字节跳动与清华AIR开源DAPO算法,超越DeepSeek GRPO,提升LLM强化学习效率,Qwen2.5-32B模型在AIME 2024基准上取得了显著提升。
原文标题:超越DeepSeek GRPO的关键RL算法,字节、清华AIR开源DAPO
原文作者:机器之心
冷月清谈:
清华 AIR 和字节联合 SIA Lab 发布了名为 DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization,解耦剪辑和动态采样策略优化)的开源 SOTA 系统,旨在提升大规模 LLM 的强化学习效率。DAPO 算法成功地使 Qwen2.5-32B 模型在 AIME 2024 基准上获得了 50 分,超过了同等规模的 DeepSeek-R1-Zero-Qwen-32B,且训练步数减少了 50%。
该团队发现原生版 GRPO 存在熵崩溃、奖励噪音和训练不稳定等问题,并提出了多项改进措施。其中包括解耦剪辑(Clip-Higher)策略,通过分别设置较低和较高的剪辑范围来优化探索能力。动态采样通过过滤掉准确率为 1 或 0 的提示语,保留有效梯度,以解决梯度递减问题。此外,Token 级策略梯度损失和过长的奖励塑造也被引入,以提高训练的稳定性和性能。
实验结果表明,DAPO 算法在 AIME 2024 基准上表现出色,并且通过案例研究发现,Actor 模型的推理模式会随着时间的推移而动态演化,从而揭示了 RL 算法的适应性和探索能力。
该团队发现原生版 GRPO 存在熵崩溃、奖励噪音和训练不稳定等问题,并提出了多项改进措施。其中包括解耦剪辑(Clip-Higher)策略,通过分别设置较低和较高的剪辑范围来优化探索能力。动态采样通过过滤掉准确率为 1 或 0 的提示语,保留有效梯度,以解决梯度递减问题。此外,Token 级策略梯度损失和过长的奖励塑造也被引入,以提高训练的稳定性和性能。
实验结果表明,DAPO 算法在 AIME 2024 基准上表现出色,并且通过案例研究发现,Actor 模型的推理模式会随着时间的推移而动态演化,从而揭示了 RL 算法的适应性和探索能力。
怜星夜思:
1、DAPO 通过解耦剪辑和动态采样等技术改进了 GRPO,有效解决了熵崩溃等问题。那么,你认为除了这些技术手段,未来在提升 LLM 强化学习效率方面,还有哪些潜在的研究方向?
2、文章中提到,DAPO 在训练过程中Actor 模型的推理模式会随着时间的推移而动态演化。你认为这种演化是随机发生的,还是存在某种内在的规律?这种演化对我们理解 LLM 的智能涌现有什么启发?
3、DAPO 算法在数学问题上取得了不错的成果,但如果将其应用到其他领域,例如自然语言生成、对话系统等,你认为还需要做哪些调整或改进?
2、文章中提到,DAPO 在训练过程中Actor 模型的推理模式会随着时间的推移而动态演化。你认为这种演化是随机发生的,还是存在某种内在的规律?这种演化对我们理解 LLM 的智能涌现有什么启发?
3、DAPO 算法在数学问题上取得了不错的成果,但如果将其应用到其他领域,例如自然语言生成、对话系统等,你认为还需要做哪些调整或改进?
原文内容
机器之心报道
编辑:Panda、蛋酱
DeepSeek 提出的 GRPO 可以极大提升 LLM 的强化学习效率,不过其论文中似乎还缺少一些关键细节,让人难以复现出大规模和工业级的强化学习系统。
近日,清华 AIR 和字节联合 SIA Lab 发布了他们的第一项研究成果:DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。这是一个可实现大规模 LLM 强化学习的开源 SOTA 系统。此外,使用该算法训练的模型也将在近期开源发布。

-
项目页面:https://dapo-sia.github.io/
-
论文地址:https://dapo-sia.github.io/static/pdf/dapo_paper.pdf
-
代码地址:https://github.com/volcengine/verl/tree/gm-tyx/puffin/main/recipe/dapo
-
数据:https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k
使用该算法,该团队成功让 Qwen2.5-32B 模型在 AIME 2024 基准上获得了 50 分,优于同等规模的 DeepSeek-R1-Zero-Qwen-32B,同时 DAPO 版 Qwen2.5-32B 使用的训练步数还少 50%。

相较之下,如果使用 GRPO,Qwen2.5-32B 模型在 AIME 2024 基准上只能获得 30 分。
30 分的成绩远低于 DeepSeek 的强化学习(47 分)。该团队分析发现,原生版 GRPO 面临着几大关键问题,比如熵崩溃、奖励噪音和训练不稳定。事实上,该团队表示,很多研究团队在复现 DeepSeek 的结果时也遇到了类似的难题。他们表示:「这表明 R1 论文中可能省略了开发工业级、大规模且可重现的强化学习系统所需的关键训练细节。」

