使用Higress AI网关无缝切换QwQ-32B和DeepSeek-R1大模型,降低成本,提升效率。支持多模型服务、鉴权、限流等进阶功能,解决大模型应用难题。
原文标题:大模型无缝切换,QwQ-32B和DeepSeek-R1 全都要
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、Higress AI网关支持多模型自动切换,当一个模型出现故障时可以Fallback到其他模型。在实际应用中,如何评估Fallback模型的性能是否满足要求,以及如何避免Fallback模型也被打爆的情况?
3、文章提到了AI网关可以进行内容安全和合规性审核,那么在实际应用中,如何平衡内容审核的严格性和用户体验?过度严格的审核可能会导致误判,影响用户正常使用。
原文内容
近期,通义千问发布了最新推理模型 QwQ-32B。在各类基准测试中,拥有 320 亿参数的 QwQ 模型,其性能可与具备 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1 媲美。这意味着:
-
个人用户可以在更小的移动设备上、本地就能运行
-
企业用户推理大模型 API 的调用成本,可再降90%以上
📊 价格对比:
🔹 QwQ-32B:$0.20/M 输入, $0.20/M 输出
如果是通过云上自建(通过阿里云 PAI/ACS 等)的方式,例如阿里云 PAI:
🔹 DeepSeek R1:至少 2 台 8 卡 H20,100w+ / 年
🔹 QwQ-32B:1 台 单卡 H20,5w+ / 年

一、完整实现步骤
1. 环境准备
# 一键安装Higress(需Docker环境)
curl -sS https://higress.cn/ai-gateway/install.sh | bash
安装完成后访问控制台 http://localhost:8001,完成初始化配置。
2. 模型接入配置
-
在 Higress 控制台分别配置 DeepSeek-R1 和 QwQ-32b 的接入方式:

如果是对接厂商的模型,可以通过选择厂商名进行配置,例如:

如果是对接自建的模型,可以使用 OpenAI 兼容模式,填入 baseURL 即可:

-
在 Higress 控制台创建路由,按照匹配模型名称的路由规则转发给两个不同的模型

例如 my-qwq-32b 这条路由,匹配模型名称精确匹配 qwq-32b,转发给自建的 QwQ-32b 模型服务:

my-deepseek-r1 这条路由,匹配模型名称精确匹配 deepseek-r1,转发给自建的 DeepSeek-R1 模型服务:

因为 DeepSeek-R1 需要更多资源,可以使用 AI Token 限流插件对其进行限流:


并在触发限流后,通过模型 fallback 机制兜底到 QwQ-32b 模型:

3. 客户端调用示例(Python)
from openai import OpenAI统一访问Higress网关
client = OpenAI(
api_key=“higress-api-key”, # Higress控制台生成的二次鉴权密钥
base_url=“http://localhost:8080/v1” # Higress网关地址
)去往 deepseek 模型
response_deepseek = client.chat.completions.create(
model=“deepseek-r1”,
messages=[{“role”: “user”, “content”: “解释量子计算”}]
)去往 qwq 模型
response_qwq = client.chat.completions.create(
model=“qwq-32b”,
messages=[{“role”: “user”, “content”: “写一首七言诗”}],
)
4. 对接 QwQ-32b的效果:
QwQ 的 token 输出速度飞快,这是在单卡的h20上的效果:

二、Higress AI 网关的进阶功能
多模型服务只是 Higress AI 网关的基本能力之一,其他进阶能力还包括消费者鉴权、模型自动切换等,可以集中解决用户遇到的以下三类问题:
-
需要在 TPS 和成本之间找到平衡点,不可能无限增加资源
-
没有联网搜索,大模型幻觉依然很大
-
LLM 可观测,应用、网关、后端 LLM 服务的全链路,贴合 LLM 推理的指标
我们将 AI 网关的其他能力,汇总如下。



