探索AI推理模型中的思维链(CoT)技术,了解如何通过引导LLM逐步推理来提高答案准确性。文章涵盖多种CoT技术、微调方法及经济性分析。
原文标题:AI进入推理模型时代,一文带你读懂思维链
原文作者:机器之心
冷月清谈:
本文深入探讨了AI推理模型中的思维链(CoT)技术,该技术通过引导大型语言模型进行逐步推理,提升了答案的准确性。文章首先介绍了CoT的基本概念和发展历程,然后详细阐述了包括简单CoT、CoT链、贪婪解码、CoT-SC、解码CoT以及结合蒙特卡洛树搜索的思维树(ToT)等多种CoT技术的原理和应用。此外,文章还讨论了在CoT数据上微调模型以提升性能的研究方向,以及温度、top_p和do_sample等采样参数对模型输出的影响。最后,文章分析了CoT技术的经济成本,并提出了构建智能系统的建议,例如根据任务难度动态调整推理策略,以在准确性、成本和用户体验之间取得平衡。
怜星夜思:
1、文章提到了CoT技术在数学和复杂推理方面有显著提升,但在简单问题上提升有限。那么,在实际应用中,我们应该如何判断一个问题是否适合使用CoT技术?是否存在一些通用的指标或方法?
2、文章中提到了使用CoT会增加成本和延迟,而在实际应用中,除了直接使用更强的模型外,大家还了解哪些其他的优化思路,以平衡CoT带来的性能提升和成本增加?
3、文章提到了微调CoT模型,但效果似乎不明显。大家认为未来微调CoT模型更有前景的方向是什么?
2、文章中提到了使用CoT会增加成本和延迟,而在实际应用中,除了直接使用更强的模型外,大家还了解哪些其他的优化思路,以平衡CoT带来的性能提升和成本增加?
3、文章提到了微调CoT模型,但效果似乎不明显。大家认为未来微调CoT模型更有前景的方向是什么?
原文内容
选自 Towards Data Science
作者:Ida Silfverskiöld
机器之心编译
近段时间,推理模型 DeepSeek R1 可说是 AI 领域的头号话题。用过的都知道,该模型在输出最终回答之前,会先输出一段思维链内容。这样做可以提升最终答案的准确性。
今天这篇文章将带你了解思维链(CoT)的相关研究和技术。
