探索机器学习特征筛选的向后淘汰法:从原理到Python实现,提升模型性能与可解释性。
原文标题:机器学习特征筛选:向后淘汰法原理与Python实现
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章提到了手动实现向后淘汰法可以进行更精细的控制,那么在手动实现时,除了调整显著性水平(p值)之外,还可以从哪些方面进行更深入的定制化?
3、文章对比了statsmodels的自动化实现和Scikit-learn的递归特征消除(RFE),那么在实际项目中,应该如何选择这两种方法?它们各自的优缺点是什么?
原文内容

向后淘汰法(Backward Elimination)是机器学习领域中一种重要的特征选择技术,其核心思想是通过系统性地移除对模型贡献较小的特征,以提高模型性能和可解释性。该方法从完整特征集出发,逐步剔除不重要的特征,最终保留对预测结果最具影响力的变量子集。
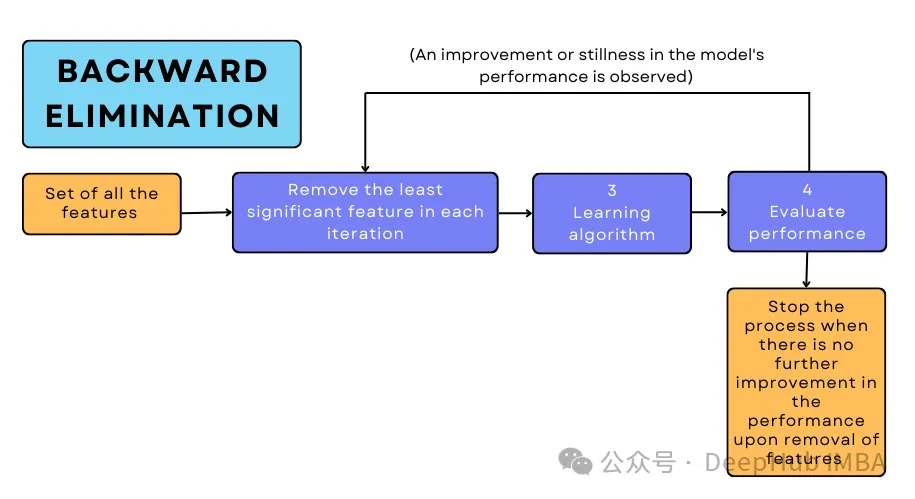
向后淘汰法的工作原理
-
初始模型构建:首先使用数据集中的全部特征构建模型。
-
模型拟合:在完整特征集上训练机器学习模型。
-
特征重要性评估:通过统计测试或性能指标(如线性回归中的p值)评估各个特征的重要性。
-
特征剔除:识别并移除对模型贡献最小的特征(例如具有最高p值或对模型性能影响最小的特征)。
-
模型重构:使用剩余特征重新训练模型。
-
迭代优化:重复上述过程,直到达到某个停止条件——例如所有剩余特征均达到统计显著性,或进一步移除特征会导致模型性能下降。
向后淘汰法的优势
线性回归中的向后淘汰法实例
方法局限性
Python实现向后淘汰法
基于statsmodels的自动化实现
向后淘汰法的手动实现
import pandas as pd import numpy as np import statsmodels.api as sm from sklearn.datasets import make_regression生成示例数据
X, y = make_regression(n_samples=100, n_features=5, noise=0.1, random_state=42)
添加常数项作为截距
X = sm.add_constant(X)
def backward_elimination(X, y, significance_level=0.05):
features = X.columns.tolist()
while len(features) > 0:拟合模型
model = sm.OLS(y, X[features]).fit()
获取各特征的p值
p_values = model.pvalues[1:] # 排除常数项
max_p_value = max(p_values)
if max_p_value > significance_level:如果最大p值超过阈值,移除该特征
excluded_feature = features[p_values.argmax()]
print(f’移除特征: {excluded_feature},p值为 {max_p_value}')
features.remove(excluded_feature)
else:
break
return features将X转换为DataFrame以使用列名
X_df = pd.DataFrame(X, columns=[‘const’, ‘Feature1’, ‘Feature2’, ‘Feature3’, ‘Feature4’, ‘Feature5’])
执行向后淘汰
selected_features = backward_elimination(X_df, y)
print(‘保留的特征:’, selected_features)
