YOLOE实现了实时、统一的开放世界物体检测与分割,支持文本、视觉和无提示等多种模式,像人眼一样观察一切。
原文标题:YOLOe问世,实时观察一切,统一开放物体检测和分割
原文作者:机器之心
冷月清谈:
怜星夜思:
2、YOLOE 集成了检测和分割功能,这在工程实现上会带来哪些挑战?在哪些应用场景下,同时进行检测和分割更有优势?
3、YOLOE 在多种任务和数据集上都表现出良好的性能,你认为它距离真正“像人眼一样观察一切”还有哪些差距?
原文内容
机器之心报道
机器之心编辑部
它能像人眼一样,在文本、视觉输入和无提示范式等不同机制下进行检测和分割。
自 2015 年由华盛顿大学的 Joseph Redmon 研究团队提出 YOLO(You Only Look Once)以来,这项突破性的目标检测技术就像为机器装上了「闪电之眼」,凭借单次推理的实时性能刷新了计算机视觉的认知边界。
传统的 YOLO 系列如同我们人工效准的精密仪器,其识别能力被严格框定在预定义的类别目录之中,每个检测框的背后,都需要工程师手动输入认知词典。这种预设规则在开放场景中限制了视觉模型的灵活性。
但是在万物互联的时代,行业迫切需要更接近人类视觉的认知范式 —— 不需要预先设定先验知识,却能通过多模态提示理解大千世界。那么如何通过视觉模型来实现这一目标呢?
近来,研究者们积极探索让模型泛化至开放提示的方法,力图让模型拥有如同人眼般的强大能力。不管是面对文本提示、视觉提示,甚至在无提示的情况下,模型都能借助区域级视觉语言预训练,实现对任意类别的精准识别。

-
论文标题:YOLOE:Real-Time Seeing Anything
-
论文地址:https://arxiv.org/abs/2503.07465
-
技术展示页:https://github.com/THU-MIG/yoloe?tab=readme-ov-file#demo
YOLOE 的设计思路
在 YOLO 的基础之上,YOLOE 通过 RepRTA 支持文本提示、通过 SAVPE 支持视觉提示以及使用 LRPC 支持无提示场景。

图 1.YOLOE 的架构
如图 1 所示,YOLOE 采用了典型的 YOLO 架构,包括骨干、PAN、回归头、分割头和对象嵌入头。骨干和 PAN 为图像提取多尺度特征。对于每个锚点,回归头预测用于检测的边界框,分割头生成用于分割的原型和掩码系数。对象嵌入头遵循 YOLO 中分类头的结构,只是最后一个 1× 卷积层的输出通道数从闭集场景中的类数更改为嵌入维度。同时,给定文本和视觉提示,YOLOE 分别使用 RepRTA 和 SAVPE 将它们编码为规范化的提示嵌入 P。
在开放集场景中,文本和对象嵌入之间的对齐决定了识别类别的准确性。先前的研究通常引入复杂的跨模态融合来改进视觉文本表示以实现更好的对齐。然而,这些方法会产生大量的计算开销。鉴于此,作者提出了可重新参数化的区域文本对齐 (RepRTA) 策略,通过可重新参数化的轻量级辅助网络在训练过程中改进预训练的文本嵌入。文本和锚点对象嵌入之间的对齐可以在零推理和传输成本的情况下得到增强。
接下来是语义激活的视觉提示编码器。为了生成视觉提示嵌入,先前的工作通常采用 Transformer 设计,例如可变形注意或附加 CLIP 视觉编码器。然而,由于运算符复杂或计算要求高,这些方法在部署和效率方面带来了挑战。
考虑到这一点,研究人员引入了语义激活的视觉提示编码器(SAVPE)来高效处理视觉提示。它具有两个解耦的轻量级分支:(1) 语义分支在 D 通道中输出与提示无关的语义特征,而无需融合视觉提示的开销;(2) 激活分支通过在低成本下在更少的通道中将视觉提示与图像特征交互来产生分组的提示感知权重。然后,它们的聚合会在最小复杂度下产生信息丰富的提示嵌入。
在没有明确指导的无提示场景中,模型需要识别图像中所有有名称的物体。先前的研究通常将这种设置表述为生成问题,使用语言模型为密集的发现物体生成类别。然而,其中语言模型远不能满足高效率要求。YOLOE 将这种设置表述为检索问题并提出惰性区域提示对比(Lazy Region-Prompt Contrast,LRPC)策略。它以高效的方式从内置的大型词汇表中惰性检索带有物体的锚点的类别名称。这种范例对语言模型的依赖为零,同时具有良好的效率和性能。
实验结果
那么在实验测试中,YOLOE 的效果如何呢?
作者将 YOLOE 基于 YOLOv8 和 YOLOv11 架构开展了实验,并提供了不同的模型尺度。如下表所示,对于 LVIS 上的检测,YOLOE 在不同模型尺度上表现出效率和零样本性能之间的良好平衡。

