腾讯混元、英伟达Nemotron-H纷纷采用Mamba-Transformer混合架构,该架构融合两者优势,显著提升模型速度与效率,或成AI模型新趋势。
原文标题:腾讯混元、英伟达都发混合架构模型,Mamba-Transformer要崛起吗?
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到了英伟达的Nemotron-H在MMLU-Pro基准测试中表现出色,速度是同体量竞品模型的三倍。那么,除了MMLU-Pro,还有哪些benchmark可以用来更全面地评估Mamba-Transformer混合架构的性能?
3、从文章来看,Mamba-Transformer混合架构主要优势在于提升效率和处理长文本。那么,未来这种架构还可能在哪些领域发挥更大的作用?
原文内容
机器之心报道
编辑:Panda、张倩
在过去的一两年中,Transformer 架构不断面临来自新兴架构的挑战。
在众多非 Transformer 架构中,Mamba 无疑是声量较大且后续发展较好的一个。然而,与最初发布时那种仿佛「水火不容」的局面不同,最近一段时间,这两种架构似乎正在走向融合。
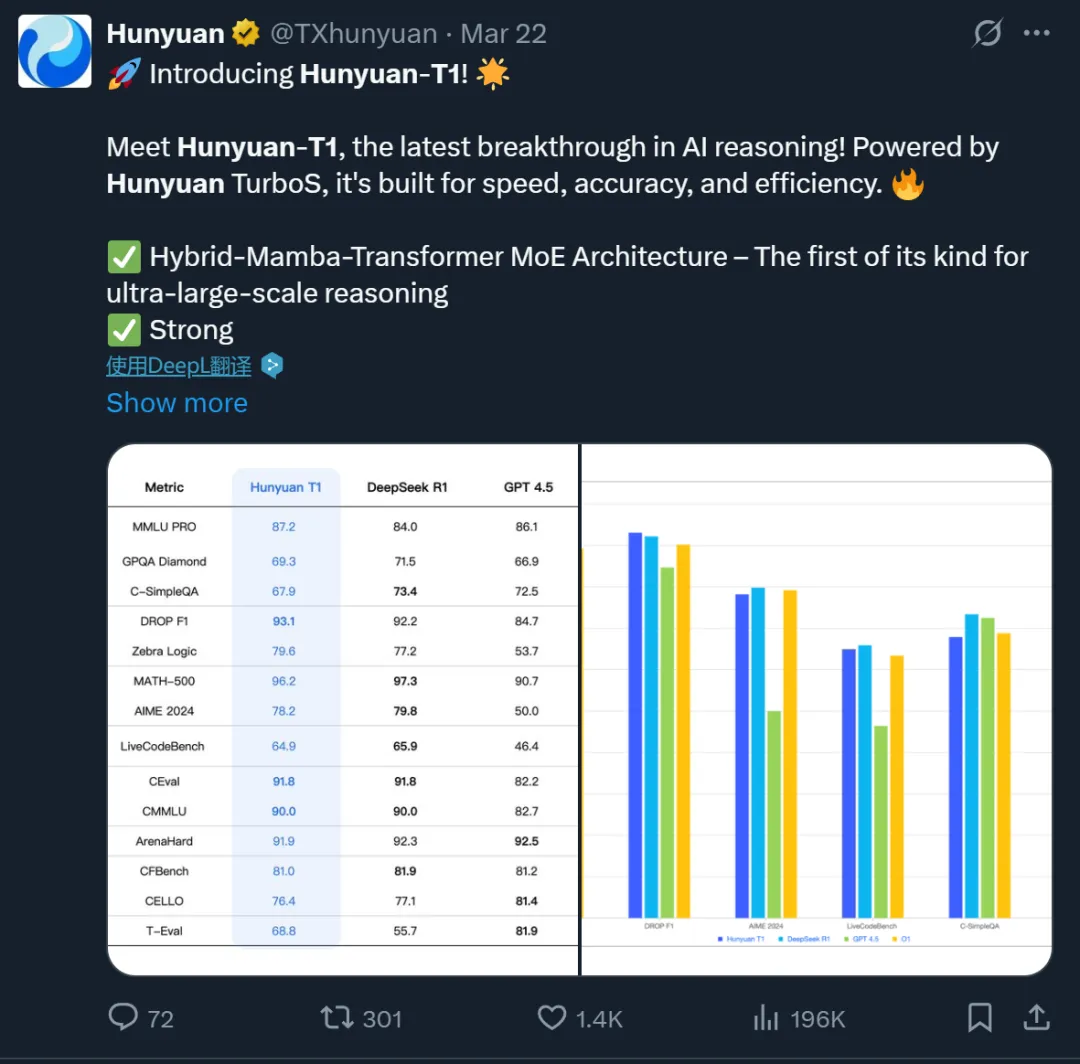
