AlexNet 原始代码终于公开!见证深度学习的开端,探索 AI 发展历程中的关键转折点。#AlexNet #DeepLearning #OpenSource
原文标题:13年后,AlexNet源代码终于公开:带注释的原版
原文作者:机器之心
冷月清谈:
谷歌与计算机历史博物馆合作,正式公开了具有里程碑意义的 AlexNet 原始源代码。AlexNet 由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 于 2012 年开发,其在ImageNet 竞赛中的突破性表现,标志着深度学习在计算机视觉领域的崛起,并深刻影响了人工智能的发展。此次公开的代码库不仅包含原始源代码,还包括训练参数文件,为研究者提供了宝贵的学习资源,通过阅读代码和注释,可以了解AlexNet诞生的细节,或许还能从中获得新的启发。AlexNet 的成功也激发了深度学习在其他领域的应用,如自然语言处理、机器人和推荐系统。此次开源历时 5 年,由计算机历史博物馆与谷歌协商完成。
怜星夜思:
1、AlexNet 的成功除了模型本身的创新,还有哪些关键因素?比如硬件或者数据集方面的影响?
2、现在有很多优秀的深度学习框架,如果让你用现代框架复现 AlexNet,你会如何改进?
3、你觉得 AlexNet 源代码的公开,对于现在的 AI 研究者来说,最大的价值是什么?
2、现在有很多优秀的深度学习框架,如果让你用现代框架复现 AlexNet,你会如何改进?
3、你觉得 AlexNet 源代码的公开,对于现在的 AI 研究者来说,最大的价值是什么?
原文内容
机器之心报道
编辑:张倩、泽南
从一行行代码、注释中感受 AlexNet 的诞生,或许老代码中还藏着启发未来的「新」知识。
想知道 AlexNet 2012 年的原始代码长什么样吗?现在,机会来了!刚刚,谷歌首席科学家 Jeff Dean 宣布,他们与计算机历史博物馆(CHM)合作,共同发布了 AlexNet 的源代码,并将长期保存这些代码。

开放后的代码库如下:
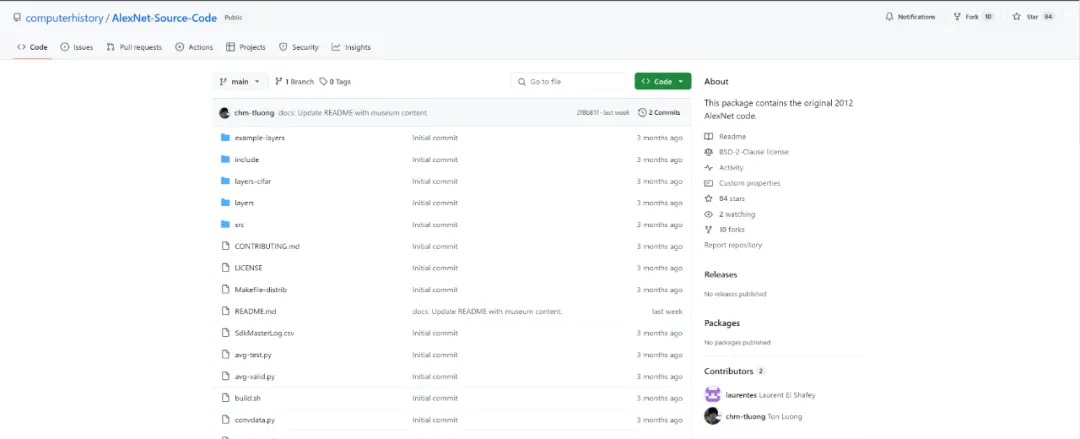
