北大团队从蒙特卡洛语言树视角解读GPT,发现大模型推理更可能是概率模式匹配,而非形式推理。思维链旨在帮助GPT模型更好地连接输入和输出。
原文标题:大模型推理更可能是概率模式匹配?北大团队从蒙特卡洛语言树的新视角解读GPT,思维链原理也有新的理解
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章提到了“token-bias”现象,即对输入token的细微扰动可能导致模型输出的巨大差异。你在使用大模型时遇到过类似的情况吗?你是如何解决的?
3、文章中提到,思维链(CoT)试图寻找路径Z来帮助GPT模型更好地连接X和Y。如果把大模型比作一个城市,CoT就像什么?
原文内容

本文经AI新媒体量子位(公众号ID:qbitai )授权转载,转载请联系出处本文约1500字,建议阅读5分钟
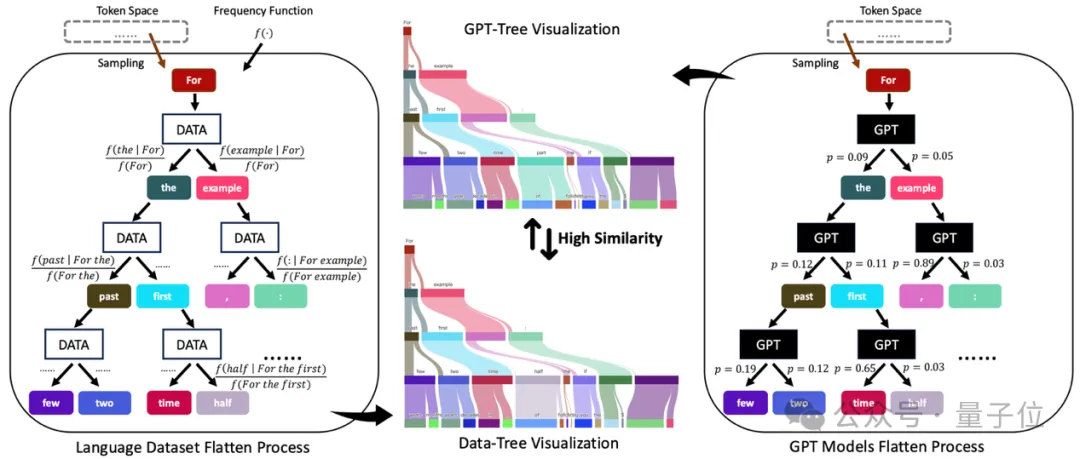
本文将语言数据集和GPT模型展开为蒙特卡洛语言树。
MLNLP社区是国内外知名的机器学习与自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企业研究人员。
社区的愿景是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流和进步,特别是初学者同学们的进步。
思维链(CoT)为什么能够提升大模型的表现?大模型又为什么会出现幻觉?
北大课题组的研究人员,发现了一个分析问题的新视角,将语言数据集和GPT模型展开为蒙特卡洛语言树。
