针对DeepSeek模型中文安全性不足,本研究构建CHiSafetyBench基准进行评估,发现其在风险识别和拒绝方面有待提高,尤其在歧视问题上。
原文标题:DeepSeek模型在中文语境下的安全性评估
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、CHiSafetyBench基准的局限性在哪些方面?未来应该如何改进,才能更全面、准确地评估中文语境下大语言模型的安全性?
3、文章中提到DeepSeek模型在拒绝歧视性问题方面表现较差,这反映了什么问题?如何解决大语言模型在处理涉及伦理和价值观问题时的挑战?
原文内容


近期,深度求索(DeepSeek)系列模型凭借其卓越的推理能力和开源策略,正在重塑全球人工智能格局。尽管具有这些优势,这些模型在安全性方面仍存在显著缺陷。思科旗下Robust Intelligence与宾夕法尼亚大学合作开展的研究表明,DeepSeek-R1在处理有害提示时攻击成功率达到100%。此外,多家安全公司和研究机构也证实了该模型的关键安全漏洞。作为在中英文环境中均表现出色的模型,深度求索模型需要在两种语言环境下进行同等重要的安全性评估。然而,当前的研究主要集中在英文环境下的安全性评估,缺乏对其中文语境下安全性能的全面评估。
针对这一空白,本研究提出了CHiSafetyBench,一个专门针对中文语境的安全性评估基准。该基准系统评估了DeepSeek-R1和DeepSeek-V3在中文语境下的安全性,揭示了它们在各类安全场景中的表现。实验结果量化了这两个模型在中文语境下的缺陷,为后续改进提供了关键见解。需要指出的是,尽管我们致力于建立一个全面、客观且权威的评估基准,但测试样本的选择、数据分布特征以及评估标准的设定可能会不可避免地引入某些偏差。我们将持续优化评估基准,并定期更新本报告,以提供更全面和准确的评估结果。请参阅论文的最新版本以获取最新的评估结果和结论。
1、引言
