一文回顾LLM发展历程,从2017年Transformer到2025年DeepSeek-R1,展示了LLM在规模、性能、成本和多模态能力上的巨大进步,以及对AI领域和社会的深远影响。
原文标题:最新「大模型简史」整理!从Transformer(2017)到DeepSeek-R1(2025)
原文作者:数据派THU
冷月清谈:
1. **Transformer架构的革命性意义**:Transformer解决了RNN和LSTM的局限性,通过自注意力机制实现了并行计算和全局上下文理解,为大规模高效语言模型奠定了基础。
2. **预训练Transformer模型的兴起**:BERT通过双向训练实现了对上下文的深入理解,而GPT系列则专注于自回归生成能力。GPT-3的1750亿参数证明了规模在AI中的重要性,预示着可以通过海量规模的数据集训练,使得模型在捕获复杂模式和泛化到新任务变得更好。
3. **后训练对齐**:为了使LLM更好地贴合人类价值观,研究人员提出了监督微调(SFT)和基于人类反馈的强化学习(RLHF)等技术。ChatGPT的推出展示了对话式AI改变人机交互的潜力。
4. **多模态模型**:GPT-4V和GPT-4o等多模态LLM通过整合文本、图像、音频和视频,实现了更丰富的交互和复杂的问题解决,革新了医疗、教育和创意产业等领域。
5. **开源和开放权重模型**:开源和开放权重模型的发展民主化了AI技术,促进了社区驱动的创新,加速了AI在各个领域的应用。
6. **推理模型**:OpenAI的o1和o3推理模型通过模拟人类的“系统2”思维,在复杂推理任务中达到了新的高度,并在数学和编程等领域超越了以往的模型。
7. **成本高效的推理模型**:DeepSeek-R1通过专家混合架构和优化算法,显著降低了运营成本,使得先进LLM得以普及化,重塑AI行业的生态系统。
LLM正朝着更智能、更通用、更可及的方向发展,且在可持续性和包容性上更进一步。
怜星夜思:
2、DeepSeek-R1的低成本被认为是AI普及化的关键。那么,除了降低成本,AI普及化还面临哪些挑战?我们应该如何应对这些挑战?
3、文章中提到了从“系统1”到“系统2”思维的转变,你认为在实际应用中,如何评价一个AI模型是否真正具备了“系统2”的推理能力?有哪些可行的评测方法?
原文内容

本文详细回顾了大型语言模型从2017年Transformer架构的出现到2025年DeepSeek-R1的发展历程,涵盖了BERT、GPT系列、多模态模型、推理模型等关键进展,展示了LLMs在规模、性能、成本和多模态能力上的巨大进步,以及对AI领域和社会的深远影响。
2025年初,我国推出了一款开创性且高性价比的「大型语言模型」(Large Language Model, LLM) — — DeepSeek-R1,引发了AI领域的巨大变革。

1. 什么是语言模型 (Language Models)?
「语言模型」是一种「人工智能系统」,旨在处理、理解和生成类似人类的语言。它们从大型数据集中学习模式和结构,使得能够产生连贯且上下文相关的文本,应用于翻译、摘要、聊天机器人和内容生成等领域。