Allen AI 研究者 Nathan Lambert 总结了 DAPO 对 GRPO 的改进,包括两个不同的裁剪超参数、动态采样、token 层面的策略梯度损失、过长奖励塑造
下面将从 PPO 到 GRPO 再到 DAPO 逐步介绍,看看这个新的强化学习算法究竟是如何炼成的。
近端策略优化(PPO)
PPO 引入了裁剪式替代目标(clipped surrogate objective)来执行策略优化。通过使用裁剪将策略更新限制在先前策略的近端区域内,PPO 可以让训练稳定并提高样本效率。具体而言,PPO 更新策略的方式是最大化以下目标:

群组相对策略优化(GRPO)
与 PPO 相比,GRPO 消除了价值函数并以群组相关的方式来估计优势。对于特定的问答对 (q, a),行为策略 π_θ_old 采样一组 G 个个体响应 。然后,通过对群组级奖励
。然后,通过对群组级奖励 进行归一化来计算第 i 个响应的优势:
进行归一化来计算第 i 个响应的优势:
。然后,通过对群组级奖励
与 PPO 类似,GRPO 也采用了裁剪目标,同时还有一个直接添加的 KL 惩罚项:

还值得注意的是,GRPO 是在样本层级计算目标。确切地说,GRPO 首先会计算每个生成序列中的平均损失,然后再对不同样本的损失进行平均。正如后面会讨论的那样,这种差异可能会对算法的性能产生影响。
另外两项改进
消除 KL 偏离
KL 惩罚项的作用是调节在线策略和冻结参考策略之间的偏离情况。在 RLHF 场景中,RL 的目标是在不偏离初始模型太远的情况下调整模型行为。然而,在训练长 CoT 推理模型时,模型分布可能会与初始模型有显著差异,因此这种限制是不必要的。因此,在 DAPO 中,KL 项被排除在外。
基于规则的奖励建模
奖励模型的使用通常会受到奖励 hacking 问题的影响。作为替代,该团队直接使用可验证任务的最终准确率作为结果奖励,计算规则如下:

事实证明,这是激活基础模型推理能力的有效方法,这也在多个领域得到了证明,包括自动定理证明、计算机编程和数学竞赛。
DAPO

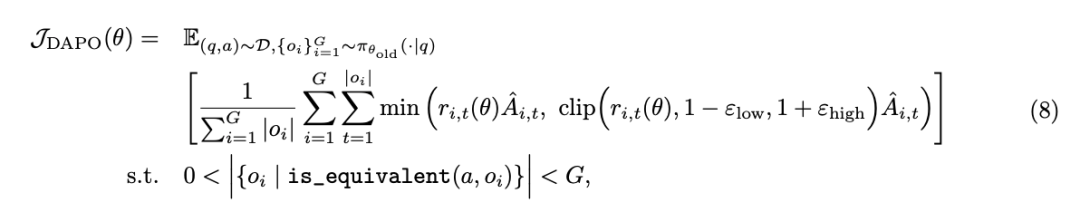
此处
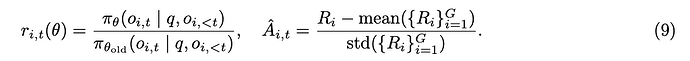
下面将介绍与 DAPO 相关的关键技术。
抬高天花板:Clip-Higher
在使用 PPO 或 GRPO 进行的初步实验中,研究者观察到了熵崩溃现象:随着训练的进行,策略的熵迅速下降(如图 2b)。某些组的采样响应通常几乎相同。这表明有限的探索和早期的确定性策略会阻碍扩展过程。

针对这一问题,研究者提出了 Clip-Higher 策略。对重要度采样率进行剪辑是 PPO-Clip 中的一种策略,用于限制信任区域并增强 RL 的稳定性。上剪辑可以限制策略的探索。在这种情况下,提高「利用 token」的概率要比提高不可能的「探索 token」的概率容易得多。


如公式 10 所示,根据 Clip-Higher 策略,研究者将较低和较高的剪辑范围解耦为 ε_low 和 ε_high:

研究者增加了 ε_high 的值,以便为低概率 token 的增加留出更多空间。如图 2 所示,这一调整有效地提高了策略的熵,有利于生成更多样化的样本。研究者选择将 ε_low 保持在相对较小的范围内,因为增大 ε_low 会将这些 token 的概率压制为 0,从而导致采样空间的崩溃。
越多越好:动态采样
当某些提示的准确度等于 1 时,现有的 RL 算法就会出现梯度递减问题。根据经验,准确率等于 1 的样本数量会继续增加,如图 3b 所示。这意味着每批样本中的有效提示次数会不断减少,从而导致梯度方差增大,抑制了模型训练的梯度信号。
为此,研究者建议进行过度采样,过滤掉等式 11 中所示精度等于 1 和 0 的提示语,保留批次中所有具有有效梯度的提示语,并保持一致的提示语数量。在训练之前不断采样,直到批次中全部都是准确率既不等于 0 也不等于 1 的样本。