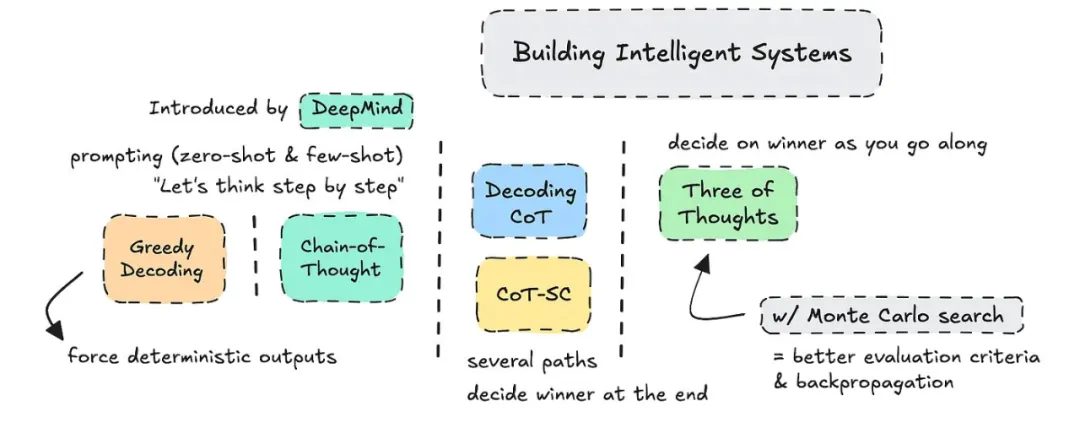
(图注)某些形式的推理技巧。
思维链(CoT)已经存在了相当长的一段时间。从技术上讲,它是一种高级提示工程。各种形式的 CoT 通常都是强迫大型语言模型进行推理。
今年 9 月,OpenAI 发布了其模型 o1 的预览版后,我们看到围绕 CoT 的炒作愈演愈烈。
除了 OpenAI,没有人完全知道 o1 是如何工作的,它是否是一个组合系统,用什么样的数据进行了微调,是否使用了强化学习,或者是否有几个模型在一起工作。
也许一个模型负责计划,另一个模型负责思考,第三个模型负责评分。但我们知道,它们都采用了某种逐步推理的方式。
关于这一点,已经有很多公开的研究。这篇文章将介绍现有的研究成果,让你知道自己可以使用什么。我也会对不同的技术进行测试,看看我们能否实现真正的改进。
研究者们在过去两年中发表了很多论文。你可以在下图中看到他们所谈到的推理技术。
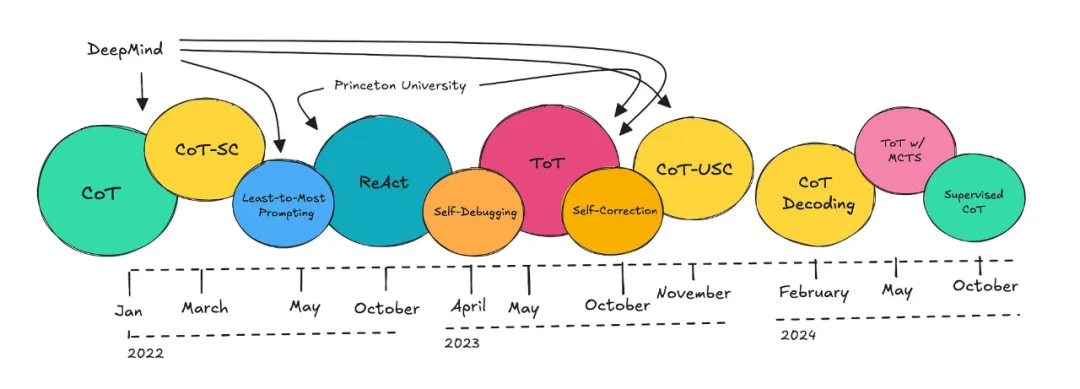
过去两年讨论较多的 CoT 技术。
大部分工作直接来自 DeepMind 或普林斯顿大学。为他们的开源工作点赞。
CoT 这个词是 DeepMind 在 2022 年提出的,只在提示中使用。最新的论文探索了结合蒙特卡洛搜索(Monte Carlo Search)和无需提示的 CoT 的「思维树」(ToT)。
接下来将介绍简单的思维链 (CoT)、CoT 链、贪婪解码、CoT-SC、解码 CoT 以及结合蒙特卡洛树搜索的「思维树」。
LLM 的基线分数
要了解如何改进 LLM 的结果,我们首先需要建立某种基线分数。
在引入模型时,通常会附带评估指标。目前有几种流行的评估指标,如 MMLU(语言理解)、BigBench(推理)、HellaSwag(常识推理)等。
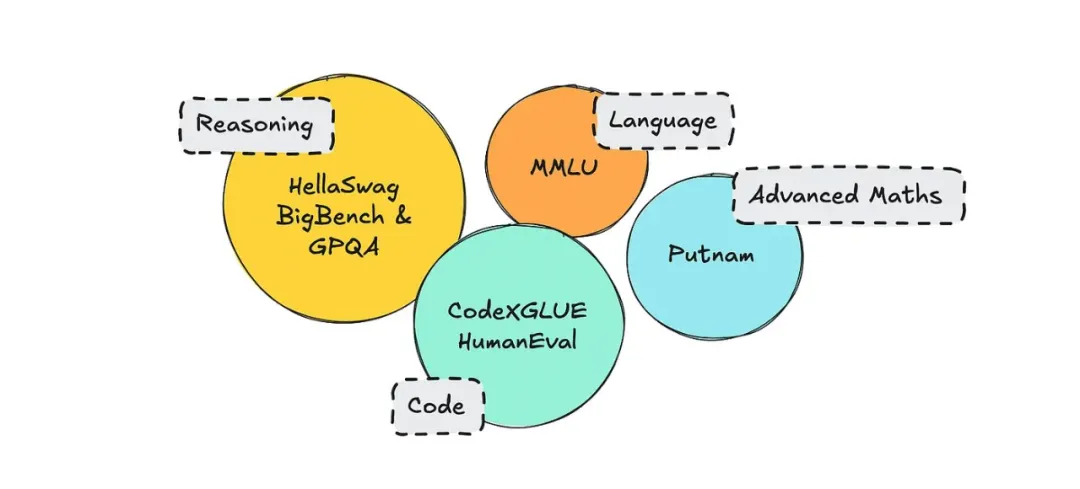
有趣的数据集。
不过,其中一些数据集已经过时,可能受到了一些污染。
