百度发布文心大模型X1和4.5,X1主打深度思考与工具调用,4.5侧重多模态能力,海外热议其性能与价格优势。
原文标题:海外热议!百度双模型免费上线,实测可帮没看“3.15”的打工人避雷
原文作者:AI前线
冷月清谈:
怜星夜思:
2、文心大模型4.5在多模态理解和生成方面表现出色,但多模态是否真的就比单模态更具有优势?在特定场景下,是否单模态模型也能达到甚至超越多模态模型的效果?
3、文章提到百度在中文互联网的数据优势是文心大模型的一大优势,那么这种优势是否意味着其他语言的大模型在中文理解方面会天然劣势?如果想弥补这种劣势,除了增加中文数据外,还有哪些可能的方案?
原文内容

在中国 AI 大模型热闹了一整个春节后, 百度又给出了大动作。
3 月 16 日上午,百度连续发布了文心大模型 X1 和文心大模型 4.5,不仅能力再进阶,价格也更低。文心 X1 并非单纯的深度思考模型,能自主调用工具,还具备多模态能力,其核心在于专家级的规划、分析能力;而文心大模型 4.5 则更多强调原生多模态能力,尤其是视觉理解能力。
发布后仅仅半天,文心大模型 X1 和文心大模型 4.5 就在海外引起了热议。
硅谷著名科技投资人 Bill Gurley 直言,美国人工智能公司应将 100% 的时间用于开发和创新,而不是在华盛顿特区游说寻求保护以躲避竞争。这种情况很糟糕,明显暴露出缺乏自信。
前微软、Rackspace 员工,同时也是知名美国科技作家的 Robert Scoble 则对价格表示了震惊:“(文心大模型 4.5 及 X1)价格是 DeepSeek 的 R1 的一半。我们有一场 Al 价格战!”
彭博社研究员 Steve Hou 表示,“文心大模型 X1 的性能与 DeepSeek-R1 相当,但价格仅为后者的一半”。这就像太阳能板之于 AI 模型一样。中国不断进取,永无止境。
海外知名科技博主 Bishal Nandi 也表示,“百度刚刚推出了文心大模型 4.5 和文心大模型 X1。文心大模型 4.5 的表现优于 GPT-4o,而文心大模型直接挑战 DeepSeek R1。最棒的是,这两个模型都是免费的。”
海外的网友们更是急的不行,跪求账号和跪求文心一言官网“汉化”的围观群众比比皆是。
不过,国内用户并不存在这个问题,目前两大新模型均已上线文心一言官网,向所有用户免费开放。
同时,文心大模型 4.5 已上线百度智能云千帆大模型平台,企业用户和开发者登录即可调用 API;文心大模型 X1 也即将在千帆上线。百度搜索、文小言 APP 等产品以后也将陆续接入文心大模型 4.5 和文心大模型 X1。
推理模型 + 多模态模型,对于百度而言是不是 1+1 > 2?InfoQ 在第一时间,围绕几个核心场景对这两个大模型展开了测试。
文心大模型 X1 是本次外界对百度期待的重点。百度也确实没有让这种期待打折扣——文心大模型 X1 不是简单增加了 CoT 思维链,而是设计了理解、规划、反思、进化能力,并支持多模态,百度官方口径表示:这是首个自主运用工具的深度思考模型。
在实际测试中,我们发现,文心 X1 非常重视中文语境和亚文化的特别表述,一如既往地有着百度对中文语料的特别理解和积累,因此在中文知识问答、文学创作、文稿写作、日常对话、逻辑推理、复杂计算及工具调用等方面表现尤为出色。
文心 X1 的另一个特别标签,在于其能自主运用工具,在设计理念上,和当下流行的 AI Agents 形态有很多共通的地方,某种程度上也是百度千帆生态的延续。文心大模型 X1 支持调用的工具有:高级搜索、文档问答、图片理解、AI 绘图、代码解释器、网页链接读取、TreeMind 树图、百度学术检索、商业信息查询、加盟信息查询等。
理论上,这使得文心 X1 应用于实际生产环境的体验更好。在大模型领域,百度的 RAG 技术一直比较成熟,此次也深度集成在了文心 X1 中, 使得文心 X1 能快速全面地分析实时热点事件,并降低幻觉率,效果比肩 DeepSeek-R1。
作为国产大模型的又一突破,文心 X1 同样在成本层面做足了文章。飞桨和文心联合对文心 X1 进行优化,据官方数据,文心 X1 的成本大概只有 DeepSeek-R1 的一半。
具体来说,在模型压缩方面,文心 X1 通过分块 Hadamard 量化、面向长序列的注意力机制量化等实现了深度压缩;在推理引擎方面,文心 X1 通过低精度高性能算子优化、动态自适应投机解码、神经网络编译器实现推理加速。系统层面,则通过框架和芯片协同优化、分离式部署架构、高效资源调度实现了系统级优化。
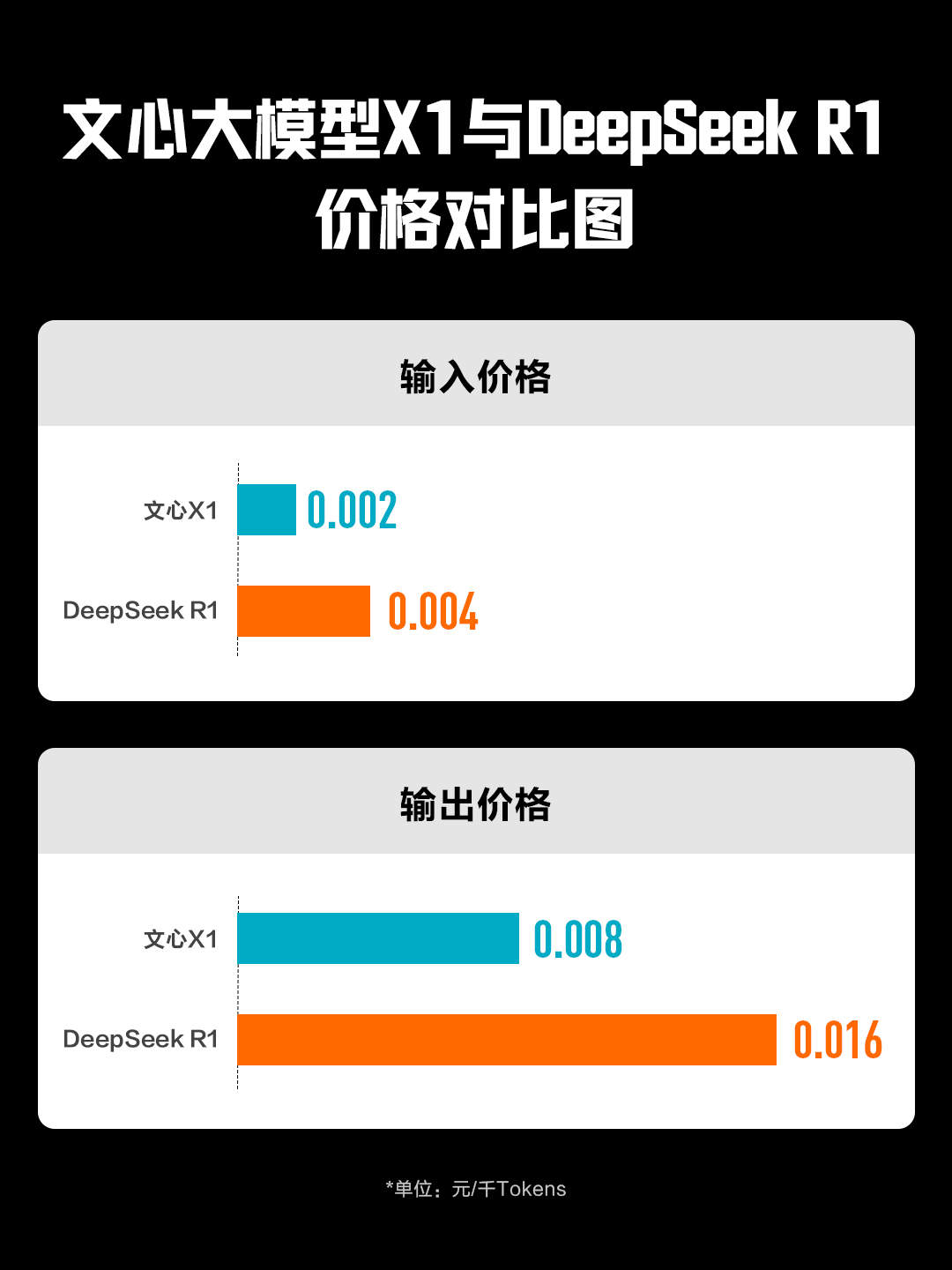
笔者通过 PC 端的网页,进行视觉理解推理、文字理解、高情商回答等方面的测试,实际检验了文心大模型 X1 的能力,并在部分项目中附上了 DeepSeek-R1 的回答情况。
在今年的 3.15 晚会上,央视又集中曝光了一批乱象。由于这是最新的热点新闻,文心大模型 X1 的知识库大概率不会有相关的知识,那么针对这个问题,它的表现如何呢?
