人大高瓴提出TTR框架,通过预训练大语言模型和运动编码器,使AI能够“思考”人类动作,并生成更自然的反应,提升人机交互体验。
原文标题:AI预判了你的预判!人大高瓴团队发布TTR,教会AI一眼看穿你的下一步
原文作者:机器之心
冷月清谈:
中国人民大学高瓴人工智能学院的研究团队提出了一种新的框架——Think-Then-React (TTR),该框架结合了预训练大语言模型(LLM)和运动编码器,旨在使AI能够更好地理解人类动作的意图,并生成更自然、连贯的反应动作。
TTR框架包含以下几个关键组成部分与创新点:
1. 统一运动编码器:通过解耦空间-位姿编码,同时保证了编码系统的高效利用与交互过程中两人相对位置信息保留。
2. 运动-文本联合预训练:通过将运动数据与文本数据结合,让大语言模型能够同时处理文本和运动数据,学习到两者之间的对应关系,以便在后续的反应生成过程中能够更好地理解和生成与动作相关的反应。
3. 思考-反应生成(Thinking-Reacting):类似于人类的决策和行动流程,在某种程度上模拟了人类对外界刺激的反应机制。
实验结果表明,TTR 在反应动作生成质量上表现出色,尤其是在长时间序列场景中,用户更偏好 TTR 生成的动作。消融实验也验证了各个模块的有效性,例如,去除思考阶段会导致性能显著下降。此外,TTR 在运动描述任务上也取得了最佳性能。
TTR框架包含以下几个关键组成部分与创新点:
1. 统一运动编码器:通过解耦空间-位姿编码,同时保证了编码系统的高效利用与交互过程中两人相对位置信息保留。
2. 运动-文本联合预训练:通过将运动数据与文本数据结合,让大语言模型能够同时处理文本和运动数据,学习到两者之间的对应关系,以便在后续的反应生成过程中能够更好地理解和生成与动作相关的反应。
3. 思考-反应生成(Thinking-Reacting):类似于人类的决策和行动流程,在某种程度上模拟了人类对外界刺激的反应机制。
实验结果表明,TTR 在反应动作生成质量上表现出色,尤其是在长时间序列场景中,用户更偏好 TTR 生成的动作。消融实验也验证了各个模块的有效性,例如,去除思考阶段会导致性能显著下降。此外,TTR 在运动描述任务上也取得了最佳性能。
怜星夜思:
1、TTR框架中提到的“思考”过程,是否真的能让AI理解人类行为背后的意图,还是仅仅在模仿人类的反应模式?这种理解的深度如何衡量?
2、TTR框架中,单人动作数据对模型效果的提升不明显,这是否意味着在人机交互中,单人动作识别的价值不大?或者说,单人动作数据在人机交互中应该如何更有效地利用?
3、TTR框架在实时推理方面表现出色,延迟低于50毫秒。那么,在实际应用中,除了延迟之外,还有哪些因素会影响用户体验?如何进一步优化TTR框架,以提升整体的用户体验?
2、TTR框架中,单人动作数据对模型效果的提升不明显,这是否意味着在人机交互中,单人动作识别的价值不大?或者说,单人动作数据在人机交互中应该如何更有效地利用?
3、TTR框架在实时推理方面表现出色,延迟低于50毫秒。那么,在实际应用中,除了延迟之外,还有哪些因素会影响用户体验?如何进一步优化TTR框架,以提升整体的用户体验?
原文内容

本文作者均来自中国人民大学高瓴人工智能学院。其中,第一作者谭文辉是人大高瓴博士生(导师:宋睿华长聘副教授),他的研究兴趣主要在多模态与具身智能。本文通讯作者为宋睿华长聘副教授,她的团队 AIMind 主要研究方向为多模态感知、生成与交互。
对面有个人向你缓缓抬起手,你会怎么回应呢?握手,还是挥手致意?
