本地运行Deep Research,保护隐私!AI研究助手,自动深度研究、追踪引用、集成多种搜索源,兼容PDF、Markdown等。
原文标题:本地也能运行Deep Research!支持arXiv平台,兼容PDF、Markdown等
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到了 RAG(检索增强生成)技术,这个技术在本地 Deep Research 中发挥了什么作用? 对于研究结果的准确性和可靠性有什么影响?
3、文章中提到了多种搜索引擎的集成,例如维基百科、arXiv、PubMed 等。 如果我想针对特定领域的知识进行研究,应该如何选择合适的搜索引擎,或者组合使用这些搜索引擎?
原文内容
机器之心报道
编辑:陈陈
今年年初,OpenAI 上线 Deep Research,开启了智能体又一新阶段,其能根据用户需求自主进行网络信息检索、整合多源信息、深度分析数据,并最终为用户提供全面深入的解答。
此后,Grok 3 及 Perplexity 等,它们都推出了类似的 Deep Research 服务。
其实,大家在惊叹 Deep Research 能力的同时,也会担心数据隐私等安全问题。
现在,可以本地运行的 Deep Research 来了!
我们可以将其看作一个强大的 AI 研究助手,它使用多个 LLM 和网络搜索进行深入的、迭代的分析。该系统可以本地运行,从而保护用户隐私,你也可以使用基于云的 LLM 以增强其功能。
目前项目已经收获 1.4k star 量。
项目地址:https://github.com/LearningCircuit/local-deep-research
该项目具有以下特点:
先进的研究功能:
-
能够自动进行深度研究,并在过程中提出智能的跟进问题,以确保全面理解和深入挖掘主题;
-
追踪引用来源,并验证其可靠性和准确性,确保信息的可信度;
-
通过多次迭代分析,该项目能够逐步完善研究内容,确保覆盖所有相关方面,避免遗漏重要信息;
-
分析整个网页的内容,而不仅仅是提取片段,从而提供更全面和准确的信息。
对 LLM 灵活支持:
-
支持在本地设备上运行 AI 模型(如 Ollama),确保数据处理的高效性和隐私性;
-
兼容云端大语言模型(如 Claude,GPT),从而提供更强大的计算能力和多样化的模型选择;
-
能够无缝集成和使用 Langchain 框架下的所有模型;
-
用户可以根据具体需求选择和配置不同的 AI 模型,以优化研究效果。
丰富的输出选项:
-
详细的研究结果,并附带引用来源;
-
生成内容详实、结构清晰的综合研究报告;
-