表 1. LVIS 上的零样本检测评估
实验结果表明 YOLOE 的训练时间少于其他对比模型,比 YOLO-Worldv2 快了近 3 倍。同时 YOLOE-v8-S/M/L 的性能比 YOLOv8-Worldv2-S /M/L 分别高出 3.5/0.2/0.4AP,在 T4 和 iPhone 12 上的推理速度分别提高 1.4 倍 / 1.3 倍 / 1.3 倍和 1.3 倍 / 1.2 倍 / 1.2 倍。
不过在 Ap 指标上,与 YOLO - Worldv2 相比,YOLOE-v8-M/L 稍显逊色。进一步分析发现,这种性能差距主要是由于 YOLOE 创新性地在一个模型中集成了检测和分割功能。
作者还通过以下角度验证了模型和方法的有效性:
-
分割评估
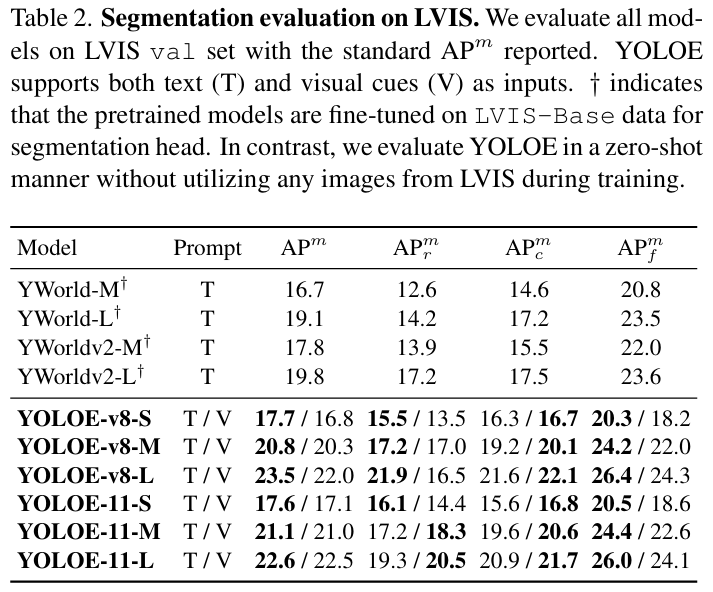
表 2. LVIS 上的分割评估
-
无提示词评估

表 3. LVIS 上的无提示词评估
-
可迁移性评估

表 4. 在 COCO 上的可迁移性测试,测试了两种微调策略,线性探测和完全调整
这些结果充分证明,YOLOE 拥有强大的功能和高效率,适用于各种提示方式,可以实时看到任何东西。

此外,研究人员对 YOLOE 开展了四种场景的可视化分析:
-
图 (a):在 LVIS 上进行零样本推理,以类别名称作为文本提示
-
图 (b):可输入任意文本作为提示
-
图 (c):能绘制视觉线索作为提示
-
图 (d):无明确提示,模型自动识别所有对象
结果显示,YOLOE 在这些不同场景下均表现出色,能准确检测和分割各类物体,进一步体现了其在多种应用中的有效性与实用性。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com