NVIDIA提出GEN3C,一种基于3D缓存引导的视频生成模型,实现精确相机控制和时间3D一致性,并在新视图合成中取得SOTA结果。项目地址:research.nvidia.com/labs/toronto-ai/GEN3C/
原文标题:【CVPR2025】GEN3C:基于3D信息的世界一致性视频生成与精确相机控制
原文作者:数据派THU
冷月清谈:
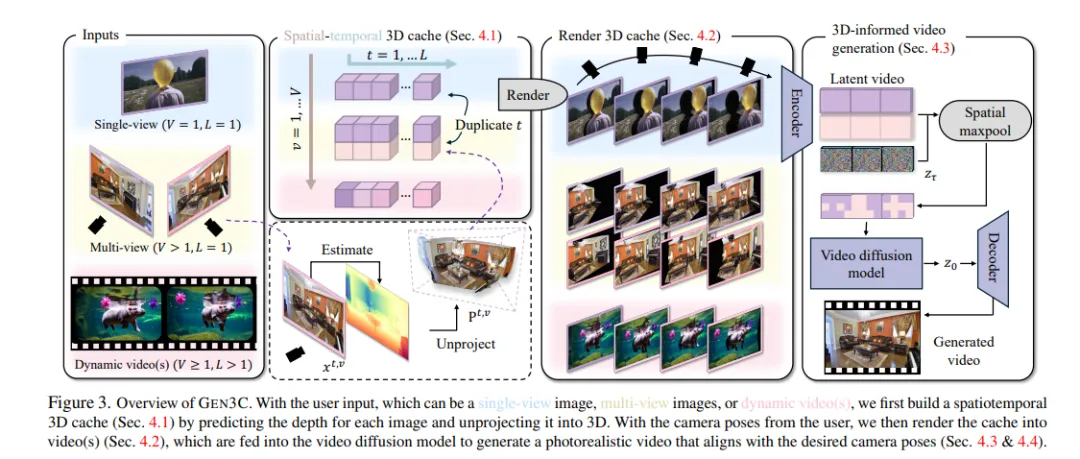
GEN3C是一种新型的生成视频模型,它通过利用3D缓存来引导视频生成,从而实现更精确的相机控制和时间3D一致性。与现有方法不同,GEN3C通过预测种子图像或先前生成帧的逐像素深度来获得点云,并在生成下一帧时,以用户提供的新相机轨迹对3D缓存的2D渲染进行条件生成。这种方法避免了模型记忆先前生成内容或从相机姿态推断图像结构的需求,从而能够更专注于生成先前未观察到的区域,并将场景状态推进到下一帧。实验结果表明,GEN3C在相机控制精度和稀疏视角新视图合成方面均优于现有技术,即使在驾驶场景和单目动态视频等复杂场景中也表现出色。
怜星夜思:
1、GEN3C通过3D缓存来引导视频生成,这个3D缓存具体是如何构建和更新的?它包含了哪些信息,又如何利用这些信息来提升视频生成质量和一致性的?
2、文章提到GEN3C在驾驶场景和单目动态视频等具有挑战性的设置中表现出色,那么它在哪些方面解决了这些场景的特殊难题?例如,如何处理驾驶场景中快速变化的视角和复杂的遮挡关系?单目视频中又如何解决深度信息的缺失问题?
3、GEN3C模型的核心创新点在于利用3D缓存进行引导,这种思路对未来的视频生成领域可能带来哪些影响?例如,是否可以应用于其他领域,如游戏开发、虚拟现实等?又可能面临哪些挑战和局限性?
2、文章提到GEN3C在驾驶场景和单目动态视频等具有挑战性的设置中表现出色,那么它在哪些方面解决了这些场景的特殊难题?例如,如何处理驾驶场景中快速变化的视角和复杂的遮挡关系?单目视频中又如何解决深度信息的缺失问题?
3、GEN3C模型的核心创新点在于利用3D缓存进行引导,这种思路对未来的视频生成领域可能带来哪些影响?例如,是否可以应用于其他领域,如游戏开发、虚拟现实等?又可能面临哪些挑战和局限性?
原文内容

来源:专知本文约1000字,建议阅读5分钟
我们的结果表明,与现有工作相比,GEN3C实现了更精确的相机控制,并在稀疏视角新视图合成中取得了最先进的结果,即使在驾驶场景和单目动态视频等具有挑战性的设置中也是如此。

我们提出了GEN3C,一种具有精确相机控制和时间3D一致性的生成视频模型。现有的视频模型已经能够生成逼真的视频,但它们往往利用较少的3D信息,导致不一致性,例如物体突然出现或消失。即使实现了相机控制,也不精确,因为相机参数仅仅是神经网络的输入,网络必须推断视频如何依赖于相机。相比之下,GEN3C通过3D缓存进行引导:通过预测种子图像或先前生成帧的逐像素深度获得的点云。在生成下一帧时,GEN3C以用户提供的新相机轨迹对3D缓存的2D渲染进行条件生成。
至关重要的是,这意味着GEN3C既不需要记住它先前生成的内容,也不需要从相机姿态推断图像结构。相反,模型可以将其生成能力集中在先前未观察到的区域,并将场景状态推进到下一帧。我们的结果表明,与现有工作相比,GEN3C实现了更精确的相机控制,并在稀疏视角新视图合成中取得了最先进的结果,即使在驾驶场景和单目动态视频等具有挑战性的设置中也是如此。最佳效果请观看视频。访问我们的网页:https://research.nvidia.com/labs/toronto-ai/GEN3C/。