NXAI 团队再次优化 xLSTM,推出 7B 模型,推理速度超越 Mamba 50%,权重代码已开源。核心改进包括优化架构、提升训练稳定性等。
原文标题:原作者带队再次改造xLSTM,7B模型速度最快超Mamba 50%,权重代码全开源
原文作者:机器之心
冷月清谈:
本文介绍了 NXAI 团队对 xLSTM 架构的最新优化成果,该优化使得 xLSTM 模型可以扩展到 70 亿参数,并在推理速度上超越了 Mamba 模型 50%。核心改进包括:1. 在低维空间运行 mLSTM 并添加前馈 MLP 层,优化了模块架构,提高吞吐量;2. 解决了训练稳定性问题,特别是在 mLSTM 单元的门控机制上,有效缓解了梯度问题;3. 采用 RMSNorm 替代 LayerNorm,并对输入门和遗忘门实施软上限限制,对输入门偏置进行负初始化。实验结果表明,优化后的 xLSTM 7B 模型在各类任务评估中与同规模 Transformer 和 Mamba 模型表现相当,并在推理效率测试中实现了最高的预填充和生成吞吐量,同时保持了最低的 GPU 内存占用。
怜星夜思:
1、xLSTM 7B 在长文本处理上的优势和局限分别是什么?在实际应用中,你认为它更适合处理哪些类型的长文本任务?
2、文章提到 xLSTM 7B 在推理速度上超越了 Mamba。你认为未来 xLSTM 在哪些方面还有提升空间,可以进一步拉开与 Mamba 和 Transformer 的差距?
3、xLSTM 7B 在哪些实际应用场景中能够发挥其优势?例如,在移动设备或边缘计算等资源受限的环境中,它相比其他模型有哪些优势?
2、文章提到 xLSTM 7B 在推理速度上超越了 Mamba。你认为未来 xLSTM 在哪些方面还有提升空间,可以进一步拉开与 Mamba 和 Transformer 的差距?
3、xLSTM 7B 在哪些实际应用场景中能够发挥其优势?例如,在移动设备或边缘计算等资源受限的环境中,它相比其他模型有哪些优势?
原文内容
机器之心报道
编辑:佳琳、杜伟
近年来,大型语言模型(LLM)通过大量计算资源在推理阶段取得了解决复杂问题的突破。推理速度已成为 LLM 架构的关键属性,市场对高效快速的 LLM 需求不断增长。
其中,采用 Transformer 架构的模型虽然占据了主流,但在输入序列长度增加时,计算量会呈二次方增长。因此,自上个世纪 90 年代兴起的 LSTM 卷土重来,它的提出者和奠基者 Sepp Hochreiter 在去年 5 月推出了 ,将 LSTM 扩展到数十亿参数,成为 Transformer 的有力替代品,提供了与序列长度线性相关的计算扩展和稳定的内存占用。
然而,xLSTM 在扩展至更大参数规模时存在限制,推理速度和效率具体如何也没做系统测评。
近日,Sepp Hochreiter 等来自 NXAI、JKU 的研究者再次对 xLSTM 进行了优化,现在可以扩展到 70 亿参数了。
具体来讲,xLSTM 7B 模型基于 DCLM 数据集,使用 128 块 H100 GPU,在 8192 上下文长度下训练了 2.3 万亿 token。研究者对原始 xLSTM 架构进行了改进,确保训练效率和稳定性,同时保持任务性能。新架构依靠 mLSTM 单元和并行训练模式,实现高性能的同时最大化速度。

-
论文标题:xLSTM 7B: A Recurrent LLM for Fast and Efficient Inference
-
论文地址:https://arxiv.org/pdf/2503.13427
-
代码地址:https://github.com/NX-AI/xlstm
-
Hugging Face 地址:https://huggingface.co/NX-AI/xLSTM-7b
通过修改模块架构,研究者优化了吞吐量,在低维空间运行 mLSTM 并添加前馈 MLP 层,同时去除了不必要的组件以提高 GPU 利用率。优化后的架构在保持相似性能的同时,将 token 吞吐量提高了 2 到 4 倍。研究者还优化了训练稳定性,特别是 mLSTM 单元的门控机制,有效解决了梯度问题。
在各类任务评估中,xLSTM 7B 与同规模 Transformer 和 Mamba 模型表现相当。通过架构优化,该模型在推理效率测试中实现了最高的预填充和生成吞吐量,同时保持最低的 GPU 内存占用。
论文作者之一 Günter Klambauer 表示,xLSTM 7B 成为了最快、最高效的 7B 语言模型!
