腾讯AI Lab与厦大联合提出Fetch框架,解决大语言模型树搜索中的“过思考”与“欠思考”问题,提升计算效率和推理效能。
原文标题:树搜索也存在「过思考」与「欠思考」?腾讯AI Lab与厦大联合提出高效树搜索框架
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到使用SimCSE模型提取节点语义特征向量,并进行微调。除了SimCSE,还有哪些其他的语义相似度计算方法可以应用在这个场景中?各自的优缺点是什么?
3、Fetch框架通过合并语义重复的节点来避免冗余计算,但是如何确定两个节点是否“语义重复”?如果判断不准确,可能会导致什么问题?
原文内容

通讯作者包括腾讯 AI Lab研究员宋林峰与涂兆鹏,以及厦门大学苏劲松教授。论文第一作者为厦门大学博士生王安特。
本文探讨基于树搜索的大语言模型推理过程中存在的「过思考」与「欠思考」问题,并提出高效树搜索框架——Fetch。本研究由腾讯 AI Lab 与厦门大学、苏州大学研究团队合作完成。

-
论文题目:Don't Get Lost in the Trees: Streamlining LLM Reasoning by Overcoming Tree Search Exploration Pitfalls
-
论文地址:https://arxiv.org/abs/2502.11183
背景与动机
近月来,OpenAI-o1 展现的卓越推理性能激发了通过推理时计算扩展(Test-Time Computation)增强大语言模型(LLMs)推理能力的研究热潮。
该研究领域内,基于验证器引导的树搜索算法已成为相对成熟的技术路径。这类算法通过系统探索庞大的解空间,在复杂问题的最优解搜索方面展现出显著优势,其有效性已获得多项研究实证支持。
尽管诸如集束搜索(Beam Search)、最佳优先搜索(Best-First Search)、A*算法及蒙特卡洛树搜索(MCTS)等传统树搜索算法已得到广泛探索,但其固有缺陷仍待解决:树搜索算法需承担高昂的计算开销,且难以根据问题复杂度动态调整计算资源分配。
针对上述挑战,研究团队通过系统性解构树搜索的行为范式,首次揭示了该推理过程中存在的「过思考」与「欠思考」双重困境。
「过思考」与「欠思考」