1.1 大型语言模型(LLMs)
「语言模型」(LMs)和「大型语言模型」(LLMs)这两个术语虽然经常被互换使用,但实际上它们基于规模、架构、训练数据和能力指代不同的概念。LLMs 是 LMs 的一个子集,其规模显著更大,通常包含数十亿个参数(例如,GPT-3 拥有 1750 亿个参数)。这种更大的规模使 LLMs 能够在广泛的任务中表现出卓越的性能。“LLM”这一术语在 2018 至 2019 年间随着基于 Transformer 架构的模型(如 BERT 和 GPT-1)的出现开始受到关注。然而,在 2020 年 GPT-3 发布后,这个词才被广泛使用,展示了这些大规模模型的重大影响力和强大能力。
1.2 自回归语言模型 (Autoregressive Language Models)
大多数LLMs以「自回归方式」(Autoregressive)操作,这意味着它们根据前面的「文本」预测下一个「字」(或token/sub-word)的「概率分布」(propability distribution)。这种自回归特性使模型能够学习复杂的语言模式和依赖关系,从而善于「文本生成」。
![]()
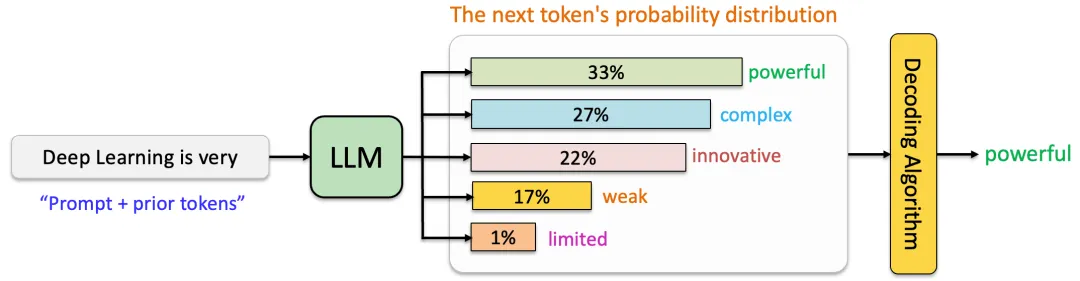
1.3 生成能力
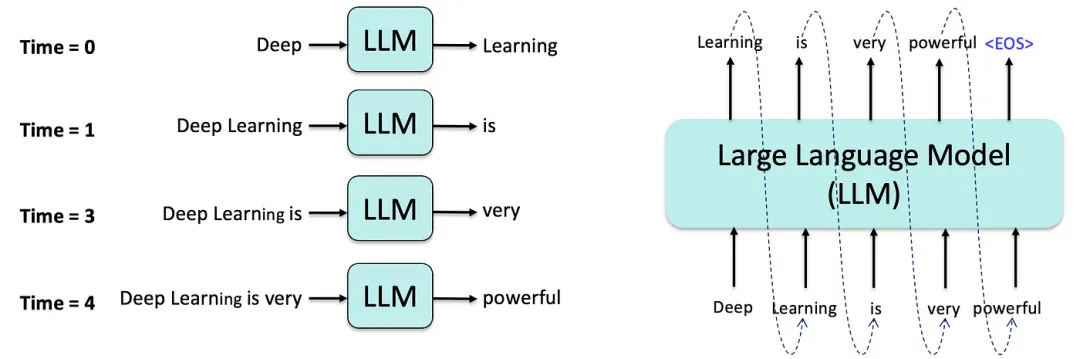
2. Transformer革命 (2017)
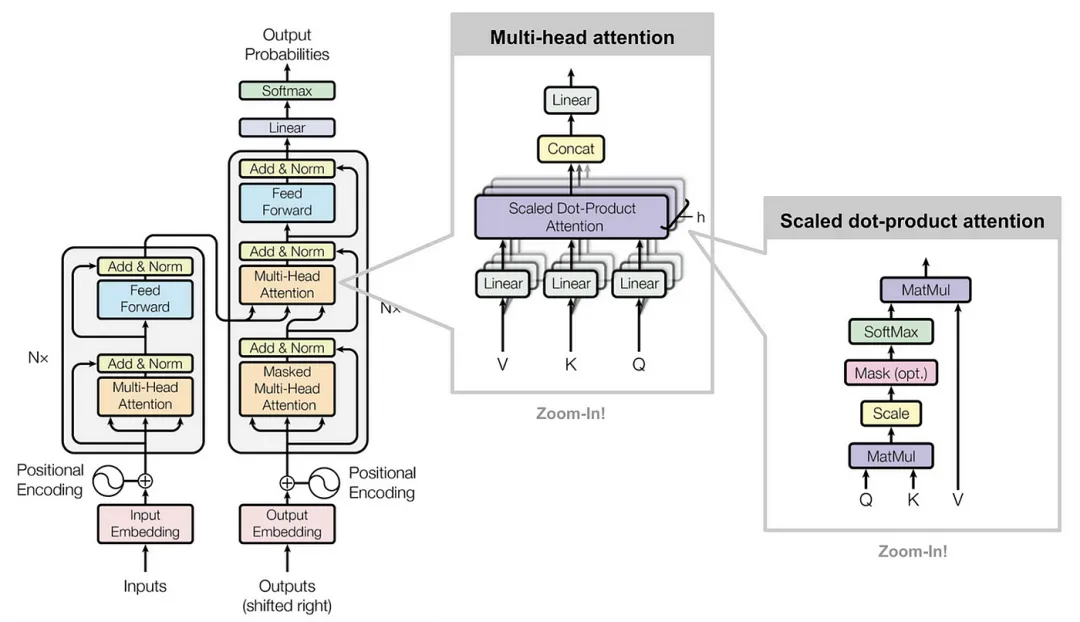
2.1 Transformer架构的关键创新