上周五,腾讯宣布推出自研深度思考模型「混元 T1」正式版,这是一个能秒回、吐字快、擅长超长文处理的强推理模型。而之所以具备这些优势,很大程度上是因为腾讯采用了 Hybrid-Mamba-Transformer 融合架构。这一架构有效降低了传统 Transformer 架构的计算复杂度,减少了 KV-Cache 的内存占用,从而显著降低了训练和推理成本,让混元 T1 实现首字秒出,吐字速度最快可达 80 token/s。
与此同时,英伟达也推出了一个采用 Mamba-Transformer 混合架构的模型家族 ——Nemotron-H,其速度是同体量竞品模型的三倍。

速度的提升与成本的降低,是 AI 大模型迈向更广泛应用与普及的必经之路。如今,腾讯、英伟达等科技巨头对 Mamba-Transformer 混合架构的高度关注与投入,释放出一个极为重要的信号:此类架构所蕴含的巨大价值,值得我们深入挖掘与探索。
恰好,滑铁卢大学计算机科学助理教授陈文虎(Wenhu Chen)最近发帖,盘点了一下最近的几款 Mamba-Transformer 模型。我们对他的盘点进行了整理,希望能带给大家一些启发。

Mamba-Transformer 简介
Mamba-Transformer 混合架构,顾名思义,就是将 Mamba 与 Transformer 架构组合到一起。