提供简洁的摘要,帮助用户快速抓住核心信息;
-
自动追踪信息来源并验证其可靠性。
增强的搜索集成:
-
自动选择搜索源:对于用户正在查询的内容,自动搜索引擎会进行智能分析,并根据查询内容选择最合适的搜索引擎;
-
集成了维基百科,方便快速获取准确的事实性知识和百科信息;
-
支持 arXiv 平台,便于检索和访问最新的科学论文和学术研究成果;
-
集成 PubMed,提供生物医学领域的最新文献和医学研究资源;
-
支持 DuckDuckGo 搜索引擎,提供隐私友好的网页搜索体验(但可能受到速率限制);
-
通过 SerpAPI 集成,可以获取 Google 搜索结果(需提供 API 密钥);
-
支持 Google 可编程搜索引擎,允许用户创建个性化的搜索体验(需提供 API 密钥);
-
集成 The Guardian(《卫报》),方便获取最新的新闻文章和深度报道(需提供 API 密钥);
-
支持通过本地 RAG 搜索对私有文档进行搜索,确保数据隐私;
-
能够抓取并分析整个网页的内容;
-
提供来源过滤和验证功能,确保搜索结果的可靠性和准确性;
-
用户可以根据需求自定义搜索参数,优化搜索体验。
本地文档搜索(RAG):
-
基于向量嵌入的本地文档搜索;
-
为不同主题创建自定义文档集合;
-
保护隐私,用户文档保留在自己的机器上;
-
智能分块和检索;
-
兼容多种文档格式(PDF、文本、Markdown 等);
-
自动与元搜索集成,实现统一查询。
该项目还包括一个 Web 界面(如下所示),以提供更加用户友好的体验:
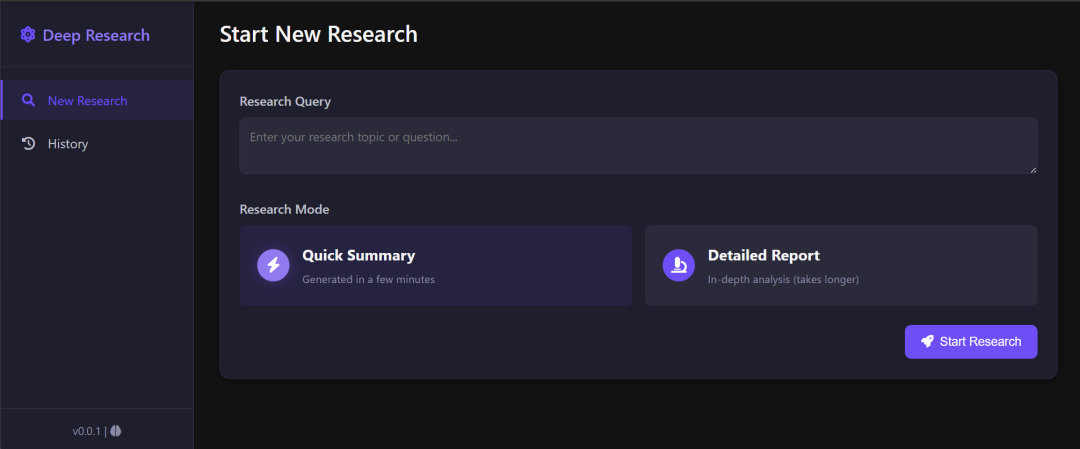
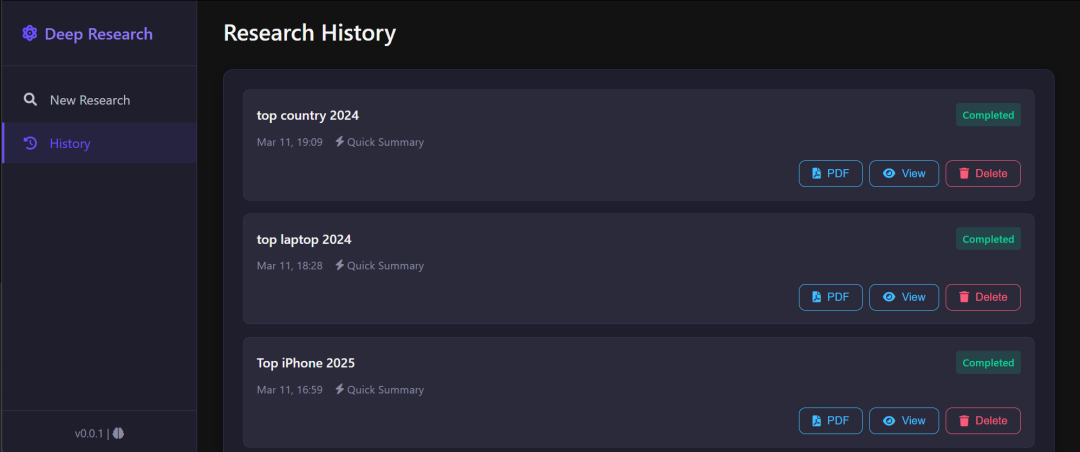
到底效果如何呢?我们以官方示例来说明,官方展示了一个关于核聚变能源发展的调查研究。
用户提问:核聚变能源研究的最新进展是什么?商业核聚变什么时候可行?
然后 Deep Research 输出了一篇可用的调查报告,内容非常详实:

报告部分截图
完整报告可参考:https://github.com/LearningCircuit/local-deep-research/blob/main/examples/fusion-energy-research-developments.md
通过这一示例,我们可以直观了解到该项目在深度研究、跨领域分析和信息整合方面的强大功能。
想要上手体验的小伙伴,可以跟着官方教程进行部署,打造属于自己的 Deep Research 了。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com