研究团队选取最佳优先搜索算法为研究对象,基于 GSM8K 数据集开展系统性研究。实验设置中逐步增加子节点拓展数(N=2,3,5,10)时发现:模型性能虽持续提升但呈现边际效益递减规律(图 a),而计算开销却呈指数级增长(图 b),二者形成的显著差异揭示出传统树搜索在推理时计算扩展的效率瓶颈。
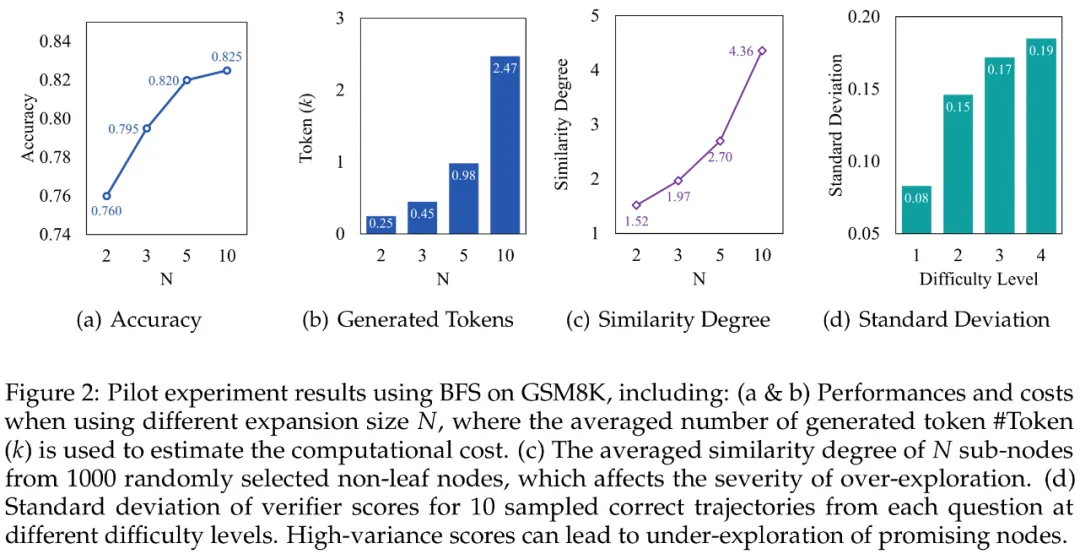
通过深度解构搜索过程,研究团队首次揭示搜索树中存在两类关键缺陷:
-
节点冗余:由于大语言模型采样机制的随机性,搜索树中生成大量语义重复节点(图 c)。量化分析采用基于语义相似度的节点聚类方法,定义重复度为平均类内节点数,该指标与计算开销呈现显著正相关,此现象直接导致算法重复遍历相似推理路径,形成「过思考」困境;
-
验证器不稳定性:引导搜索的验证器存在一定的鲁棒性缺陷,节点评分易受推理路径表述差异影响而产生非必要波动(图 d),在复杂数学推理场景中尤为明显。这种不稳定性可能引发搜索路径的局部震荡,迫使搜索算法过早终止高潜力路径的深度探索,从而产生「欠思考」现象。
Fetch
为应对「过思考」与「欠思考」问题,研究团队提出适用于主流搜索算法的高效树搜索框架 Fetch,其核心包含两部分:
-
冗余节点合并(State Merging):通过合并语义重复的节点,有效避免冗余节点的重复探索。
-
验证方差抑制(Variance Reduction):采用训练阶段与推理阶段的双重优化策略,降低验证器评分的非必要波动。
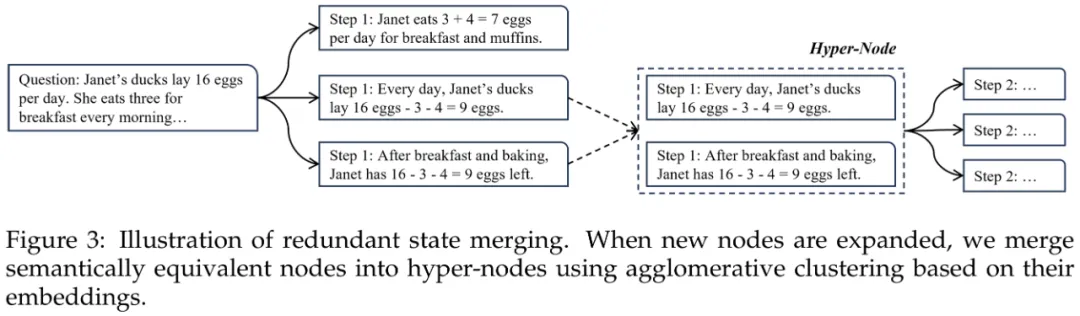
冗余节点合并
研究团队采用层次聚类算法(Agglomerative Clustering)实现节点冗余合并。具体而言,当搜索算法生成子节点后![]() ,首先基于 SimCSE 句子表示模型提取节点语义特征向量
,首先基于 SimCSE 句子表示模型提取节点语义特征向量![]() ,随后应用聚类算法形成超节点(Hyper-Node,
,随后应用聚类算法形成超节点(Hyper-Node,![]() )。该机制通过将语义等价节点聚合为单一超节点,有效避免冗余节点的重复拓展。
)。该机制通过将语义等价节点聚合为单一超节点,有效避免冗余节点的重复拓展。

针对通用领域预训练 SimCSE 在数学推理场景下存在的领域适配问题,研究团队对 SimCSE 进一步微调。为此,提出两种可选的节点对语义等价标注方案:
-
基于提示:利用大语言模型的指令遵循能力,通过用户指令自动生成节点对语义等价性标注。但受限于专家模型的指令遵循局限性,该方法可能依赖于额外的通用模型;
-
基于一致性:基于重复节点后续采样结果具有更高一致性的先验假设,通过比较节点后续推理路径的概率相似度,构建无监督标注数据集。该方法规避了对外部模型的依赖。
最终,利用收集的节点对标注,通过交叉熵损失对 SimCSE 进行微调:
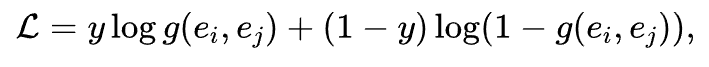
其中,![]() 表示余弦相似度计算函数。
表示余弦相似度计算函数。
验证方差抑制
现有验证器普遍采用判别方式对树节点进行质量评分。传统训练方法基于强化学习经验,通过蒙特卡洛采样估计节点期望奖励:
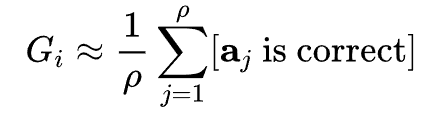
其中,![]() 表示从当前状态(节点
表示从当前状态(节点![]() )出发通过策略模型采样获取的推理路径,即
)出发通过策略模型采样获取的推理路径,即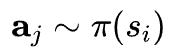 ,
,![]() 是采样的次数。受限于高昂的采样代价,
是采样的次数。受限于高昂的采样代价,![]() 通常设置较小(例如
通常设置较小(例如![]() ),导致奖励估计存在显著方差,进而削弱验证器的决策稳健性。
),导致奖励估计存在显著方差,进而削弱验证器的决策稳健性。
为此,研究团队提出训练和测试两阶段的优化方案:
在训练阶段,研究团队借鉴时序差分学习(Temporal Difference Learning),引入![]() 训练验证器。
训练验证器。![]() 是经典的强化学习算法,通过将蒙特卡洛采样与时序差分学习结合,以平衡训练数据的偏差(bias)及方差(variance)。对于节点
是经典的强化学习算法,通过将蒙特卡洛采样与时序差分学习结合,以平衡训练数据的偏差(bias)及方差(variance)。对于节点![]() ,其期望奖励为
,其期望奖励为
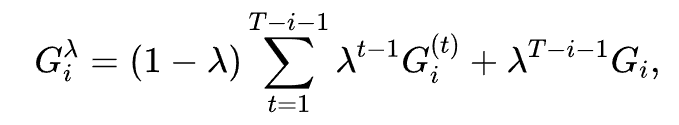
其中,![]() 是总计后续采样节点数,