另外一点发现如图 6 所示,在动态采样的情况下,实验能更快地实现相同的性能。

Rebalancing Act:Token 级策略梯度损失
研究者观察到,由于所有样本在损失计算中的权重相同,因此长回复中的 token 对总体损失的贡献可能会不成比例地降低,这可能会导致两种不利影响。
首先,对于高质量的长样本来说,这种影响会阻碍模型学习其中与推理相关的模式的能力。其次,过长的样本往往表现出低质量的模式,如胡言乱语和重复词语。
如图 4a 和图 4b 所示,样本级损失计算由于无法有效惩罚长样本中的不良模式,会导致熵和响应长度的不健康增长。

捉迷藏:过长的奖励塑造
为了研究奖励噪声的影响,研究者首先应用了超长过滤策略,以掩盖截断样本的损失。如图 5 所示,这种方法大大稳定了训练并提高了性能。

此外,他们还提出了「Soft Overlong Punishment」(等式 13),这是一种长度感知惩罚机制,旨在塑造截断样本的奖励。具体来说,当响应长度超过预定义的最大值时,研究者会定义一个惩罚区间。在这个区间内,响应越长,受到的惩罚就越大。这种惩罚会添加到基于规则的原始正确性奖励中,从而向模型发出信号,避免过长的响应。

DAPO 的实验表现
基于 Qwen-32B 基础模型,该团队进行了一系列实验,验证了新提出的 DAPO 算法的有效性和优势。这里我们略过实验细节,重点来看看实验结果。
整体来看,在 AIME 2024 上,使用 DAPO 训练的 Qwen-32B 模型成长为了一个强大的推理模型,性能优于使用 R1 方法训练的 Qwen2.5-32B。
如图 1 所示,可以看到 DAPO 训练的 Qwen2.5-32B 在 AIME 2024 基准上的性能提升情况。随着训练步数增长,模型准确度从 0% 稳步升至了 50%。需要重点指出:达成这一性能所使用的步数仅为 DeepSeek-R1-Zero-Qwen-32B 所需步数的一半。
表 1 展示了新方法中每种训练技术的贡献。看得出来,每种技术都对准确度的增长有所贡献。可以看到,原生 GRPO 只能让 Qwen2.5-32B 基础模型的准确度达到 30%。

至于 token 级损失,虽然它带来的性能提升较少,但该团队发现它可增强训练稳定性并使长度增加得更健康。
训练动态
为了获得更透彻的分析,该团队也分析了训练动态和中间结果。

生成响应的长度:该指标与训练稳定性和性能密切相关。如图 7a 所示。长度的增加可为模型提供更大的探索空间,允许采样更复杂的推理行为并通过训练逐渐强化。但需要注意的是,长度在训练过程中并不总是保持持续的上升趋势。在一些相当长的时期内,它可以停滞甚至下降。通常的做法是将长度与验证准确度结合起来作为评估实验是否正在恶化的指标。
训练过程中的奖励动态:这一直是强化学习中至关重要的监测指标之一,如图 7b 所示。在这里的大多数实验中,奖励增加的趋势相对稳定,不会因为实验设置的调整而出现大幅波动或下降。这表明,在给定可靠奖励信号的情况下,语言模型可以稳健地拟合训练集的分布。然而,该团队发现,在训练集上的最终奖励往往与在验证集上的准确度相关性不大,这表明对训练集存在过拟合现象。
Actor 模型的熵和生成概率:这与模型的探索能力有关,同时也是实验中密切监控的关键指标。直观地讲,模型的熵需要保持在适当的范围内。过低的熵表示概率分布过于尖锐,这会导致探索能力丧失。相反,过高的熵往往与过度探索的问题有关,例如乱码和重复生成。对于生成概率,情况恰恰相反。如前所示,通过应用 Clip-Higher 策略,可以有效地解决熵崩溃的问题。在后续的实验中,该团队还发现保持熵缓慢上升的趋势有利于模型提升性能,如图 7c 和图 7d 所示。
案例研究
在 RL 训练过程中,研究者观察到一个有趣的现象:Actor 模型的推理模式会随着时间的推移而动态演化。具体来说,算法不仅强化了有助于正确解决问题的现有推理模式,还逐渐产生了最初不存在的全新推理模式。这一发现揭示了 RL 算法的适应性和探索能力,并为模型的学习机制提供了新的见解。
例如,在模型训练的早期阶段,几乎不存在对之前推理步骤的检查和反思。然而,随着训练的进行,模型表现出明显的反思和回溯行为,如表 2 所示。这一观察结果为进一步探索解释推理能力在 RL 过程中的出现提供了启示。

更多研究细节,可参考原论文。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com