Hugging Face 在 12 月份推出了新的 LLM 排行榜,基于较新的数据集进行评估。你可以清楚地看到,大多数模型的得分都比它们在原始数据集上的得分低得多。
这里值得做一些研究,以了解在模型评估方面应该如何思考,以及你和你的组织应该根据什么进行评估。使用内部私有数据集进行测试并不是最糟糕的想法。
我从不同的数据集中抽取了大约 350 个问题,再加上我在网上找到的一些流行问题,然后对 11 种不同的模型进行了评估。
我需要知道这些数据集以及 LLM 生成的答案是什么样的。
因此,我构建了自己的脚本来遍历问题,然后对每个问题用 0 或 1 来评估 LLM。
下面是我发现的结果。
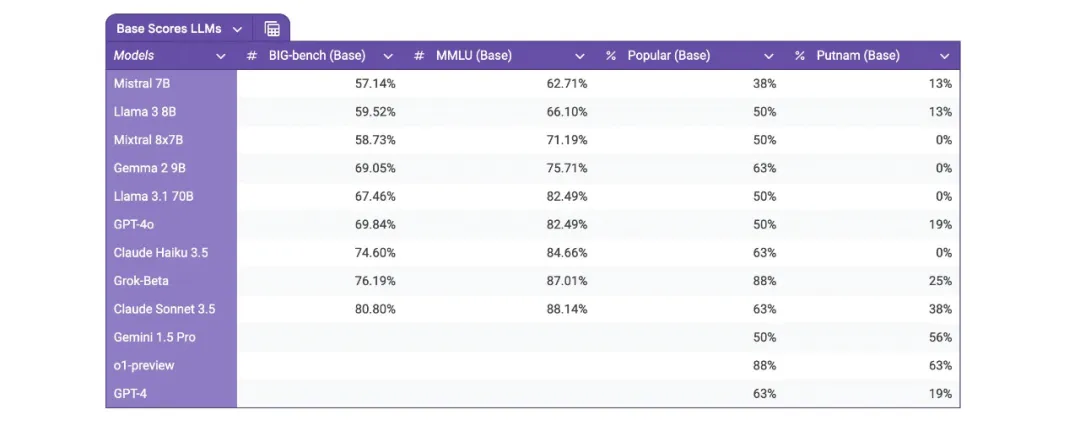
你可以在这个谷歌表格中找到整个数据集和结果:https://docs.google.com/spreadsheets/d/1awPb5klHx-v1oafgZrV_-hdFHnibxla1BGHZ8vCY2CE/edit
我们可以从里面读出来的信息并不多。
我使用了来自 Big Bench、MMLU 和 Putnam 的问题,以及诸如「How many r’s are in Strawberry」之类的流行问题,但我们无法知道它们是否受到了这些问题的污染。此外,这也是一个相当小的数据集。
不过,我们可以清楚地看到,更大的模型表现更好。
我们感兴趣的是,能否通过让模型在回答之前进行推理和思考,来提高这些分数。
思维链(CoT)
思维链(CoT)提示是由 DeepMind 在 2022 年发表的论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中提出的。因此,CoT 的概念已经存在了很长时间。
不过,这第一篇论文研究的是如何通过使用提示策略激活模型固有的推理能力,从而迫使模型对问题进行推理。
当时,人们只是以正确的方式进行提示,要求模型「一步步地思考」,要么通过零样本(不提供例子),要么通过少样本(提供几个例子)的方法。
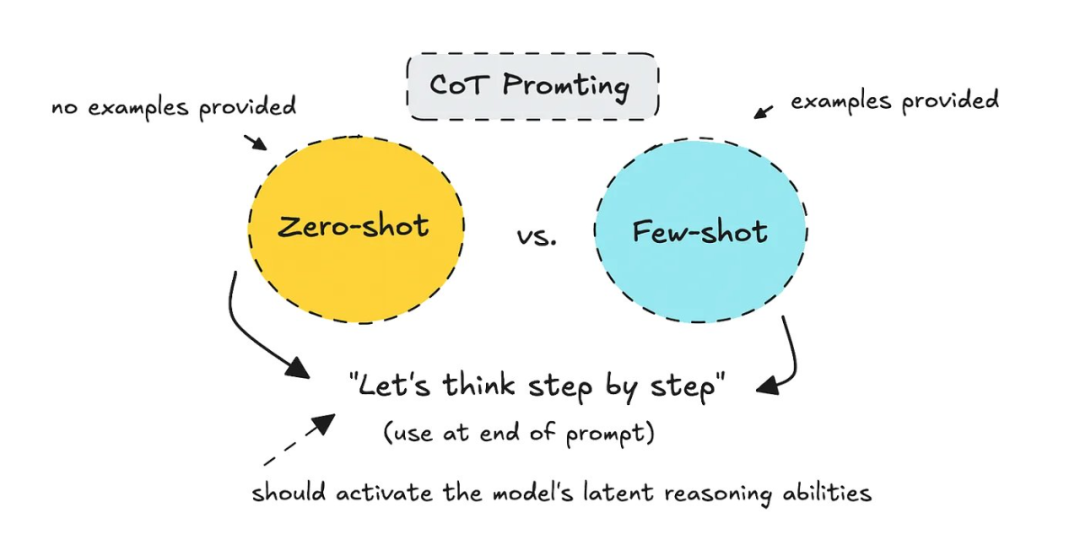
零样本 vs 少样本。
