本文介绍如何为LLM添加自定义token,以Llama 3.2为例,通过监督微调训练模型区分思考和回答过程,提升模型推理能力。
原文标题:LLM模型添加自定义Token代码示例:为Llama 3.2模型添加思考与回答标记(附代码)
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中使用的是SkunkworksAI/reasoning-0.01数据集。如果想要将这种方法应用到特定领域的LLM上,应该如何构建或选择更合适的数据集?
3、在将自定义Token添加到LLM后,文章采用的是SFT(Supervised Fine-Tuning)方法进行训练。大家认为除了SFT,还有哪些其他的训练方法可能更适合这种情况?
原文内容

来源:DeepHub IMBA本文约3600字,建议阅读7分钟
本文将介绍如何为大型语言模型(LLM)添加自定义token并进行训练,使模型能够有效地利用这些新增token。
本文将介绍如何为大型语言模型(LLM)添加自定义token并进行训练,使模型能够有效地利用这些新增token。以Llama 3.2模型为基础,实现了类似DeepSeek R1中think和answer标记功能的扩展方法,通过监督微调使模型学习使用这些标记进行推理过程与答案输出的区分。

本文聚焦于如何通过监督微调和标记示例训练模型使用新token,这类似于DeepSeek在其主要训练迭代前的"冷启动"训练阶段,不涉及RLHF或GRPO等强化学习训练方法。
环境配置
本文可以在A100 GPU的Google Colab环境中运行,但任何具备足够内存的GPU环境均可适用。我们将使用Llama-3.2-1B-instruct作为基础模型,这需要接受其服务条款并在环境中完成HuggingFace身份验证。理论上,本方法应与HuggingFace库中的大多数模型兼容。
硬件需求:约32GB GPU内存,Colab环境下运行时间约3小时。通过调整训练部分的超参数,可以适应较低GPU内存环境的需求,相关参数将在后文中详细说明。
依赖包安装
首先,安装所需的Python库:
!pip install --upgrade transformers bitsandbytes peft accelerate datasets trl
定义实验使用的模型,使用1B参数量的Llama 3.2模型进行实验。该技术同样适用于更大规模的模型,但可能需要更长的训练时间。
model_id = "meta-llama/Llama-3.2-1B-Instruct"
向Tokenizer添加自定义Token
首先加载并准备模型的tokenizer,同时定义必要的padding token和相关参数。
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained(model_id)定义padding token和相关参数
这些是训练器后续所需的配置
tokenizer.pad_token = “<|finetune_right_pad_id|>”
tokenizer.pad_token_id = 128004
tokenizer.padding_side = ‘right’
在添加新token前,先检查tokenizer如何处理我们计划用作自定义token的文本字符串,以便进行后续比较。我们将添加用于表示LLM输出中思考(think)和回答(answer)部分的token,总共4个token。
tokenizer("<think></think><answer></answer")
输出结果:
{'input_ids': [128000, 14023, 771, 1500, 27963, 1822, 9399, 1500, 9399], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
可以看到,默认情况下tokenizer使用了8个token来表示这些文本(不包括初始的begin text token [128000])。现在使用add_tokens方法添加自定义token:
tokenizer.add_tokens("<think>")
tokenizer.add_tokens("</think>")
tokenizer.add_tokens("<answer>")
tokenizer.add_tokens("</answer>")
验证新token的编码效果:
tokenizer("<think></think><answer></answer>")
输出结果:
{'input_ids': [128000, 128256, 128257, 128258, 128259], 'attention_mask': [1, 1, 1, 1, 1]}
可以观察到,tokenizer现在仅使用4个新token对相同文本进行编码。进一步验证解码过程:
tokenizer.decode([128256]),tokenizer.decode([128257]),tokenizer.decode([128258]),tokenizer.decode([128259])
输出结果:
(' <think>', '</think>', '<answer>', '</answer>')
验证成功,tokenizer已正确添加并处理新token的编码与解码。
加载和调整模型
虽然tokenizer已准备完毕,但模型尚未适配新token。如果直接传入新token,模型会因嵌入层缺少对应权重而报错。需要扩展模型以容纳新token,这可通过HuggingFace提供的内置函数实现,该函数会调整模型的token嵌入层大小,同时保留现有token权重。
from transformers import AutoModelForCausalLM, BitsAndBytesConfig import torch以全精度加载模型,不进行量化处理
model=AutoModelForCausalLM.from_pretrained(model_id, device_map=“auto”)
调整模型大小以匹配扩展后的tokenizer:
# 记录调整前的嵌入层和语言模型头部大小embedding_size = model.get_input_embeddings().weight.shape
print(f"Embedding layer size before resize: {embedding_size}“)
lm_head_size = model.lm_head.weight.shape
print(f"LM head size before resize: {lm_head_size}”)
print(“-”*10)调整token嵌入层大小以适应扩展后的tokenizer
此操作保留现有token的训练权重,仅为新token添加权重
model.resize_token_embeddings(len(tokenizer))
验证调整后的大小
embedding_size = model.get_input_embeddings().weight.shape
print(f"Embedding layer size after resize: {embedding_size}“)