是总计后续采样节点数,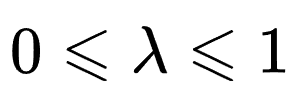 为偏差-方差权衡系数,
为偏差-方差权衡系数,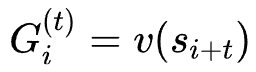 。
。
随后,通过标准的均方误差损失进行训练:
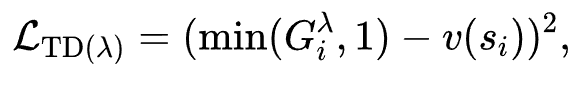
该方案虽有效降低方差,但引入的偏差可能损害验证精度,且不兼容现有开源验证器的迁移需求。因此,研究团队进一步提出在推理阶段实施验证器集成策略,以有效抑制个体验证器的异常波动:
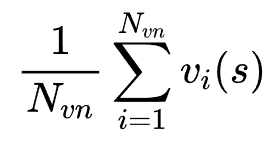
其中,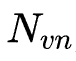 为集成验证器的个数。
为集成验证器的个数。
实验结果
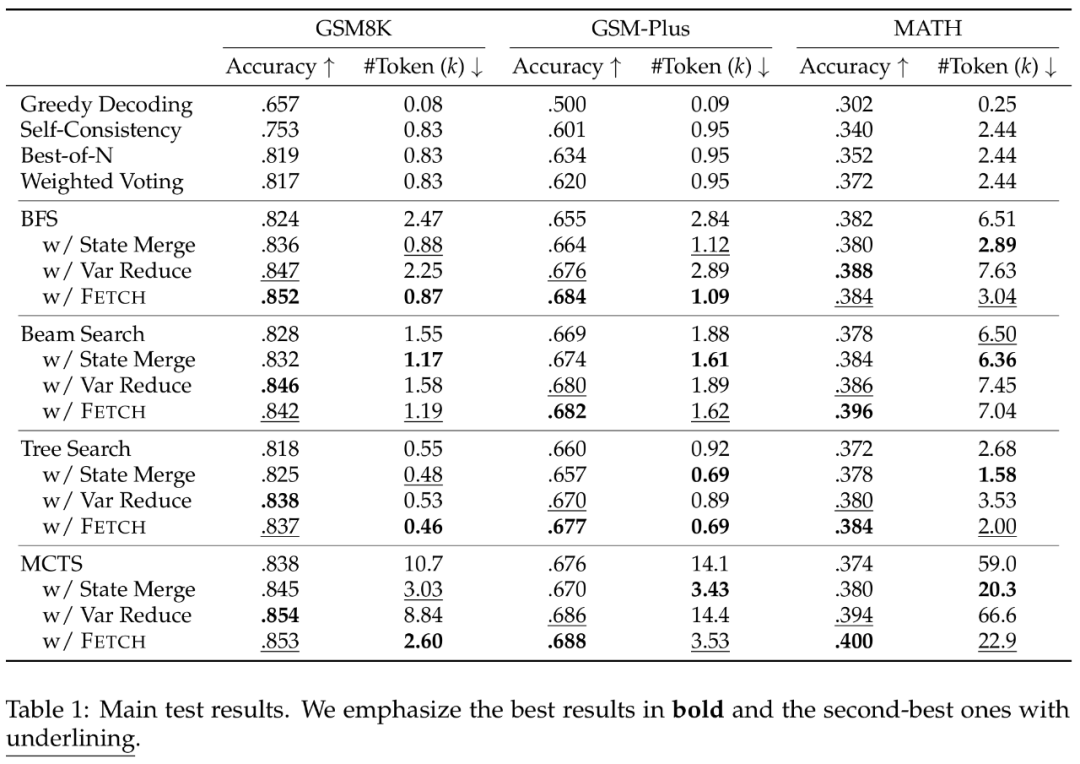
实验结果表明,Fetch 框架在跨数据集与跨算法测试中均展现出显著优势。例如,对于 BFS 及 MCTS 算法,相较于基线,Fetch 计算开销降低至原有的 1/3,并且保持 1~3 个点的准确率提升。
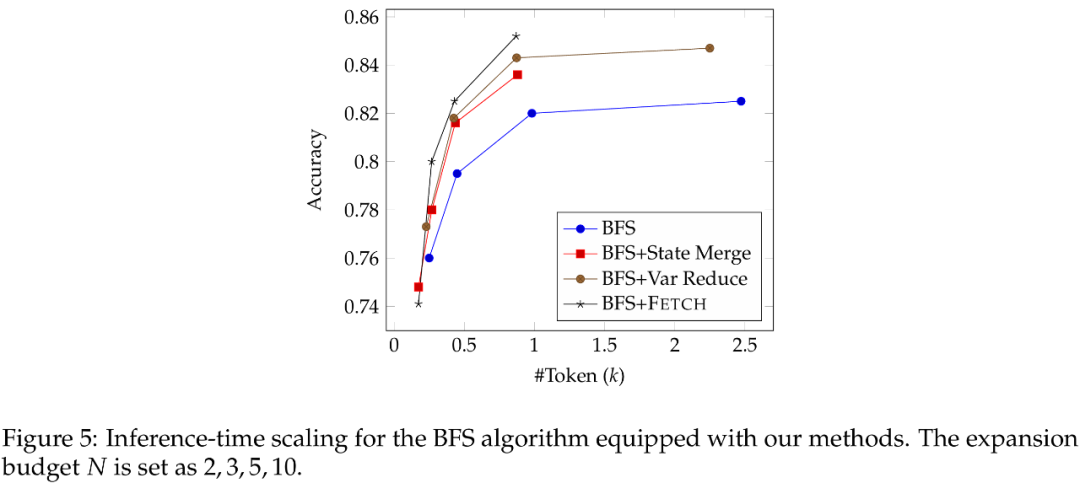
当测试时计算规模逐步提升时,Fetch 带来的增益也更加显著,验证了框架的效率优势。
总结
本研究由腾讯 AI Lab 联合厦门大学、苏州大学科研团队共同完成,首次揭示基于树搜索的大语言模型推理中存在的「过思考-欠思考」双重困境。
分析表明,该现象的核心成因源于两个关键缺陷:搜索树中大量语义冗余节点导致的无效计算循环,以及验证器评分方差过高引发的探索路径失焦。二者共同导致树搜索陷入计算资源错配困境——即消耗指数级算力却仅获得次线性性能提升。
针对上述挑战,研究团队提出高效树搜索框架 Fetch,其创新性体现在双重优化机制:
-
冗余节点合并机制,实现搜索空间的智能压缩;
-
验证方差抑制机制,保障搜索方向稳定性。
结果表明,Fetch 在 GSM8K、MATH 等基准测试中展现出显著优势:相较传统树搜索算法,框架实现了计算效率和性能的同步提升。该成果为提升大语言模型推理效能提供了新的方法论支持。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com