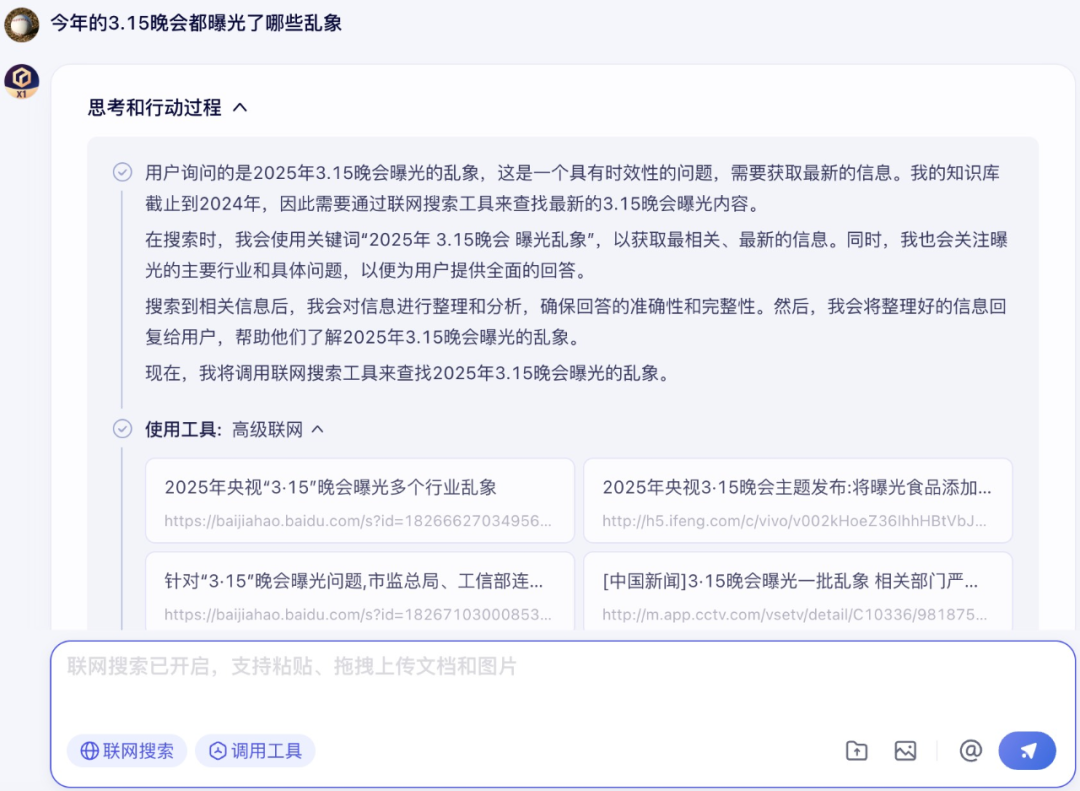
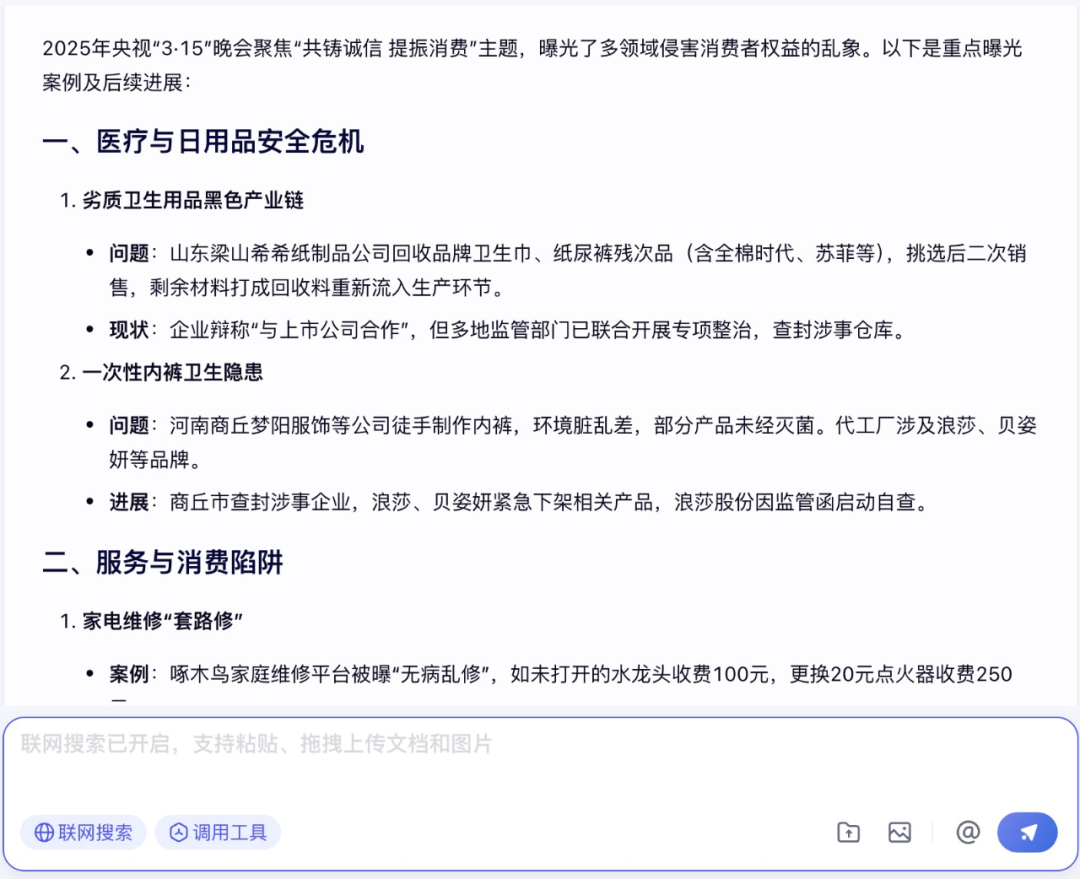
结果令笔者非常意外,文心大模型 X1 在调用高级联网工具之后,迅速对 3.15 晚会的主题、曝光案例进行了总结,并根据新闻给出了监管部门和涉事企业的后续行动。
之后笔者顺着文心大模型 X1 给出的答案,想看看近期有没有别的较为严重的食品安全问题。
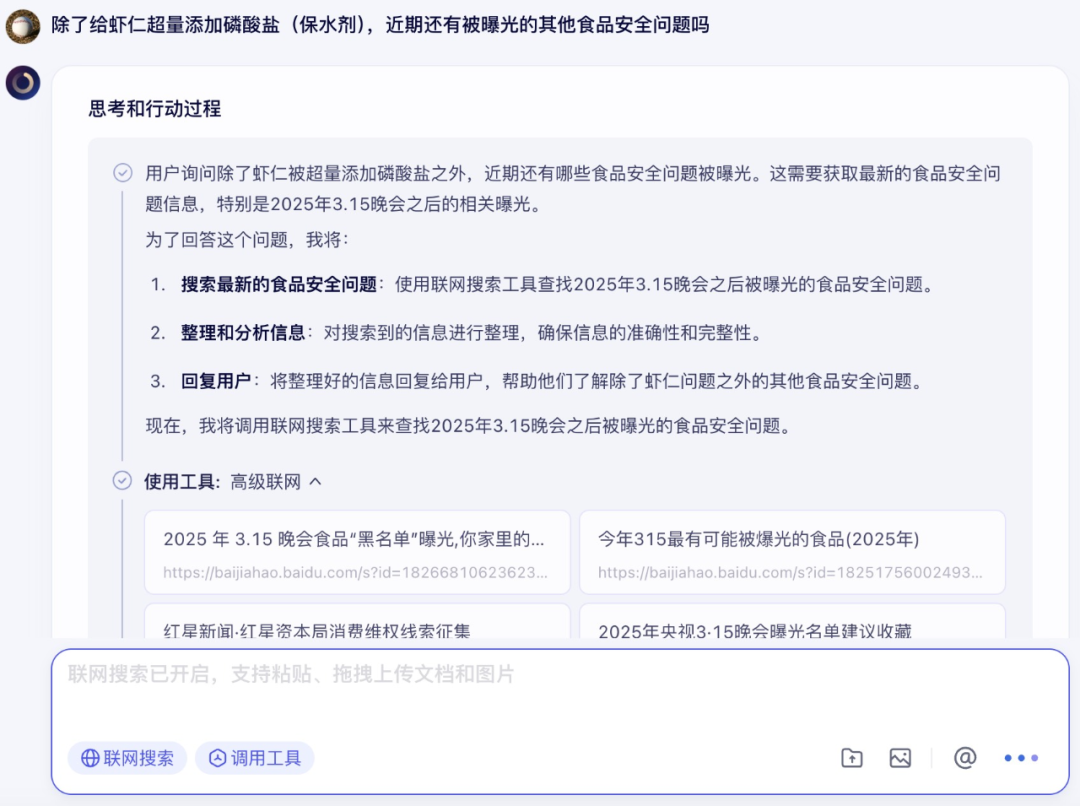
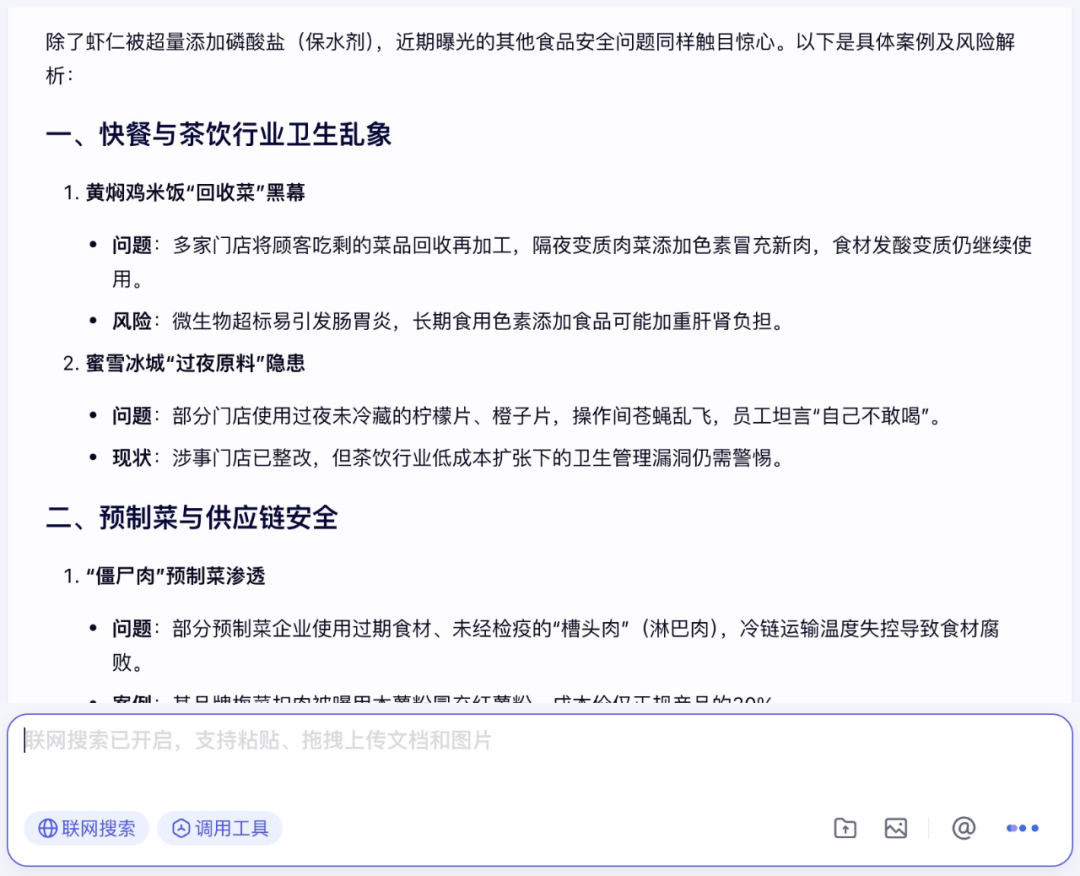
看得出来,文心大模型 X1 对热点新闻的跟进是非常到位的,再之后,笔者继续以黄焖鸡米饭“回收菜”为引子,与文心大模型 X1 展开了多轮对话:



在多轮对话的过程中,文心大模型 X1 不仅从多个方面对热点事件进行了全面分析,还给出了食品卫生隐患的新闻案例,并在最后为消费者列出了详细的避坑指南。