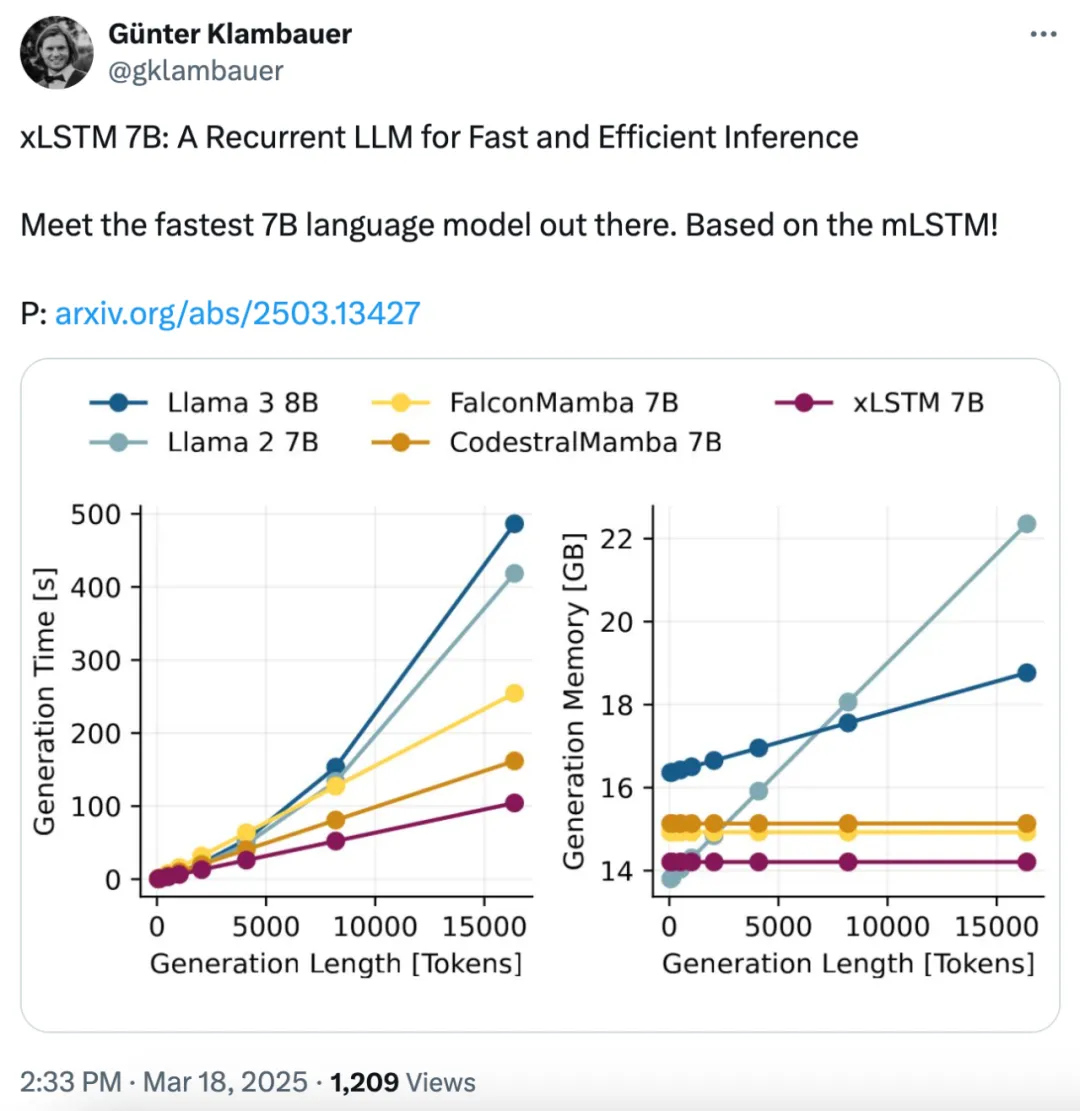
优化的 xLSTM 7B 架构
xLSTM 7B 架构的核心是 mLSTM 单元,它的循环和并行模式可以实现高效的训练和推理。为了充分发挥该单元的潜力,研究者重新审视了相邻块结构的设计。
与 Mamba 等其他线性 RNN 类似,以前的 xLSTM 架构将与通道卷积相结合的 mLSTM 单元置于线性上投影和下投影之间,这被称为预上投影(pre up-projection )块。这些块将序列混合和通道混合结合在一个块中,因此均匀堆叠,而无需交错位于前馈 MLP 层。尽管预上投影块架构已展示出了对 1.4B 参数 xLSTM 的竞争性语言建模性能,但由于以下几方面的原因,它在计算效率方面付出了很大代价:
-
在预上投影块中,mLSTM 在比模型嵌入维数高得多的维数上运行,这导致 mLSTM 操作的计算成本和 GPU 内存使用量大幅增加。
-
省略位置前馈 MLP 层会导致模型中高效线性层 FLOP 的比例下降。
-
以前的 xLSTM 架构使用几个额外的组件,例如可学习的残差连接、通道卷积以及用于计算查询、键和值的小(块对角化)投影层。如果没有自定义内核融合,这些小操作会导致 GPU 上出现多个短内核调用,无法有效利用张量核心,从而大幅降低 GPU 利用率。