在生活中,我们每天都在和别人互动,但这些互动很多时候都不太确定,很难直接猜到对方动作意图,以及应该作何反应。
为此,来自人大高瓴的研究团队提出了一种新的框架 ——Think-Then-React (TTR),采用预训练大语言模型(LLM)+ 运动编码器的策略,使模型能够先「思考」输入动作的意义,再推理出适合的反应,最后生成连贯的反应动作。该论文已被 ICLR 2025 接收。

-
论文标题:Think-Then-React: Towards Unconstrained Human Action-to-Reaction Generation
-
论文链接:https://openreview.net/pdf?id=UxzKcIZedp
-
项目链接:Think-Then-React.github.io
图1 :Think-Then-React (TTR) 模型总览图。TTR 通过动作编码器将人类动作编码为大语言模型可读的标记,进而在预测人类反应过程中使用大语言模型识别动作,推理出合适的反应动作。推理过程中,模型不间断地进行重新思考,以避免动作的错误识别以及累计误差。
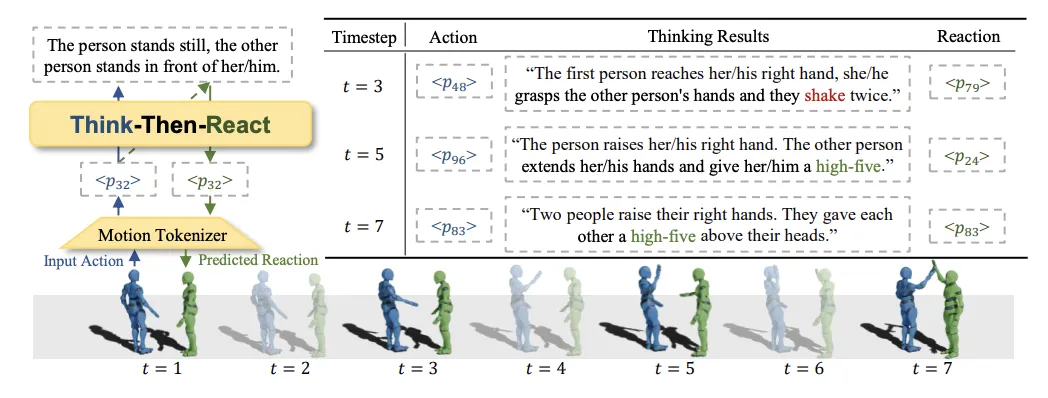
方法
统一运动编码器
TTR 方法的第一步是通过统一运动编码器处理输入的动作数据。过去的工作通常将人类动作起始姿态在空间上规范化至坐标轴原点,以保证编码器的高效利用。然而这种方式忽略了人类交互场景中的相对位置关系。
为此,作者团队提出解耦空间 - 位姿编码,将人类动作的全局信息(空间中的位置与身体朝向)与局部信息(运动位姿)分别编码并组合使用,同时保证了编码系统的高效利用与交互过程中两人相对位置信息保留。