Transformer 想必大家已经非常熟悉了,简单来说:Transformer 架构是一种以自注意力机制为核心的深度学习模型,自 2017 年由 Ashish Vaswani 等人提出以来,便革新了传统序列模型的设计理念。其关键在于多头自注意力机制能够在全局范围内捕捉输入序列中各元素之间的复杂依赖关系,同时通过位置编码保留序列位置信息,加上残差连接和层归一化等技术确保了高效的并行计算和稳定的训练过程。这种架构不仅显著提升了机器翻译、文本生成等自然语言处理任务的性能,也为后续 BERT、GPT 等预训练模型的快速发展奠定了坚实基础。
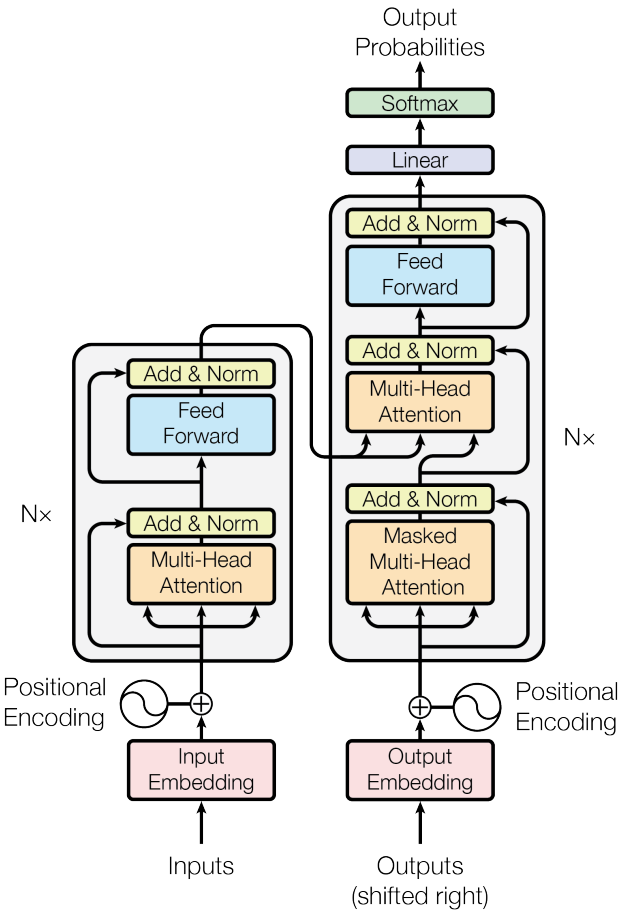
经典 Transformer 架构
而 Mamba 则是一种状态空间模型(SSM)—— 该架构的一大显著优势是能高效地捕获序列数据中的复杂依赖关系,并由此成为 Transformer 的一大强劲对手。
经典的状态空间模型可被视为循环神经网络(RNN)和卷积神经网络的(CNN 融合模型。它们可使用循环或卷积运算进行高效地计算,从而让计算开销随序列长度而线性或近线性地变化,由此大幅降低计算成本。
作为 SSM 最成功的变体架构之一,Mamba 的建模能力已经可以比肩 Transformer,同时还能维持随序列长度的线性可扩展性。