对于 Claude、ChatGPT 或其他各种模型,只需在提示语末尾添加「让我们一步步思考」即可。如果你想尝试少样本学习,你可以在提示中给它一些例子。
DeepMind 报告说,他们可以证实,通过正确的提示,使用 CoT 技术有了显著提高。
从那时起,许多论文都在这些技术的基础上进行了深入研究,并开辟了越来越先进的道路。
构建推理链
在提示词工程社区中,有许多人尝试使用 CoT 风格的技术。我在这里收集了大部分我找到的库,以便读者查找。
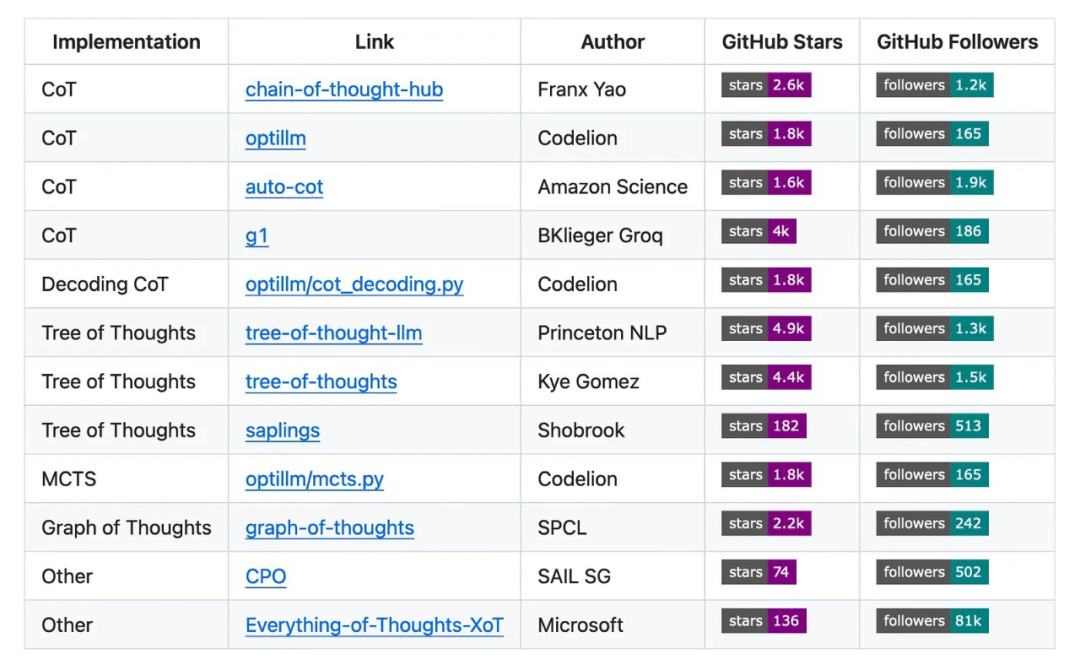
CoT 风格技术的一些实现,详见 https://github.com/ilsilfverskiold/Awesome-LLM-Resources-List
Benjamin Klieger 使用 Groq 和 Llama 3.1 70b 构建了一个提示词风格的应用,通过进一步分解思考过程来引发思维链。可访问这里:https://github.com/bklieger-groq/g1
其想法是要求 LLM 将其思维分解为链,并继续思考,直到对答案有信心为止。
然后,系统将继续为该链的每个部分生成 LLM 调用,而不是将整个思考过程放在一个响应中。
下面这个例子展示了在 Grok-Beta 上应用该技术的示例,问题为「How many R’s are in Strawberry?」
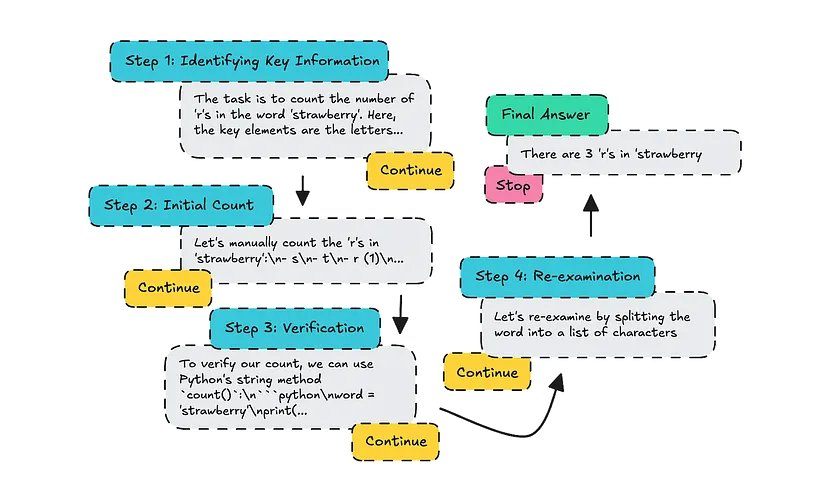
在 Grok 上使用 CoT 链来回答 How many R’s are in Strawberry?
每个部分都由该模型本身设置,为其赋予标题,并决定是否需要继续使用另一个「思维」,还是是否已经得出最终答案。
这仍然是一种 CoT 风格的技术,因为它是线性的,但它比简单地要求模型「一步步思考」稍微高级一些。
我使用了他的部分代码构建了一个脚本,循环遍历我测试的一些针对 LLM 的基本问题,以查看使用这样的系统实际上会带来多少改进。我改编了 Claude 和 Grok 的脚本,以评估这种策略对它们的影响。下面是提升情况:

对于前三个类别,Llama 3.1 70B 的进步最大。Grok 在热门问题上表现较差(Haiku 也是如此)。
Putnam 数据集是高等数学,很少有 LLM 能在其上表现出色,所以当 Claude Sonnet 3.5 凭借这些 CoT 链得到了 68.75%,而 o1-preview 只有 63% 时,我深感惊讶。
总的来说,Sonnet 在使用 CoT 后,高等数学成绩提高了 81%。
请记住,我在这里使用了一个非常小的数据集,这只是为了了解它们在哪些方面表现好以及我们是否可以提高分数。需要在更大规模的数据上测试后才能获得更具体的信息。
不过,我还观察到,如果较小的模型开始对简单问题进行过度分析,会产生更糟的结果。Grok-Beta 和 Haiku 在常见的「较简单」问题上的表现就体现了这一点。
更简单的非数学问题可能无法从 CoT 获得同样的好处。
我们还必须记住,我们可以让模型在自己的能力范围内表现更好,但很少能超越它。如果它不知道答案,它就是无法知道。
用于推理的微调
这里需要提一下微调。AI 领域有一个非常有趣的研究方向:在 CoT 数据集上微调较小的模型,以将其准确度提高到比其大 1-2 倍的大模型的水平。
我已经找到了多个资源,但不幸的是,我们没能找到相较于基础模型有显著改进的案例。下面列出了我找到的开源模型:

下面是开源的 CoT 数据集。
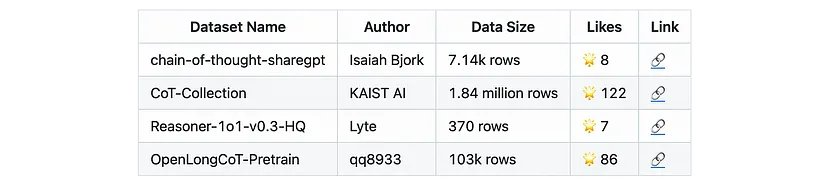
这并不是说微调对 CoT 没用,只是需要构建更好的模型并进行充分的记录。
如果你喜欢自己尝试微调,请查看这些资源。我相信还有更多资源。
其它生成技术
我们讨论的是思维链技术,但还有其他方法可以在没有提示的情况下优化语言模型的输出准确性。
这涉及到我们在调用 LLM 时大多忽略的那些采样器设置 —— 如 temperature、top_p 和 do_sample 等参数 —— 它们可以在控制输出行为方面发挥作用。