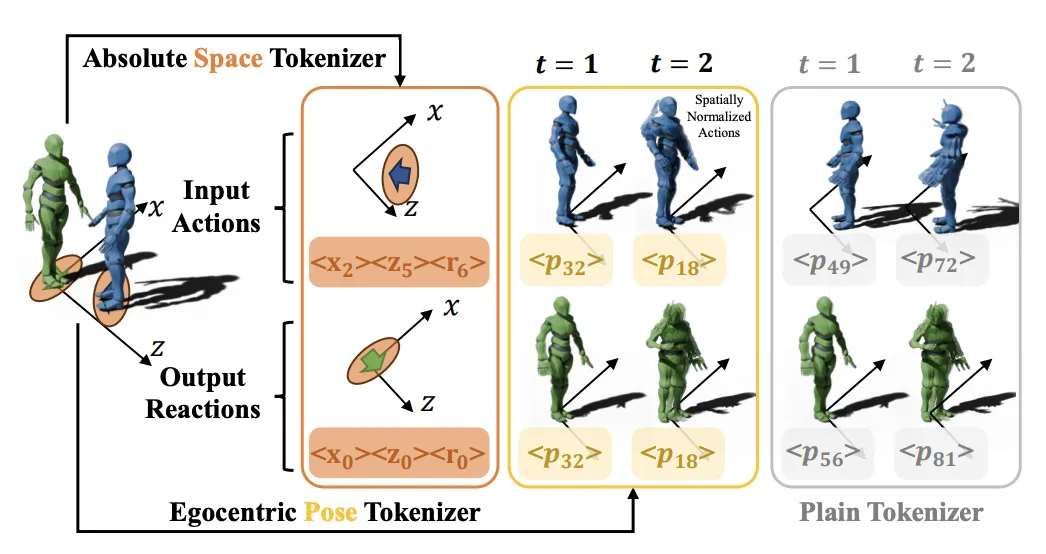
图2 :空间 - 位姿解耦编码器与传统编码器架构对比。
运动 - 文本联合预训练
为了提升模型对运动数据和语言的理解能力,作者设计了一系列运动与文本相关的预训练任务。这些任务的目标是让大语言模型能够同时处理文本和运动数据,从而在多模态的环境中进行知识迁移和任务执行。
在这个阶段,模型通过将运动数据与文本数据结合,学习到两者之间的对应关系,以便在后续的反应生成过程中能够更好地理解和生成与动作相关的反应。
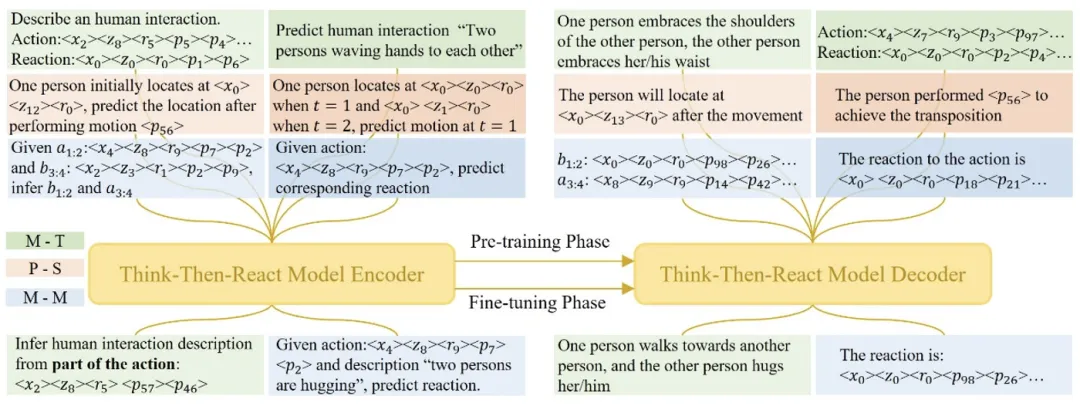
图3 :TTR 预训练与微调阶段任务示意图。
思考 - 反应生成(Thinking-Reacting)
TTR 方法的核心是分阶段生成反应动作。具体来说,模型首先进入「思考」阶段(Think),在此阶段中,模型理解输入动作的含义,并判断出什么样的反应是合适的。
接下来,进入「反应」阶段(React),模型根据思考结果生成与输入动作相关的反应动作。这一过程类似于人类的决策和行动流程,在某种程度上模拟了人类对外界刺激的反应机制。
实验
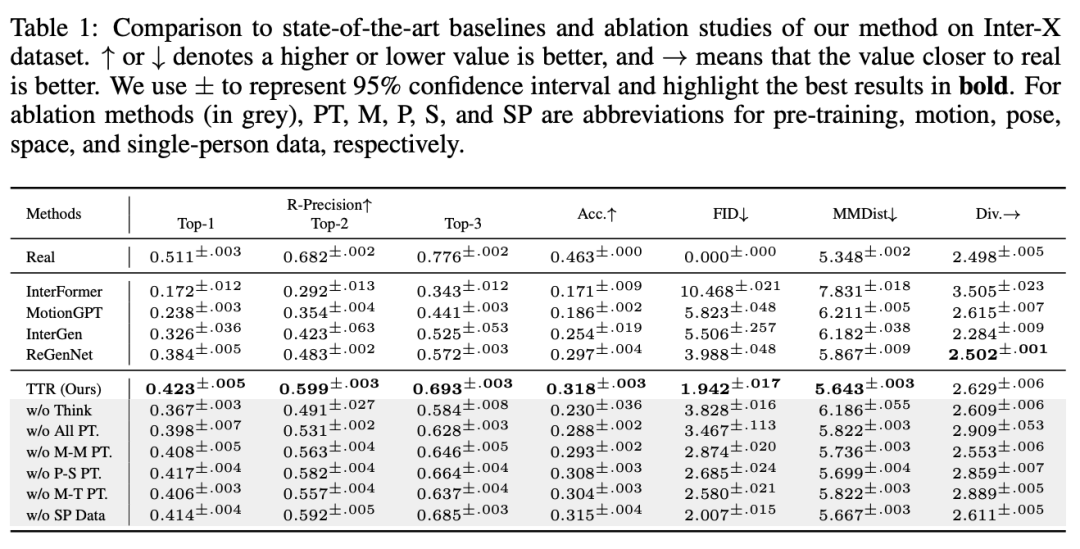
反应动作生成质量测评
TTR 在不同的任务上,包括 R-Precision、分类准确率(Acc.)、Frechet Inception Distance (FID)、多模态距离(MMDist.)等方面,均取得了优异的性能。