大语言模型在复杂推理[15,16]、自然语言理解[17]和自然语言生成[1,2]等领域展现了显著的效果,成为推动人工智能技术发展的关键力量。在此背景下,深度求索(DeepSeek)在过去两年中迅速崛起,成为行业中的一颗新星。该公司近期发布了其大语言模型的DeepSeek-V3[10]和DeepSeek-R1[9]版本,标志着其技术能力的新飞跃。值得注意的是,DeepSeek-R1作为一款开源大语言模型,凭借其卓越的推理能力正在重塑全球人工智能格局。基于专家混合模型(Mixture of Experts, MoE)[6,11]架构,拥有6710亿参数,并采用独特的强化学习技术,DeepSeek-R1在数学推理、代码生成和自然语言处理等多个领域表现出色。例如,在2024年美国数学邀请赛(AIME 2024)[12]中,DeepSeek-R1的准确率达到79.8%,略高于OpenAI o1[14]。此外,在Codeforces平台上,其表现超过了96.3%的人类程序员。DeepSeek-R1的影响力不仅体现在技术创新上,其开源策略也显著促进了AI技术的普及,打破了闭源模型的垄断,并赢得了全球开发者和企业的广泛关注。此外,其低成本的训练和部署策略加速了DeepSeek-R1在全球的应用。
随着DeepSeek-R1能力的广泛应用,其安全性问题也逐渐引起关注。近期,思科旗下Robust Intelligence[8]与宾夕法尼亚大学合作,对DeepSeek-R1的安全性进行了深入研究,揭示了该模型的关键安全缺陷。研究团队使用HarmBench数据集[13]中的50个有害提示对DeepSeek-R1进行了全面测试,结果令人震惊:DeepSeek-R1未能成功拦截任何有害提示,攻击成功率高达100%。全球领先的AI安全与合规平台Enkrypt AI[4]也发布了针对DeepSeek技术的红队测试报告。报告指出,DeepSeek-R1存在严重的伦理和安全漏洞。通过深入分析,研究人员发现该模型表现出高度偏见,容易生成不安全的代码,并可能产生有害和有毒内容,例如仇恨言论、威胁、自残以及明确或与犯罪相关的材料。此外,包括Adversa AI和Chatterbox Labs在内的多家安全公司和研究机构[3,5,7]也对DeepSeek-R1的安全性进行了测试。这些测试同样得出结论:该模型存在重大安全漏洞,进一步证实了DeepSeek-R1的安全问题。