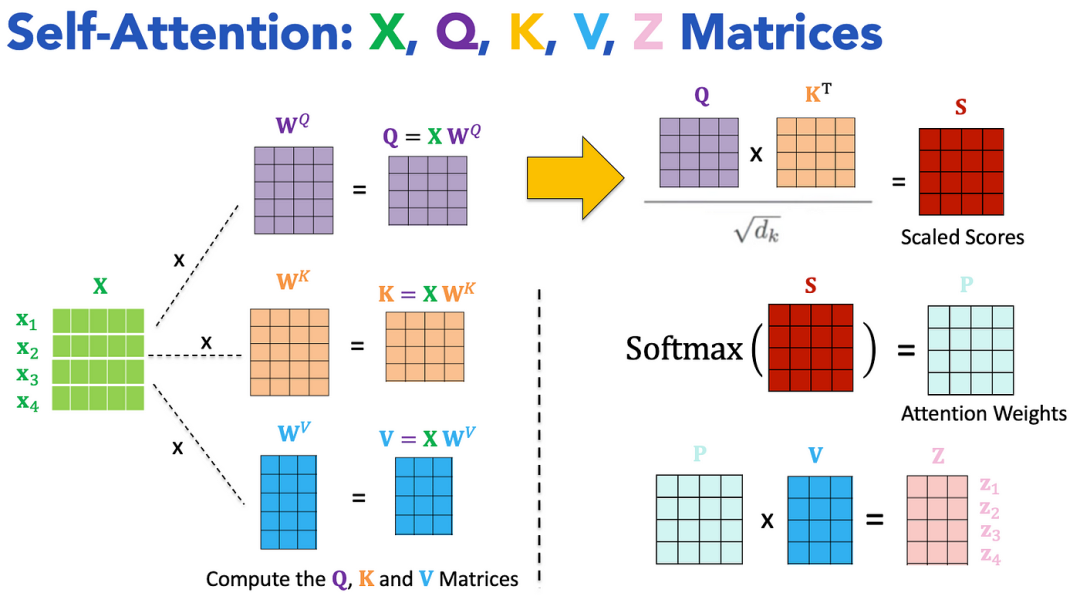


-
可扩展性:Transformers实现了完全并行化的计算,使得在大型数据集上训练大规模模型成为可能。
-
上下文理解:自注意力捕捉局部和全局依赖关系,提高了连贯性和上下文意识。
3. 预训练Transformer模型时代 (2018–2020)
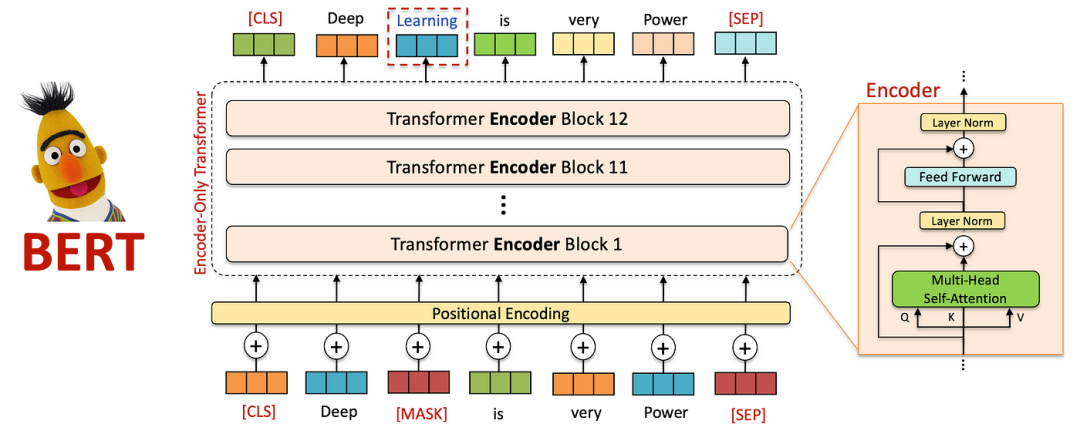
3.1 BERT:双向上下文理解 (2018)
-
掩码语言建模(Masker Language Modeling — MLM):BERT不是预测序列中的下一个词,而是被训练预测句子中随机掩码的标记。这迫使模型在进行预测时考虑整个句子的上下文 — — 包括前后词语。例如,给定句子“The cat sat on the [MASK] mat”,BERT会学习根据周围上下文预测“soft”。
-
下一句预测(Next Sentence Prediction — NSP):除了MLM之外,BERT还接受了称为下一句预测的次要任务训练,其中模型学习预测两个句子是否在文档中连续。这帮助BERT在需要理解句子之间关系的任务中表现出色,例如问答和自然语言推理。