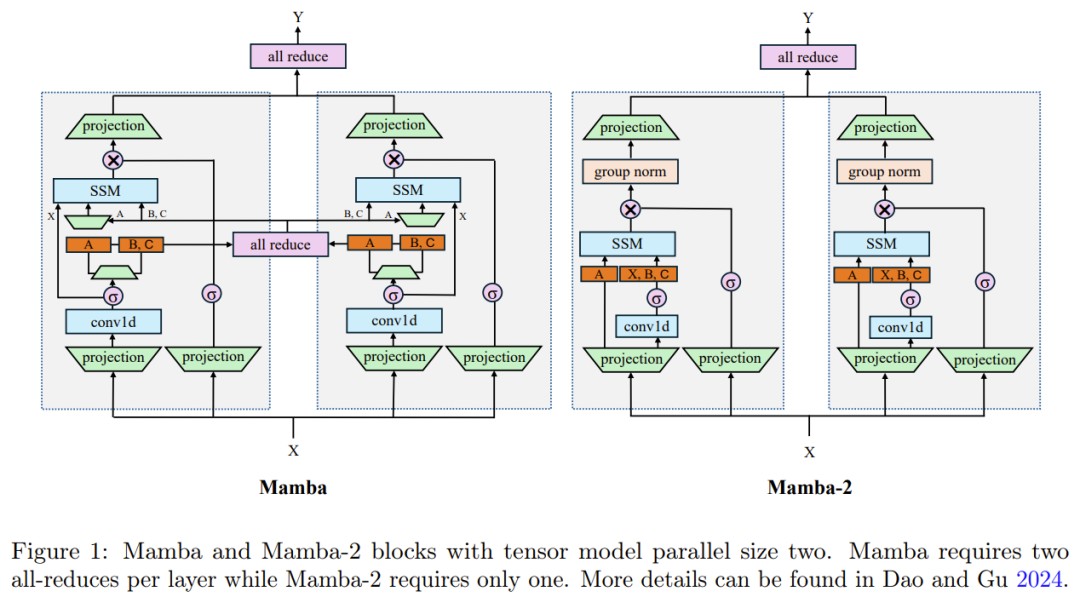
Mamba 首先引入了一个简单却有效的选择机制,可根据输入对 SSM 进行重新参数化,从而可让模型在滤除不相关信息的同时无限期地保留必要和相关的数据。然后,Mamba 还包含一种硬件感知型算法,可使用扫描(scan)而非卷积来循环地计算模型,这在 A100 GPU 上能让计算速度提升 3 倍。
凭借强大的建模复杂长序列数据的能力和近乎线性的可扩展性,Mamba 已经崛起成为一种重要的基础模型架构。关于 Mamba 架构的更详细介绍可参阅机器之心文章以及。
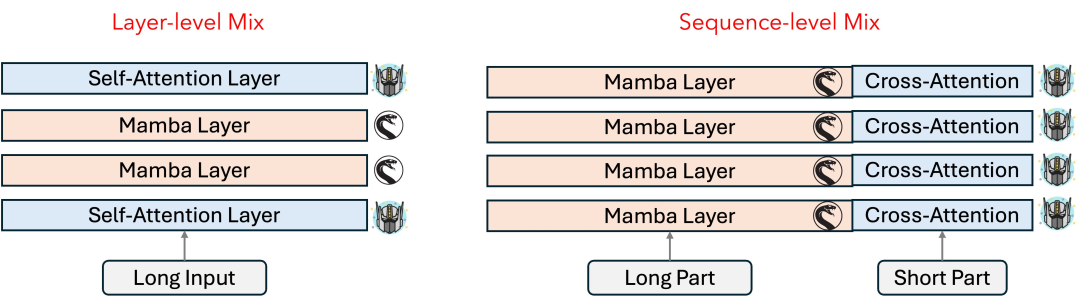
而要将 Mamba 与 Transformer 混合到一起,常见的方式有两种:层级混合与序列级混合。如下图所示,当前的 Mamba-Transformer 混合架构模型会根据自身需要选择不同的混合策略。
Nemotron-H
3 月 21 日,英伟达推出了 Nemotron-H 系列的 Mamba-Transformer 混合架构模型,其中包含多种规模的多种模型,比如 Nemotron-H-8B-Base、Nemotron-H-8B-Instruct、Nemotron-H-8B-VLM、Nemotron-H-47B-Base、 Nemotron-H-56B-Base、Nemotron-H-56B-VLM。