具体来说,数据集和模型分别被展开成了Data-Tree 和GPT-Tree 。
结果,他们发现,现有的模型拟合训练数据的本质是在寻求一种更有效的数据树近似方法(即 )。
进一步地,研究人员认为,大模型中的推理过程,更可能是概率模式匹配,而不是形式推理。
将数据和模型拆解为蒙特卡洛树
在预训练过程中,大模型通常学习的是如何预测下一个token(也就是将每个token的似然进行最大化),从而对大规模数据进行无损压缩。
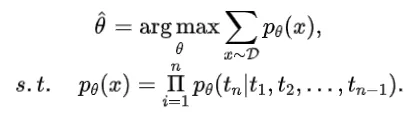
其中, 是优化上述似然得到的模型参数。
作者发现,任何语言数据集 都可以用蒙特卡洛语言树(简称“Data-Tree”)完美地表示,参数化为 。
具体来说,作者采样第一个token作为根节点(例如“For”),枚举其下一个token作为叶子节点(例如“the”或“example”),并计算条件频率( )作为边。
重复这一过程,就可以得到被语言数据集扁平化的“Data-Tree”。形式上,Data-Tree 满足以下条件:
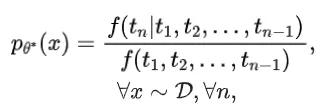
其中, 代表频率函数, 代表第 个token。作者从理论上证明了Data-Tree的 是上述最大似然的最优解。换句话说,最大化似然得到的模型参数 最终都在不断靠近 。
类似的,作者提出任意的类GPT模型也可以展开成另一颗蒙特卡洛语言树(简称“GPT-Tree”),参数化为 。