TTR 的 FID 仅为 1.942,相较于次优方法 ReGenNet (3.988) 显著降低。此外,在 R-Precision 和分类准确率方面,TTR 也取得了更高的分数,表明其生成的反应动作更加符合输入动作的语义。
同样,在对比 TTR 与 ReGenNet 的用户研究中,受试者更偏好 TTR 生成的动作,特别是在较长时间序列的场景中,TTR 以 76.2% 的胜率胜出。
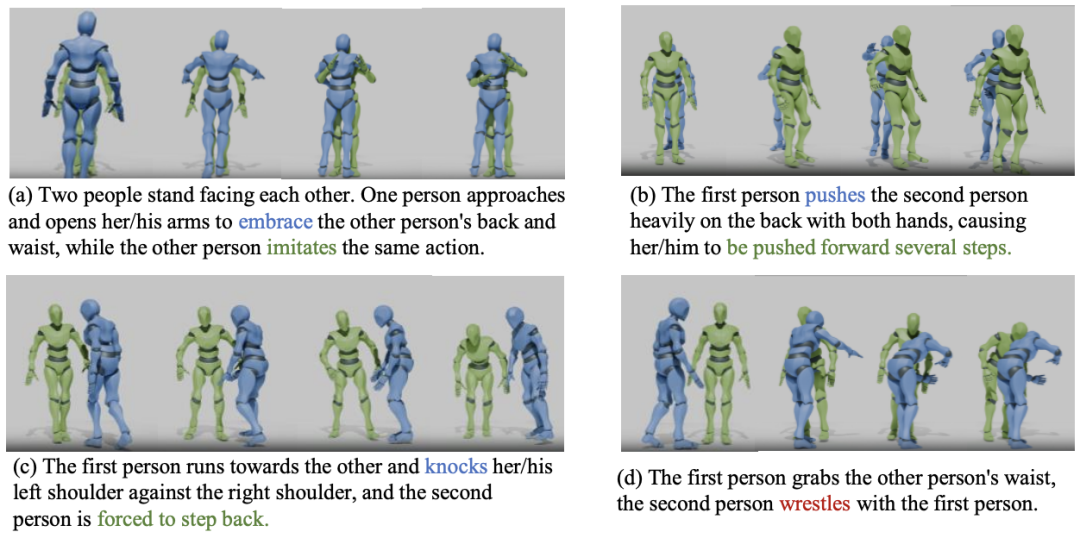
图4 :TTR 思考与预测反应(绿色)可视化样例。在样例 (a) 至 (c) 中,TTR 思考过程正确识别并推理出了相应动作,进而预测了正确的反应。在样例 (d) 中,TTR 错误地将对方动作(蓝色)识别为「摔跤」(正确动作为「拥抱」),预测了错误的反应。
消融实验
为了更进一步验证文中所提方法的有效性,作者团队进行了多项消融实验:
-
去除思考(w/o Think):FID 从 1.942 上升到 3.828,证明了思考阶段对反应生成的重要性。
-
去除预训练(w/o All PT.):模型性能大幅下降,表明预训练对于适应运动 - 语言模态至关重要。
-
去除不同预训练任务:三种预训练任务(动作 - 动作、空间 - 位姿、动作 - 文本)均有正向贡献,互为补充。
-
去除单人数据(w/o SP Data):仅依赖多人的数据仍可取得较好结果,单人数据的补充对模型表现提升不显著。

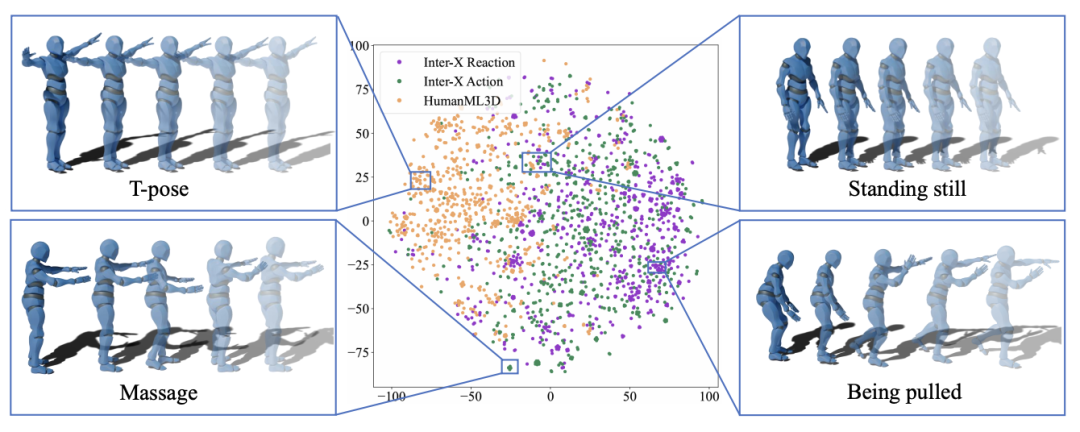
图五:多人交互数据集 Inter-X Action/Reaction 以及单人动作数据集 HumanML3D 动作特征示意图。