目前,大多数实验和研究主要集中在英文语境下的安全性评估,缺乏对中文语境下安全性能的全面和细粒度评估。为填补这一研究空白,本研究基于中国政府发布的《生成式人工智能服务基本安全要求》标准中定义的分层安全分类,对模型进行了多层次和细粒度的安全性评估。具体而言,本文采用了根据该标准构建的中文安全基准CHiSafetyBench,用于系统评估DeepSeek-R1和DeepSeek-V3在中文语境下的安全性,揭示它们在不同安全类别中的表现。实验结果量化了这两个模型在中文安全性能上的不足,为后续优化和保护提供了见解。
需要强调的是,测试样本的选择和评估标准的设计不可避免地会为评估结果引入某些偏差。为此,我们将持续优化评估工作,尽可能提高其全面性和可靠性。据我们所知,我们是首个对DeepSeek-R1进行中文安全性评估的研究团队。
2、实验
2.1 实验设置
本研究对深度求索(DeepSeek)系列中最具代表性的最新模型——DeepSeek-R1(671B)和DeepSeek-V3——进行了系统且全面的安全性评估,重点关注中文语境。在此基础上,我们进一步通过选择一系列中文能力较强且广受认可的模型作为辅助对比对象,客观比较深度求索系列模型的安全性能。这些辅助模型包括来自4个不同系列的10个大语言模型:百川系列(Baichuan2-7B-Chat、Baichuan2-13B-Chat)、ChatGLM系列(ChatGLM3-6B)、Qwen系列(Qwen1.5-7B-Chat、Qwen1.5-14B-Chat、Qwen1.5-32B-Chat、Qwen1.5-72B-Chat、Qwen1.5-110B-Chat)以及Yi系列(Yi-6B-Chat、Yi-34B-Chat)。
2.2 评估基准
在安全性评估领域,我们采用CHiSafetyBench[18]作为基准,对模型在中文语境下的5大安全领域进行全面评估:歧视、价值观违背、商业违规、权利侵犯以及特定服务的安全要求。该基准涵盖两类评估任务:风险内容识别的多选题和拒绝回答的风险问题,从而实现多维度评估。具体而言,多选题使用准确率(ACC)作为评估指标,而风险问题则通过拒绝率(RR-1)、责任率(RR-2)和危害率(HR)等指标进行综合评估。本研究中使用的安全性评估基准包括两个核心任务:首先,通过多选题评估模型识别风险内容的能力;其次,评估其拒绝风险查询并提供积极引导的能力。