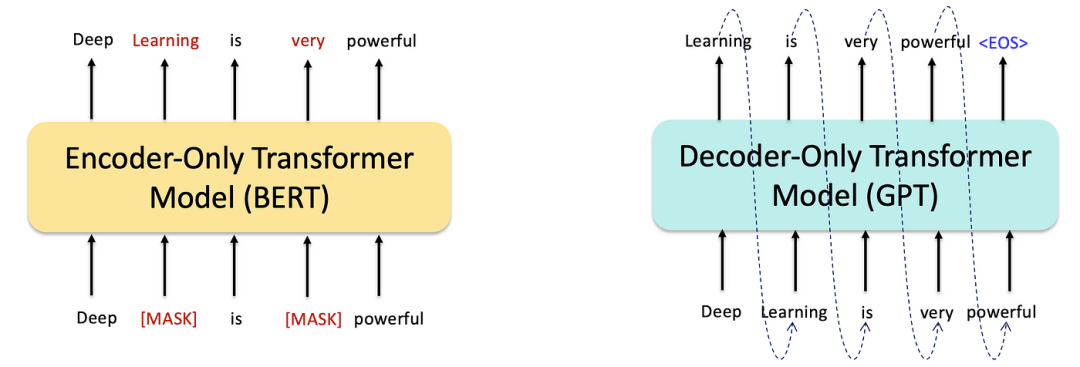
3.2 GPT:生成式预训练和自回归文本生成(2018–2020)
-
单向自回归训练:GPT使用因果语言建模目标进行训练,其中模型仅基于前面的标记预测下一个标记。这使得它特别适合于生成任务,如文本补全、摘要生成和对话生成。
-
下游任务的微调:GPT的一个关键贡献是它能够在不需要特定任务架构的情况下针对特定下游任务进行微调。只需添加一个分类头或修改输入格式,GPT就可以适应诸如情感分析、机器翻译和问答等任务。


3.3 GPT的影响及规模的作用

-
数据集大小:更大的模型需要庞大的数据集进行预训练。例如,GPT-3是在大量互联网文本语料库上进行训练的,使其能够学习多样化的语言模式和知识领域。
-
计算资源:强大的硬件(如GPU和TPU)的可用性以及分布式训练技术,使得高效训练具有数十亿参数的模型成为可能。
-
高效架构:混合精度训练和梯度检查点等创新降低了计算成本,使得在合理的时间和预算内进行大规模训练更加实际。
4. 后训练对齐:弥合AI与人类价值观之间的差距 (2021–2022)
4.1 监督微调 (SFT)