系统分析
-
单人动作数据有效性
为了进一步分析单人数据贡献较小的原因,作者在同一空间中可视化了单人运动(HumanML3D)、交互动作(Inter-X Action)和交互反应(Inter-X Reaction)的运动序列,如上图所示。
具体而言,该团队使用 t-SNE 工具将运动分词序列的特征投影到二维空间。从上图可以看出,单人运动与两人运动序列几乎没有重叠。
在案例分析中,作者发现大多数交互运动是独特的,例如按摩、被拉拽等,而这些动作不会出现在单人运动数据中。同样,大多数单人运动也是独特的,例如 T 字姿势,很少出现在多人交互中。两者只有少量重叠的运动,如静止站立。
-
重新思考时间间隔
TTR 的重新思考(re-thinking)机制可以动态调整生成的反应描述,从而减少累积误差,同时在计算成本上保持高效。
实验表明,过高与过低的重新思考频率均会导致性能下降。在保证高性能的情况下,TTR 的平均推理时间可以在单张 Tesla V100 上实现实时推理(延迟低于 50 毫秒)。
-
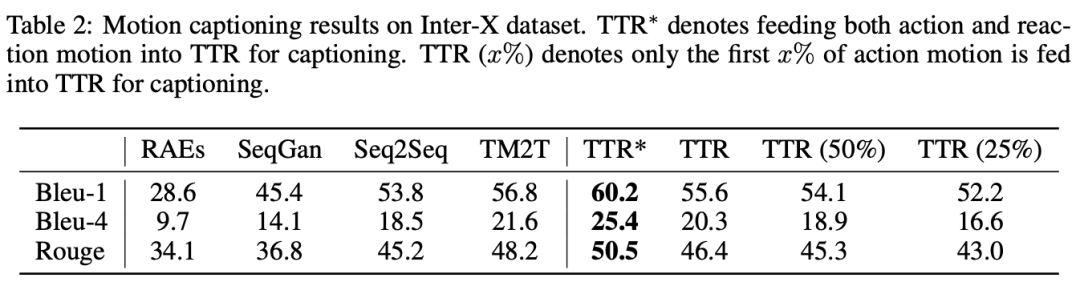
动作描述质量
作者还在运动描述任务上对 TTR 模型进行了评估,结果下表所示。基线方法的结果来源于 Inter-X 论文的附录 A.1。由于基线方法均使用动作和反应作为输入,而 TTR 的思考过程仅能访问真实的动作,因此作者首先调整 TTR 的设置,使其与基线方法一致,记作 TTR∗。
从结果可以看出,得益于作者的细粒度训练和高效的运动表示,TTR∗ 在所有指标上都取得了最佳的运动描述性能。