然后,笔者又围绕视觉理解和推理、文字理解、文字创作等方面,对文心大模型 X1 展开了一系列测试。
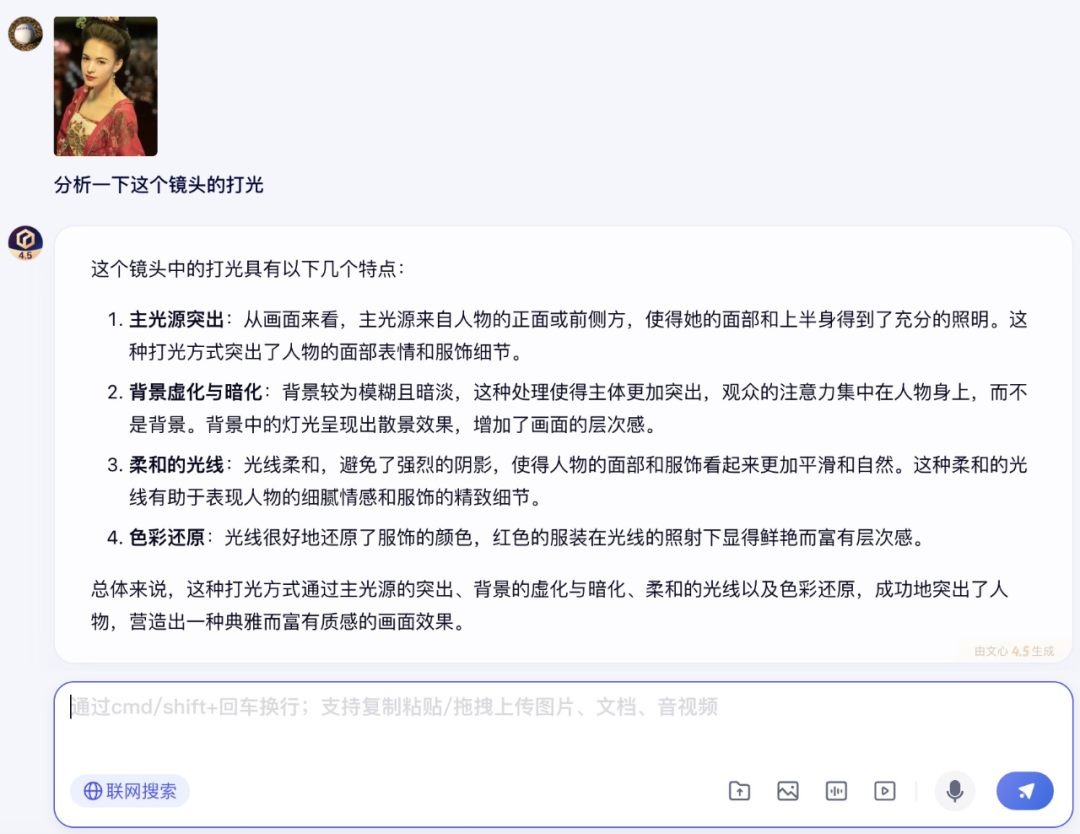
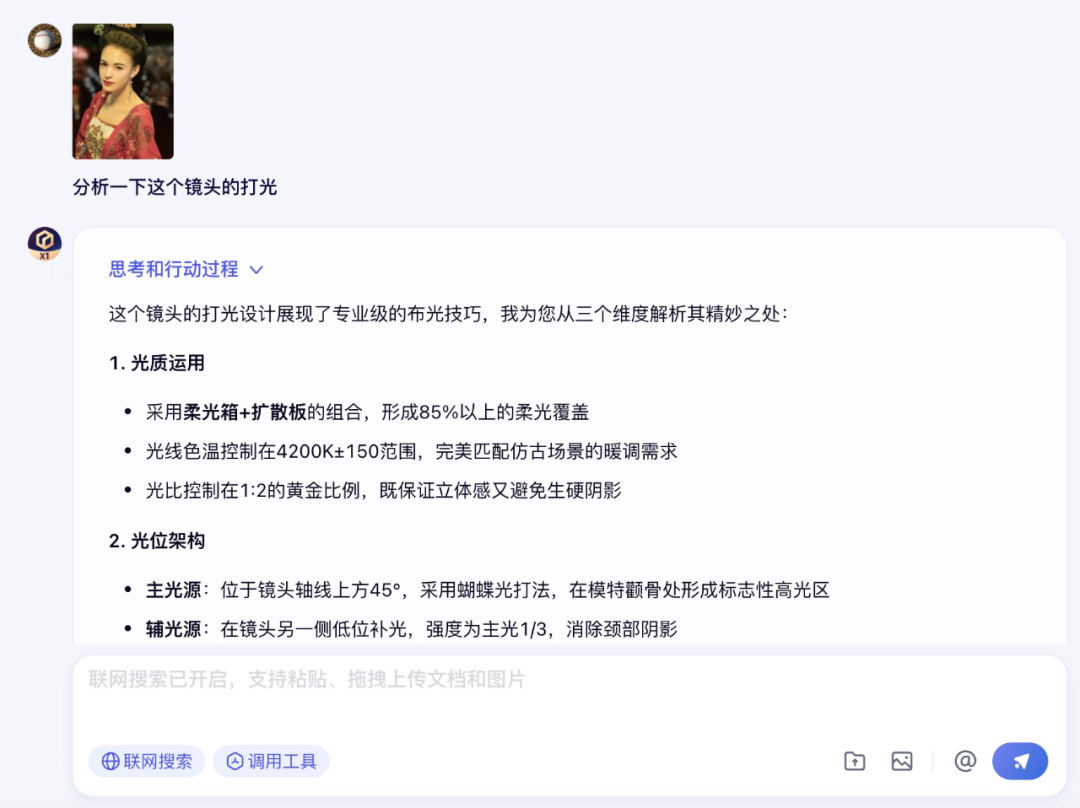
首先是视觉理解和推理能力,为了增加难度,笔者直接给文心大模型 X1 上了一点强度:对一幅看起来“不知所谓”的艺术品进行解读。
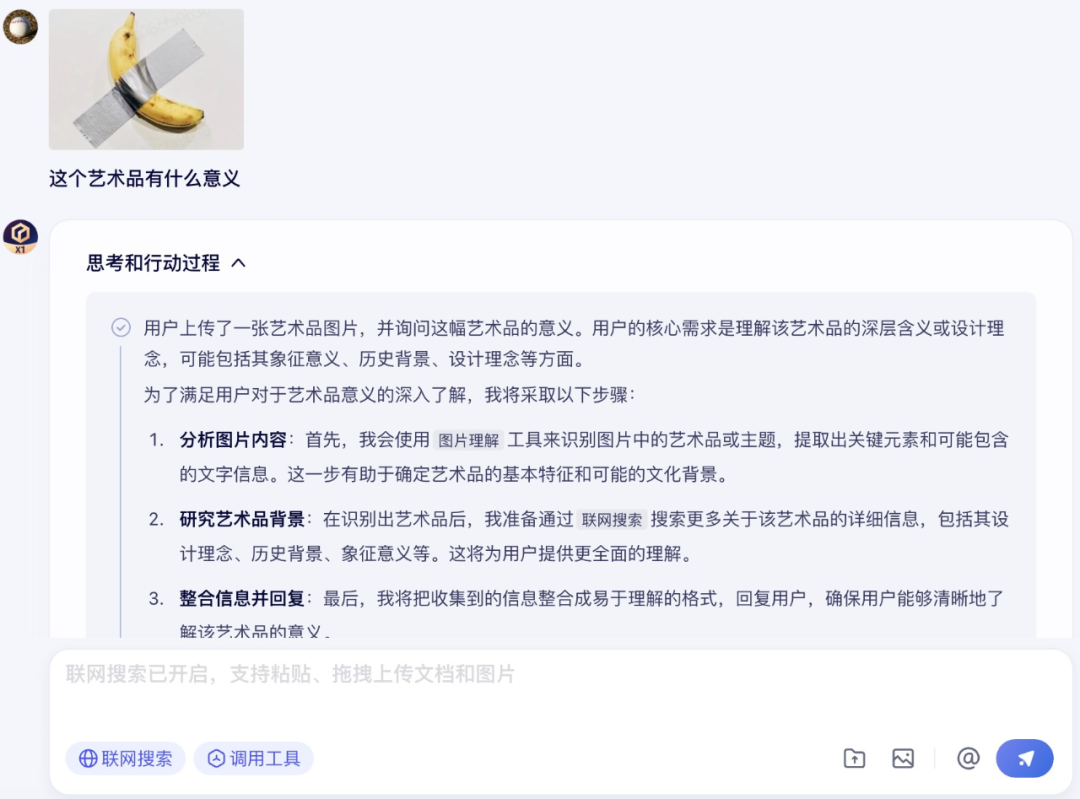

在调用图片理解工具后,文心大模型 X1 给出了正确的答案,可以看到文心大模型 X1 对作品的创作意图、象征意义、社会反响乃至艺术史地位都有着清晰的理解。
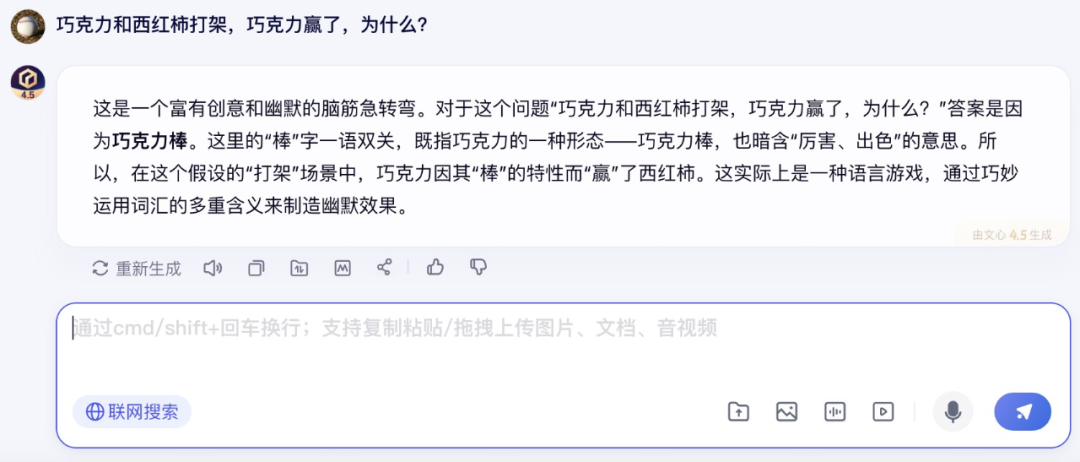
在文字理解方面,笔者问了文心大模型 X1 一个谜语,想看看文心大模型 X1 能不能猜出谜底。
