普林斯顿&华沙理工研究表明,将强化学习网络扩展至1000层,机器人任务性能提升高达50倍,或为RL领域带来突破。
原文标题:强化学习也涌现?自监督RL扩展到1000层网络,机器人任务提升50倍
原文作者:机器之心
冷月清谈:
普林斯顿大学和华沙理工大学的联合研究表明,通过将对比强化学习(CRL)扩展到1000层网络,可以显著提升强化学习在机器人任务中的性能,最高可达50倍。这项研究挑战了传统RL使用浅层网络的做法,通过融合自监督学习范式、增加数据量和突破网络深度限制,实现了在无监督目标条件任务中目标达成能力的显著提升。研究团队采用了残差连接、层归一化和Swish激活函数等技术来稳定训练过程,并探究了批大小和网络宽度对性能的影响。实验结果表明,更深的网络能够学习到更好的对比表征,提高泛化能力。这项研究为强化学习的未来发展指明了方向,即通过扩展网络深度和融合更多构建模块,可以实现更强大的性能和涌现新的智能行为。
怜星夜思:
1、这项研究将网络深度扩展到1000层,这在强化学习领域是一个很大的突破。你认为未来强化学习模型的发展趋势是更注重深度还是宽度?或者两者兼顾?为什么?
2、研究中提到,深层网络可以学习到更好的对比表征,并提高泛化能力。你认为这种深层网络学习到的表征和人类的认知方式有什么相似之处?
3、这项研究使用了对比强化学习(CRL)算法,并融合了残差连接、层归一化等技术。你认为这些技术在深层强化学习中起到了什么作用?还有哪些其他的技术可以用来改进深层强化学习的性能?