为了构建GPT-Tree,作者也从token空间采样第一个token 并将其输入到GPT,然后记录其第二个token 以及其概率分布![]() 。
。
接着,作者枚举所有的第二个token,并将 输入到GPT并得到第三个token 。
重复这一过程,就可以得到GPT展开后的“GPT-Tree”。
蒙特卡洛树视角下的新发现
在将数据和模型展开后,作者有了新的发现,并用新的视角解释了一些模型现象。
下图是对GPT-X系列模型和Data-Tree的树形可视化结果,其中每列代表不同token,每行代表不同的模型,最后一行代表Data-Tree。
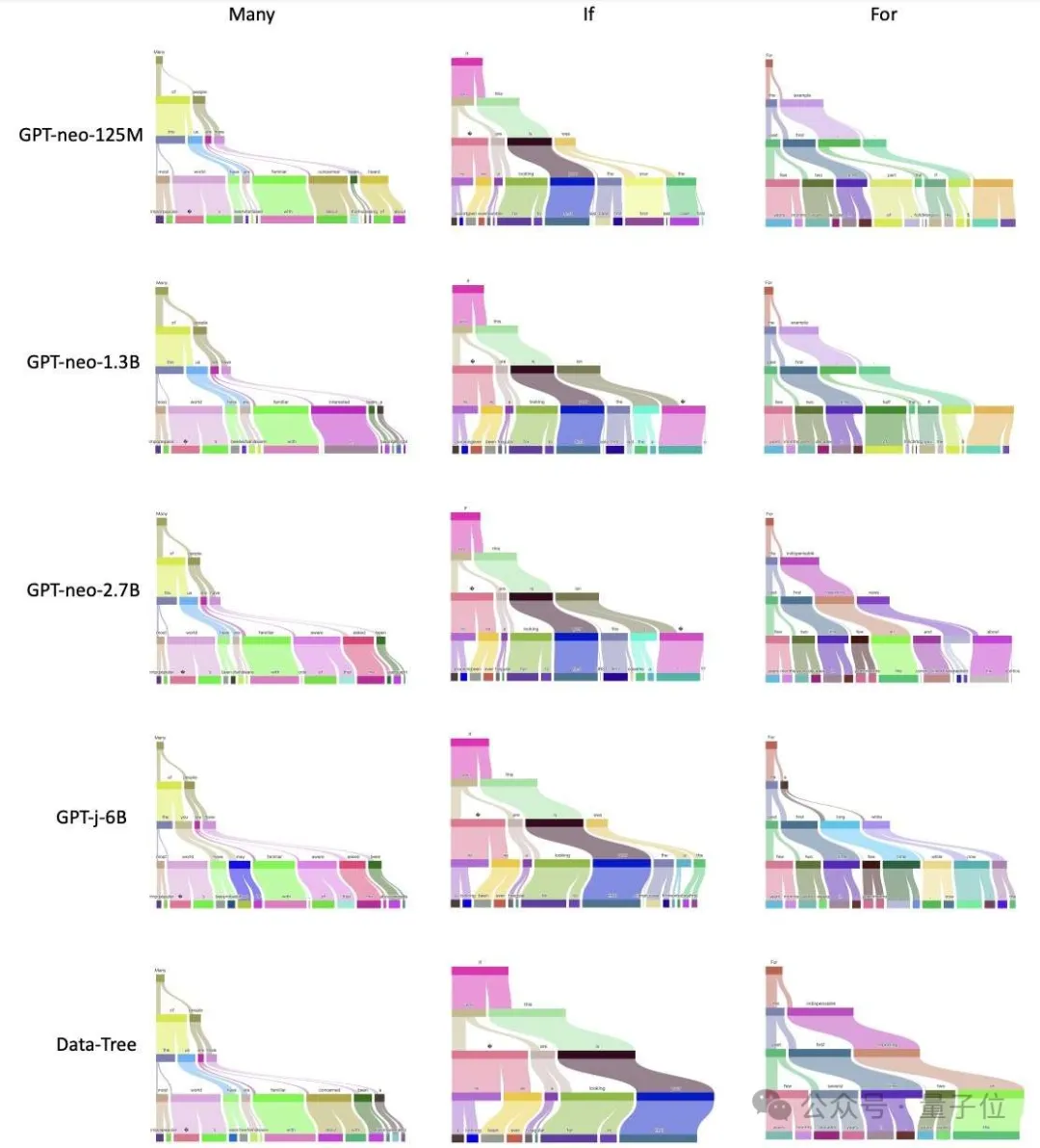
GPT模型逐渐收敛于数据树
作者发现,在同一数据集(the Pile)上训练的不同语言模型(GPT-neo-X系列模型)在GPT-Tree可视化中具有显著的结构相似性。
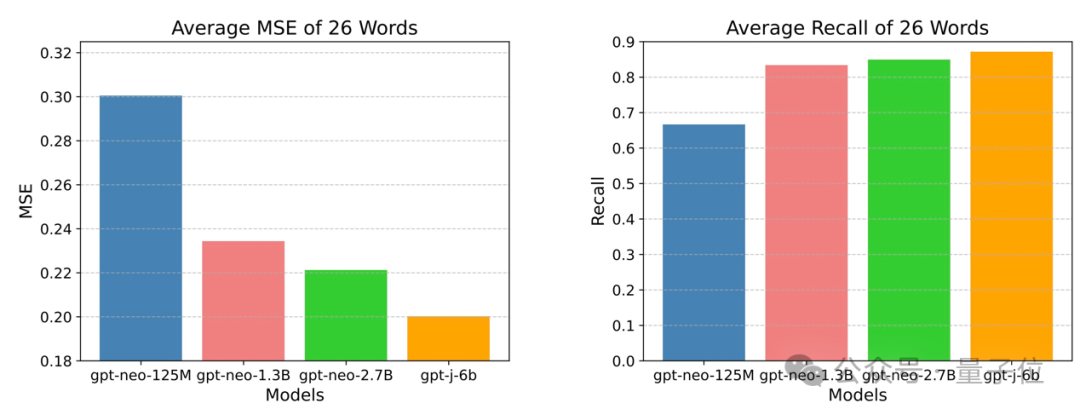
通过对这一结果进行进一步量化,作者发现,GPT模型越大,越接近 Data-Tree,超过87%的GPT输出token可以被Data-Tree召回。
这些结果表明,现有的语言模型本质上寻求一种更有效的方法来近似数据树,这可能证实了LLM的推理过程更可能是概率模式匹配而不是形式推理。
理解token-bias现象和模型幻觉
Token-bias现象首次发现于宾夕法尼亚大学Bowen Jiang等人的研究(arXiv:2406.11050),并被苹果公司的Iman Mirzadeh等人进行了进一步的研究(arXiv:2410.05229)。