-
以前,输入和遗忘门预激活是通过连接的查询、键和值投影计算出来的。而在大规模张量并行训练设置中,这需要每个 mLSTM 块进行额外的全归约操作,从而增加总体通信成本。
因此,为了将 xLSTM 扩展到更大的模型大小,研究者通过解决以上四个限制来优化 mLSTM 块以实现最大效率。
对于优化 mLSTM 块,研究者首先在模型的嵌入维数而不是更高维数的空间中操作 mLSTM 单元,并在每个 mLSTM 层之后放置位置前馈 MLP 层。此修改增加了高度优化的线性层(即矩阵乘法)FLOP 的比例,并降低了 mLSTM 操作的计算成本。显著减少的 GPU 内存使用量使得在训练期间可以使用更大的批大小,从而提高了训练效率。
此外,研究者放弃了通道卷积和可学习的残差连接等操作,并用密集线性层替换块查询、键和值投影。这再次增加了线性层 FLOP,并确保有效使用 mLSTM 层内的张量核。最后,确保每个 head 的门预激活都是独立计算的。
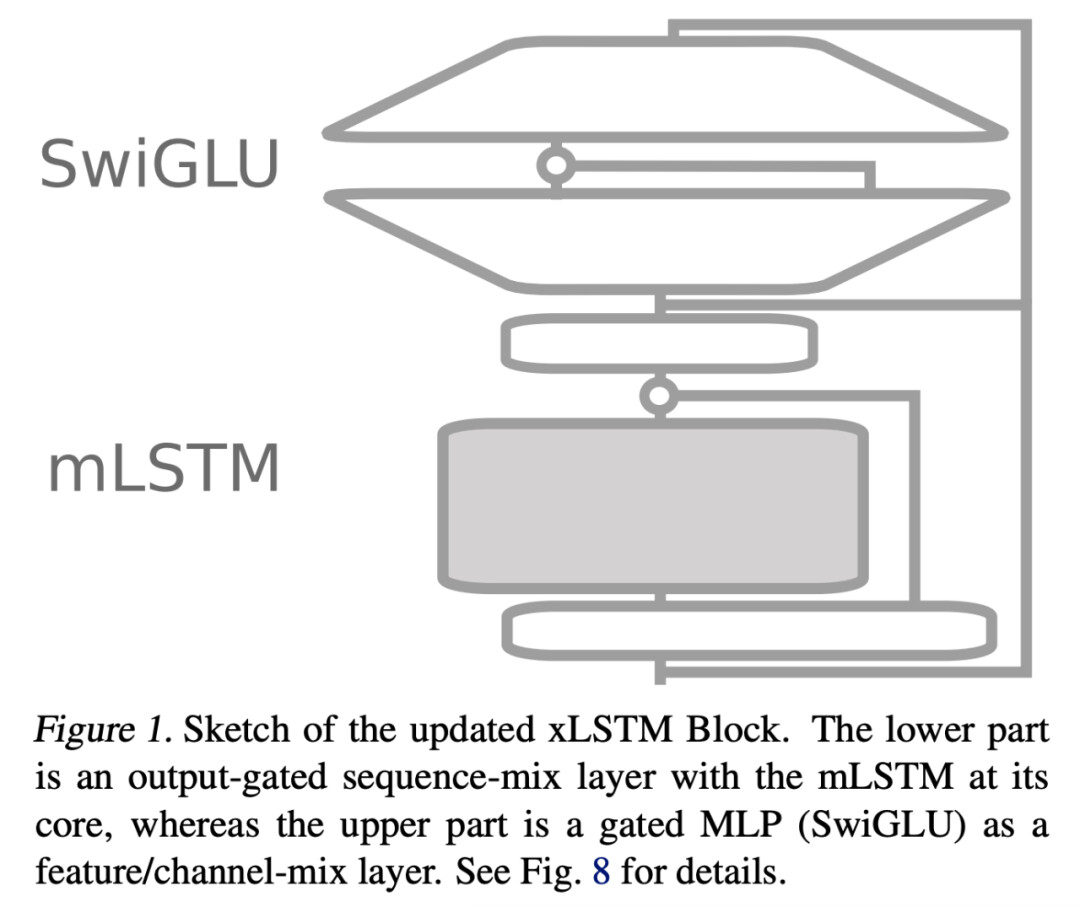
这些优化产生了下图 1 和下图 8 中改进后的 mLSTM 块和 xLSTM 架构,其中在 xLSTM 7B 架构中堆叠了 32 个 mLSTM 块。