2、研究中提到,深层网络可以学习到更好的对比表征,并提高泛化能力。你认为这种深层网络学习到的表征和人类的认知方式有什么相似之处?
3、这项研究使用了对比强化学习(CRL)算法,并融合了残差连接、层归一化等技术。你认为这些技术在深层强化学习中起到了什么作用?还有哪些其他的技术可以用来改进深层强化学习的性能?
原文内容
机器之心报道
机器之心编辑部
虽然大多数强化学习(RL)方法都在使用浅层多层感知器(MLP),但普林斯顿大学和华沙理工的新研究表明,将对比 RL(CRL)扩展到 1000 层可以显著提高性能,在各种机器人任务中,性能可以提高最多 50 倍。

-
论文标题:1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
-
论文链接:https://arxiv.org/abs/2503.14858
-
GitHub 链接:https://github.com/wang-kevin3290/scaling-crl
研究背景
最近在人工智能领域里,强化学习的重要性因为 DeepSeek R1 等研究再次凸显出来,该方法通过试错让智能体学会在复杂环境中完成任务。尽管自监督学习近年在语言和视觉领域取得了显著突破,但 RL 领域的进展相对滞后。
与其他 AI 领域广泛采用的深层网络结构(如 Llama 3 和 Stable Diffusion 3 拥有数百层结构)相比,基于状态的强化学习任务通常仅使用 2-5 层的浅层网络。相比之下,在视觉和语言等领域,模型往往只有在规模超过某个临界值时才能获得解决特定任务的能力,因此研究人员一直在寻找 RL 中类似的能力涌现现象。