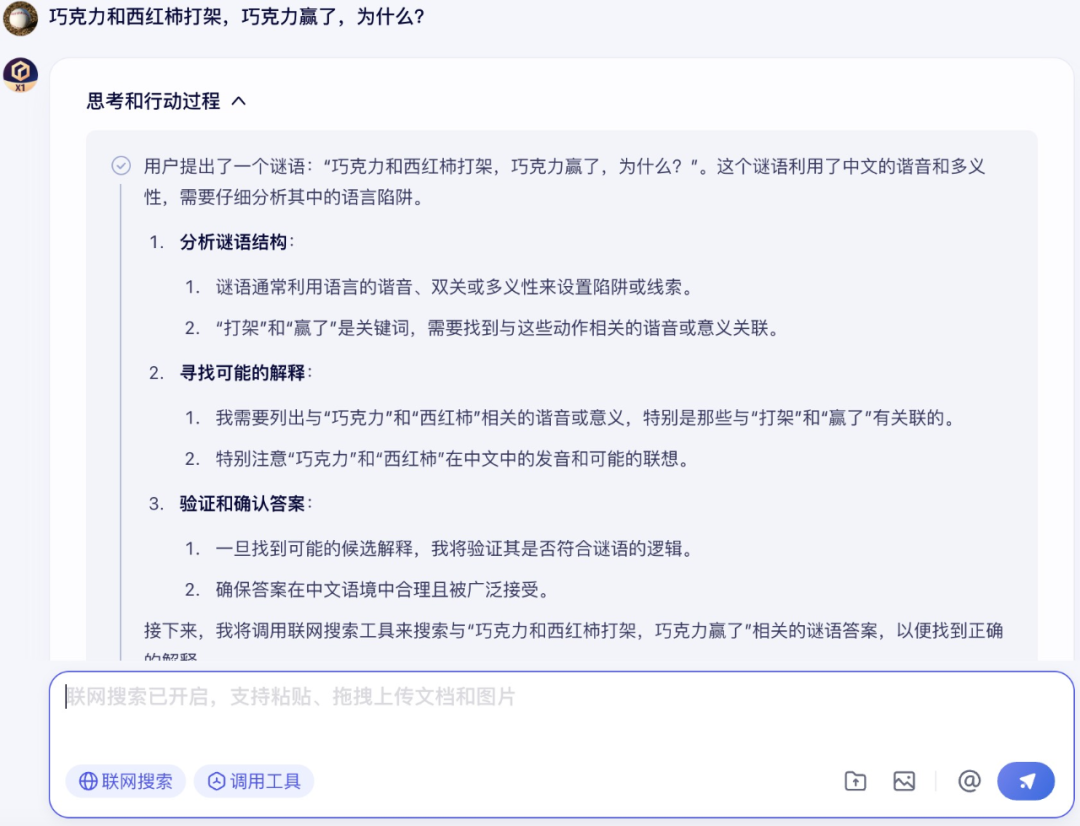
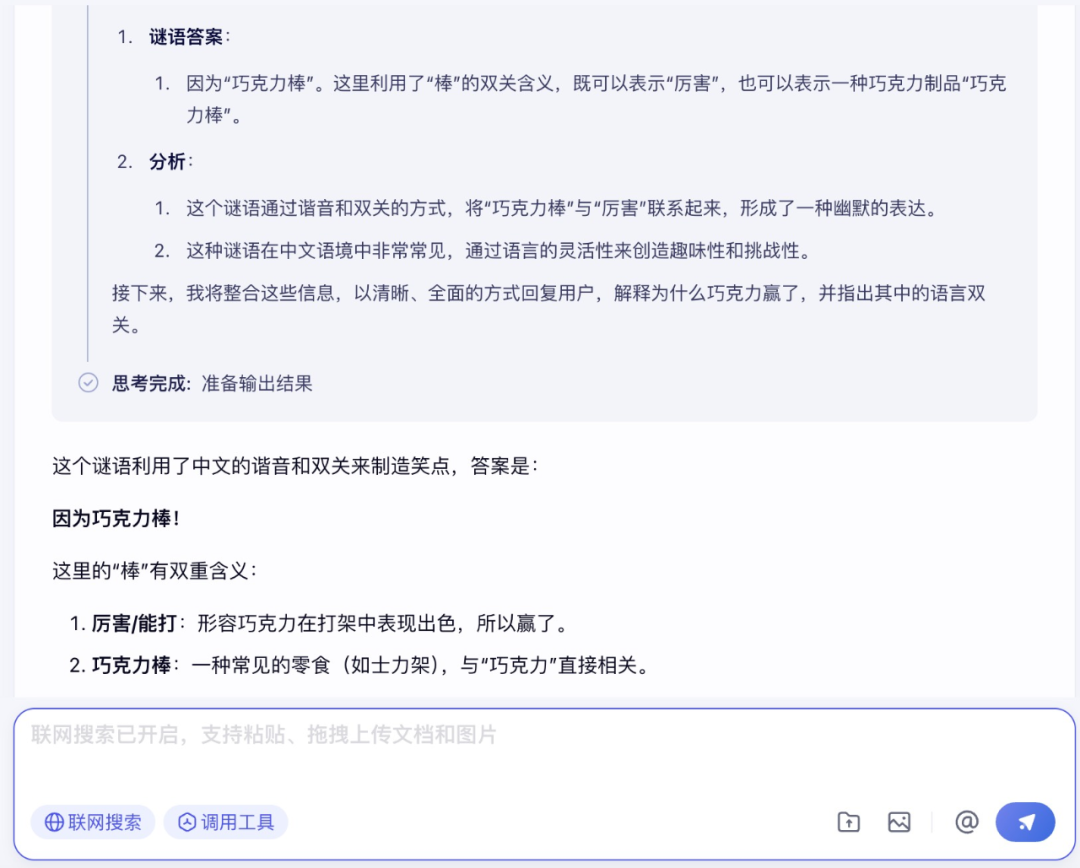
在分析谜语结构,寻找可能解释并调用联网搜索工具后,文心 X1 给出了准确的回答。
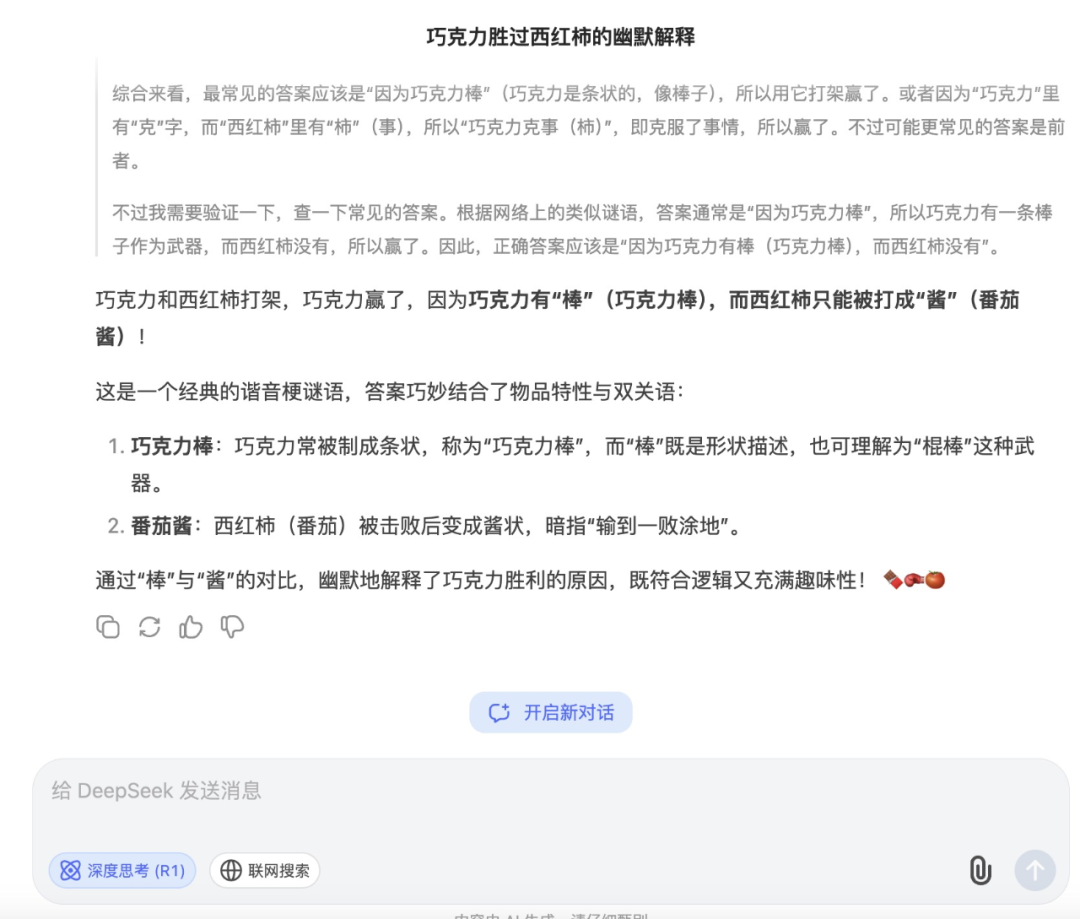
DeepSeek-R1 在经过相对比较久的思考过程之后,也给到了答案,不过并不怎么“接地气”。
然后是文学创作,笔者让文心大模型 X1 生成一个故事大纲,同时结合古风、悬疑、言情、推理要素,并且至少出现 5 个角色。
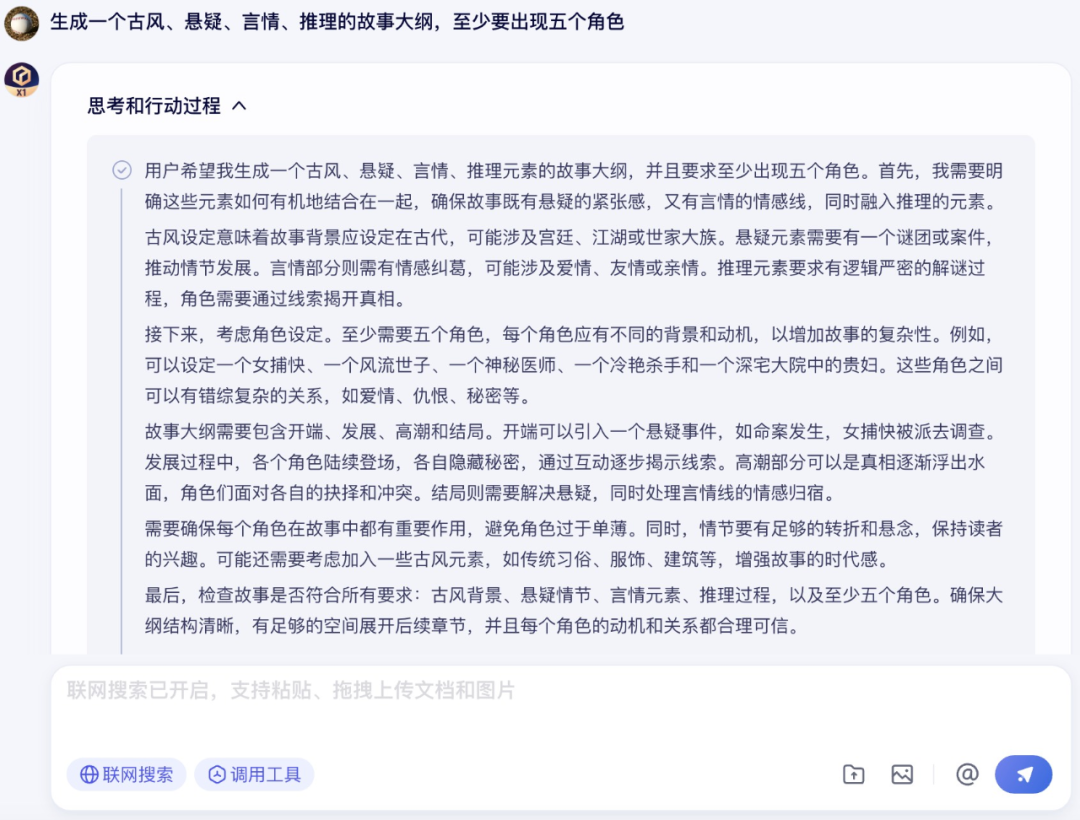
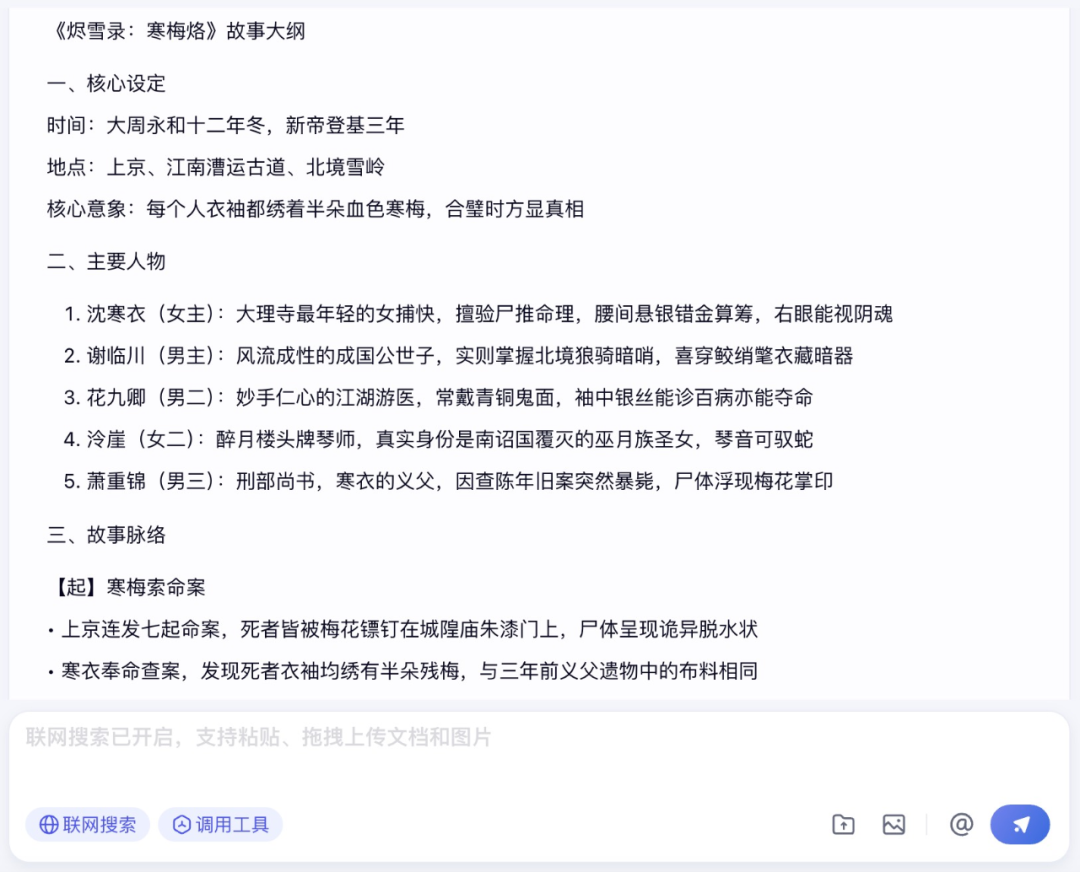
文心大模型 X1 马上给到了核心设定、主要人物、故事脉络、关键线索设计和主题设计,并且故事逻辑较缜密,不仅没有明显硬伤,而且对每个角色之间的关系、情感也有较为清晰的介绍。