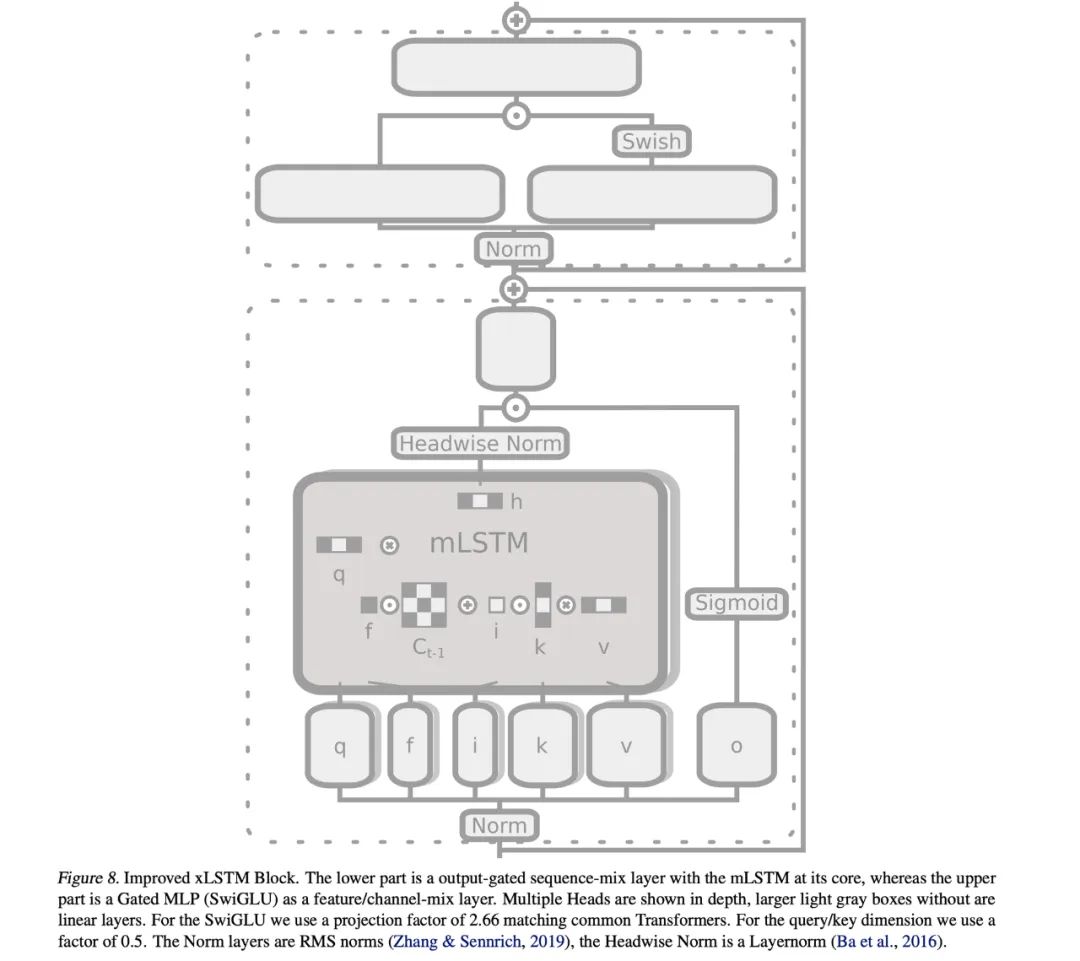
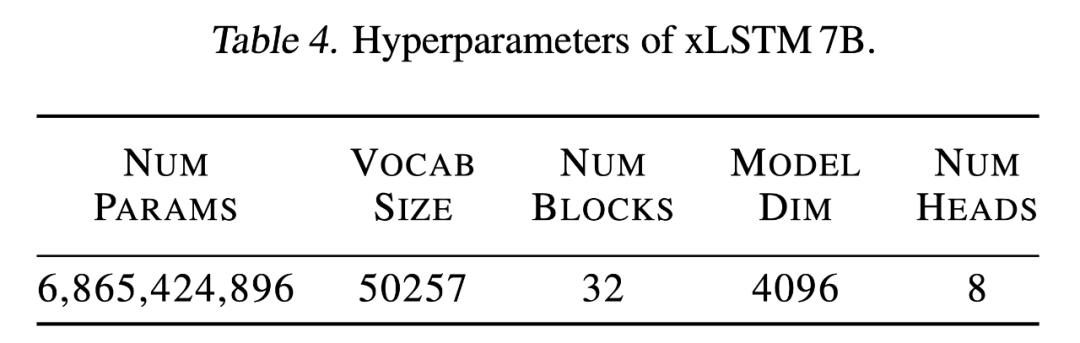
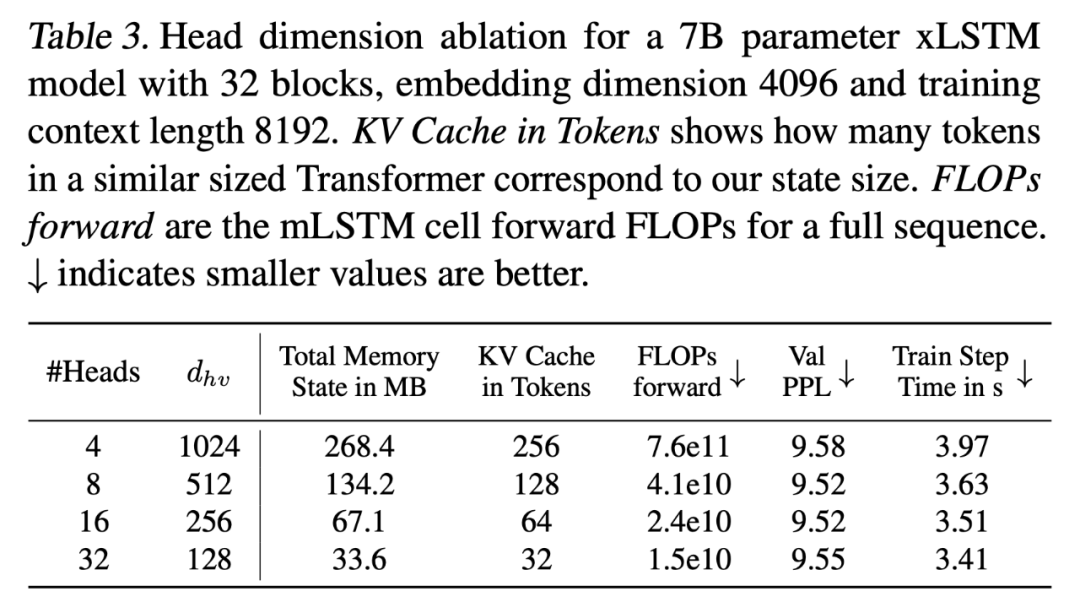
下表 4 为 xLSTM 7B 的超参数,包括模型参数(近 70 亿)、词表大小(50257)、块数量(32)、模型维数(4096)以及 head 数(8)。
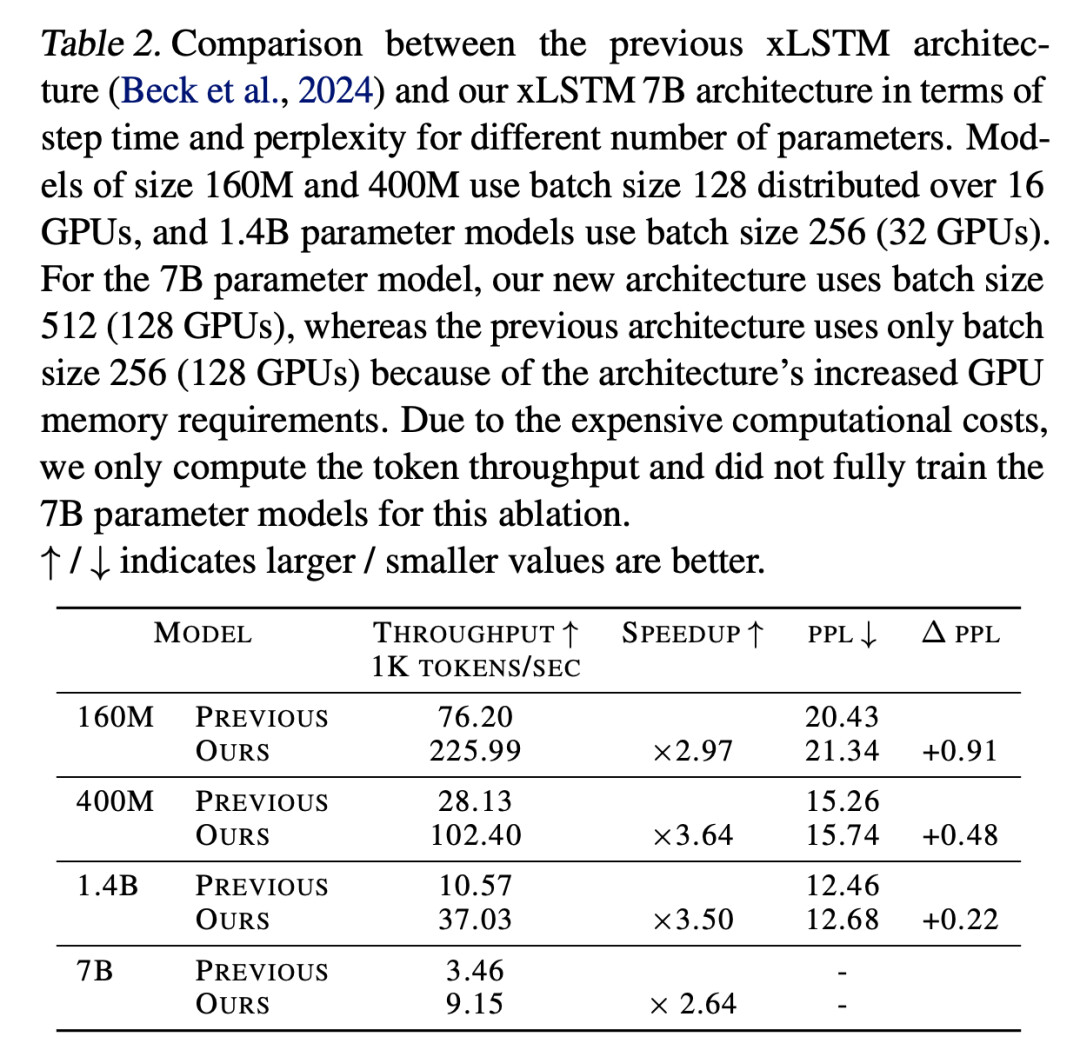
研究者观察到,本文优化在 1.4B 参数的模型训练中实现了 3.5 倍的加速,但在验证困惑度方面略有损失,可以通过增加几个训练步骤来缓解,详见下表 2。
优化稳定性
研究者发现,先前在 7B 参数规模下的 xLSTM 架构在训练初期阶段常出现不稳定现象。具体而言,他们观察到在较高学习率条件下训练会导致梯度幅度和损失值剧烈波动。本文通过以下方法解决了这些稳定性问题:
-
使用 RMSNorm 替代 LayerNorm;
-
对输入门和遗忘门实施软上限限制;
-
对输入门偏置进行负初始化。
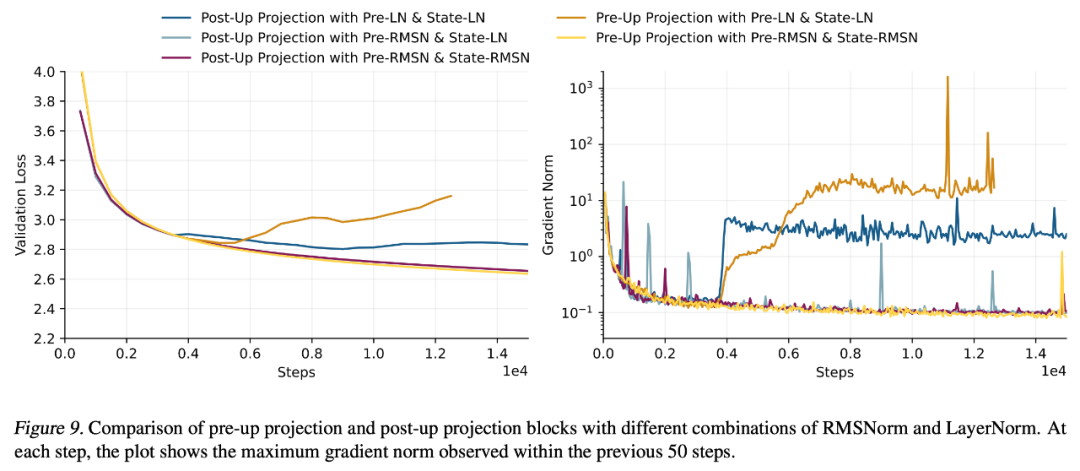
