具备稳定的泛化能力。
融合对齐模块(Fusion Alignment Module, FAM)
透视自适应模块(PAM)能够为 VLM 提供更符合任务需求的观察视角,但即使如此,VLM 仍然面临一个关键挑战:它无法直接推理 3D 物体的空间信息,也无法自动对齐 2D 渲染图中的物体与 3D 位置描述中的物体。
SeeGround 将 3D 场景表示为 2D 渲染图像 + 文本 3D 坐标信息,然而,当 VLM 看到 2D 渲染图像时,它并不知道图中的椅子对应的是哪个 3D 坐标。这意味着,如果场景中有多个相似物体(如多把椅子),VLM 可能会误解 2D 图像中的目标物体,导致错误的 3D 预测。
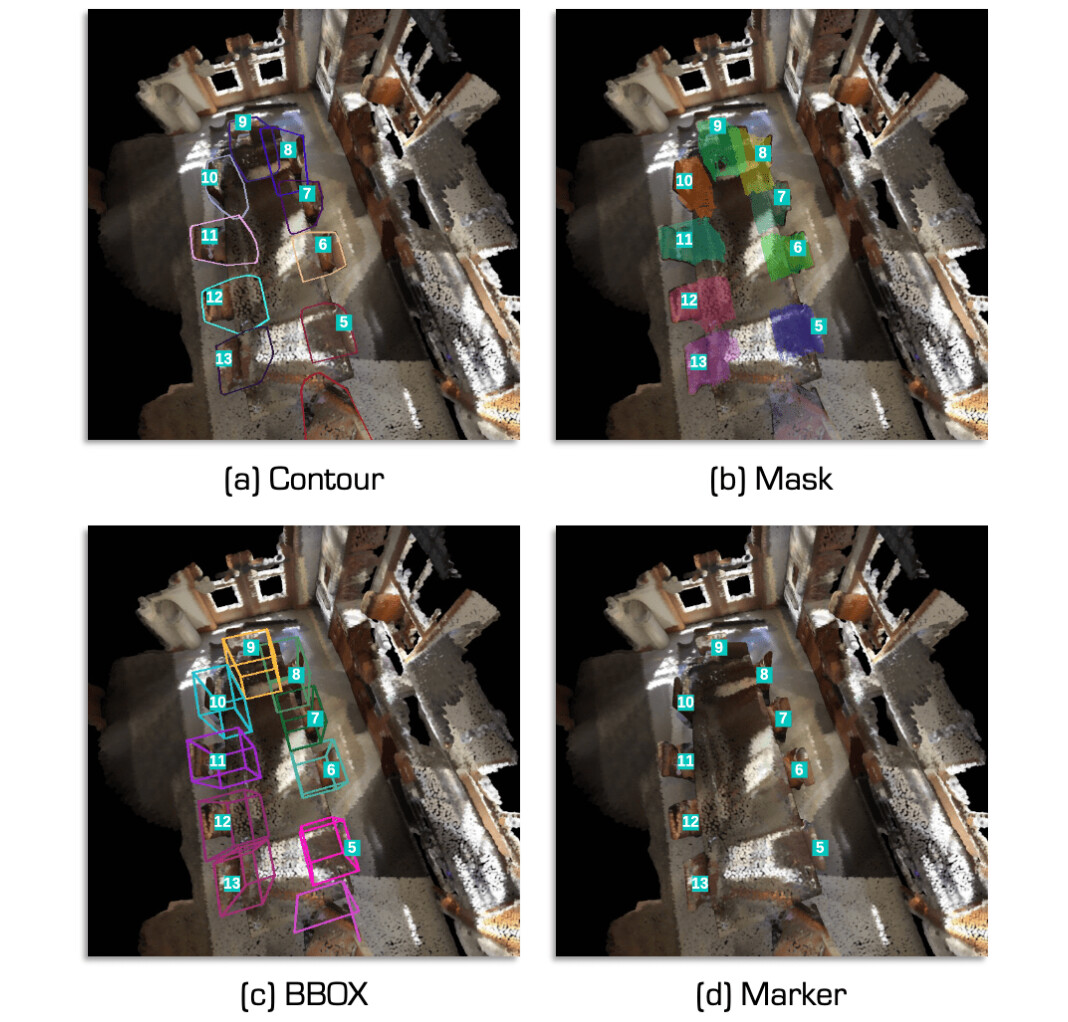
SeeGround 通过视觉提示增强(Visual Prompting) 技术,在 2D 渲染图像中标注出关键物体的位置,使 VLM 能够识别出 2D 画面中的具体目标物体,并将其与 3D 坐标数据关联。
首先,SeeGround 使用对象查找表(Object Lookup Table) 来获取场景中的所有物体的 3D 坐标。然后,使用投影技术将 3D 物体的空间位置转换为 2D 图像中的对应位置,并在渲染图像上添加可视化标注,以便 VLM 在推理时能够准确识别出目标物体。同时,在文本描述输入部分,SeeGround 进一步增强了 3D 物体的空间描述,使 VLM 在推理时能够结合 2D 视觉特征和 3D 坐标信息,从而准确匹配目标物体。
实验结果
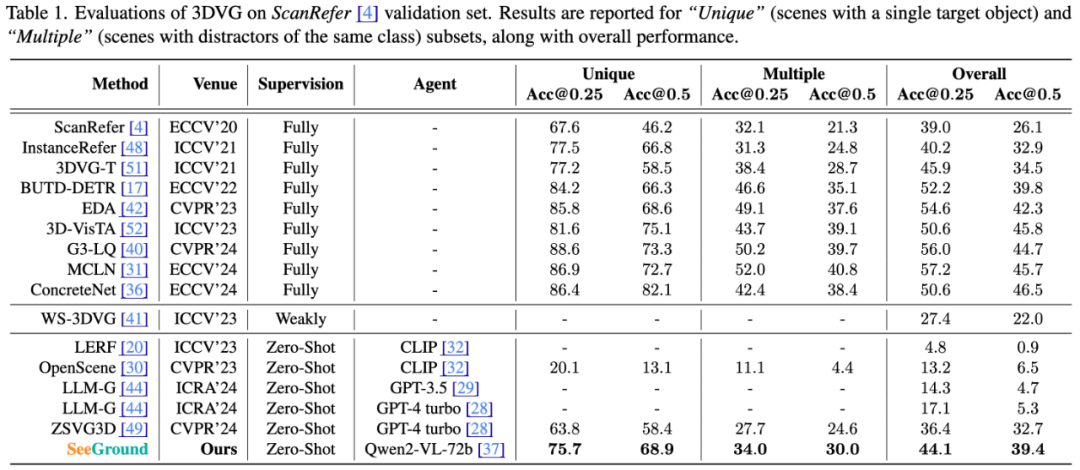
为了验证 SeeGround 在零样本 3D 视觉定位(3DVG)任务中的有效性,作者在 ScanRefer 和 Nr3D 数据集上进行了广泛的实验。结果表明,SeeGround 在多个基准测试中显著超越了现有零样本方法,并在某些任务上接近弱监督甚至全监督方法的性能。