-
可扩展性:收集人类演示是劳动密集型且耗时的,尤其是对于复杂或小众任务。
-
性能:简单模仿人类行为并不能保证模型会超越人类表现或在未见过的任务上很好地泛化。
4.2 基于人类反馈的强化学习 (RLHF)
-
训练奖励模型:人类注释者对模型生成的多个输出进行排名,创建一个偏好数据集。这些数据用于训练一个奖励模型,该模型学习根据人类反馈评估输出的质量。
-
使用强化学习微调LLM:奖励模型使用近端策略优化(Proximal Policy Optimization - PPO)(一种强化学习算法)指导LLM的微调。通过迭代更新,模型学会了生成更符合人类偏好和期望的输出。
4.3 ChatGPT:推进对话式AI (2022)

-
对话聚焦的微调:在大量对话数据集上进行训练,ChatGPT擅长维持对话的上下文和连贯性,实现更引人入胜和类似人类的互动。
-
RLHF:通过整合RLHF,ChatGPT学会了生成不仅有用而且诚实和无害的响应。人类培训师根据质量对响应进行排名,使模型能够逐步改进其表现。
5. 多模态模型:连接文本、图像及其他 (2023–2024)

5.1 GPT-4V:视觉遇见语言

5.2 GPT-4o:全模态前沿
6. 开源和开放权重模型 (2023–2024)
-
开放权重LLMs:开放权重模型提供公开访问的模型权重,限制极少。这使得微调和适应成为可能,但架构和训练数据保持封闭。它们适合快速部署。例子:Meta AI的LLaMA系列和Mistral AI的Mistral 7B / Mixtral 8x7B
-
开源模型使底层代码和结构公开可用。这允许全面理解、修改和定制模型,促进创新和适应性。例子:OPT和BERT。
-
社区驱动的创新:像Hugging Face这样的平台促进了协作,LoRA和PEFT等工具使高效的微调成为可能。

7. 推理模型:从「系统1」到「系统2」思维的转变 (2024)