现在,我们并不总是可以访问商业 API 的所有这些设置,但我们可以访问 temperature。从技术术语上讲,temperature 的意思是:当我们将其设置为高时,我们可以缩放 logit,从而增加低概率 token 被选中的机会。如下所示:
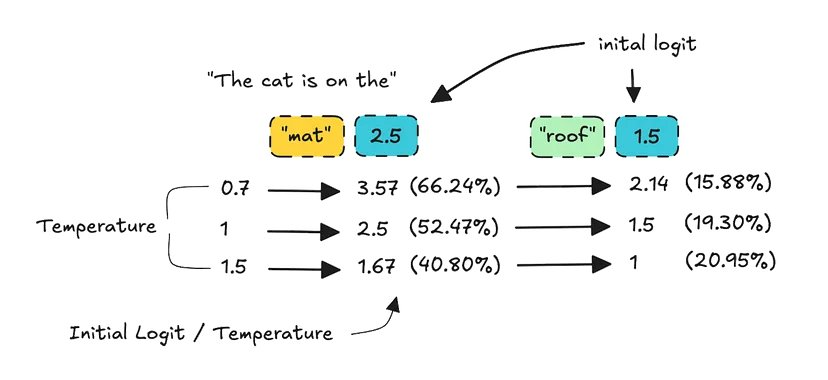
temperature 如何使 logit 上升和下降?
假设 token「mat」在开始时具有最高的初始 logit,但随着温度的升高,我们发现它开始下降,从而降低了概率。对于具有较低数字的初始 logit,情况正好相反。
这是什么意思?这意味着如果温度高,模型更有可能选择一个感觉不太「安全」的词。
大多数人称之为随机性或创造力。
对于并非所有商业 API 都可以访问的 top_p,你可以限制或根据你设置的数字扩展 token 池。低分将限制池中具有高概率分数的 token,反之亦然 —— 低分意味着只有高概率 token 才会出现在候选池中。
高 top_p 与高温度相结合将产生更具创新性和创造性的输出,因为更多的 token 将成为候选者。
do_sample 参数决定模型是否使用采样来生成下一个 token。设置为 True 时,模型会从候选池中采样并具有更大的自由度。设置为 False 时,它仅选择概率最高的 token(并完全忽略 temperature 或 top_p)。
我们可以使用此设置强制模型产生更确定的输出,即每个阶段概率最高的 token。
这被称为贪婪解码(Greedy Decoding)。
这是一种策略:模型在每一步都选择概率最高的 token,这可能会产生更准确的答案(如果它具有所需的固有知识)。
我也确实使用 do_sample 将贪婪解码应用于模型 Llama 3 8B,以检验能否在基础问题上获得提升。结果如下:

可以看到,在 MMLU 和 Big-Bench 上有所提升,但在高等数学上进步很小。
现在,商业 API 多半不提供 do_sample,因此要在无法访问模型的情况下应用类似的东西,你可以将温度设置为 0 以尝试模仿这种行为,但这并不能保证。
所以,你现在可能有一个问题:如果我们确实看到了小的改进,为什么不总是使用贪婪解码?