此外,在对比实验中,即使去除部分文本信息,SeeGround 仍然能够利用视觉线索进行准确定位,进一步验证了该方法在不完全信息条件下的稳健性。
作者专门设计了一个场景,即让模型在文本描述缺失关键物体信息的情况下,尝试定位目标物体:在 “请找到打印机上方的柜子” 这一查询任务中,文本输入被刻意去除了 “打印机” 和 “柜台” 等关键信息,仅提供物体类别及其位置信息。
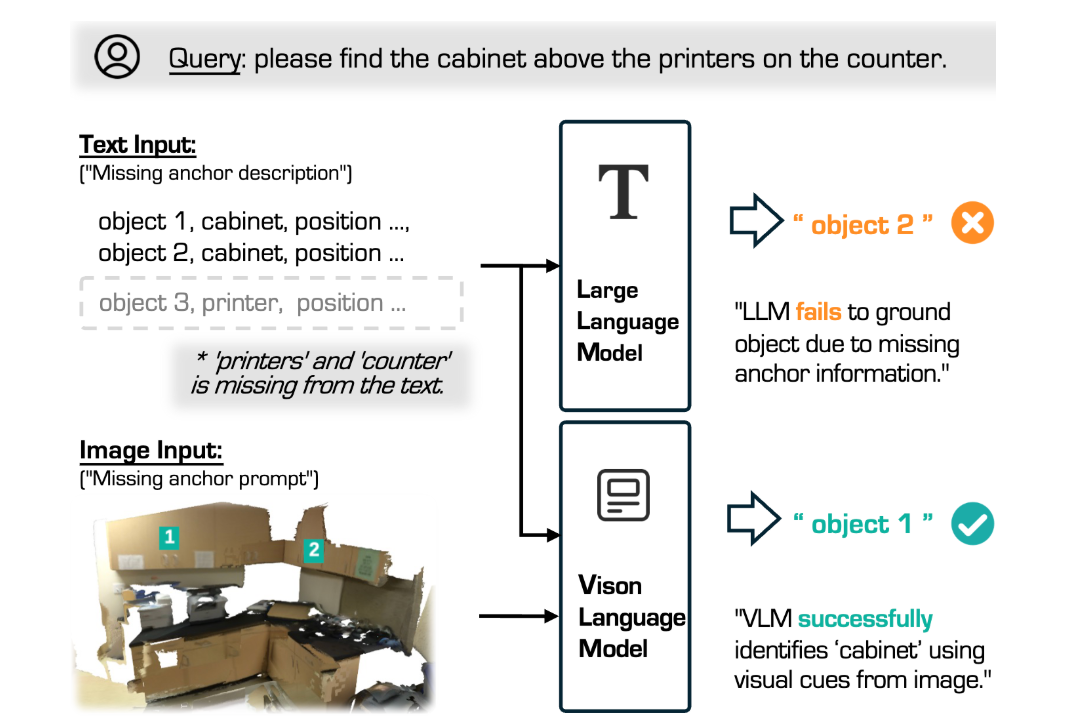
在这种情况下,仅依赖文本推理的 LLM 由于无法获取必要的上下文信息,错误地匹配到了错误的柜子。而 SeeGround 通过 VLM 结合视觉信息成功识别出图像中的打印机,并准确定位其上方的柜子。
这一特性进一步提升了 SeeGround 在复杂现实环境中的适用性,使其能够在 3D 物体定位任务中表现出更强的稳健性和泛化能力。

结论
SeeGround 通过无需 3D 训练数据的创新设计,成功解决了现有零样本方法在视觉细节和空间推理上的不足,显著提升了 3DVG 任务的泛化能力。这一突破为增强现实、机器人导航和智能家居等领域提供了更高效、灵活的 3D 物体定位方案。
作者介绍
SeeGround 是香港科技大学(广州)、新加坡 A*STAR 研究院和新加坡国立大学团队的合作项目。
本文的第一作者为港科广博士生李蓉,通讯作者为港科广 AI Thrust 助理教授梁俊卫。其余作者包括新加坡国立大学博士生孔令东,以及 A*STAR 研究院研究员李仕杰和 Xulei Yang。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com