1. 使用 RMSNorm 的预归一化(Pre-Norm with RMSNorm)
下图 9 中的实验证实,预归一化技术同样适用于 xLSTM 架构的预归一化层。因此,研究者在 xLSTM 架构中将 LayerNorm 替换为 RMSNorm(全称为 Root Mean Square Normalization)。
2. 门控软上限限制(Gate Soft-Capping)
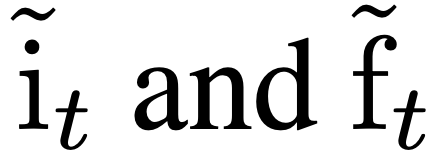
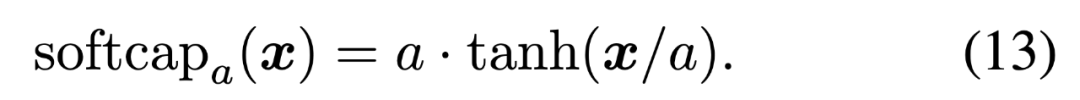
3. 负输入门偏置初始化(Negative Input Gate Bias Initialization)
研究者发现,在训练初期,xLSTM 模型会出现较大的梯度范数峰值,这对模型的最终性能产生不利影响(详见下图 11)。将输入门初始化为较大的负值(如 - 10)能有效缓解这些梯度范数峰值,从而提升模型性能。
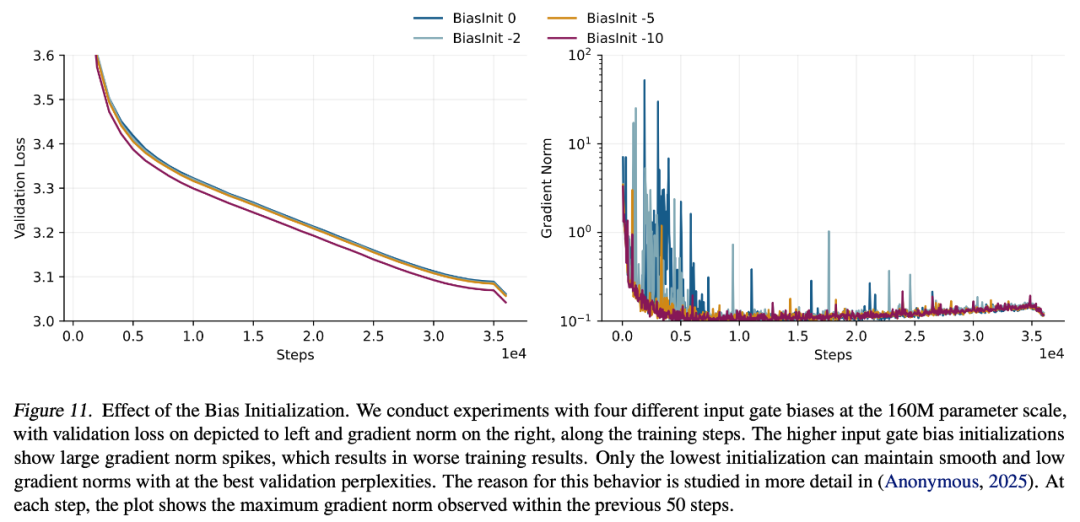
综上所述,这些优化措施使 xLSTM 7B 的预训练过程变得极为稳定,如下图 2 所示。
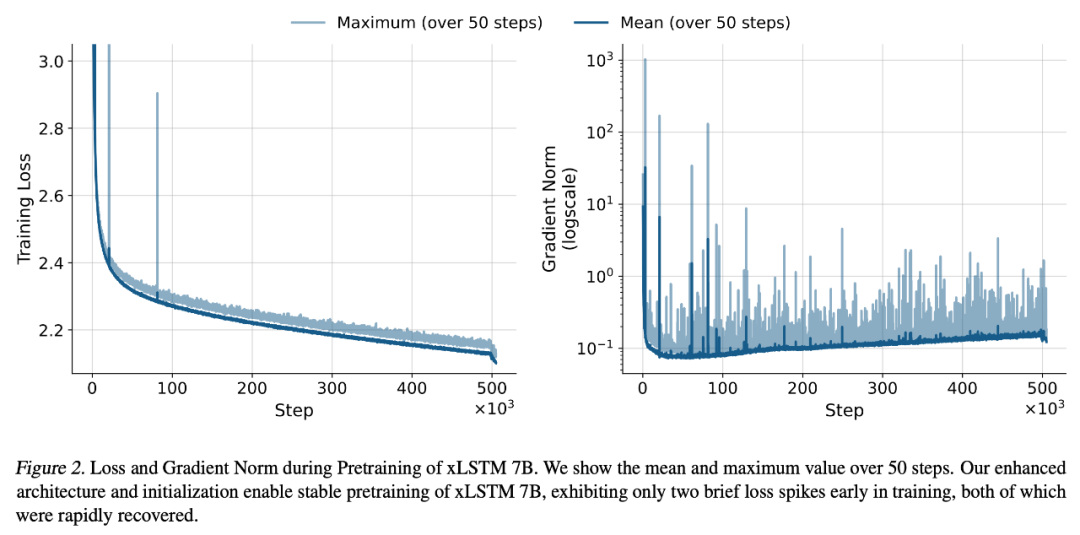