其中 47B 版本可以在单台商品级 NVIDIA RTX 5090 GPU 上以 FP4 精度支持 100 万 token 长度上下文的推理。
实际上,Nemotron-H 就是英伟达近期发布的用于物理 AI 的强大 VLM 模型 Cosmos-Reason 1 背后的骨干网络。
据介绍,通过采用 Mamba-Transformer 混合架构,相比于 SOTA 的开源纯 Transformer 模型,Nemotron-H 在保证了相当乃至更好的准确度的同时,可以提供远远更快的推理速度(高达 3 倍)。下面两图展示了在 MMLU-Pro 基准上,Nemotron-H 与同等数量级参数的开源 Transformer 模型的准确度与吞吐量对比。可以看到,Nemotron-H 具有非常明显的效率优势。
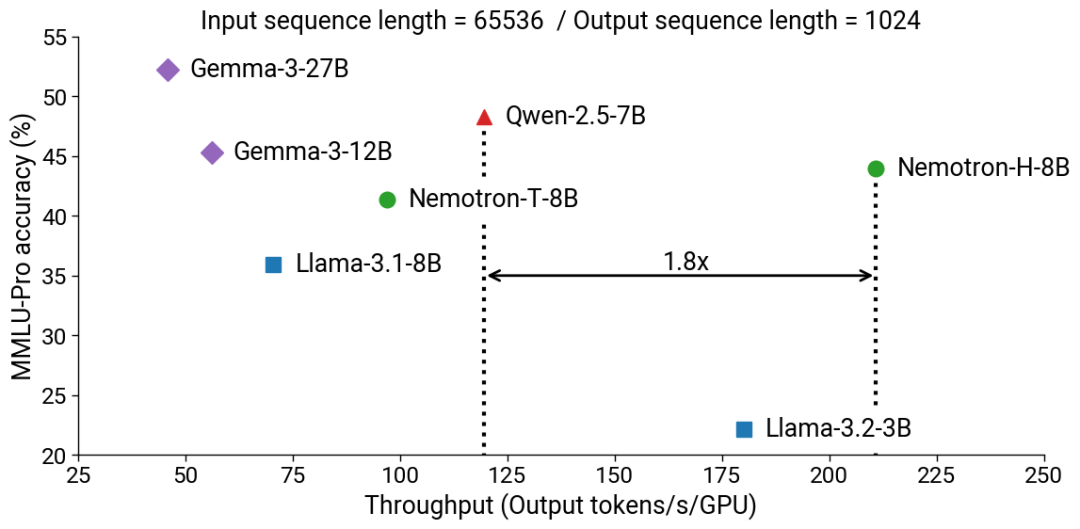
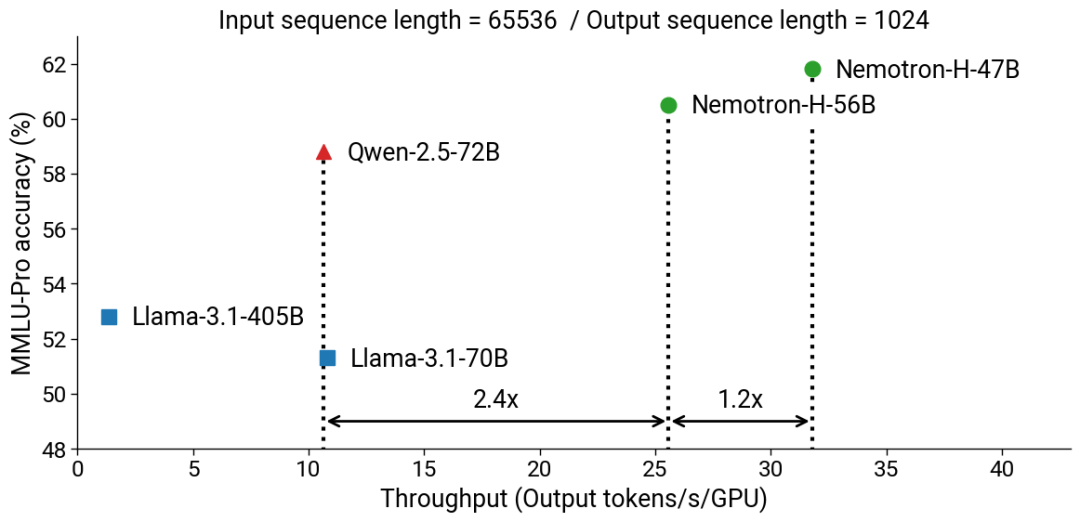