7.1 OpenAI-o1:推理能力的一大飞跃(2024)

-
长链思维(Long CoT) :使模型能够将复杂问题分解为更小的部分,批判性地评估其解决方案,并探索多种方法,类似于搜索算法。
-
推理时计算控制 :对于更复杂的问题,可以生成更长的CoTs;而对于较简单的问题,则使用较短的CoTs以节省计算资源。
-
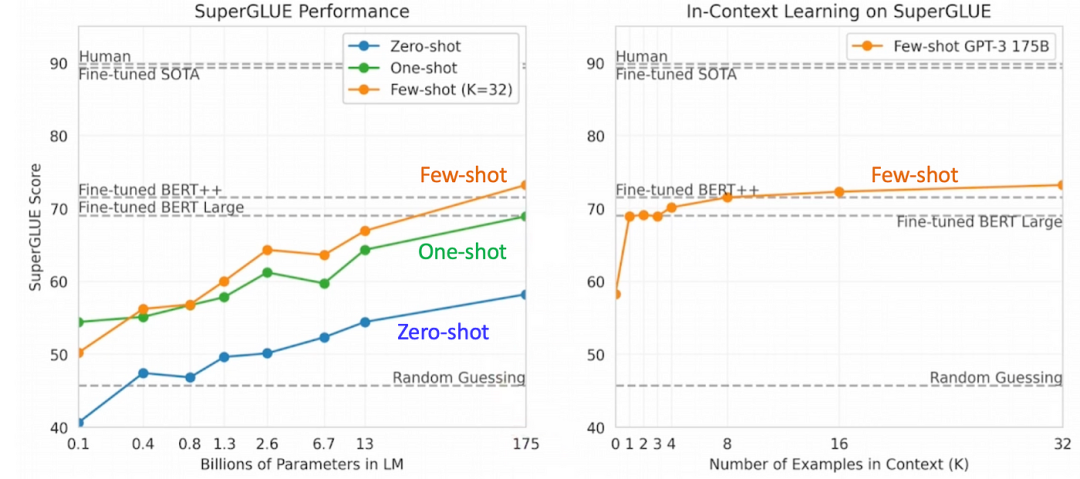
增强的推理能力 :尽管像o1-preview这样的初始推理模型在某些领域的能力不如标准LLMs,但在推理任务中,它们的表现远远超越了后者,常常能与人类专家媲美。例如,o1-preview在数学(AIME 2024)、编程(CodeForces)和博士级别的科学问题上均超越了GPT-4o。
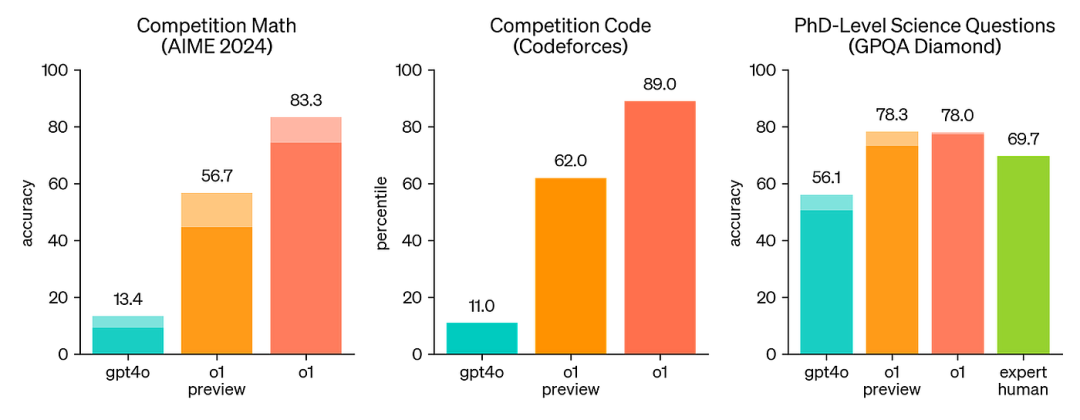
-
ARC-AGI :达到87.5%的准确率,超过了人类水平的85%,远超GPT-4o的5%。
-
编程 :在SWE-Bench Verified上得分71.7%,并在Codeforces上获得2727的Elo评分,跻身全球前200名竞争性程序员之列。
-
数学 :在EpochAI的FrontierMath基准测试中达到25.2%的准确率,相比之前的最先进水平(2.0%)有了显著提升。