语言建模性能评估
Huggingface 排行榜
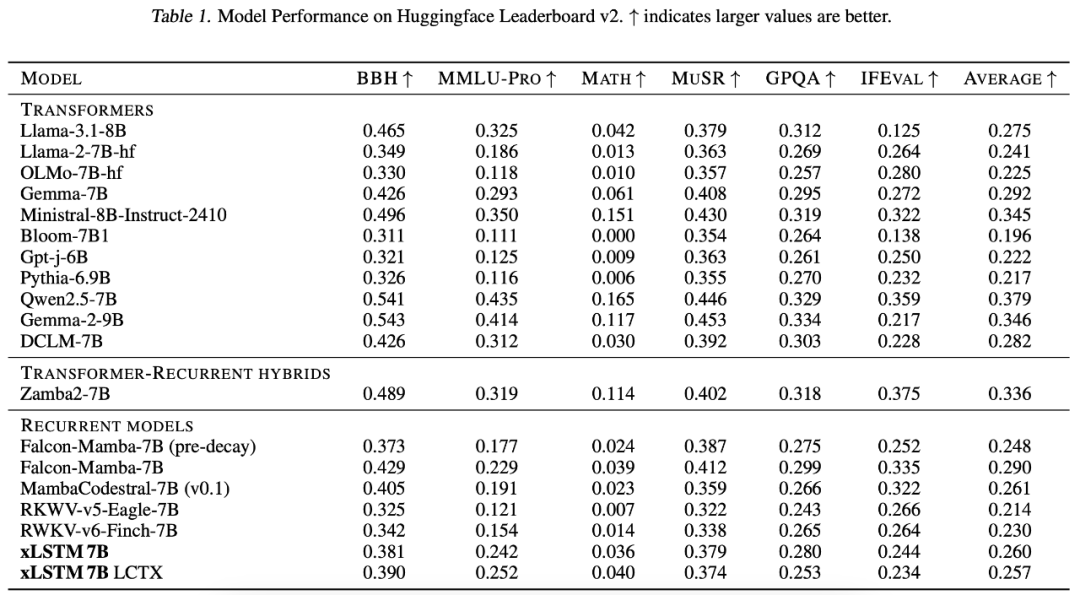
研究者首先在 7B 参数规模上,将 xLSTM 7B 与最先进的 Transformer 和循环神经网络(RNN)大语言模型进行了基准测试。
结果总结在下表 1 中,显示 xLSTM 7B 在 7B 规模模型中排名居中,其中一些表现更好的模型受益于更大规模的训练数据集。研究者认为,如果使用更大且更精心策划的训练数据集,尤其是在早期训练阶段更加注重数学和代码数据,xLSTM 7B 可能会达到最强 7B 模型的性能水平。
长文本评估与微调
研究者将 xLSTM 与几种基线模型进行了比较:作为 Transformer 基线的 Llama 2 7B(未进行长文本微调)和 Llama 3.1 8B(已进行长达 131K 词元的长文本微调),作为状态空间模型(State Space Model,SSM)基线的 CodestralMamba 和 FalconMamba,以及作为额外循环神经网络(Recurrent Neural Network,RNN)基线的 RWKV-5/6。