此外,英伟达也公布了 Nemotron-H 的其它一些细节,包括 Nemotron-H-56B-Base 的训练使用了 6144 台 H100 GPU 和 20 万亿 token,训练精度为 FP8(是 FP8 预训练的一次大规模展示);Nemotron-H-47B-Base 是 Nemotron-H-56B-Base 的蒸馏版 —— 蒸馏精度为 FP8 并使用了 630 亿训练 token。
Hunyuan-Turbo-S 和 Hunyuan-T1
3 月 21 日同一天,腾讯也宣布推出了深度思考模型混元 T1 正式版,并同步在腾讯云官网上线。而在此之前,他们已于 3 月初发布了混元 Turbo S 基础模型以及之后的混元 T1-preview 模型。
这些模型都采用了 Mamba-Transformer 混合架构,其中 T1 更是一款使用了大规模强化学习的强推理模型,在数学、逻辑推理、科学和代码等理科难题具有非常明显的优势。当然,Mamba-Transformer 高效率的优势也在这里有非常明显的体现。

比如在大语言模型评估增强数据集 MMLU-PRO 上,混元 T1 取得了 87.2 分,仅次于 o1。在 CEval、AIME、Zebra Logic 等中英文知识及竞赛级数学、逻辑推理的公开基准测试中,混元 T1 的成绩也达到业界领先推理模型的水平。
据介绍,混元 T1 正式版沿用了混元 Turbo S 的创新架构,采用 Hybrid-Mamba-Transformer 融合模式。这是工业界首次将混合 Mamba 架构无损应用于超大型推理模型。