创新方法
普林斯顿大学和华沙理工的最新研究提出,通过将神经网络深度从常见的 2-5 层扩展到 1024 层,可以显著提升自监督 RL 的性能,特别是在无监督目标条件任务中的目标达成能力。
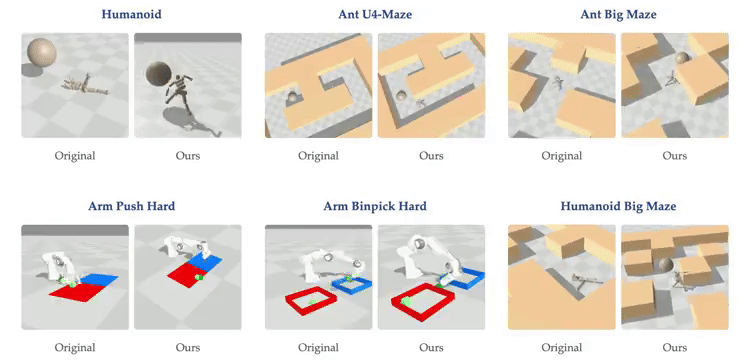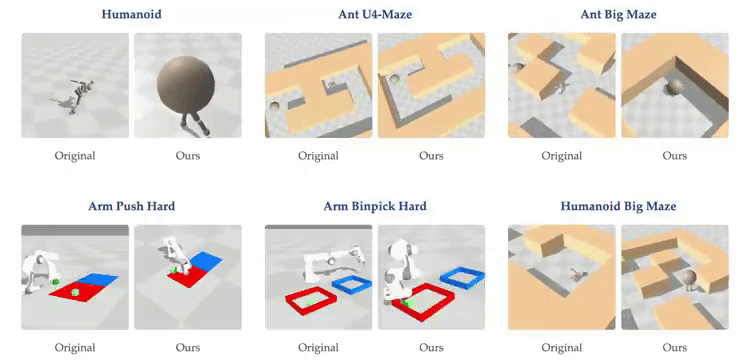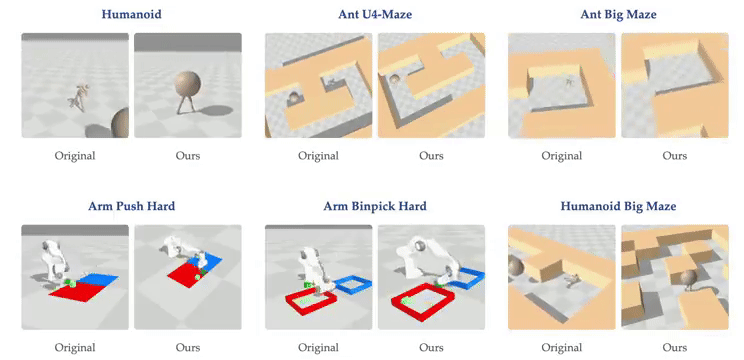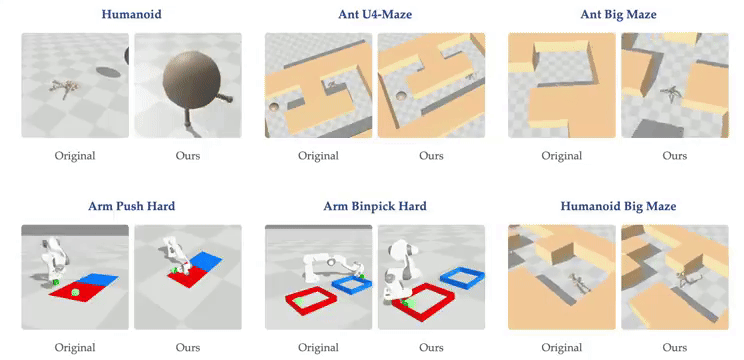
这一发现挑战了传统观点。过去认为训练大型 RL 网络困难是因为 RL 问题提供的反馈极为稀少(如长序列观测后的稀疏奖励),导致反馈与参数比率很小。传统观点认为大型 AI 系统应主要以自监督方式训练,而强化学习仅用于微调。
研究团队从三个关键方面进行创新:
-
范式融合:重新定义「强化学习」和「自监督学习」的关系,将它们结合形成自监督强化学习系统,采用对比强化学习(Contrastive RL, CRL)算法;
-
增加数据量:通过近期的 GPU 加速强化学习框架增加可用数据量;
-
网络深度突破:将网络深度增加到比先前工作深 100 倍,并融合多种架构技术稳定训练过程,包括:残差连接(Residual Connections)、层归一化(Layer Normalization)、Swish 激活函数。