如果我们忽略输出中对创造力的需求,你还会发现能力较差的 LLM 可能会陷入重复的循环中,例如「The color is blue blue blue blue」,其中「blue」似乎是最高概率的 token,因此会重复。
高级 CoT
之前谈到都是线性技术,即模型在一个线程或链中产生输出。
但在第一篇 CoT 论文发表后不久,DeepMind 就提出了另一种更先进的技术,称为具有自我一致性的思维链(CoT-SC)。
该技术会创建多条推理路径,并使用某种方法在最后选择最一致的答案(或路径)。
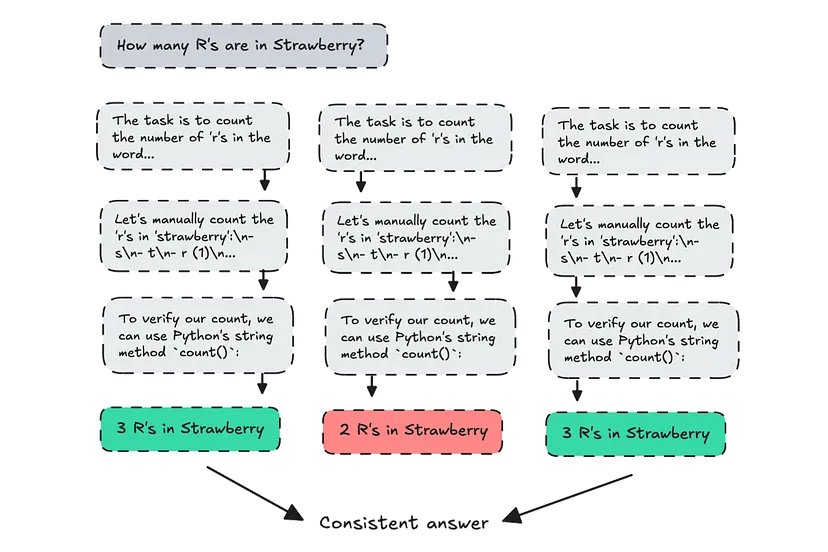
CoT-SC 演示
他们报告说,使用这种方法让算术推理能力提高了 1-8%。
另一种方法的想法也颇为类似,是使用多条路径但不使用任何提示。
还记得我在上一节中谈到的贪婪解码吗?
这种方法类似,只是它不仅要强制选择最可能的 token,还要查看整个响应的置信度分数。
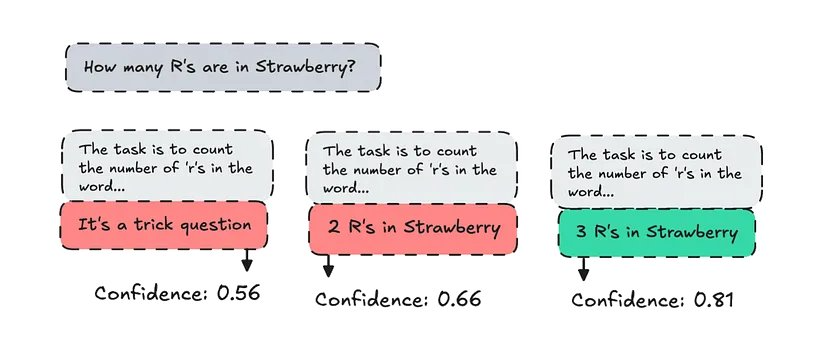
评估内部置信度分数
为此,系统首先会启动一定数量 k 的初始顶部 token,然后从每个 token 生成路径。生成答案后,它会通过分析不同路径中每个 token 的概率(logit)来计算置信度分数。
返回的结果是具有最高概率的答案(或路径)。
这种方法称为 Decoding CoT,由 DeepMind 提出。这种方法的思想是查看模型对返回答案的内部置信度。
但是如果它没有回答问题的固有知识会发生什么?与 CoT-SC 一样,这种方法在很大程度上取决于模型首先是否具有正确的答案。
不过,这并不意味着我们不应该测试它。
对于所有这些技术,都有人开源了不同的实现,这个也不例外。
因此,我很容易就建立了一个系统来测试这些方法,并比较哪种方法在较小的开源模型 Llama 3 8B 上表现更好。

感谢 Codelion 开源他的实现,让我可以轻松复现:https://github.com/codelion/optillm
从上面的结果可以看到,与其他方法(例如 Entropy)或仅使用贪婪解码来处理此特定模型相比,使用 Decoding CoT 显然产生了最佳结果。
更新的技术
现在的研究进展很快,很难完全跟进。这里不会过多论述,但我确实想提一下 ,特别是与蒙特卡洛搜索的结合时。
ToT 于 2023 年底由普林斯顿大学和 DeepMind 提出,但通常建立在以前的基于树的推理方法之上。
ToT 不同于具有自我一致性的思维链(CoT-SC)。ToT 不会生成多条路径,而是在生成后才对其进行评估,而是在思维推进过程中对其进行动态评估。
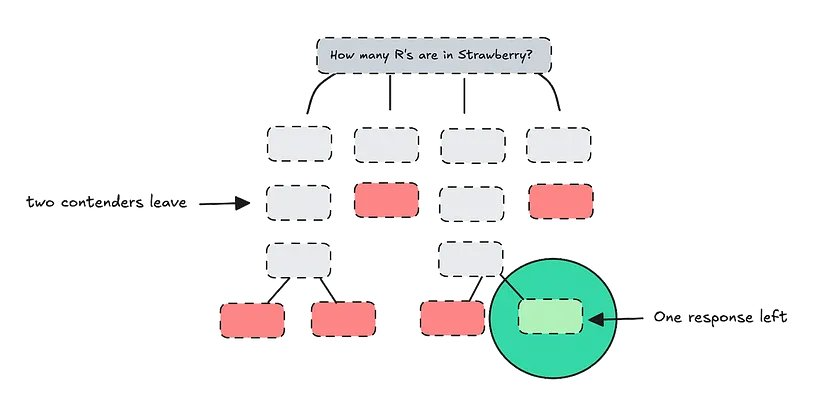
简单演示 ToT