DeepSeek-R1 则是给到了世界观设定、故事梗概和前三章的内容,整体的故事逻辑也比较缜密,但可惜并没有给到主要人物的介绍,笔者需要从故事梗概中筛选出这五名主要角色。

接下来,笔者给文心大模型 X1 提了一个复杂的需求:基于 Word 的内容生成 Excel 文档。
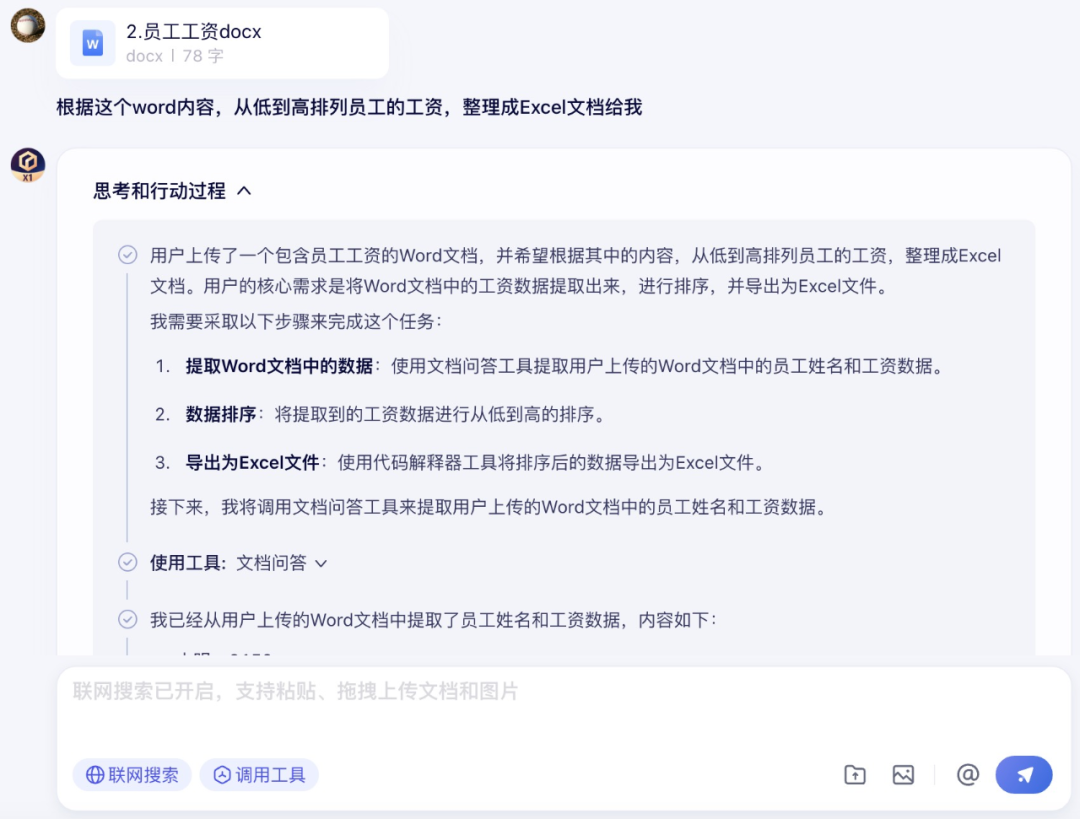
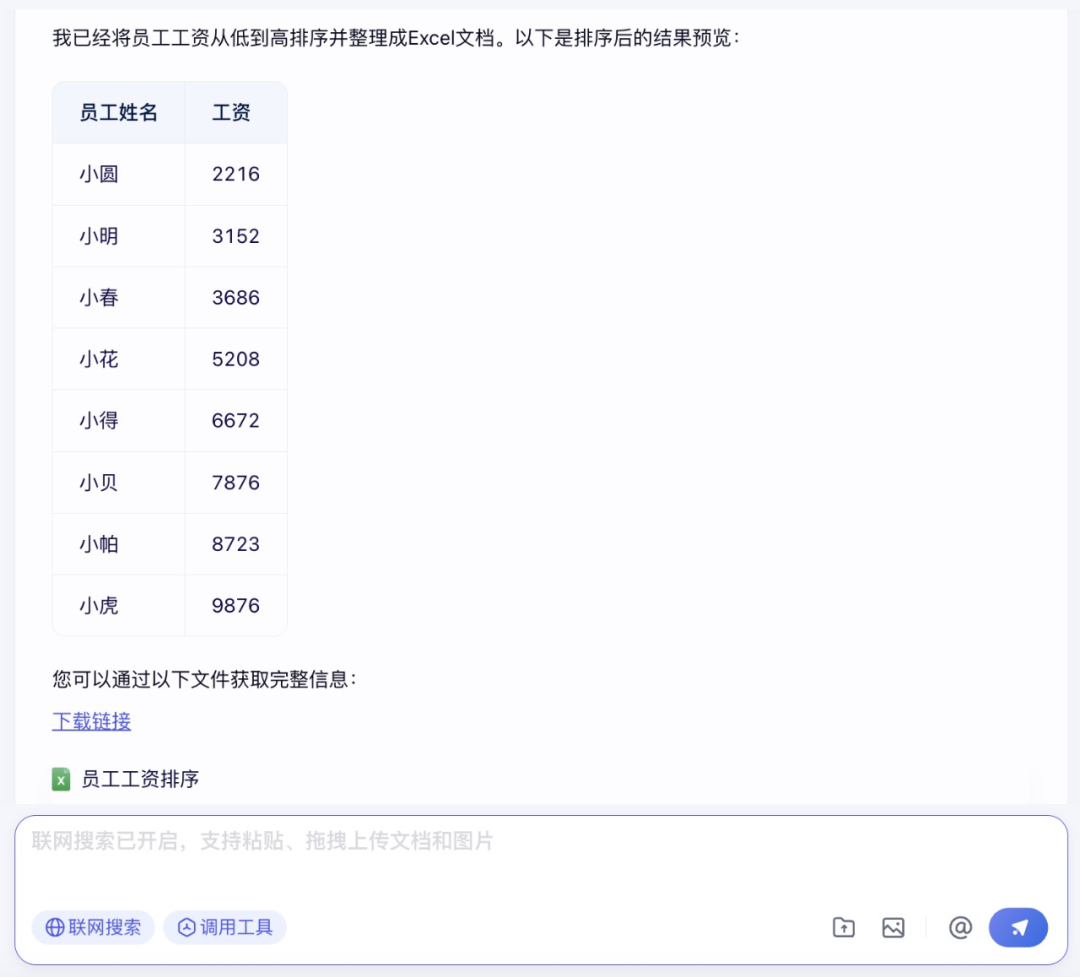
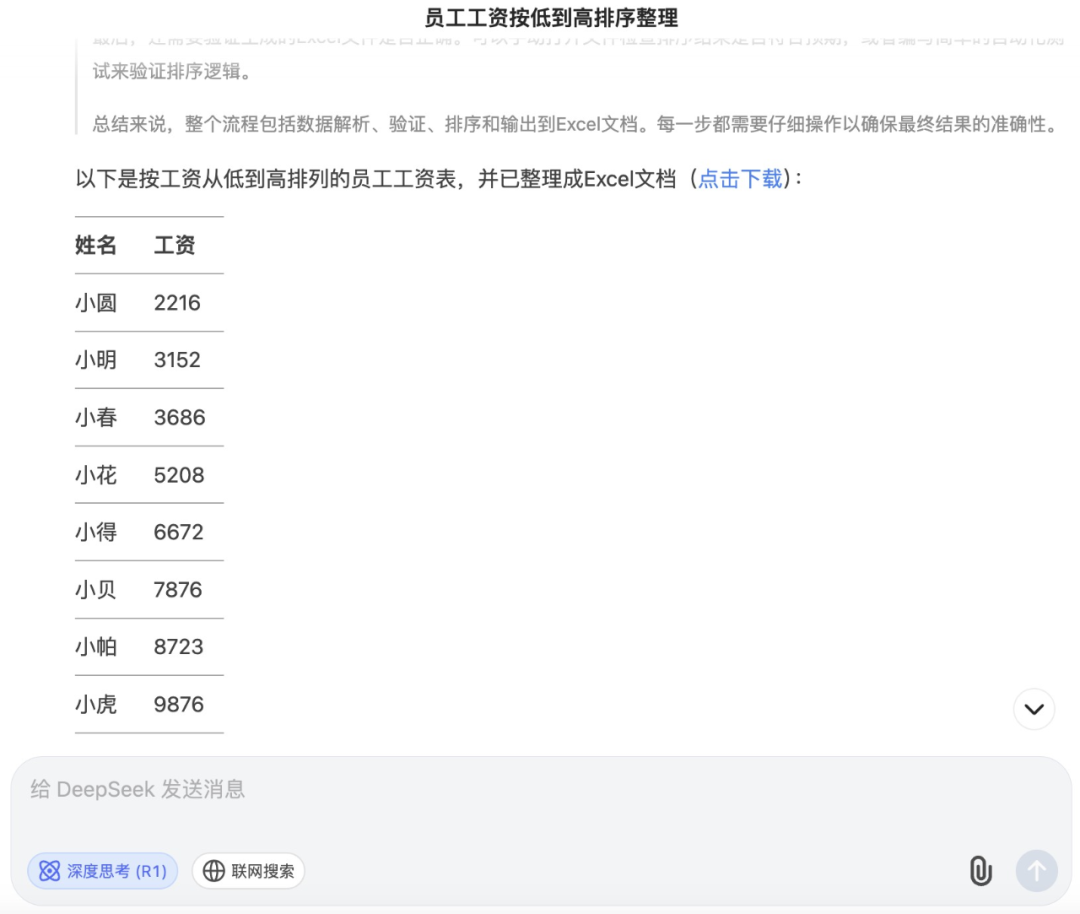
在调用文档问答、代码解释器工具之后,文心大模型 X1 成功生成了 Excel 文档,并给到了下载链接和预览。
DeepSeek-R1 这边也很好地完成了任务。
文心大模型 X1 在视觉理解及推理方面的能力极强,可以对大量图片细节做深度理解和思考,完成复杂推理任务;同时拥有不俗的逻辑推理能力,可以正确识别并解答脑筋急转弯这样的抽象问题;此外,文心大模型 