此外,研究还探究了批大小(batch size)和网络宽度(network width)的相对重要性。
关键发现
随着网络深度的扩大,我们能发现虚拟环境中的强化学习智能体出现了新行为:在深度 4 时,人形机器人会直接向目标坠落,而在深度 16 时,它学会了直立行走。在人形机器人 U-Maze 环境中,在深度 256 时,出现了一种独特的学习策略:智能体学会了越过迷宫高墙。
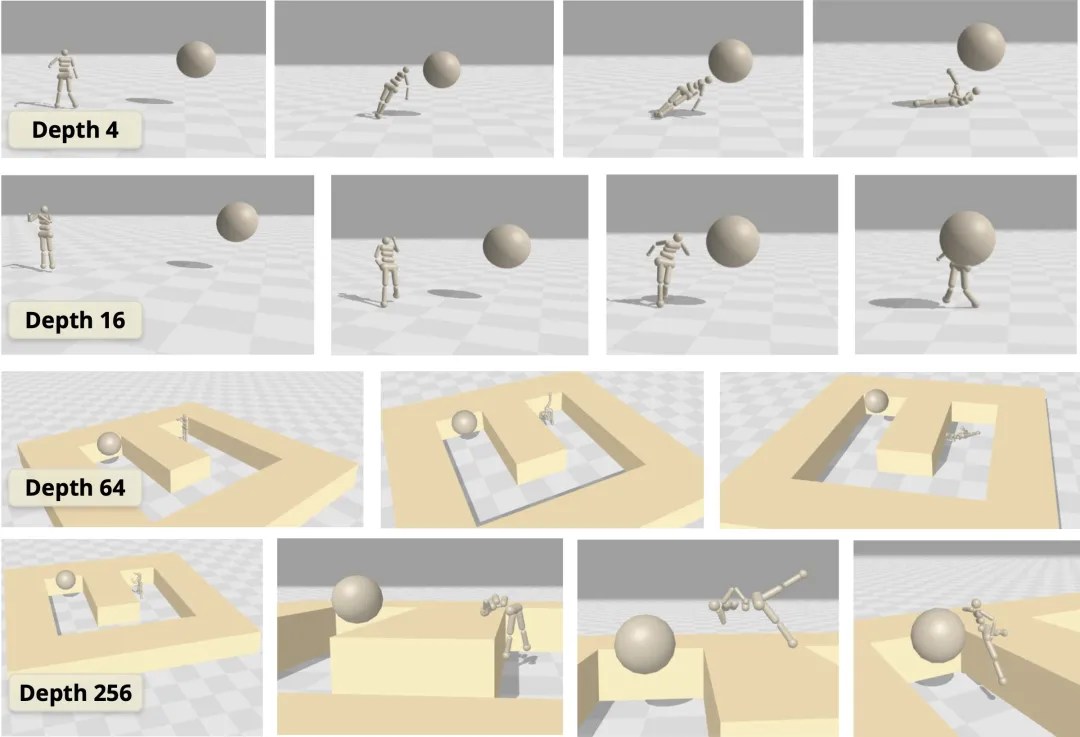
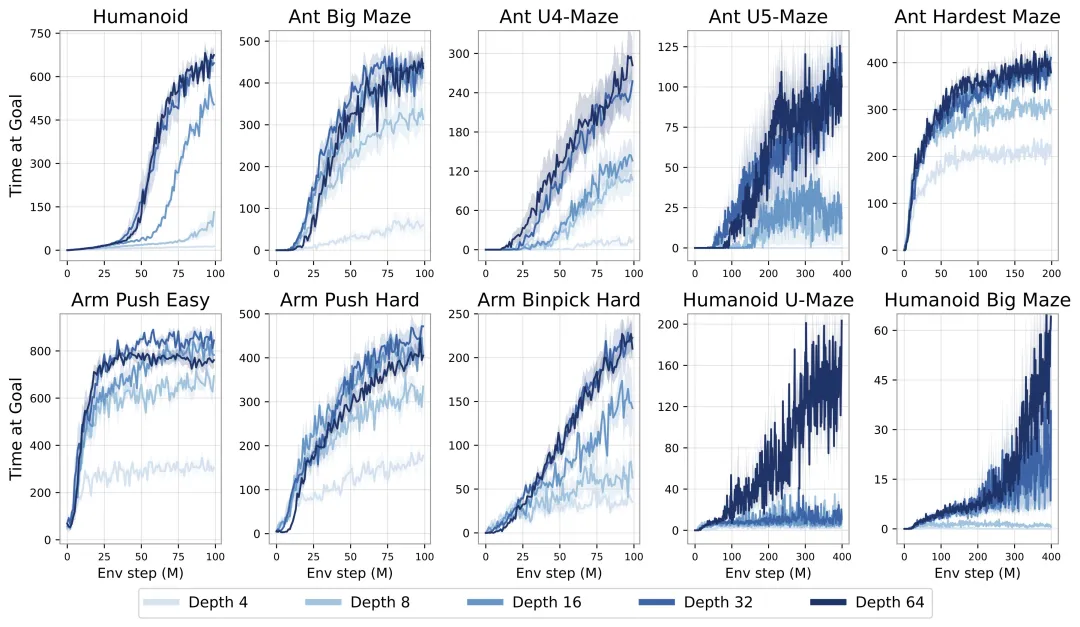
进一步研究,人们发现在具有高维输入的复杂任务中,深度扩展的优势更大。在扩展效果最为突出的 Humanoid U-Maze 环境中,研究人员测试了扩展的极限,并观察到高达 1024 层的性能持续提升。
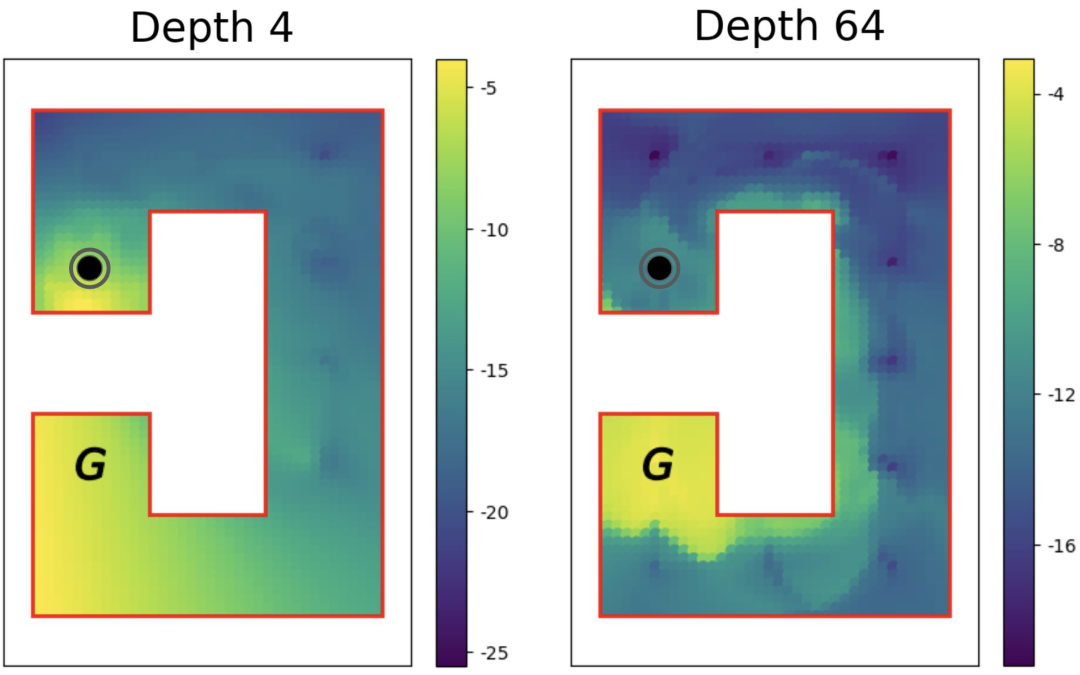
另外,更深的网络可以学习到更好的对比表征。仅在导航任务中,Depth-4 网络使用到目标的欧几里得距离简单地近似 Q 值,而 Depth-64 能够捕捉迷宫拓扑,并使用高 Q 值勾勒出可行路径。
扩展网络深度也能提高 AI 的泛化能力。在训练期间未见过的起始-目标对上进行测试时,与较浅的网络相比,较深的网络在更高比例的任务上取得了成功。
技术细节
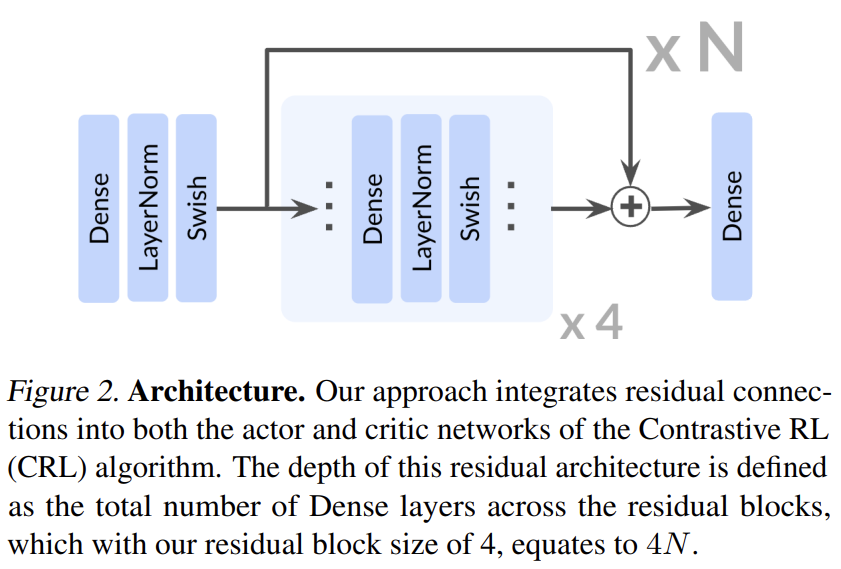