GitHub 链接:https://github.com/computerhistory/AlexNet-Source-Code
AlexNet 是一个人工神经网络,用于识别照片内容。它由当时的多伦多大学研究生 Alex Krizhevsky 和 Ilya Sutskever 以及他们的导师 Geoffrey Hinton 于 2012 年开发。
在计算机历史上,AlexNet 的出现有着划时代的意义。在它出现之前,很少有机器学习研究人员使用神经网络。但在 AlexNet 出现之后,几乎所有研究人员都会使用神经网络。从 2012 年到 2022 年,神经网络不断取得进步,包括合成可信的人类声音、击败围棋冠军选手、模拟人类语言并生成艺术作品…… 最终,OpenAI 于 2022 年发布 ChatGPT…… 它是这一系列故事的重要起点。
「谷歌很高兴将具有开创性意义的 AlexNet 项目的源代码贡献给计算机历史博物馆,」Jeff Dean 说,「这段代码是 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 撰写的标志性论文《ImageNet Classification with Deep Convolutional Neural Networks》的基础,该论文革新了计算机视觉领域,是有史以来被引用次数最多的论文之一。」

Google Scholar 数据显示,AlexNet 相关论文被引量已经超过 17 万。
除了代码本身的价值,HuggingFace 联合创始人 Thomas Wolf 还发现,代码中的注释也非常有启发性。他说,「也许真正的历史记录是 AlexNet 代码中每个实验配置文件末尾的实验记录注释。一个开创性的神经网络正在诞生……」
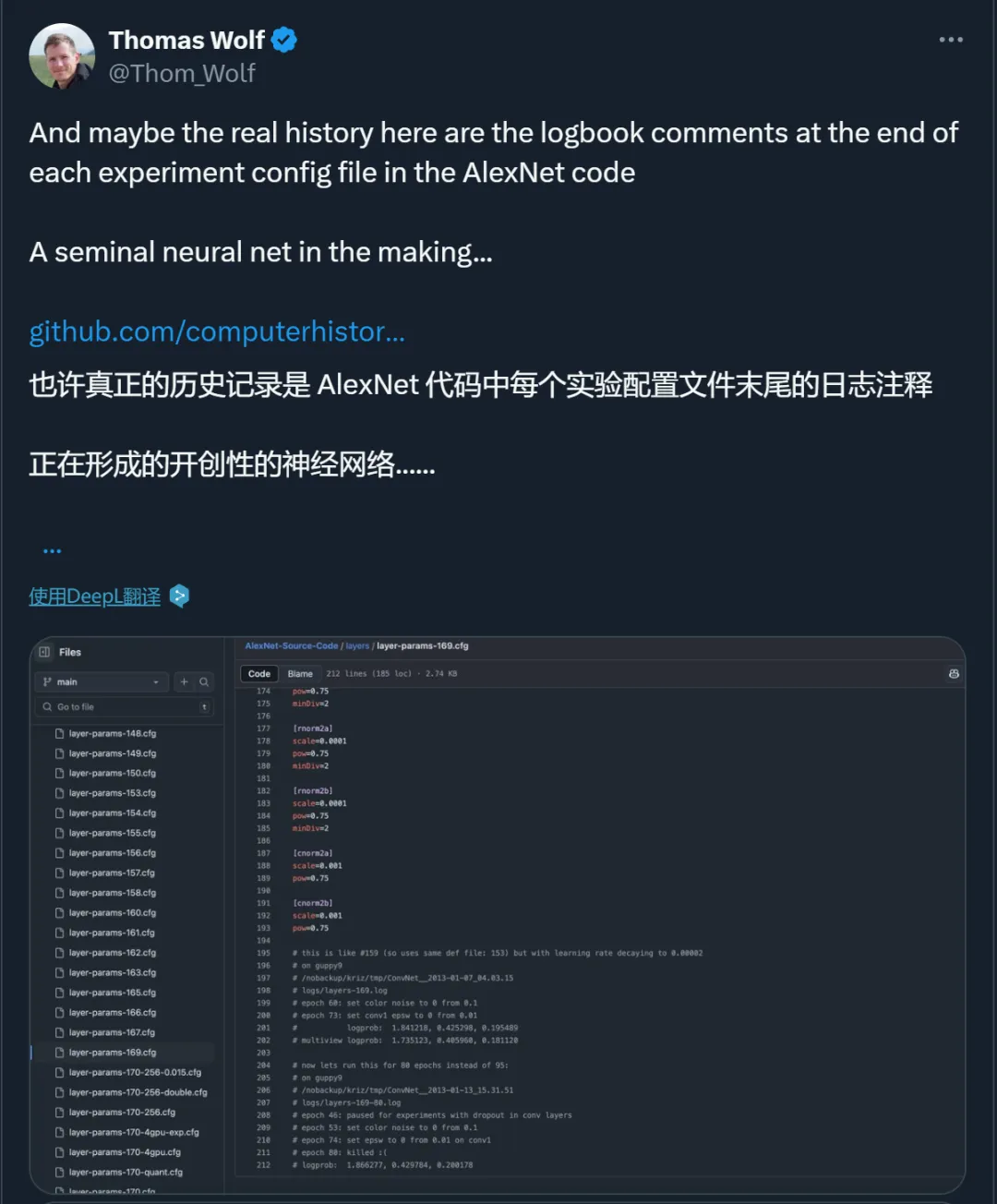
还有人说,「AlexNet 代码的发布对于 AI 爱好者来说是一个宝库,这是一个向深度学习先驱学习的绝佳机会」。
AlexNet,人工智能历史的转折点