下表 3 展示了 RULER 评估结果。对于 xLSTM 7B,预训练中的长文本降温(cooling)阶段极大地提升了其长文本处理能力,使其性能与状态空间模型相当,并且优于 RWKV-5/6。
值得注意的是,长文本 xLSTM 7B 在 131K 上下文长度时实现了 20% 的平均准确率,尽管在降温阶段训练时仅使用了最多 32K 的上下文长度。这一点尤为显著,因为与具有不断增长的 KV 缓存(Key-Value cache)的 Transformer 不同,xLSTM 7B 必须在有限容量的固定大小内存中存储整个序列的信息(见表 3)。
速度基准测试
本研究主要关注本地单用户推理场景,这在模型部署到边缘设备时较为常见。除非另有说明,研究在单个英伟达 H100 GPU 上对批大小为 1 的 xLSTM 7B 模型进行生成式推理基准测试,并将其与 Llama 2 和 Llama 3 模型进行了比较。
生成吞吐量
如下图 4 所示,由于注意力机制随输入上下文长度呈二次方增长,Transformer 模型在较长预填充长度下的文本生成速度显著降低。
研究表明,xLSTM 7B 的文本生成速度比 Mamba 快约 50%,这主要得益于其优化的块设计。即使在预填充长度为 0 的情况下,xLSTM 7B 也比采用类似块设计的基于 Llama 的 Transformer 模型更快。