lm_head_size = model.lm_head.weight.shape
print(f"LM head size after resize: {lm_head_size}”)
输出结果:
_Embedding layer size before resize: torch.Size([128256, 2048])
LM head size before resize: torch.Size([128256, 2048])
Embedding layer size after resize: torch.Size([128260, 2048]) LM head size after resize: torch.Size([128260, 2048])_
执行简单测试,确认模型在调整大小后仍能正常运行:
messages = [{"role": "user", "content": "Hello!"}]
tokens = tokenizer.apply_chat_template(messages, tokenize=True, return_tensors="pt")
tokens = tokens.to(model.device)
outputs = model.generate(tokens, max_new_tokens=100)
decoded_outputs = tokenizer.decode(outputs[0])
print(decoded_outputs)
部分输出内容:
< |eot_id|><|start_header_id|>user<|end_header_id|>
Hello! <|eot_id|><|start_header_id|>assistant<|end_header_id|>
Hello! How can I assist you today? <|eot_id|>
import torch
# 辅助函数:计算模型对特定token的预测概率
def get_token_probability(model, input_tokens, target_token):
with torch.no_grad():
outputs = model(input_tokens)
# 获取模型输出的logits
logits = outputs.logits[:, -1, :]
# 计算softmax概率
probs = torch.softmax(logits, dim=-1)
token_prob = probs[0, target_token]
return token_prob
# 测试函数:分析模型对think和answer token的预测概率
def print_think_answer_probabilibites_on_test():
question = "Why is the sky blue?"
messages = [{"role": "user", "content": question}]
tokens = tokenizer.apply_chat_template(messages, tokenize=True, return_tensors="pt")
tokens = tokens.to(model.device)
think_id = tokenizer.convert_tokens_to_ids("<think>")
think_prob = get_token_probability(model, tokens, think_id)
answer_id = tokenizer.convert_tokens_to_ids("<answer>")
answer_prob = get_token_probability(model, tokens, answer_id)
print(f"Probability of <think>: {think_prob:.6f}")
print(f"Probability of <answer>: {answer_prob:.6f}")
print_think_answer_probabilibites_on_test()
Probability of <think>: 0.000000 Probability of <answer>: 0.000000
import torch.nn as nn # 获取模型的输入嵌入层 embedding_layer = model.get_input_embeddings()选择参考token:使用start_header_id token
reference_token_id = tokenizer.convert_tokens_to_ids(“<|start_header_id|>”)
将参考token的嵌入权重复制到新token
for token in [“<think>”, “</think>”, “<answer>”, “</answer>”]:
token_id = tokenizer.convert_tokens_to_ids(token)
embedding_layer.weight.data[token_id] = embedding_layer.weight.data[reference_token_id].clone()再次测试新token的概率
print_think_answer_probabilibites_on_test()
Probability of <think>: 0.199994 Probability of <answer>: 0.199994
from datasets import load_dataset加载数据集,选择前10000个样本,按9:1比例划分训练集和测试集
data_set = load_dataset(“SkunkworksAI/reasoning-0.01”, split=‘train[:10000]’).train_test_split(test_size=.1)
数据处理函数:将样本格式化为包含think和answer标记的对话格式
def create_sample_conversation(row):
reasoning = row[‘reasoning’]
question = row[‘instruction’]
answer = row[‘output’]
assistant_response = “<think>%s</think><answer>%s</answer>”%(reasoning, answer)
messages = [
{“role”: “user”, “content”: question},
{“role”:“assistant”, “content”: assistant_response}
]
text = tokenizer.apply_chat_template(messages, tokenize=False)
return {“text”: text}并行处理训练集和测试集
import multiprocessing
data_set[‘train’] = data_set[‘train’].map(
create_sample_conversation,
num_proc= multiprocessing.cpu_count(),
load_from_cache_file=False