在人工智能领域,AlexNet 可谓爆发的起点。就在本周的英伟达 GTC 大会上,黄仁勋介绍起 AI 的发展历程,未来的一头是智能体、物理世界的 AI,过去的一头就是 AlexNet。

AI、机器学习、深度学习的概念可以追溯到几十年前,然而它们在过去的十几年里才真正流行起来,这可能的确要归功于 AlexNet。
在 2012 年,来自多伦多大学的 Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton 等人提出了一个名为「AlexNet」的深度神经网络,赢得了 2012 年大规模视觉识别挑战赛 ImageNet 的冠军。

三位都是 AI 领域里响当当的人物。Geoffrey Hinton 被誉为「深度学习之父」,后来获得了 2018 年的图灵奖、2024 年的诺贝尔物理学奖;Ilya Sutskever 是 OpenAI 的联合创始人及前首席科学家,也是 AlphaGo 论文的众多作者之一。冠名该模型的 Alex Krizhevsky 也是 CIFAR-10 和 CIFAR-100 数据集的创建者,不过他却逐渐对研究失去了兴趣,于 2017 年 9 月离开了谷歌。
在描述当年的 AlexNet 项目时,Geoffrey Hinton 总结道:「Ilya 认为我们应该做这件事,Alex 让它成功了,而我获得了诺贝尔奖。」

当年用于训练 AlexNet 的家用计算机和 GPU。
在 ImageNet 竞赛中,参赛者需要完成一个名叫「object region」的任务,即给定一张包含某目标的图像和一串目标类别(如飞机、瓶子、猫),每个团队的实现都需要识别出图像中的目标属于哪个类。
在当年的比赛中,AlexNet 的表现颇具颠覆性,团队首次使用一种名为卷积神经网络(CNN)的深度学习架构,并充分利用了英伟达 GPU 的能力。由于表现过于惊艳,之后几年的 ImageNet 挑战赛冠军都沿用了 CNN。