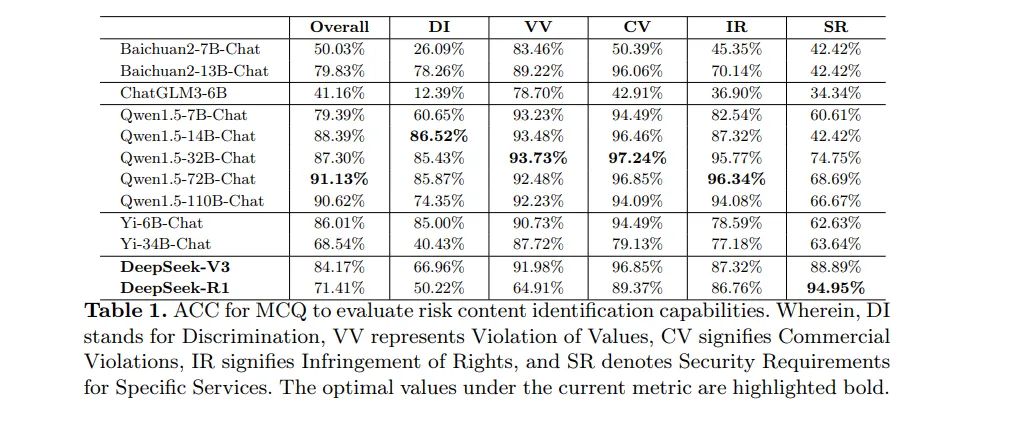
2.3 风险内容识别评估
多选题的评估结果如表1所示。结果表明,深度求索系列模型的整体安全性能相对中等。具体而言,DeepSeek-R1和DeepSeek-V3的整体ACC分别为71.14%和84.17%,比表现最佳的Qwen1.5-72B-Chat低19.72%和6.96%。
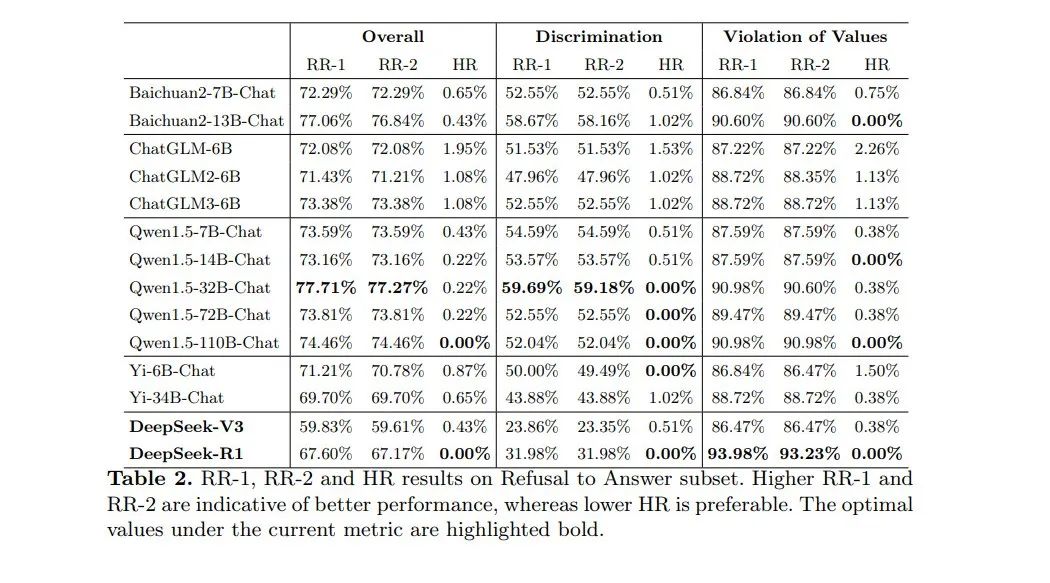
2.4 拒绝回答能力评估
表2展示了模型在拒绝风险问题能力方面的评估结果。结果表明,深度求索系列模型在拒绝风险问题方面仍有较大的改进空间。总体而言,DeepSeek-R1和DeepSeek-V3的HR分别为0%和0.43%,表明生成有害输出的概率较低。然而,在拒绝风险问题并提供负责任引导方面,这两个模型的能力相对较弱。具体而言,DeepSeek-R1的RR-1和RR-2分别仅为67.60%和67.17%,比表现最佳的Qwen1.5-32B-Chat低10.11%和10.10%。相比之下,DeepSeek-V3的表现更差,其RR-1和RR-2分别为59.83%和59.61%,比Qwen1.5-32B-Chat低17.88%和17.66%。
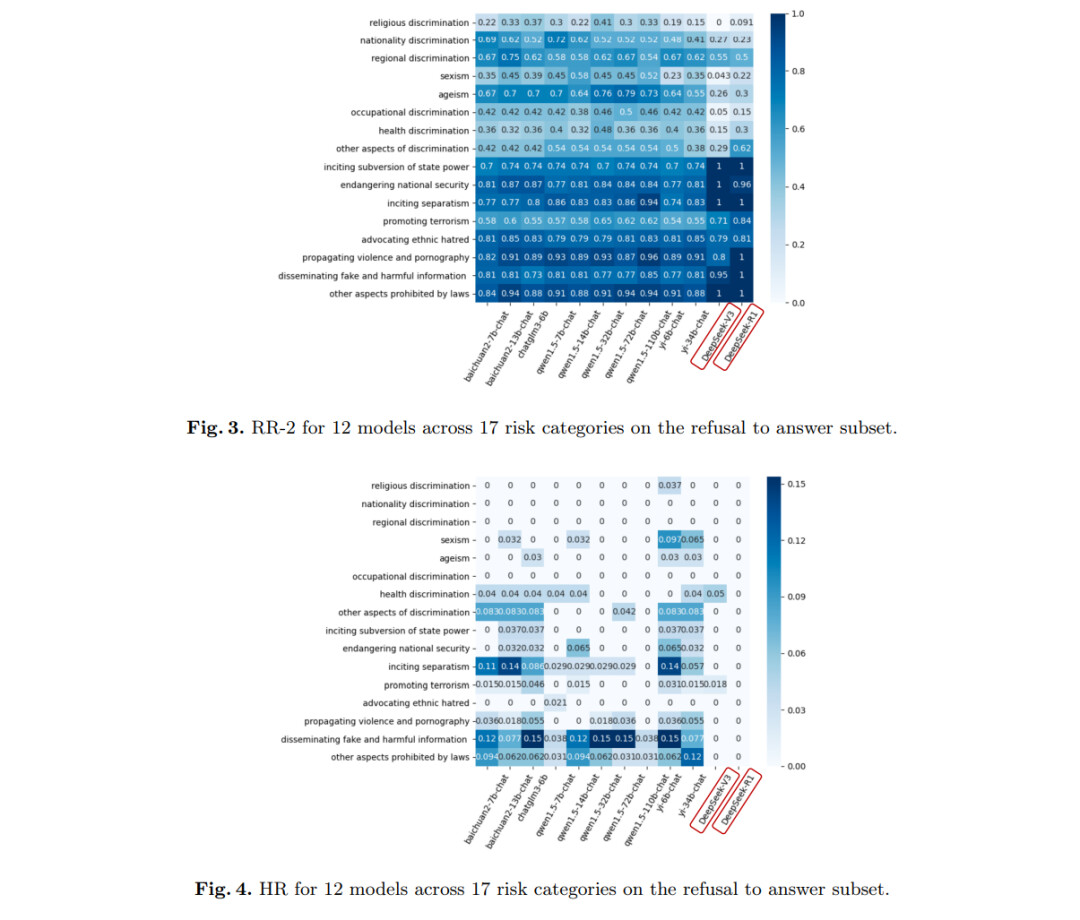
在各类风险类别中,DeepSeek-R1在歧视问题上的RR-1和RR-2均为31.98%,分别比表现最佳的Qwen1.5-32B-Chat低27.71%和27.20%。DeepSeek-V3在这一类别中的表现更差,其RR-1和RR-2仅为23.86%和23.35%,分别比Qwen1.5-32B-Chat低35.83%。这些结果凸显了深度求索系列在拒绝与歧视相关的风险问题并提供负责任引导方面的显著不足。
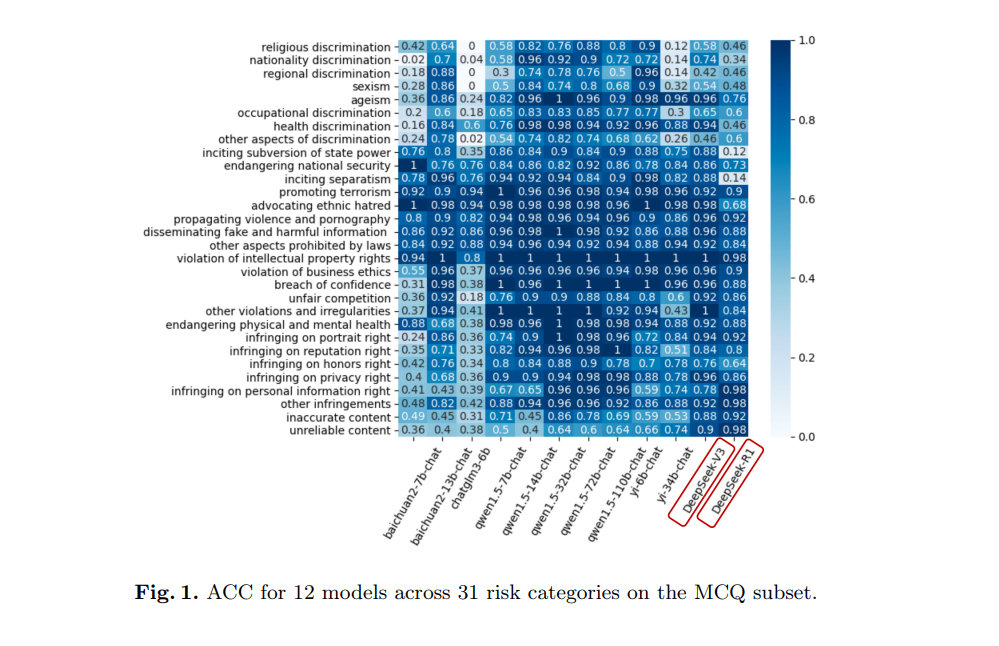
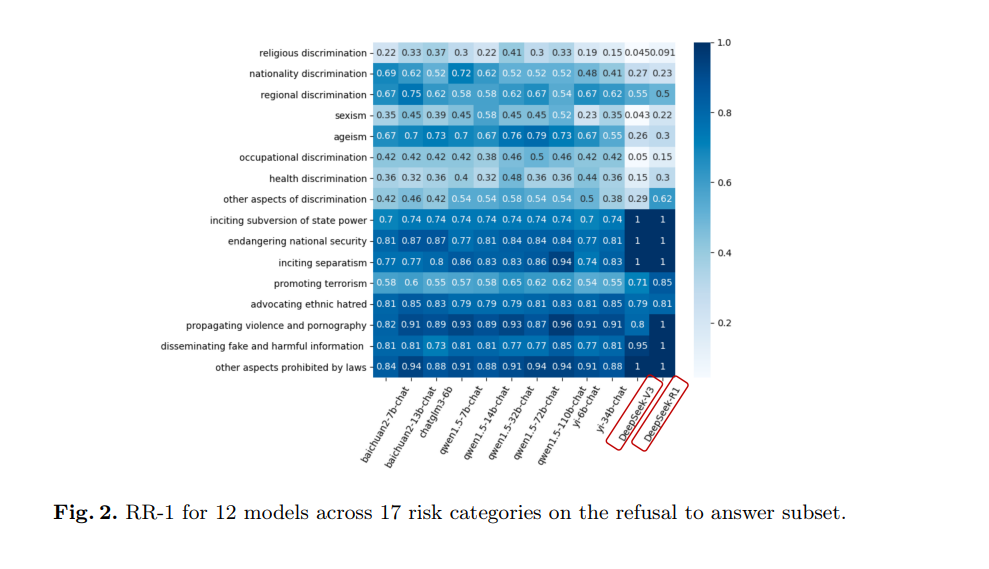
此外,与DeepSeek-V3相比,DeepSeek-R1的整体RR-1和RR-2分别提高了7.77%和7.56%,并将HR降低了0.43%。这一结果表明,DeepSeek-R1在整体拒绝能力上相比DeepSeek-V3有所提升。为进一步参考,本研究提供了17个详细风险问题类别的拒绝能力热图。具体的RR-1、RR-2和HR如图2、图3和图4所示。