)
data_set[‘test’] = data_set[‘test’].map(
create_sample_conversation,
num_proc= multiprocessing.cpu_count(),
load_from_cache_file=False
)显示数据集信息
print(data_set[‘train’])
print(data_set[‘test’])
Dataset({ features: ['instruction', 'reasoning', 'output', 'reasoning_chains', 'text'], num_rows: 9000 }) Dataset({ features: ['instruction', 'reasoning', 'output', 'reasoning_chains', 'text'], num_rows: 1000 })
from trl import SFTConfig, SFTTrainer以下参数可根据GPU内存进行调整
减小批量大小可降低内存需求,但仍需足够空间存储模型和梯度
samples_per_training_step = 32
batch_size = 4
gradient_accumulation_steps = int(samples_per_training_step/batch_size)训练配置
training_arguments = SFTConfig(
output_dir=“./training_outputs”,
eval_strategy=“steps”,
do_eval=True,
optim=“adamw_8bit”,
per_device_train_batch_size=batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
per_device_eval_batch_size=batch_size,
log_level=“debug”,
save_strategy=“epoch”,
logging_steps=50,
learning_rate=1e-5,
eval_steps=50,
num_train_epochs=2,
warmup_ratio=0.1,
lr_scheduler_type=“linear”,
dataset_text_field=“text”,
max_seq_length=1024,
report_to=‘none’
)初始化训练器
trainer = SFTTrainer(
model=model,
train_dataset=data_set[‘train’],
eval_dataset=data_set[‘test’],
processing_class=tokenizer,
args=training_arguments
)
trainer.train()
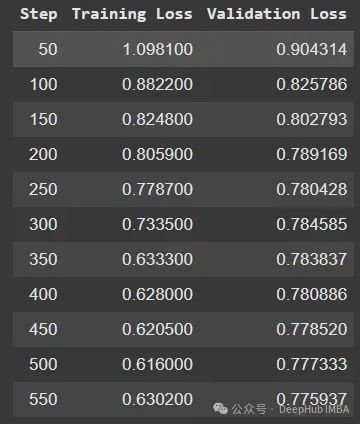
# 测量训练期间的最大GPU内存使用量
import torch
max_memory = torch.cuda.max_memory_allocated() / (1024 ** 3) # 将字节转换为GB
print(f"Max GPU memory used: {max_memory:.2f} GB")
Max GPU memory used: 31.03 GB
question = "Write a Python script to check if two string variables are anagrams or not."
messages = [{"role": "user", "content": question}]
tokens = trainer.tokenizer.apply_chat_template(messages, tokenize=True, return_tensors="pt")
tokens = tokens.to(model.device)
outputs = trainer.model.generate(tokens, max_new_tokens=1024)
new_tokens = outputs[0]
decoded_outputs = tokenizer.decode(new_tokens)
print(decoded_outputs)
# 保存模型和tokenizer
final_model_path = "./model/final_model"
final_model = trainer.model
final_tokenizer = trainer.tokenizer
final_model.save_pretrained(final_model_path)
final_tokenizer.save_pretrained(final_model_path)
# 加载保存的模型和tokenizer loaded_model = AutoModelForCausalLM.from_pretrained( final_model_path, device_map="auto" ) loaded_tokenizer = AutoTokenizer.from_pretrained(final_model_path)验证模型结构
print(f"Embedding layer size after resize: {loaded_model.get_input_embeddings().weight.shape}“)
print(f"LM head size after resize: {loaded_model.lm_head.weight.shape}”)
Embedding layer size after resize: torch.Size([128260, 2048]) LM head size after resize: torch.Size([128260, 2048])
# 使用加载的模型进行推理测试
question = "Write a Python script to check if two string variables are anagrams or not."
messages = [{"role": "user", "content": question}]
tokens = loaded_tokenizer.apply_chat_template(messages, tokenize=True, return_tensors="pt")
tokens = tokens.to(loaded_model.device)
outputs = loaded_model.generate(tokens, max_new_tokens=1024)
new_tokens = outputs[0][tokens.shape[-1]:]
decoded_outputs = loaded_tokenizer.decode(new_tokens)
print(decoded_outputs)
代码:
https://drive.google.com/file/d/1MqfuxScqcBrHvBzV-aYlbq99t8f4zYpc/view?usp=drive_link