随后在真实场景下评估 TTR,即仅能看到部分输入动作。作者分别使用 25%、50% 和完整的输入动作,让 TTR 进行动作到文本的生成。
结果表明,即使仅提供四分之一的输入动作,TTR 仍然能够准确预测对应的动作和反应描述,展现出较强的泛化能力。
-
思考 / 动作描述
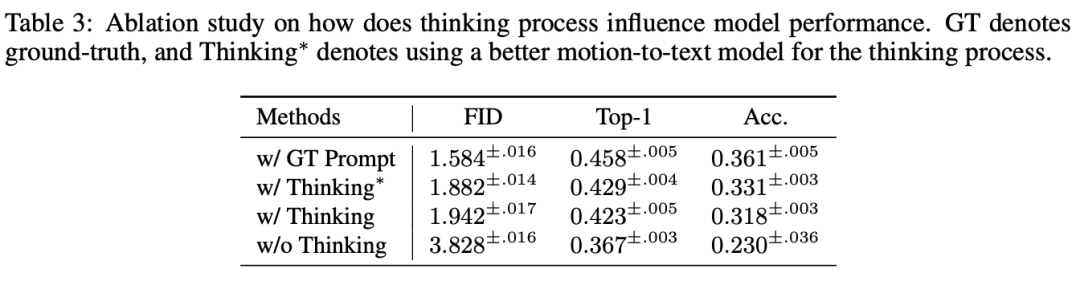
为了探究思考过程的必要性,作者比较了不同的提示对反应生成的影响。
首先,将真实提示 (w/ GT Prompt) 输入到思考过程中,结果表明,预测的反应质量显著提升。
然后,作者采用了一个增强版的思考模型 (w/ Thinking*),结果 FID 从 1.94 降至 1.88,这证明了更好的思考过程能够有效提升后续的反应生成能力。
此外,当完全去除思考过程时,模型的反应生成质量大幅下降,这表明思考与重新思考(re-thinking)过程在指导反应生成和减少累积误差方面至关重要。
总结
综上所述,该团队借用大语言模型的推理能力,设计了「先思考,后反应」的人类反应动作预测框架 Think-Then-React (TTR),并且通过解耦空间 - 位姿编码系统实现了人类动作高效编码,提升了预测反应动作质量。
与过往工作相比,TTR 模型在 Inter-X 数据集多个指标上均有明显提升,同时作者通过大量消融实验与分析实验验证了方法的有效性。
在未来,作者团队计划探索更高效的跨类别数据集利用,包括单人与多人动作数据,以实现更高的泛化性能。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com