该研究采用了来自 ResNet 架构的残差连接,每个残差块由四个重复单元组成,每个单元包含一个 Dense 层、一个层归一化(Layer Normalization)层和 Swish 激活函数。残差连接在残差块的最终激活函数之后立即应用。
在本论文中,网络深度被定义为架构中所有残差块的 Dense 层总数。在所有实验中,深度指的是 actor 网络和两个 critic encoder 网络的配置,这些网络被共同扩展。
研究贡献
本研究的主要贡献在于展示了一种将多种构建模块整合到单一强化学习方法中的方式,该方法展现出卓越的可扩展性:
-
实证可扩展性:研究观察到性能显著提升,在半数测试环境中提升超过 20 倍,这对应着随模型规模增长而涌现的质变策略;
-
网络架构深度的扩展:虽然许多先前的强化学习研究主要关注增加网络宽度,但在扩展深度时通常只能报告有限甚至负面的收益。相比之下,本方法成功解锁了沿深度轴扩展的能力,产生的性能改进超过了仅靠扩展宽度所能达到的;
-
实证分析:研究表明更深的网络表现出增强的拼接能力,能够学习更准确的价值函数,并有效利用更大批量大小带来的优势。
不过,拓展网络深度是以消耗计算量为代价的,使用分布式训练来提升算力,以及剪枝蒸馏是未来的扩展方向。
预计未来研究将在此基础上,通过探索额外的构建模块来进一步发展这一方法。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com