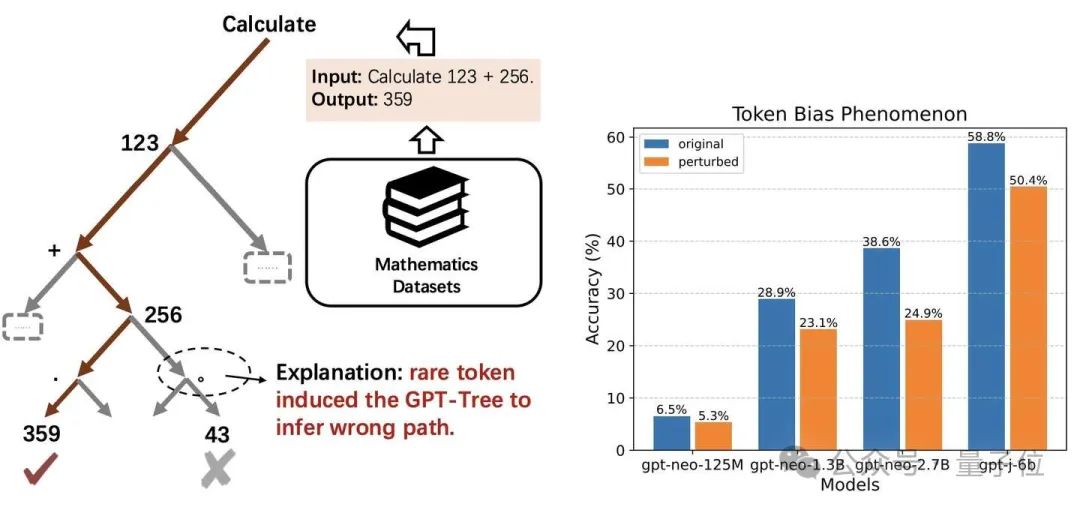
例如对于一个简单的数学计算问题,“Calculate 123 + 256.”,将最后一个 token“.”扰动成“。”,模型就会错误地回答为“43”。
作者认为,token-bias是由于一些罕见的token诱导GPT-Tree推断错误的路径。
作者通过评估21076对QA测试对中不同模型的原始(蓝色条)和扰动(橙色条)精度进一步量化了这一现象。
扰动最后一个token后,所有模型的准确性都显著下降。
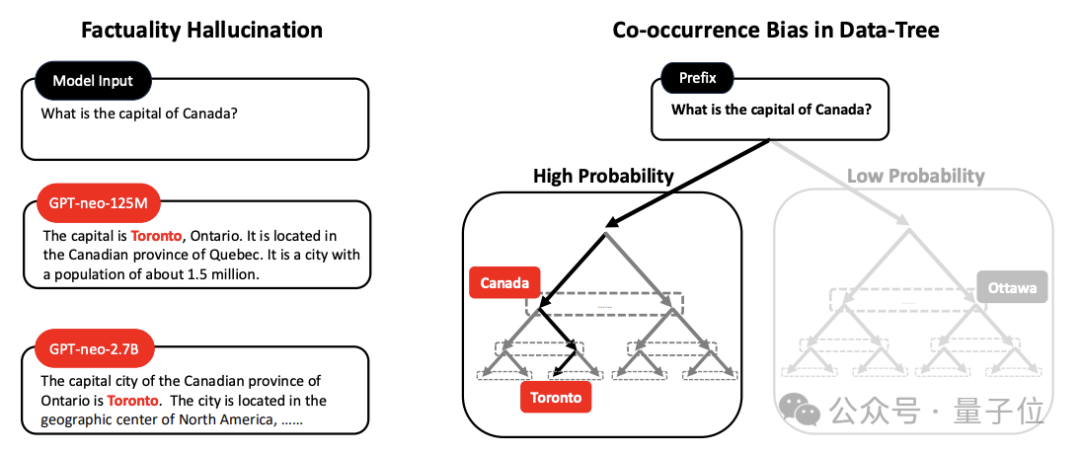
而至于模型幻觉,作者认为这是由数据树的共现偏差造成。
如下图所示,训练数据表现出多伦多和加拿大这两个术语的高频共现,导致模型严重倾向于这些语料库,从而错将多伦多认为是加拿大首都。
理解思维链的有效性
在蒙特卡洛树的视角下,思维链的有效性也有了新的解释。
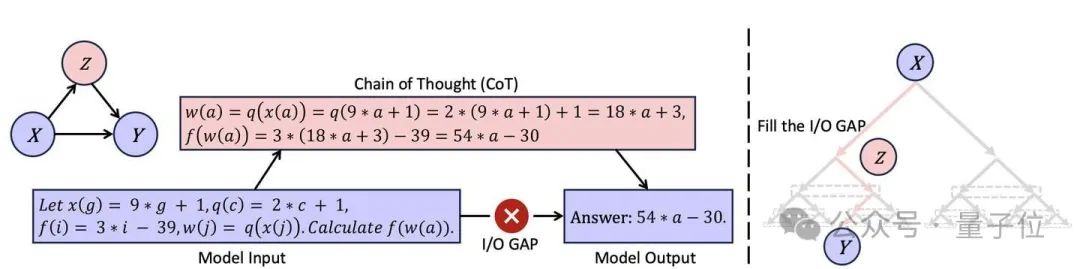
对于一些复杂的问题,输入X和输出Y之间存在明显的 Gap,使得GPT模型难以直接从X中输出Y。
从GPT-tree的视角来看,输入X位于父节点,输出Y位于比较深的叶节点。
思维链的原理就是试图弥补这一缺口,即试图寻找路径Z来帮助GPT模型更好的连接X和Y。
https://arxiv.org/abs/2501.07641
项目主页:
https://github.com/PKU-YuanGroup/GPT-as-Language-Tree