生成效率与内存消耗分析
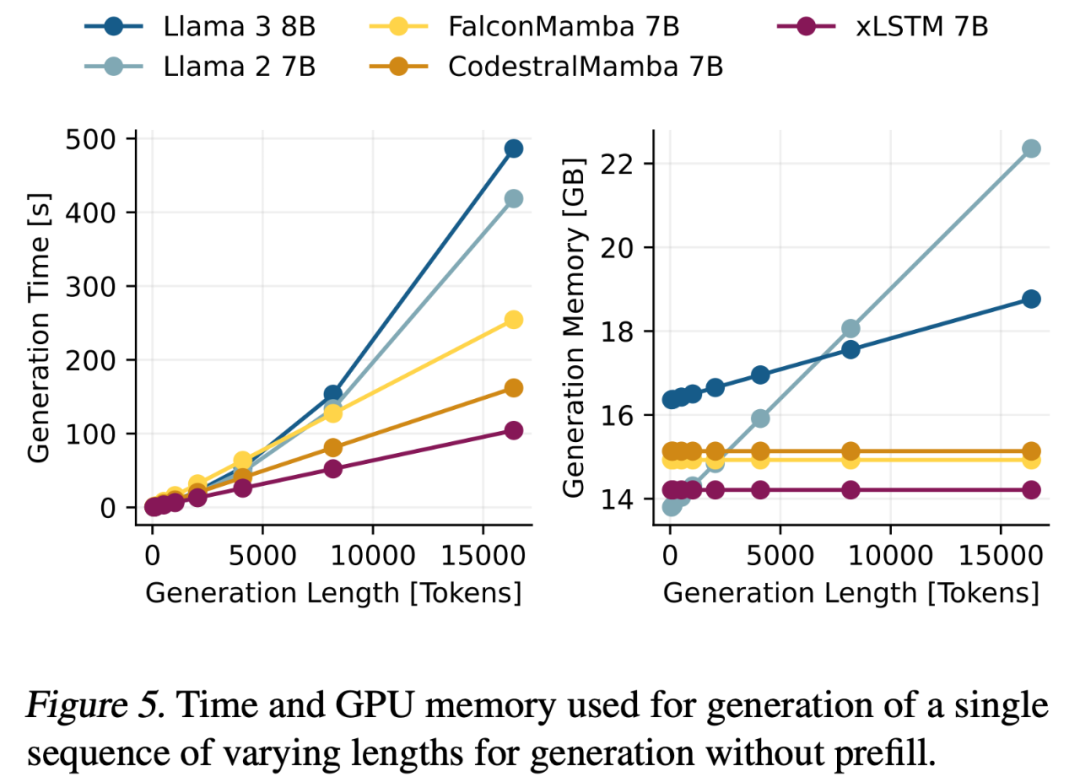
研究者测量了不同生成长度下的 token 生成时间和 GPU 内存使用情况(不包括预填充)。图 5(左)展示了循环模型在计算时间上呈线性增长,与 Transformer 呈二次方增长的对比;图 5(右)则显示了循环模型内存占用保持恒定,而 Transformer 的 KV 缓存随生成长度线性增长的对比。
得益于优化的模块设计,mLSTM 在低维空间中运行,使得 xLSTM 7B 模型与 Mamba 模型相比具有显著更低的内存占用(如下图 5 右侧所示)和更短的生成时间(如图 5 左侧所示)。
TTFT(Time To First Token)
在语言模型作为用户界面(可能在边缘设备上)的应用场景中,较短的响应时间至关重要。下图 6 展示了不同模型在处理各种长度的预填充(prefill)内容后,生成 1 个或 100 个 token 所需的响应时间或延迟。在所有预填充长度条件下,xLSTM 7B 模型均表现出最快的响应速度。

更多实验结果请参阅原论文。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com