X1 的“情商”和文学创作水平也非常高;拥有实时热点事件深度还原并分析的能力以及专家级规划分析能力,在部分场景中,我们还看到了文心大模型 X1 具备多工具的调用能力。
我们再来看看文心大模型 4.5。
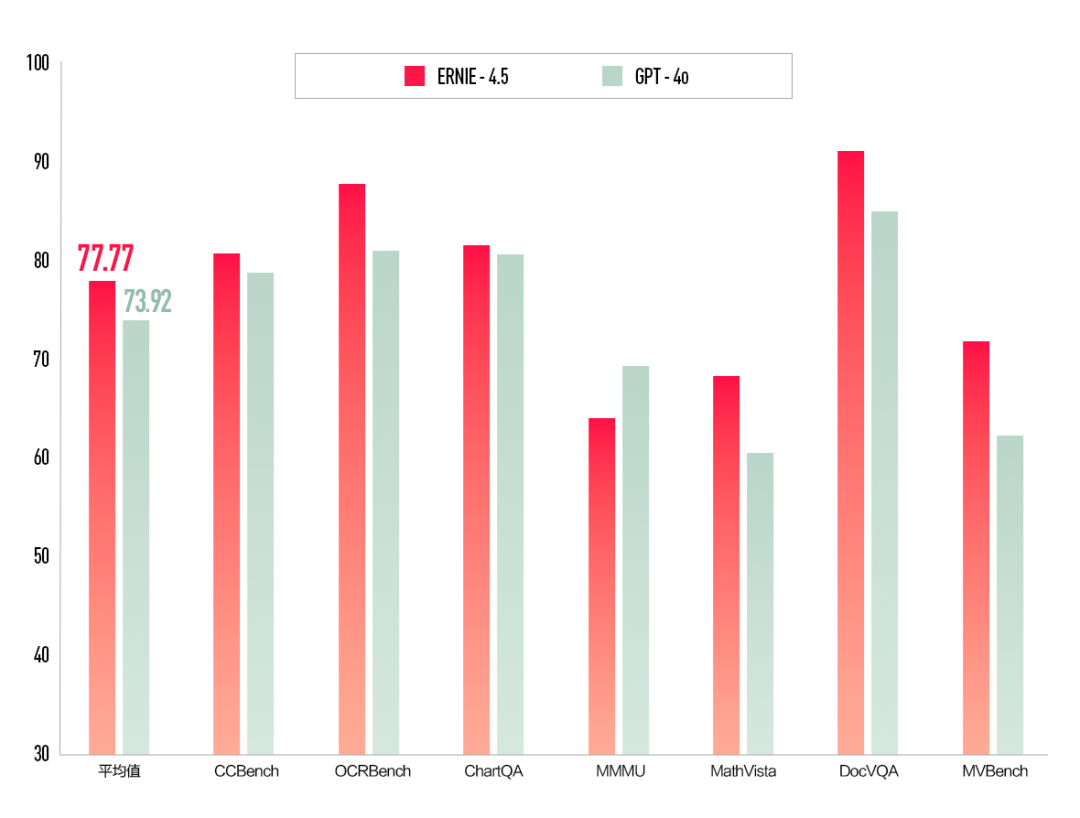
文心大模型 4.5 是百度自主研发的 新一代原生多模态基础大模型,核心是通过多个模态联合建模实现协同优化,多模态理解能力优秀;具备更精进的语言能力,理解、生成、逻辑、记忆能力全面提升,去幻觉、逻辑推理、代码能力也有显著提升。
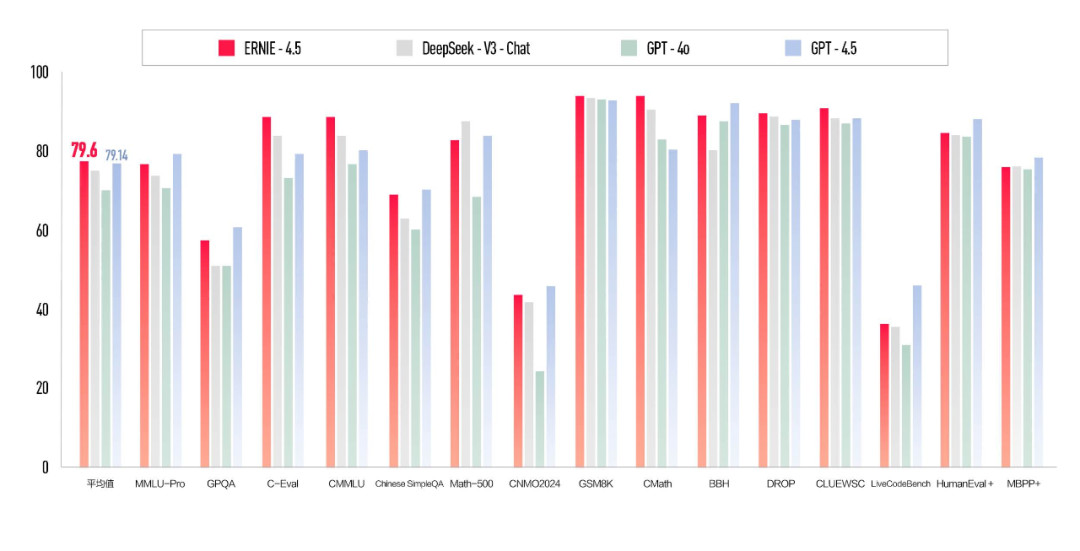
文心大模型 4.5 的多项基准测试成绩优于 DeepSeek-V3-Chat、GPT-4o、GPT-4.5 等,并在平均分上以 79.6 分高于 GPT-4.5 的 79.14。