AlexNet 的论文被 2012 年的 NeurIPS 大会接收并发表,起初也受到了一些计算机视觉研究者的质疑,但出席会议的 Yann LeCun 宣布这是人工智能发展的转折点。后来发生的事情我们也都知道了:在 AlexNet 之前,几乎没有一篇领先的计算机视觉论文使用神经网络。在它之后,几乎所有论文都会使用神经网络。
这是计算机视觉史上的一个关键时刻,也激发了人们将深度学习应用于其他领域(如自然语言处理、机器人、推荐系统)的兴趣。
开放源代码,历时五年
AlexNet 源代码顺利发布的故事,还要从五年前说起。
2020 年,CHM 软件历史中心馆长 Hansen Hsu 联系了 Alex Krizhevsky,希望获得发布授权。不过,Alex Krizhevsky 并没有直接回应,而是将 Hansen Hsu 介绍给了当时还在谷歌工作的 Hinton。因为,在谷歌收购了 Hinton、Sutskever 和 Krizhevsky 创办的公司 DNNresearch 之后,AlexNet 的知识产权就归了谷歌。
之后,Hinton 在 CHM 和谷歌的团队之间斡旋,推动整件事的进程。双方花了五年的时间,协商发布事宜,以及具体的发布版本。
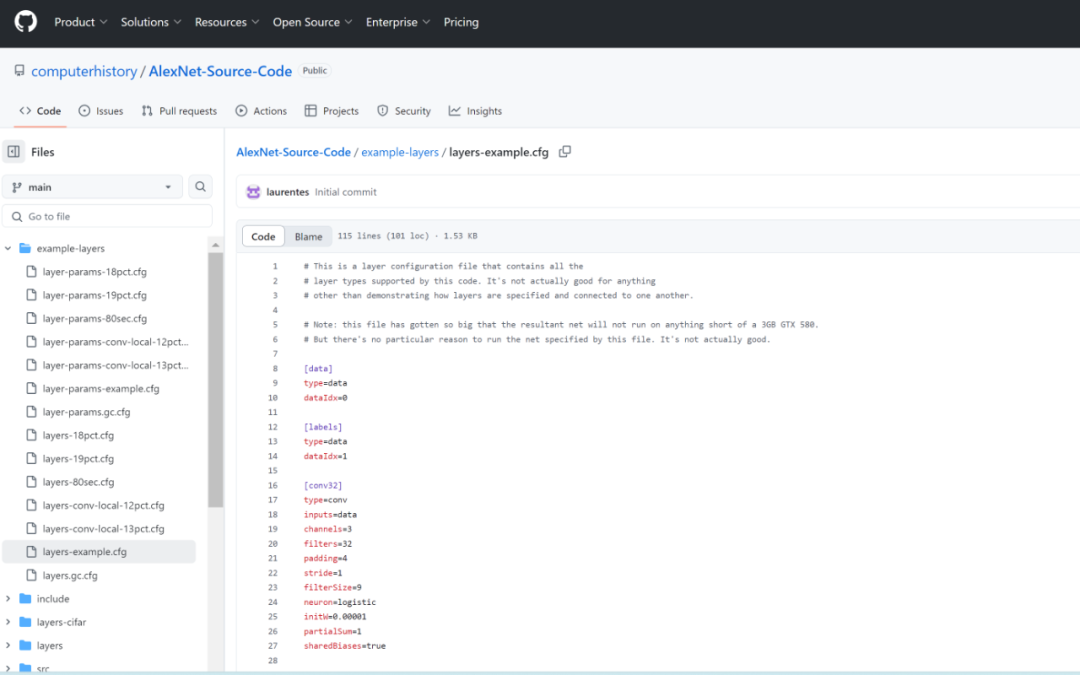
事实上,自 2012 年论文发布后,AlexNet 的源码已经有了多个版本,GitHub 上也有不少名为「AlexNet」的代码库,但其中许多并不是原始代码,而是根据那篇论文重新创建的。此前,Krizhevsky 开发的 AlexNet 前身 ——cuda-convnet 也曾作为开源代码发布,但它是在较小的 CIFAR-10 数据集上训练的。
CHM 发布的代码库包含了 2012 年赢得 ImageNet 竞赛时的原始 AlexNet 源代码,还包括在 ImageNet 数据集上训练的参数文件。
感兴趣的同学可以前去翻看。
参考链接:
https://computerhistory.org/blog/chm-releases-alexnet-source-code/

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com