8. 成本高效的推理模型:DeepSeek-R1 (2025)
8.1 DeepSeek-V3 (2024–12)
-
多头潜在注意力(Multi-head Latent Attention — MLA):通过压缩注意力键和值来减少内存使用,同时保持性能,并通过旋转位置嵌入(RoPE)增强位置信息。
-
DeepSeek专家混合(DeepSeekMoE):在前馈网络(FFNs)中采用共享和路由专家的混合,以提高效率并平衡专家利用率。
-
多标记预测 (Multi-Token Prediction — MTP):增强模型生成连贯且上下文相关的输出的能力,特别是对于需要复杂序列生成的任务。
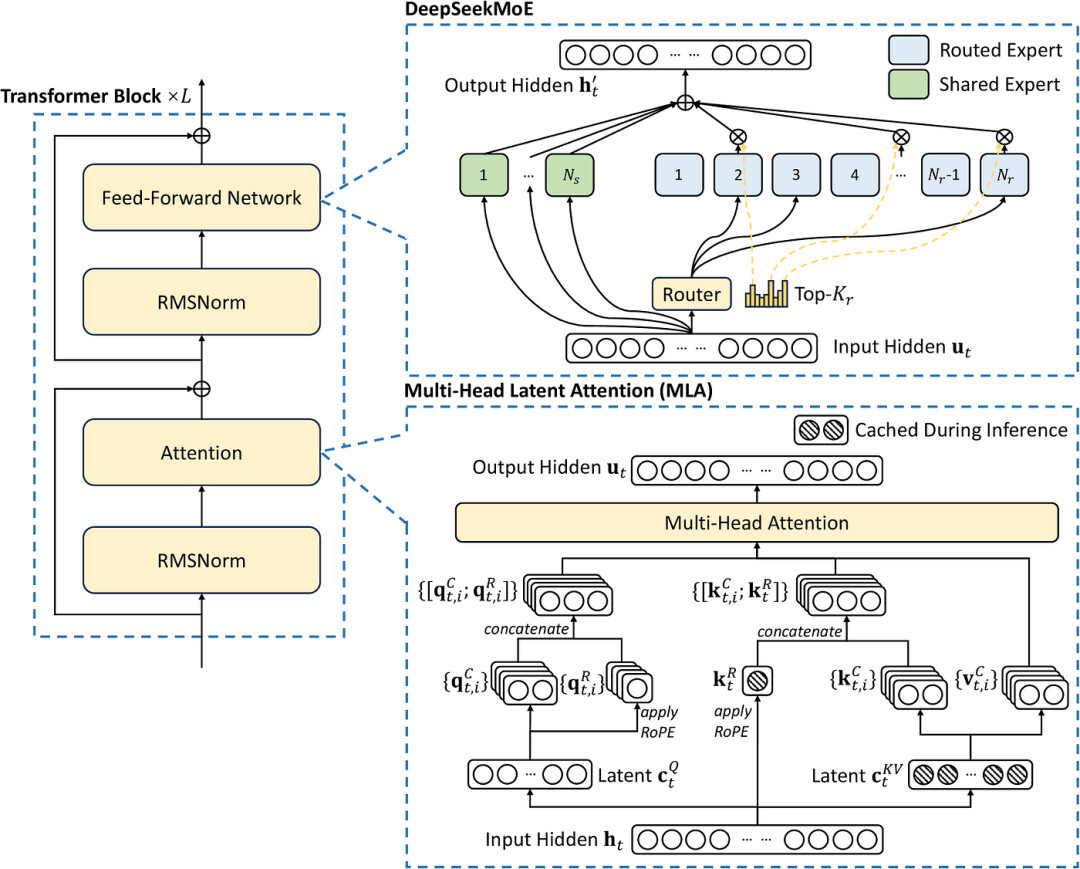
8.2 DeepSeek-R1-Zero 和 DeepSeek-R1 (2025–01)
-
DeepSeek-R1-Zero:一种基于DeepSeek-V3的推理模型,通过强化学习(RL)增强其推理能力。它完全消除了「监督微调」(SFT)阶段,直接从名为DeepSeek-V3-Base的预训练模型开始。它采用了一种基于「规则的强化学习方法」(Rule-based Reinforcement Learning),称为「组相对策略优化」(Group Relative Policy Optimization — GRPO),根据预定义规则计算奖励,使训练过程更简单且更具可扩展性。

-
DeepSeek-R1:为了解决DeepSeek-R1-Zero的局限性,如低可读性和语言混杂,DeepSeek-R1纳入了一组有限的高质量冷启动数据和额外的RL训练。该模型经历了多个微调和RL阶段,包括拒绝采样和第二轮RL训练,以提高其通用能力和与人类偏好的一致性。
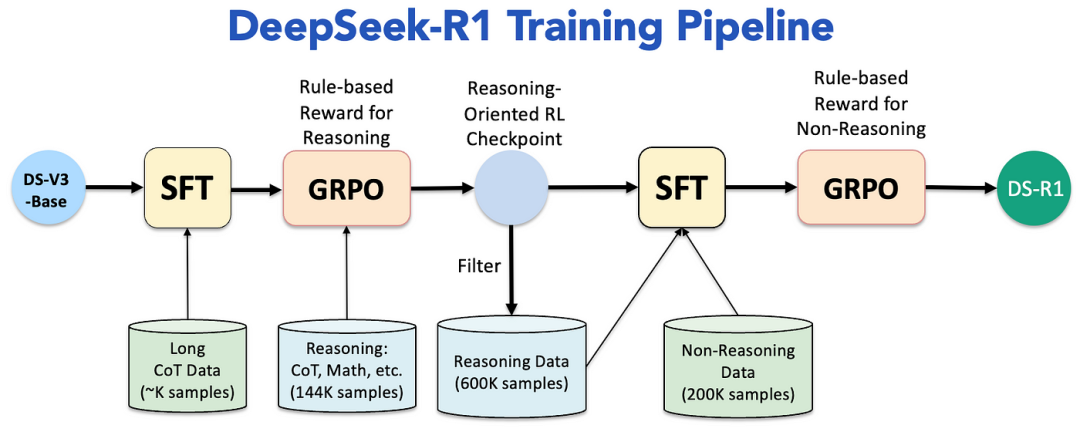