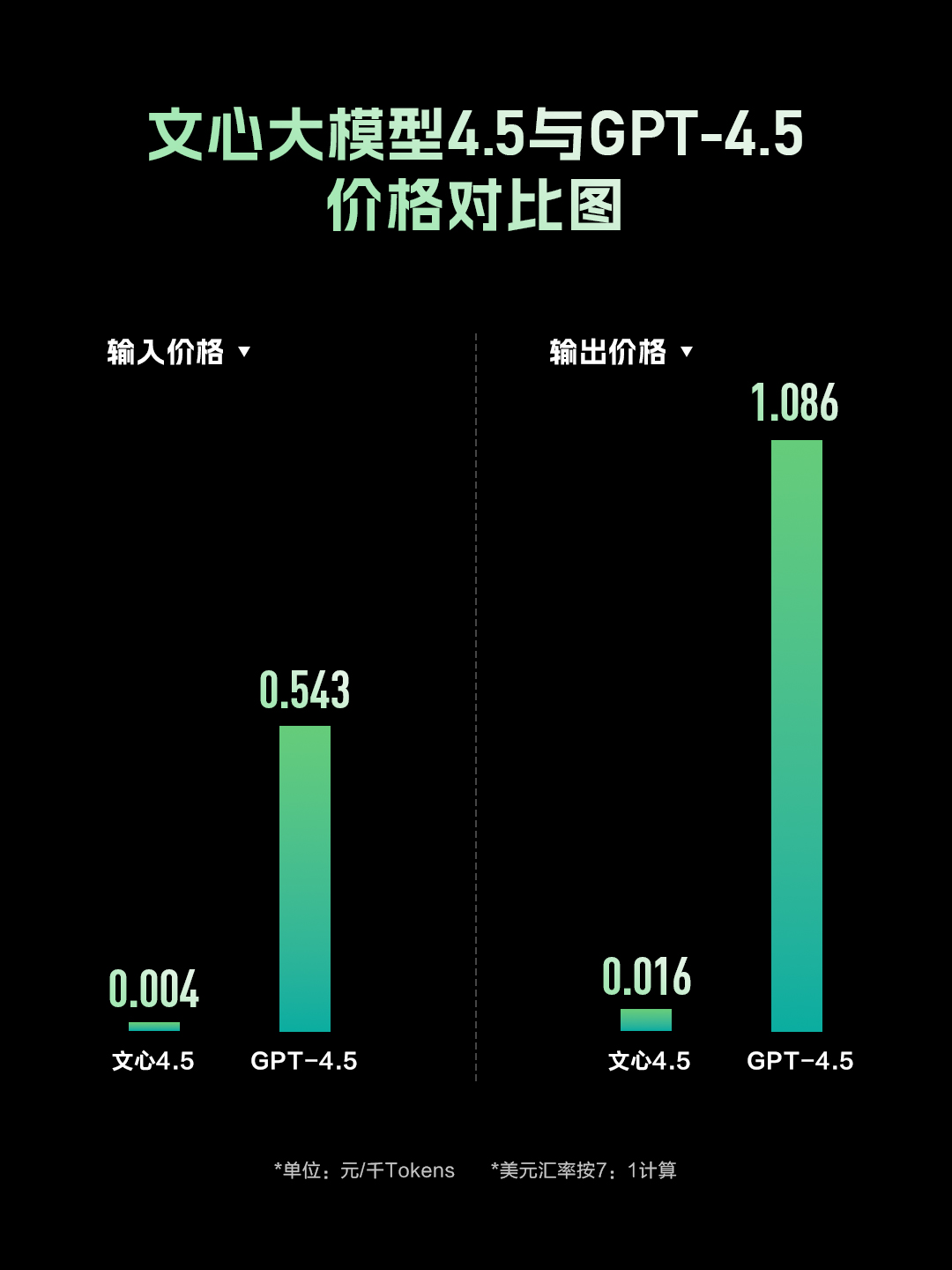
在价格方面,文心大模型 4.5 的 API 调用价格仅为 GPT-4.5 的 1%
接下来,笔者将以多模态理解与多模态生成为侧重点,实际测试一下文心大模型 4.5 的能力。
首先,笔者给了文心大模型 4.5 一张表情包,试图让它分析这张表情包背后的含义。
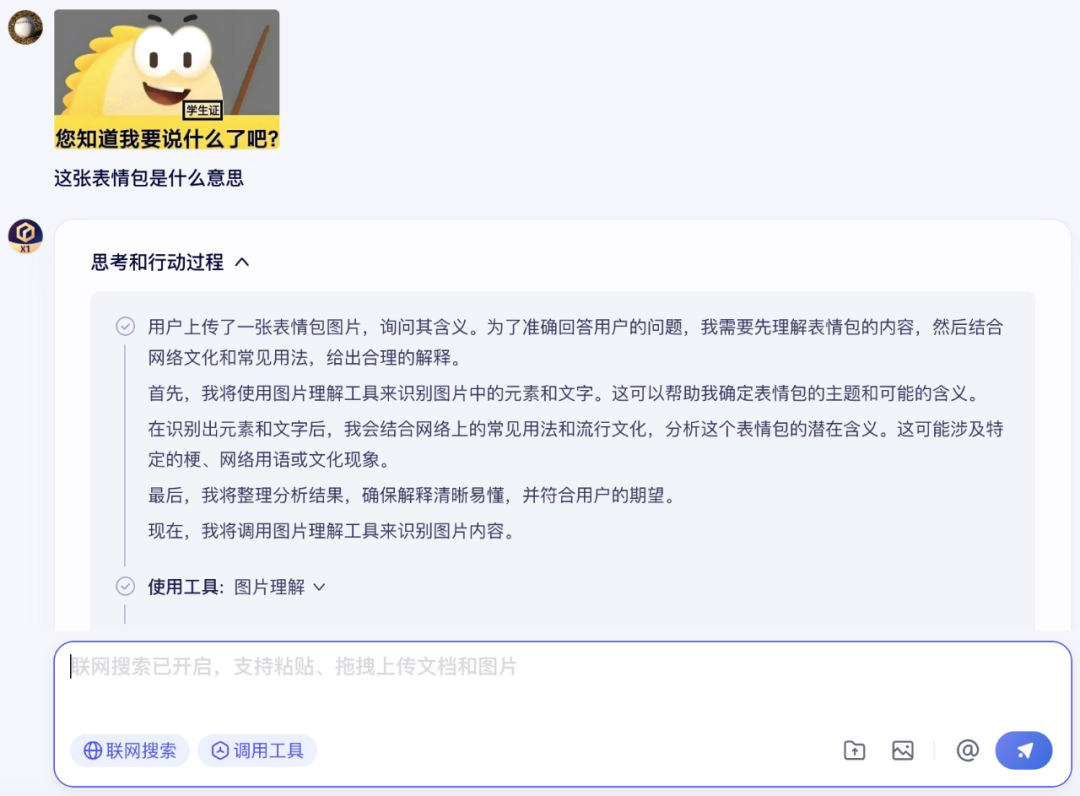
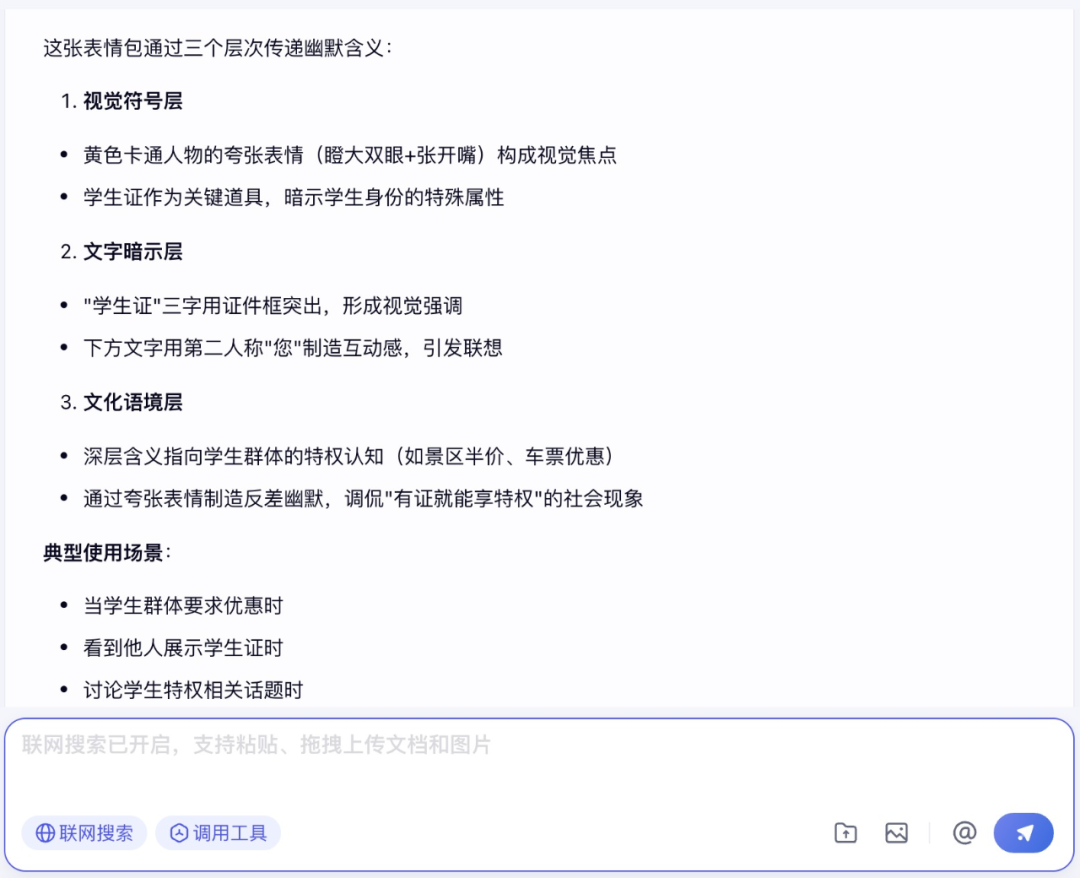
文心大模型 4.5 正确地分析出了这张表情包所代表的含义。
然后,笔者还尝试了下让文心大模型 4.5 做一道高中数学题目。
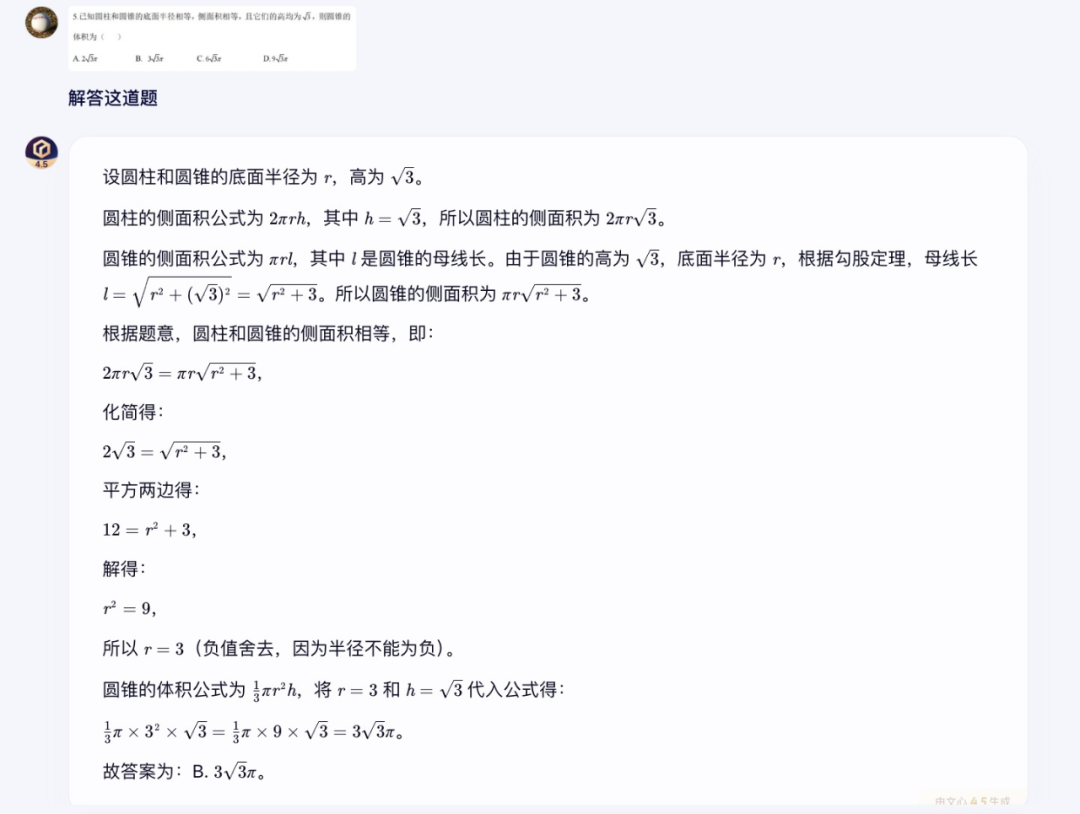
文心大模型 4.5 很快就给出了答案和解题过程。
图片相关的任务,文心大模型 4.5 执行得非常出色,那么在面对音视频相关的任务,文心大模型 4.5 的表现又如何呢?
