Meta提出SWEET-RL算法,通过多轮训练,显著提升LLM在协作推理任务中的性能,甚至可以与GPT-4o等专有模型媲美。
原文标题:田渊栋和Sergey Levine参与开发新型RL算法,能通过多轮训练让智能体学会协作推理
原文作者:机器之心
冷月清谈:
Meta FAIR 和加利福尼亚大学伯克利分校的研究团队,针对如何训练通用、有能力和目标导向的智能体,提出了一种新型强化学习算法 SWEET-RL。该算法基于 ColBench 基准构建,通过两阶段训练方法,首先学习各个轮次的优势函数,然后通过每轮流的优势优化智能体。实验结果表明,SWEET-RL 能够有效提升 LLM 智能体在复杂协作任务中的性能,在参数量较小的情况下,性能甚至可以与 GPT-4o 等专有模型媲美。该研究还强调了多轮协作对于提高 LLM 智能体在 artifact 创建方面的性能的重要性,并指出即使是对于 GPT-4o 和 o1-mini 等专有 LLM 来说,多轮协作仍然是一项具有挑战性的任务,下游微调仍然是必要的。
怜星夜思:
1、SWEET-RL算法中,为什么需要设计ColBench这个基准测试?感觉文章里只是说为了解决LLM智能体开发多轮RL算法的挑战,这个挑战具体是什么?
2、SWEET-RL算法分两个阶段训练,第一阶段学习优势函数,第二阶段用优势函数优化智能体。为什么不直接用一个模型端到端训练?分成两个阶段训练有什么好处?
3、SWEET-RL在第二阶段训练时,使用了训练时信息c,但最终策略π_φ不能以c为条件。这是为什么?这种不对称的actor-critic结构有什么好处?
2、SWEET-RL算法分两个阶段训练,第一阶段学习优势函数,第二阶段用优势函数优化智能体。为什么不直接用一个模型端到端训练?分成两个阶段训练有什么好处?
3、SWEET-RL在第二阶段训练时,使用了训练时信息c,但最终策略π_φ不能以c为条件。这是为什么?这种不对称的actor-critic结构有什么好处?
原文内容
机器之心报道
编辑:Panda
强化学习提升了 LLM 各方面的能力,而强化学习本身也在进化。
现实世界中,很多任务很复杂,需要执行一系列的决策。而要让智能体在这些任务上实现最佳性能,通常需要直接在多轮相关目标(比如成功率)上执行优化。不过,相比于模仿每一轮中最可能的动作,这种方法的难度要大得多。