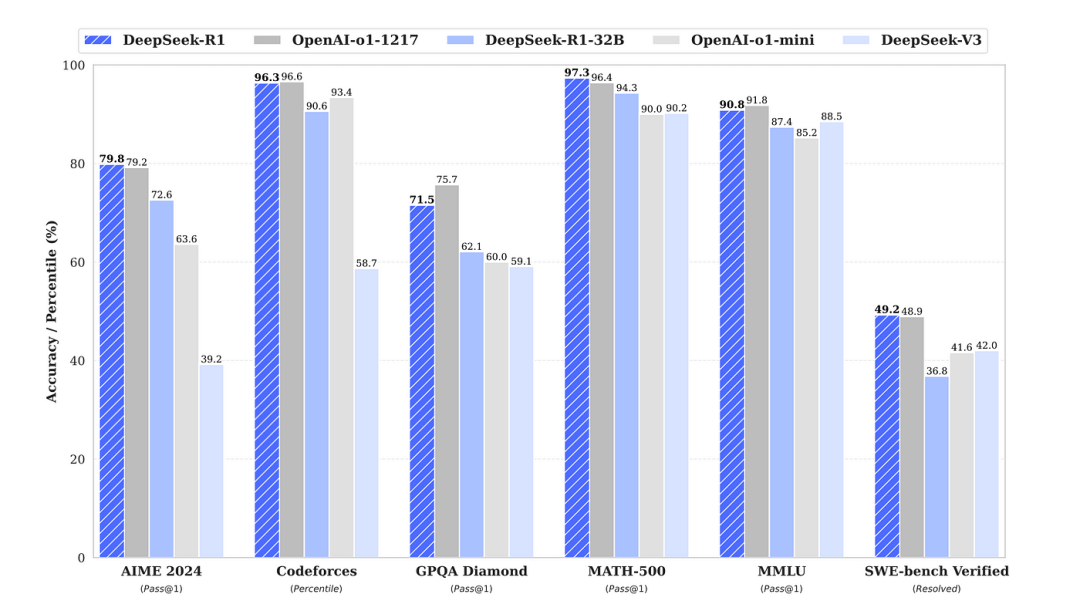
8.3 对AI行业的影响
结论
-
Transformers (2017):Transformer架构的引入为构建能够以前所未有的精确性和灵活性处理复杂任务的大规模高效模型奠定了基础。
-
GPT-3 (2020):该模型展示了规模在AI中的变革力量,证明了在大规模数据集上训练的巨大模型可以在广泛的应用中实现接近人类的表现,为AI所能完成的任务设立了新的基准。
-
ChatGPT (2022):通过将对话式AI带入主流,ChatGPT使高级AI对普通用户来说更加可访问和互动。它还引发了关于广泛采用AI的伦理和社会影响的关键讨论。
-
DeepSeek-R1 (2025):代表了成本效率的一大飞跃,DeepSeek-R1利用专家混合架构(MoE)和优化算法,与许多美国模型相比,运营成本降低了多达50倍。其开源性质加速尖端AI应用的普及化,赋予各行业创新者权力,并强调了可扩展性、对齐性和可访问性在塑造AI未来中的重要性。
原文链接:
