川大提出TCR,一种新的跨模态检索TTA范式,通过调整模态内分布和模态间差异,有效应对查询偏移带来的挑战,已被ICLR 2025接收。
原文标题:ICLR 2025 | 四川大学提出Test-time Adaptation新范式,突破查询偏移挑战
原文作者:机器之心
冷月清谈:
四川大学XLearning团队提出了一种新的Test-time Adaptation(TTA)范式TCR,用于解决跨模态检索中因查询偏移导致的性能下降问题。该研究揭示了查询偏移对模态内均匀性和模态间差异的负面影响,并提出了相应的解决方案,包括模态内分布约束、模态间差异约束和噪声鲁棒学习。通过调整模态内分布、模态间差异以及缓解检索过程中的高噪声现象,TCR实现了查询偏移下的鲁棒跨模态检索。此外,该研究还建立了统一的跨模态检索TTA基准,涵盖多个数据集和模态损坏场景,为后续研究提供了实验观察和评估体系。
怜星夜思:
1、文章中提到TCR通过调整模态内均匀性和模态间差异来提升检索性能。大家觉得在实际应用中,这两个因素哪个更重要,或者说哪个更难优化?为什么?
2、文章中提出了噪声鲁棒学习来解决检索任务中的高噪声问题。除了文中提到的方法,大家还有什么其他思路可以降低跨模态检索中的噪声影响吗?
3、文章提到TTA有望在更复杂的跨模态场景(如VQA等)中发挥关键作用。你认为TTA在VQA任务中会面临哪些新的挑战?
2、文章中提出了噪声鲁棒学习来解决检索任务中的高噪声问题。除了文中提到的方法,大家还有什么其他思路可以降低跨模态检索中的噪声影响吗?
3、文章提到TTA有望在更复杂的跨模态场景(如VQA等)中发挥关键作用。你认为TTA在VQA任务中会面临哪些新的挑战?
原文内容

在 NeurIPS 2024 大会上,OpenAI 联合创始人兼前首席科学家 Ilya Sutskever 在其主题报告中展望了基础模型的未来研究方向,其中包括了 Inference Time Compute [1],即增强模型在推理阶段的能力,这也是 OpenAI o1 和 o3 等核心项目的关键技术路径。
作为 Inference Time Compute 的重要方向之一,Test-time Adaptation(TTA)旨在使预训练模型动态适应推理阶段中不同分布类型的数据,能够有效提高神经网络模型的分布外泛化能力。
然而,当前 TTA 的应用场景仍存在较大局限性,主要集中在单模态任务中,如识别、分割等领域。
近日,四川大学 XLearning 团队将 TTA 拓展至跨模态检索任务中,有效缓解了查询偏移(Query Shift)挑战的负面影响,有望推动 Inference time compute 向跨模态应用发展。
目前,该论文已被机器学习国际顶会 ICLR 2025 接收并评选为 Spotlight(入选比例 5.1%)。

-
论文题目:Test-time Adaptation for Cross-modal Retrieval with Query Shift
-
论文地址:https://openreview.net/forum?id=BmG88rONaU
-
项目地址:https://hbinli.github.io/TCR/
背景与挑战
跨模态检索旨在通过构建多模态共同空间来关联不同模态的数据,在搜索引擎、推荐系统等领域具有重要的应用价值。如图 1 (a) 所示,现有方法通常基于预训练模型来构建共同空间,并假设推理阶段的查询数据与训练数据分布一致。然而,如图 1 (b) 所示,在现实场景中,用户的查询往往具有高度个性化的特点,甚至可能涉及不常见的需求,导致查询偏移(Query Shift)挑战,即模型推理时查询数据与源域数据的分布显著不同。

图 1:(a) 主流范式:利用预训练模型 Zero-shot 检索或者 Fine-tune 后检索。(b) 导致查询偏移的原因:难以对数据稀缺的领域进行微调;即使微调模型,也会面临 “众口难调” 的问题。(c) 观察:查询偏移会降低模态内的均匀性和增大模态间的差异。
如图 1 (c) 所示,本文观察到,查询偏移不仅会破坏查询模态的均匀性(Modality Uniformity),使得模型难以区分多样化的查询,还会增大查询模态与候选模态间的差异(Modality Gap),破坏预训练模型构建的跨模态对齐关系。这两点都会导致预训练模型在推理阶段的性能急剧下降。
尽管 TTA 作为能够实时应对分布偏移的范式已取得显著成功,但现有方法仍无法有效应对查询偏移挑战。一方面,当前 TTA 范式面向单模态任务设计,无法有效应对查询偏移对模态内分布和模态间对齐关系的影响。另一方面,现有 TTA 方法主要应用于识别任务,无法应对检索任务中的高噪声现象,即候选项远大于类别数量会导致更大的错误几率。
主要贡献
针对上述挑战,本文提出了 TCR,贡献如下:
-
从模态内分布和模态间差异两个层面,揭示了查询偏移导致检索性能下降的根本原因。
-
将 TTA 范式扩展至跨模态检索领域,通过调整模态内分布、模态间差异以及缓解检索过程中的高噪声现象,实现查询偏移下的鲁棒跨模态检索。
-
为跨模态检索 TTA 建立了统一的基准,涵盖 6 个广泛应用的数据集和 130 种风格各异、程度不同的模态损坏场景,支持包括 BLIP [2]、CLIP [3] 等主流预训练模型。
观察与方法
本文通过一系列的分析实验和方法设计,深入探究了查询偏移对公共空间的负面影响以及造成的高噪声现象,具体如下:

图 2:TCR 的框架图
1)挑战一:查询偏移对模态内和模态间的负面影响
为了进一步探究查询偏移对公共空间的负面影响,本文以一种 Untrain 的方式进行量化实验,即对推理阶段的数据特征如下变换:

其中,Q 和 G 分别代表查询模态与候选模态, 代表查询模态的第 i 个样本,
代表查询模态的第 i 个样本, 和
和 分别代表查询模态的样本中心。换句话说,通过放缩样本离中心的距离,调整模态内分布的均匀性;通过对查询模态的样本进行位移,控制两个模态之间的差异。实验结论如下:
分别代表查询模态的样本中心。换句话说,通过放缩样本离中心的距离,调整模态内分布的均匀性;通过对查询模态的样本进行位移,控制两个模态之间的差异。实验结论如下:
如图 3(a),当增大模态内均匀性( )和降低模态间差异(
)和降低模态间差异( )时,检索性能有所提升,反之不然。正如 [4] 中讨论的,过度消除模态间差异不会改善甚至会降低模型性能。本文进一步观察到当降低模态间差异至源域的 Modality Gap 附近时,能够借助预训练模型构建的良好跨模态关系,保障模型性能。
)时,检索性能有所提升,反之不然。正如 [4] 中讨论的,过度消除模态间差异不会改善甚至会降低模型性能。本文进一步观察到当降低模态间差异至源域的 Modality Gap 附近时,能够借助预训练模型构建的良好跨模态关系,保障模型性能。

图 3:模态内均匀性与模态间差异的观察
基于上述观察,本文提出了如下损失:
模态内分布约束。让当前查询远离查询模态的样本中心,从而显式增大模态内均匀性:

其中,B代表当前批次。
模态间差异约束。对齐目标域和源域的模态间差异:
其中, 代表推理时的模态间差异,
代表推理时的模态间差异, 代表预估的源域模态间差异。
代表预估的源域模态间差异。
代表推理时的模态间差异,
如图 4 所示,本文提出的 TCR 不仅增大了模态内均匀性,而且降低了模态间差异,进而提升了跨模态检索性能。
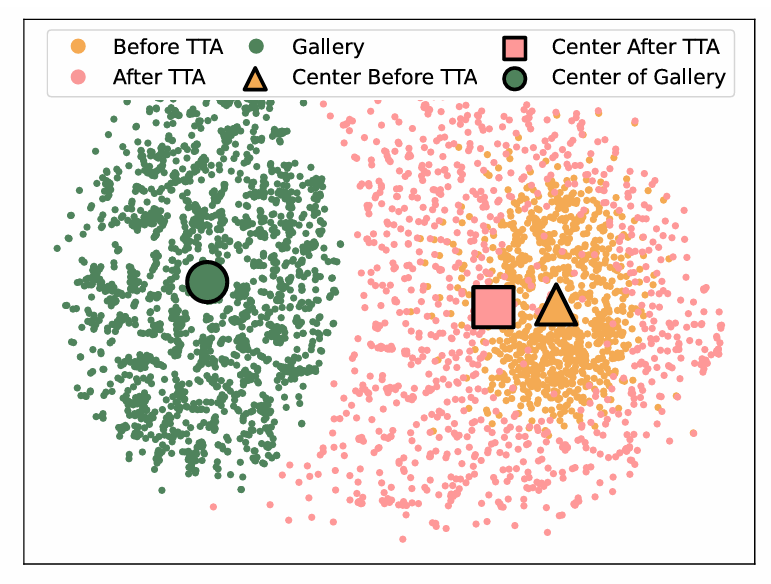
图 4:TTA 前后的特征分布
2)挑战二:查询偏移造成的高噪声现象
过去的 TTA 方法依赖熵最小化范式,且主要应用于分类任务。尽管可以通过将检索视为分类任务,进而使用熵最小化,但检索任务中候选项远大于类别的数量,直接应用该范式会导致模型欠拟合。针对此,本文提出查询预测优化如下:

其中, 代表最近邻筛选操作。该模块不仅能够排除不相关的候选项,而且排除的候选项能够避免对正确候选的大海捞针,从而避免模型欠拟合。如图 5 所示,使用查询预测优化(Ref.)能够显著提升 TTA 的稳定性。
代表最近邻筛选操作。该模块不仅能够排除不相关的候选项,而且排除的候选项能够避免对正确候选的大海捞针,从而避免模型欠拟合。如图 5 所示,使用查询预测优化(Ref.)能够显著提升 TTA 的稳定性。

图 5:温度系数的消融实验
尽管上述优化缓解了欠拟合现象,但是查询偏移仍然会导致大量的噪声预测。针对此,本文提出噪声鲁棒学习:

其中, 代表查询预测的熵,
代表查询预测的熵, 代表自适应阈值。噪声鲁棒学习不仅通过自适应阈值来过滤高熵的预测,还为低熵的预测分配更高的权重,进而实现对噪声预测的鲁棒性。
代表自适应阈值。噪声鲁棒学习不仅通过自适应阈值来过滤高熵的预测,还为低熵的预测分配更高的权重,进而实现对噪声预测的鲁棒性。
基准与实验
为了更好地研究查询偏移对跨模态检索任务的影响,本文提出以下两中评估方法:
-
仅查询偏移:只有查询模态的分布与源域数据不同。依据 [5],在 COCO [6] 和 Flickr [7] 数据集上分别引入了 16 种图像损坏和 15 种文本损坏(按照不同严重程度共计 130 种损坏)。为了保证仅查询偏移,先让模型在对应数据集上进行微调,随后将微调后的模型应用于仅有查询偏移的推理数据集中。
-
查询 - 候选偏移:查询模态和候选模态的分布都与源域数据不同。为了保证查询 - 候选偏移,本文直接将预训练模型应用于各领域的推理数据中,包括电商领域的 Fashion-Gen [8]、ReID 领域的 CUHK-PEDES [9] 和 ICFG-PEDES [10]、自然图像领域的 Nocaps [11] 等。
部分实验结果如下:
1)仅查询偏移

表 1:仅查询偏移下的性能比较
2)查询 - 候选偏移


表 3、4:查询 - 候选偏移下的性能比较
总结与展望
本文提出的 TCR 从模态内分布和模态间差异两个层面揭示了查询偏移对跨模态检索性能的负面影响,并进一步构建了跨模态检索 TTA 基准,为后续研究提供了实验观察和评估体系。
展望未来,随着基础模型的快速发展,TTA 有望在更复杂的跨模态场景(如 VQA 等)中发挥关键作用,推动基础模型从 "静态预训练" 迈向 "推理自适应" 的发展。
参考文献:
[1] Wojciech Zaremba, Evgenia Nitishinskaya, Boaz Barak, Stephanie Lin, Sam Toyer, Yaodong Yu, Rachel Dias, Eric Wallace, Kai Xiao, Johannes Heidecke, et al. Trading inference-time compute for adversarial robustness. arXiv preprint arXiv:2501.18841, 2025.
[2] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pretraining for unified vision-language understanding and generation. In ICML, 2022.
[3] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021.
[4] Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. In NeurIPS, 2022.
[5] Jielin Qiu, Yi Zhu, Xingjian Shi, Florian Wenzel, Zhiqiang Tang, Ding Zhao, Bo Li, and Mu Li. Benchmarking robustness of multimodal image-text models under distribution shift. Journal of Data-centric Machine Learning Research, 2023.
[6] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ´ ECCV, 2014.
[7] Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer imageto-sentence models. In ICCV, 2015.
[8] Negar Rostamzadeh, Seyedarian Hosseini, Thomas Boquet, Wojciech Stokowiec, Ying Zhang, Christian Jauvin, and Chris Pal. Fashion-gen: The generative fashion dataset and challenge. arXiv preprint arXiv:1806.08317, 2018.
[9] Shuang Li, Tong Xiao, Hongsheng Li, Bolei Zhou, Dayu Yue, and Xiaogang Wang. Person search with natural language description. In CVPR, 2017.
[10] Zefeng Ding, Changxing Ding, Zhiyin Shao, and Dacheng Tao. Semantically self-aligned network for text-to-image part-aware person re-identification. arXiv:2107.12666, 2021.
[11] Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. Nocaps: Novel object captioning at scale. In CVPR, 2019.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com