在直接优化多轮目标方面,一类自然的方法是应用单轮 RLHF 算法,例如 RAFT、DPO 和 PPO ,不过这些方法不会在不同轮次间执行显式的 credit 分配。因此,由于复杂顺序决策任务的长期性,它们可能会出现高方差和较差的样本复杂性等问题。
另一种选择是应用价值函数学习方法,例如 TD 学习。然而,这需要在 LLM 表征的基础上训练一个新的特定于任务的价值头,这可能无法在有限的微调数据下很好地泛化。因此,目前尚不清楚哪种多轮 RL 算法最有效,能够充分利用 LLM 的推理能力来训练通用、有能力和目标导向的智能体。
近日,Meta FAIR 和加利福尼亚大学伯克利分校一个研究团队在这个研究课题上取得了新的突破。首先,他们为该问题构建了一个新的基准:ColBench(Collaborative Agent Benchmark)。在此基础上,他们还提出了一种易于实现但非常有效的 RL 算法:SWEET-RL(RL with Step-WisE Evaluation from Training-Time Information)。

-
论文标题:SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
-
论文地址:https://arxiv.org/pdf/2503.15478
-
代码地址:https://github.com/facebookresearch/sweet_rl
这篇论文的一作为伯克利 AI 研究所(BAIR)二年级博士生周逸飞(Yifei Zhou)。并有多位著名 AI 研究者参与其中,包括田渊栋、Jason Weston 和 Sergey Levine。
下面我们就来简单解读一下这项研究,更多详情请参阅原论文。
ColBench
先来看看他们提出的新基准。首先,为了解决为 LLM 智能体开发多轮 RL 算法的挑战,该团队构建了一些基本设计原则,包括:
-
应具有足够的任务复杂性,可以挑战智能体的推理和泛化能力。
-
尽可能地降低开销,以支持快速研究原型设计。
-
应该有足够的任务多样性,以便在 RL 训练时不会过拟合。
接下来,具体看看该基准中的两个任务:后端编程和前端设计。
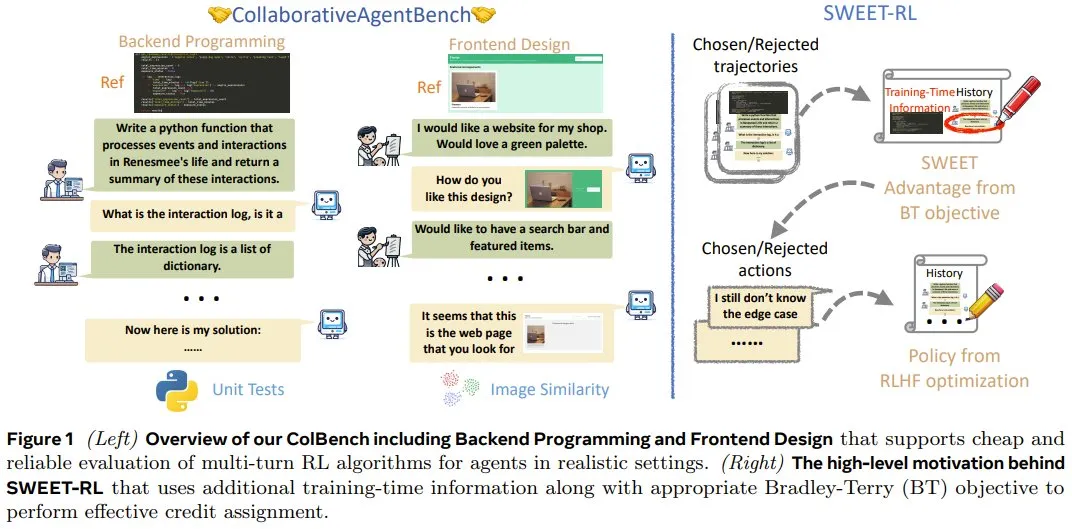
后端编程协作
在此任务中,智能体需要与人类模拟器协作编写自定义 Python 函数(最多 50 行)。
在协作开始时,智能体会先获得高级描述和函数签名。但并不会提供很多具体的细节,例如应考虑哪些条件以及在边缘情况下该怎么做。智能体必须推理并决定需要人类模拟器提供哪些具体说明。人类模拟器需要根据只有它们自己可见的参考代码,用自然语言对每个需要说明的问题提供简要解释,但不会编写代码。
智能体和人类模拟器之间的交互仅限于 10 轮来回。当智能体决定给出最终解决方案或达到最大轮数时,交互结束。
在评估智能体是否成功时,需要对每个函数进行 10 次隐藏单元测试,并对每次协作给出 0 或 1 的奖励。
前端设计协作
在此任务中,智能体需要与人类模拟器协作,通过编写 HTML 代码片段(约 100 行)来设计网页。
在协作开始时,智能体会获得网页的高级描述。同样,许多具体细节(例如网页的布局和调色板)都缺失,只有人类模拟器才能看到。在每一轮中,智能体都有机会编写 HTML 结果并通过 Web 浏览器呈现出来。人类模拟器可以对比来自智能体的网页和参考网页,然后向智能体描述它们的差异。与后端编程协作类似,当智能体决定给出最终解决方案或达到最大 10 轮交互时,交互结束。
评估指标方面,使用了智能体解答与参考网页之间的 CLIP 嵌入的余弦相似度。同样,协作结束时,会发放 0 或 1 的奖励。
表 1 比较了 ColBench 与现有的其它基准。
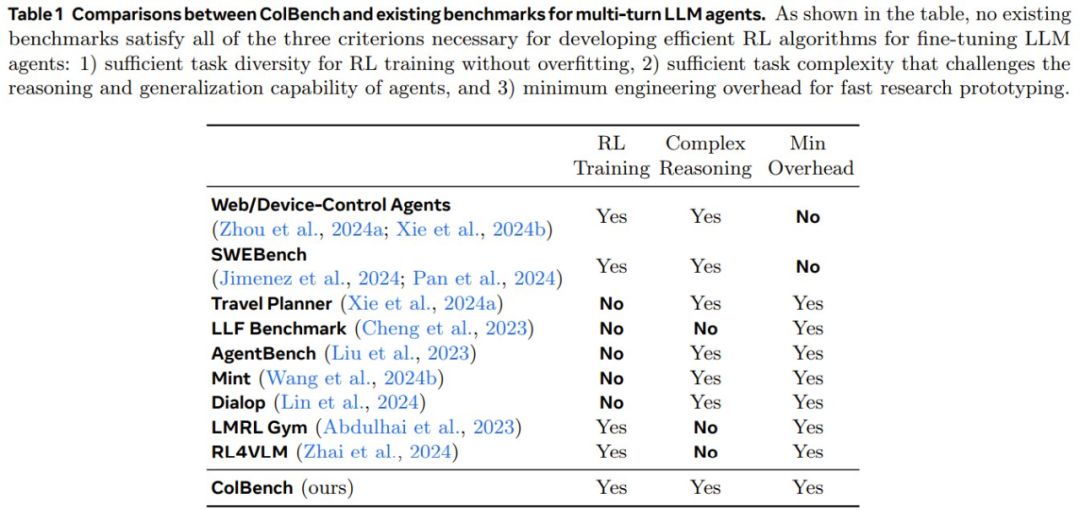
SWEET-RL
SWEET-RL 是一种两阶段训练方法,如图 2 所示。
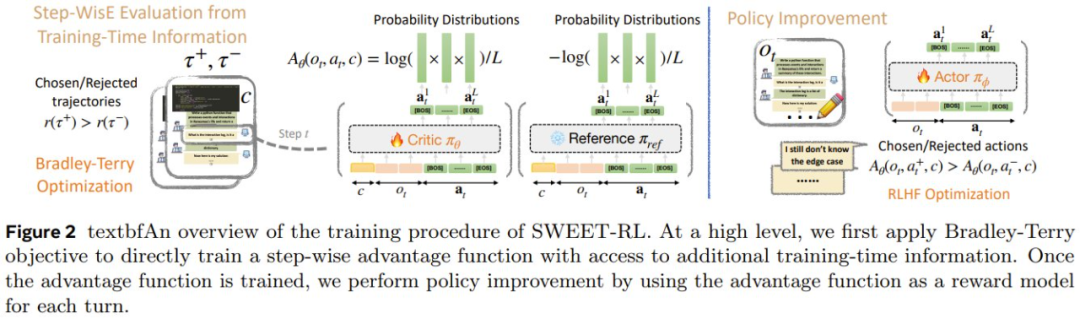
第一阶段:学习各个轮次的优势函数
为了在推理密集型任务中执行显式 credit 分配,之前一些研究使用的方法是:先学习一个显式的价值函数,然后从学习到的价值函数中得出每个单独动作的优势。
然而,该团队的实验发现,当微调只能使用有限数量的样本时,这种价值函数不能很好地泛化。他们猜想这是因为在推理密集型任务中学习准确的价值函数本身就是一项艰巨的任务,并且不能有效地利用预训练 LLM 的推理和泛化能力。
由于执行 credit 分配的最终目标是得出每个动作的优势,这对于 LLM 来说可能比估计预期的未来回报更容易,因此该团队提出直接学习每个轮次动作的优势函数。
考虑到偏好优化已经在 LLM 微调方面得到成功应用,因此该团队提出根据轨迹的偏好对来训练每轮次优势函数。
给定同一任务的两条轨迹,并附加训练时间信息 c,根据它们的累积奖励将它们标记为选取 τ+ 和拒绝 τ−。这样一来,便可以采用 Bradley-Terry 目标进行微调:
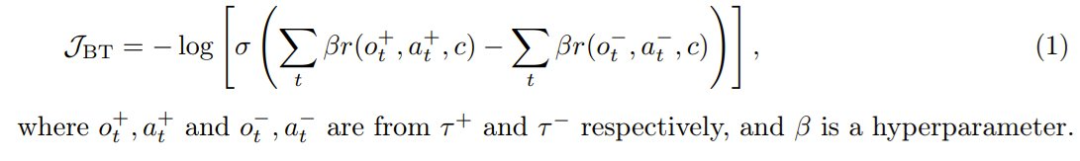
然后,可以使用优势函数重写这个目标函数:
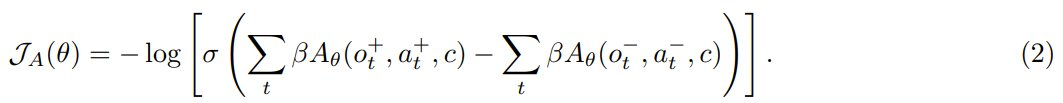
直观地讲,类似于单轮 RLHF 的目标,即学习每个选取响应的高奖励和每个拒绝响应的低奖励,2 式的效果是增加选取轨迹中每个动作的优势并降低拒绝轨迹中每个动作的优势。
为了进一步将学习目标与下一 token 预测预训练对齐,该团队的做法是重新利用 LLM 的现有语言模型头来参数化优势函数:
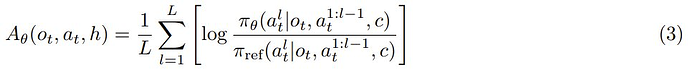
第二阶段:通过每轮流的优势优化智能体
该团队得到的一个重要观察是:虽然最终策略 π_φ 不能以隐藏信息 h 为条件,但此类信息在训练期间是可用的。由于优势 LLM π_θ 只会在训练期间使用,因此它可以将 c 作为 3 式的输入。
直观地讲,许多现实问题(例如协作和数学推理)都具有一些隐藏的训练时间信息,例如参考解。如果每轮次的优势函数可以访问此类训练时间信息,那么它应该能够更好地判断策略采取的行动是否在正确的轨道上。
因此,他们为每轮次的优势函数提供了额外的训练时间信息 c,而仅向策略提供了交互历史 o_t,从而产生了不对称的 actor-critic 结构。原则上,RLHF 文献中的任何成功算法都可用于优化每轮次策略 π_φ,方法是将交互历史视为提示词,将每轮次优势函数 A_θ 视为奖励模型。在训练策略的这个阶段,不需要人类合作者的互动。
为了简单,该团队选择使用 DPO 进行训练。对于每个轮次 t,首先从给定交互历史 o_t 的当前策略中抽取候选动作,并根据学习到的每轮次优势函数对它们进行排序,以获得要选取和拒绝的动作。然后,使用标准 DPO 损失优化每个轮次的策略:
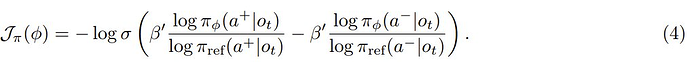
在实践中,每个轮次都会采样 16 个候选动作,并从前 50% 分位数中随机选择动作作为选取动作,从后 50% 分位数中随机选择动作作为拒绝动作。
实验表现
作为多轮强化学习算法,SWEET-RL 究竟能不能有效地训练 LLM 智能体来完成复杂的协作任务呢?为此,该团队进行了实验验证。
在 ColBench 上的表现
表 2 展示了在 ColBench 上,不同 LLM 和多轮 RL 算法的性能情况。
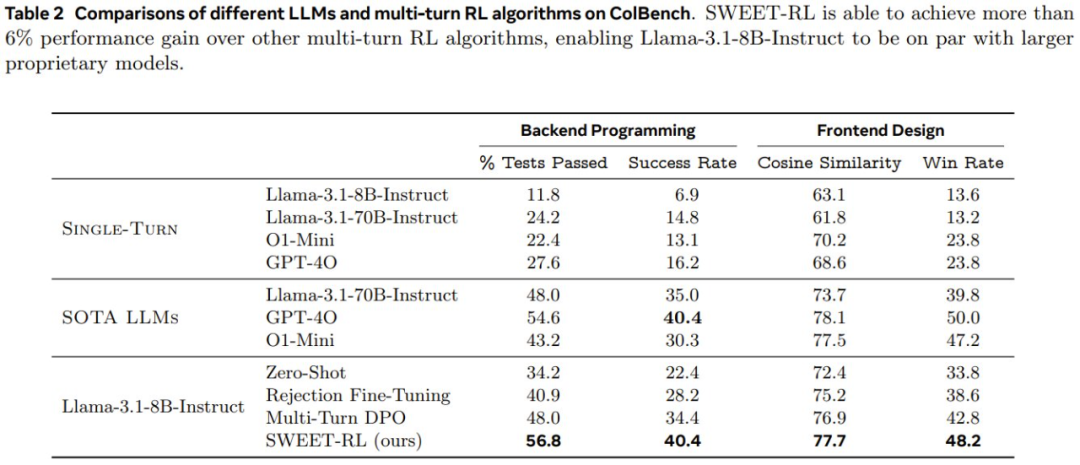
首先,比较「单轮」结果和其他协作结果,可以看到多轮协作可以通过将最终结果与人类模拟器的参考「期望」更紧密地结合起来,从而大大提高 LLM 智能体在 artifact 创建方面的性能。如果智能体必须在一个轮次内直接生产最终结果,那么即使是表现最好的 GPT-4o 也只能达到 16.2%。相比之下,如果让所有模型有机会与人类模拟器进行多轮交互并收集更多信息,则所有模型的成功率都能倍增(例如,Llama-3.1-8B-Instruct 的成功率从 6.9% 增加到 22.4%)。
尽管如此,即使对于 GPT-4o 和 o1-mini 等专有 LLM 来说,多轮协作仍然是一项具有挑战性的任务,它们的成功率分别只能达到 40.4% 和 30.3%。尽管 o1-mini 在数学和编码等符号推理任务上有所改进,但该团队观察到这些改进并没有直接让多轮协作智能体采用更好的策略,这表明为了让 LLM 优化与人类的协作,下游微调仍然是必要的。
SWEET-RL 与其它算法的比较
在使用下游数据进行微调后,可以看到即使是最简单的 RL 算法拒绝式微调(Rejection Fine-Tuning)也可以提高在这两项任务上的性能。具体来说,后端编程成功率和前端设计成功率分别提高了 5.8% 和 4.8%。
然而,该团队观察到,拒绝式微调往往只是教 LLM「记住」每个训练任务的解决方案,而没有学习一种可泛化的策略来应对新的测试任务。
多轮次 DPO 通过为被拒绝的轨迹引入「负梯度」可以缓解这个问题,但如果没有在长期时间上进行适当的 credit 分配,改进仍然有限。
而如果利用训练时间信息显式地训练每轮次的奖励模型来执行 credit 分配,可以观察到相比于多轮次 DPO,SWEET-RL 在两个任务上都有显著提升(后端编程成功率提高 6%,前端设计胜率提高 5.4%)。
事实上,使用 Llama-3.18B-Instruct 得到的 SWEET-RL 模型不仅在参数上与 Llama-3.1-70B-Instruct 的性能相当,而且在性能上也足以与 GPT-4o 和 o1-mini 等 SOTA 专有模型比肩。
有关 SWEET-RL 的更多实验细节和分析请参阅原论文。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com