这一架构有效降低了传统 Transformer 结构的计算复杂度,减少了 KV-Cache 的内存占用,从而显著降低了训练和推理成本,让混元 T1 实现首字秒出,吐字速度达到最快 80 token/s。

-
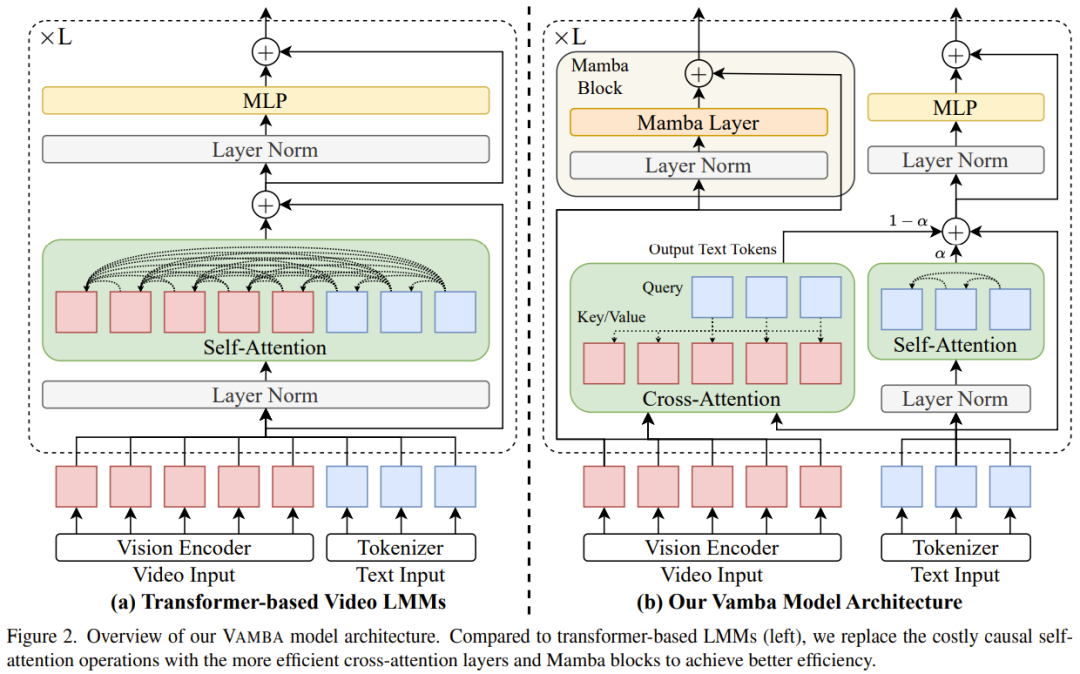
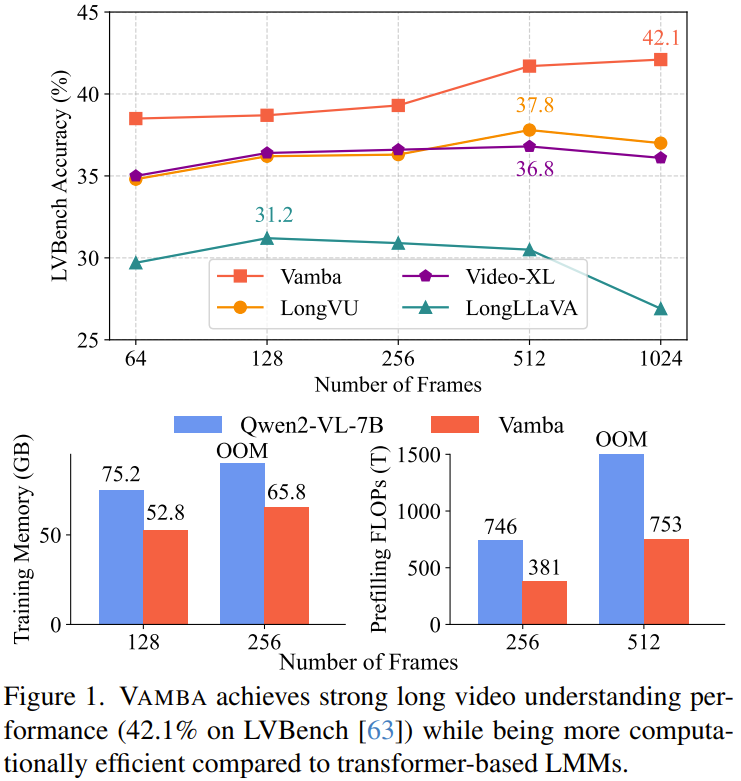
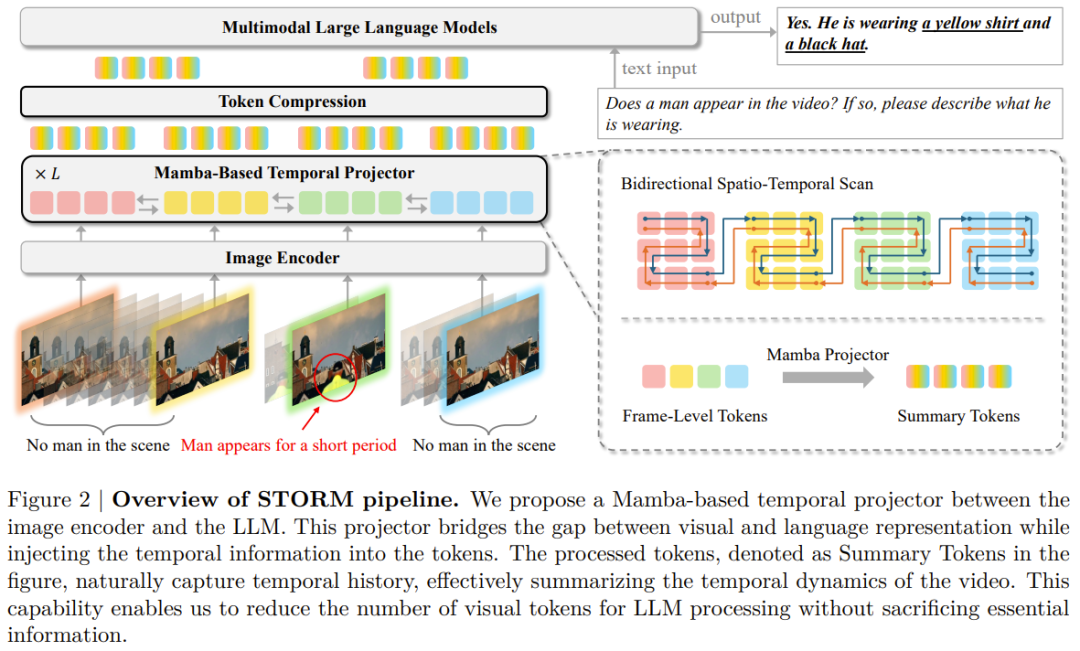
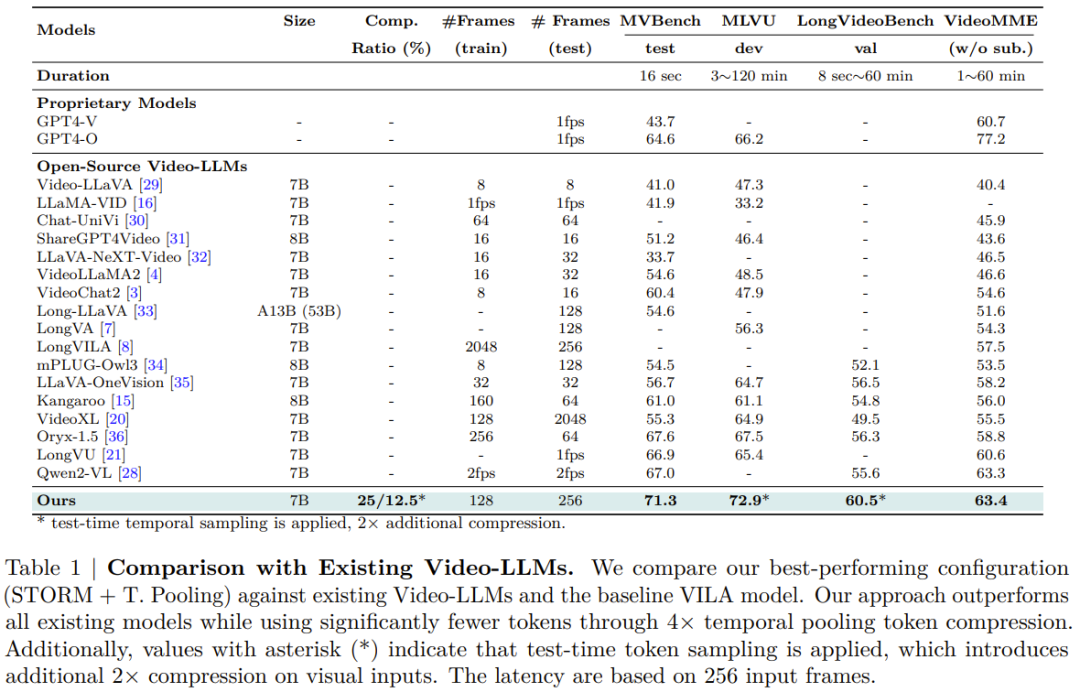
论文标题:Token-Efficient Long Video Understanding for Multimodal LLMs
-
论文地址:https://arxiv.org/pdf/2503.04130

-
论文标题:VAMBA: Understanding Hour-Long Videos with Hybrid Mamba-Transformers
-
论文地址:https://arxiv.org/pdf/2503.11579
-
项目地址:https://tiger-ai-lab.github.io/Vamba/