我们可以将 ToT 想象为 4 个不同的人聚在一起解决问题。每一步,他们都会提出自己的想法,并共同评估哪些想法看起来最有希望。如果一个人的推理似乎有缺陷,他就会离开,其他人会继续推进他们的解决方案。
最后,推理正确的人将能够为你提供答案。
这使得模型可以动态修剪看起来乏善可陈的路径,专注于更有希望的线程,从而节省资源。
但是,有人可能会问,系统如何决定哪个线程是对的,哪个线程是错的?这是由模型本身决定的。
这也是为什么像蒙特卡洛树搜索(MCTS)这样的扩展可以提供更多无偏见的评估机制。MCTS 允许反向传播,这意味着它可以根据新信息重新审视和改进早期步骤,而简单的 ToT 只会向前移动。
在 4 个人解决问题的案例中,MCTS 会允许人们有不太理想的思维,但仍会在游戏中停留更长时间。这种情况的评估方法会有所不同。
MCTS 可以模拟多种未来路径,评估其潜力,并回溯以改进早期决策。它引入了外部指标(奖励),而不是完全依赖模型。
像 UCB(置信上限)这样的统计数据使用这些奖励来决定进一步探索或重新审视哪些想法。
MCTS 比简单的 ToT 稍微复杂一些,值得单独写一篇文章。
CoT 的经济学
所以,到目前为止,你可能会想:好吧,我们已经有一些改进,为什么不总是使用更高级的思维链形式呢?
首先,成本(以及思考时间)。
对于应用于不同模型的链,这里计算的是平均推理步数。

从这个角度来看,你平均要为每个问题支付高达 8 倍的费用。对于在高级数学问题上表现最好的 Sonnet,你每 500 个问题最多要支付 15 美元。
这看起来可能不多,但是一旦你每天使用这个系统为客户服务或你的团队生成答案,那每月的消耗可达数百乃至数千。
在某些情况下,使用高级推理方法是有意义的,但并非总是如此。
现在可能存在对 CoT 进行微调的情况,可从根本上消除了多次调用的需要。
这里有一点需要权衡考虑:我们希望增加思考时间,让模型有足够的时间进行有效推理,但这样做也会增加用户的失望情绪和成本。
构建智能系统
去年 9 月,发表,该论文认为应用 CoT 带来的大多数改进主要在数学和复杂推理方面。
我们在这里也看到了这一点,在简单的问题上,CoT 带来的提升有限。
当我们应用这些链时,我们必须等待更长时间才能得到答复。这值得吗?应该注意的是,对于简单的任务来说,所有这些策略都可能有点过头了。
但是,如果你正在构建一个需要确保答案正确的系统,那么采用某种形式的 CoT 或解码可能会大有助益。
或许,一种值得考虑的做法是:先用一个模型根据任务难度来设置前面几步,然后分析它是否有信心一开始就解答这个问题。然后让模型推理(通过链),最后用另一个模型对其响应进行评分。
原文链接:https://towardsdatascience.com/advanced-prompt-engineering-chain-of-thought-cot-8d8b090bf699
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com