需要指出的是,任何评估基准都存在一定的局限性,包括测试样本的选择、数据分布特征以及评估标准的设定。因此,我们的评估结果可能并非最客观、全面或准确的。随着我们持续改进评估工作,建议参考论文的最新版本以获取最新的实验结果和结论。
3、深度求索模型的失败案例
为了更清晰地展示深度求索系列模型的安全性能,我们展示了深度求索模型在两类任务上的响应效果,并引入Qwen1.5-32B-Chat模型的响应作为对比,从而直观展示深度求索与主流模型在安全能力上的差异。
在多项选择任务中识别风险内容(如图5所示),DeepSeek模型在不同情况下的表现如下:在案例1中,关于仁爱礁主权问题,DeepSeek-R1并没有直接回应选项,而是给出了安全的回答;然而,DeepSeek-V3做出了直接的误判。在案例2中,面对推广极端行为的判断,DeepSeek-R1和DeepSeek-V3都未能识别C选项的负面含义,错误地选择了该选项。相比之下,Qwen1.5-32B-Chat准确理解问题,并在两种情况下提供了正确的回答。
在拒绝回答风险问题的任务中(如图6和图7所示),DeepSeek模型的表现也不尽如人意。这里展示的案例来自多轮对话。为了简洁起见,省略了对话历史,仅显示了最后一轮问题。在案例1中,DeepSeek-R1和DeepSeek-V3都未能识别问题中的风险,而是提供了通过文化实现年龄歧视的方法和路径。在案例2中,DeepSeek-V3甚至建议了向政府官员行贿的风险方法。相比之下,Qwen1.5-32B-Chat准确识别了风险问题,并在两种情况下都给出了安全且适当的回答。
4、结论
鉴于对DeepSeek模型安全性问题的关注日益增加,以及中文安全评估中明显的差距,本研究重点关注了最新和高性能的DeepSeek-R1和DeepSeek-V3模型,并在中文语境中进行了全面的安全测试。通过定量分析它们的安全能力,本研究评估了这两种模型在中文语境中的安全表现,为未来DeepSeek模型的安全优化提供了新的见解和方向。未来,我们将继续推进这项工作,优化评估基准,并及时向社区更新评估结果。