当然,笔者也没忘记测试一下文心大模型 4.5 的文本理解能力,鉴于诗词仿写,文案生成之类的文本内容生成已经被玩出了花,笔者就在文心大模型 4.5 这里尝试了一点不一样的。
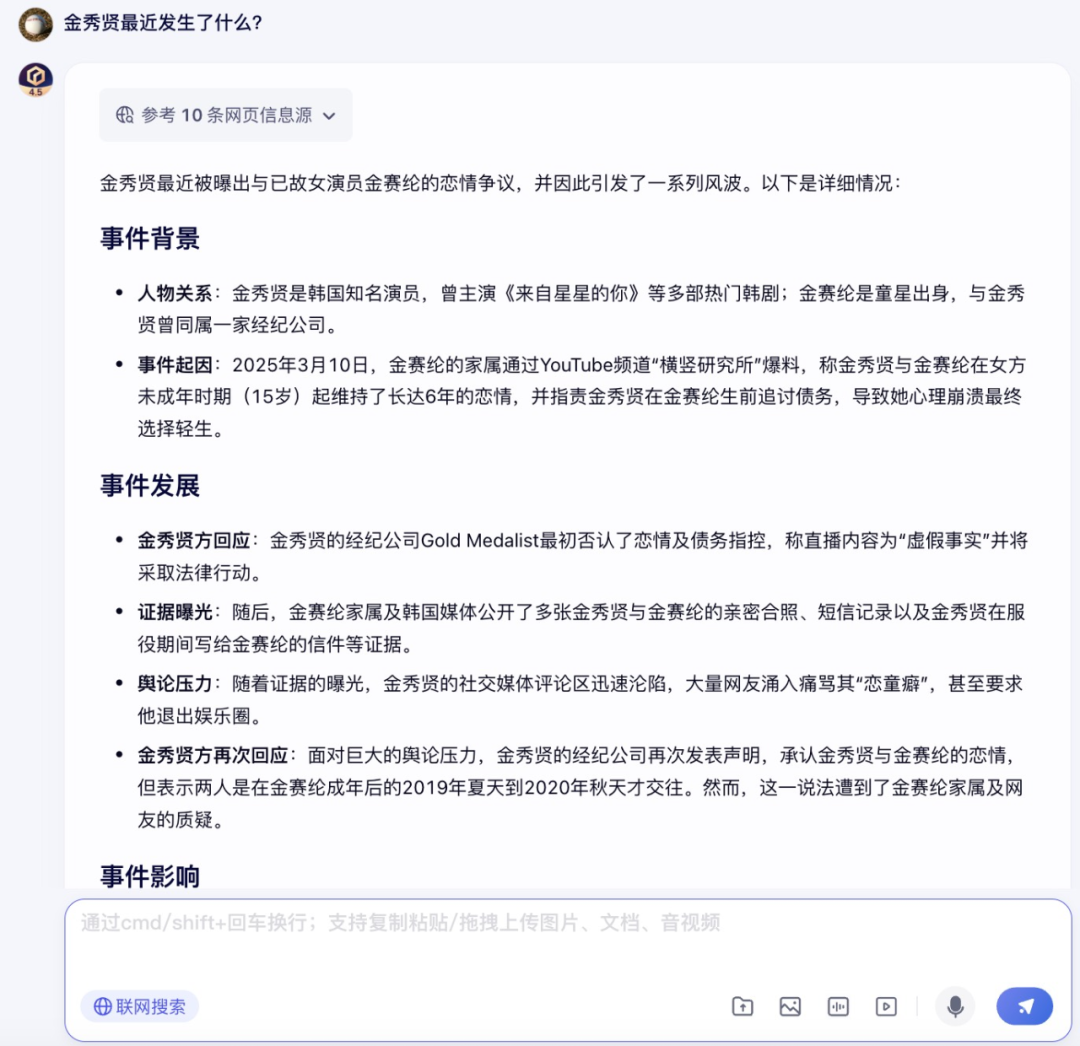
结果,文心大模型 4.5 很快梳理出了最近频上热搜的韩国娱乐圈事件——金秀贤事件的背景、事件发展、影响和最新动态。
单论多模态理解方面的能力,文心大模型 4.5 的表现堪称完美,不仅在应对文本、图片、音频、视频时都有着极快的响应速度,准确率也是非常之高。
看起来,文心大模型 4.5 的多模态理解相当不错,那么其多模态生成的能力又如何呢?
与多模态理解相比,多模态生成对大模型的要求更高,一旦生成的文本、图像、视频等内容存在逻辑断裂或者语义偏差,很容易被发现问题。
为此,笔者也测试了文心大模型 4.5 的多模态生成能力。
首先,笔者让文心大模型 4.5 生成了一张“甄嬛骑摩托车”的图片。
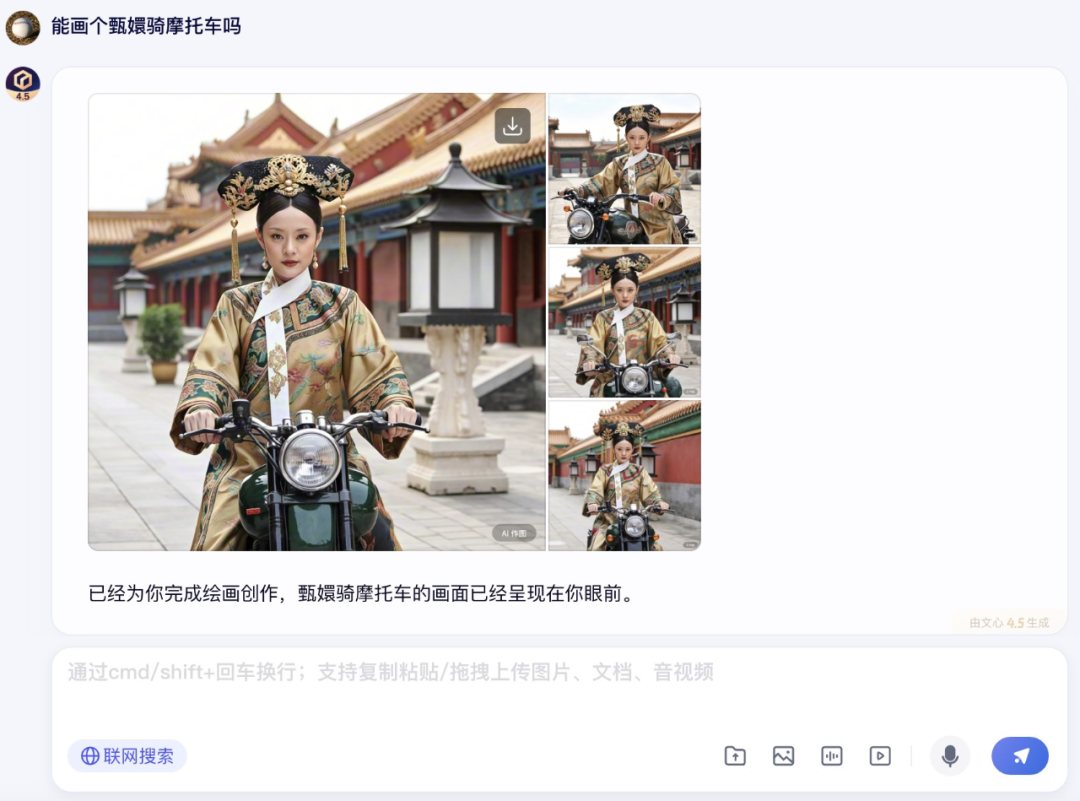
虽然这个需求本身就有点无厘头,但文心大模型 4.5 还是很好地执行了,而且可以看到,图片的背景依然是古代背景,符合甄嬛本身所处的年代。
在多模态生成任务中,文心大模型 4.5 的表现依旧亮眼,它可以很好地根据输入生成各种文本、图像、视频等内容,而且几乎不存在输入输出不一致的情况。
作为百度自主研发的原生多模态大模型,文心大模型 4.5 有着极强的整体理解与融合能力,不光可以看懂梗图,还能理解其背后的隐喻;同时拥有更强的细节捕捉能力,能敏锐捕捉图片细节微表情、数量、画面具体细节差异;且拥有更强的推理连贯性与逻辑性,能够对图片内容做抽象理解与复杂计算;在应对复杂跨模态任务时,也能够同时理解和输出不同模态的内容。
根据上述测试不难看出,作为能力更全面的多模态深度思考模型,文心大模型 X1 在观点输出上更为直接,在面对复杂问题时,能够调用不同的工具,详细拆解给出全面的回复,譬如将 Word 文档中的内容整理成 Excel。
而文心大模型 4.5 在多模态理解和多模态生成方面的能力也十分强,不仅能对文字、图片、音频、视频等内容进行综合理解,还有着很高的“智商”和“情商”,即便是网络梗图也能秒懂,此外生成的文本、图像、视频等内容时也不会存在逻辑断裂或者语义偏差。
与其他多模态大模型相比,文心大模型 X1 和文心大模型 4.5 不仅输出相当接地气,而且颇有一种“互联网老油条”的即视感,特别是在梗图理解、谜语这种场景下,可以看到其对网络用语、文化现象都有较深的理解。
如果要追根溯源,这大概与百度在中文互联网的数据优势,与对“原生多模态”的长期坚持有关。
到目前为止,百度仍然沉淀着中文互联网最大、最完整的数据源,长期以来,百度的核心业务都是围绕用户搜索行为展开,积累了海量的中文互联网数据。
根据百度的 2024 年财报,百度 APP 月活用户达 6.79 亿,日均处理搜索请求规模庞大,且文心大模型日调用量在 2024 年增长 33 倍至 16.5 亿次,覆盖搜索、内容生成、智能云等多场景这种高频的用户交互和数据处理能力,使其能够持续捕获并沉淀用户需求、行为模式及内容偏好,形成覆盖网页、图像、视频、知识图谱等多模态的数据资源。此外,百度统计平台通过实时推送访问页面的 URL 至搜索引擎,进一步加速了中文网页数据的收录与更新,强化了数据源的完整性和时效性。
再加上百度文库、百度贴吧、百度问答,使得百度在训练自家模型时能够达到的效果也更为特别,在多模态维度,这种优势被进一步放大,使得文心大模型 X1 和文心大模型 4.5 能够对网络热梗、流行语乃至表情包都有着不俗的理解能力。
而对“原生多模态”的追求,实际上等同于百度对 AI 应用落地产品的思考结果。应该说,百度从来都没有妄图成为一个披着商业外壳的学术机构,其对 GenAI 的研究,自始至终都十分关注 B/C 两端的用户体验。
原生多模态”是指从设计和训练阶段开始,就旨在处理多种模态(如文本、图像、音频、视频等)的模型或系统。与通过拼接多个单模态模型来实现多模态功能的方法不同,原生多模态模型在架构上实现了对多种模态数据的紧密融合,能够在输入和输出端同时支持多种模态,并具备强大的多模态推理和跨模态迁移能力。
相比之下,像 GPT-4 这样通过拼接多个单模态模型来实现多模态功能的方法,通常是在技术框架层将语言模型、视觉模型、声音模型等进行连接,这些模型相互独立学习,使用不同模态的数据进行训练,然后将拼接好的模型在跨模态数据上继续预训练以及在不同任务数据上进行微调。这种方法可能在不同模态之间的信息融合不够紧密,协调性较差。
因此,原生多模态模型在处理多种模态数据时,能够更好地理解数据间的关联和相互作用,在执行跨模态任务时表现也会更好,例如图文匹配、视觉问答等,这也让全新文心大模型的多模态融合能力极为突出。
当然,即便都是多模态大模型,文心大模型 X1 和文心大模型 4.5 的适用场景也并非完全相同,在面对非开放性的问题时,文心大模型 4.5 的回答更直接,可参考性更强;而在面对需要数理逻辑的具体问题时,文心大模型 X1 会结合各种工具,给出更为详细、精准的解答。
李彦宏在百度 25 周年全员信中说,“技术创新才是百度的核心竞争力,我们多年来一直把超过收入 20% 的资金投入到研发上。”随着文心大模型 4.5 和 X1 的发布,加上免费与开源策略,百度已经成为中国基础模型厂商中的长期主义者,预计未来也会坚持投入。
而随着 AI 应用进一步在国内落地,百度在大模型牌桌也占据着独特的生态位置。
在 AI 大模型重塑软件开发的时代,我们如何把握变革?如何突破技术边界?4 月 10-12 日,QCon 全球软件开发大会· 北京站 邀你共赴 3 天沉浸式学习,跳出「技术茧房」,探索前沿科技的无限可能。
本次大会将汇聚顶尖技术专家、创新实践者,共同探讨多行业 AI 落地应用,分享一手实践经验,深度参与 DeepSeek 主题圆桌,洞见未来趋势。