1. 多模型服务
大模型不存在一家独大,企业往往会实施多模型策略。企业员工在前端选择大模型,可以随意切换后端的大模型服务,例如企业内部可以部署 DeepSeek、Qwen、自建等多个大模型,由员工自行选择,以获得更加丰富、可选的生成效果。企业越是多元化,对多模型服务的需求越强烈。
需求场景:
-
多模态业务整合场景,企业需同时处理文本、图像、音频、3D 等多模态数据。研发、产品团队对推理能力强的模型需求多;客服、营销、平面设计等团队对图片大模型的场景需求多;工业设计、影视制作团队对音视频大模型的场景需求多。
-
企业业务覆盖多个垂直领域,需针对不同行业特性调用专用模型。尤其是供应链端的企业往往服务多个行业,可能会涉及多款垂直行业的大模型需求。
-
复杂任务协同场景,单一任务需多个模型分工协作以提升效果。多个大模型员工协同生成内容才能起到最佳效果。
-
安全与效率双重要求场景,例如医疗机构的场景,处理患者数据使用专属私有模型分析,其他和患者无关的需求使用通用模型,避免敏感数据和非敏感数据在写入数据库混存。

应对方案:AI 网关支持基于模型名称做不同后端模型的切换,实现同一个接口对接多种大模型服务,这些大模型服务可以分别部署在不同的平台,例如百炼、PAI、IDC 自建等,即便不同模型隶属于不同的开发和运维团队,也不存在协作成本。
2. 消费者鉴权
需求场景:
多租户模型服务分租场景:企业为不同部门或团队提供共享的大模型服务时,会通过 API Key 区分租户,确保数据隔离和权限管控。具体要求包括:
-
为每个租户分配独立 API Key,控制其调用权限和资源配额度,例如部门 A 的调用资源配额是每天每人20次,部门 B 的调用资源配额是每天每30次。
-
支持租户自定义模型参数(如温度系数、输出长度),但需通过网关校验权限。
企业内部权限分级管控:企业内部不同角色需差异化访问模型能力。具体要求包括:
-
基于 RBAC(基于角色的访问控制)限制敏感功能(如模型微调、数据导出)。
-
出于成本考虑,多模态大模型只供设计部门调用。
-
记录操作日志并关联用户身份,满足内部审计需求。例如,金融企业限制风险评估模型仅限风控部门调用,防止普通员工滥用。

实现方案:
AI 网关支持路由配置认证和消费者鉴权,实现对 API 访问的控制、安全性和策略管理,通过 API Key 的生成、分发、授权、开启授权、验证 API Key 的流程,确保只有授权的请求才能访问服务。
-
身份可信:确保请求方为注册/授权用户或系统。
-
风险拦截:防止恶意攻击、非法调用与资源滥用。
-
合规保障:满足数据安全法规及企业审计要求。
-
成本控制:基于鉴权实现精准计费与 API 配额管理。
3. 模型自动切换
需求场景:
-
模型自身特性引发的异常:大模型生成结果存在概率性波动,导致存在随机性输出不稳定的情况;发布新版本导致的流量有损。
-
用户使用不规范导致的异常:使用者请求参数不符合 API 规范,导致连接超时或中断,或者输入包含恶意构造的提示词,触发模型安全防护机制,返回空结果或错误码。
-
资源与性能限制:请求频次过高 ,触发限流策略,导致服务不可用,长请求占用过多内存,导致后续请求被阻塞,最终导致超时。
-
依赖服务故障 :外部 API,例如 RAG 检索的数据库不可用,导致模型无法获取必要上下文。

实现方案:AI 网关支持当某个大模型服务请求失败后,Fallback 到指定的其他大模型服务,以保证服务的健壮性和连续性。
4. Token 级限流
需求场景:
虽然企业内部使用,不会频繁存在并发的需求,但通过设置限流能力,可以更经济的配置硬件资源。例如一家10000人的企业,不需要配置同时支持10000人上线的硬件资源,只需要配置7000人的硬件资源,超出部分进行限流,避免资源闲置。其他需求包括:
-
提升资源管理:大模型对计算资源的消耗不可控,限流可以防止系统过载,确保所有用户都能获得稳定性能,尤其在高峰期。
-
指定用户分层:可以基于 ConsumerId 或者 API Key 进行 Token 限流。
-
防止恶意使用:通过限制 Token 数量来减少垃圾请求或攻击,以免受到资损。

应对方案:
AI 网关提供了 ai-token-ratelimit 插件,实现了基于特定键值的 token 限流,键值来源可以是 URL 参数、HTTP 请求头、客户端 IP 地址、consumer 名称、cookie 中 key 名称。
5. 内容安全和合规
需求场景:
企业内是严肃的工作场景,自建大模型需要对生成内容进行安全和合规保证,包括过滤掉有害或不适当的内容,检测和阻止包含敏感数据的请求,并对 AI 生成内容进行质量和合规性审核。
-
金融行业敏感数据处理:审核用户输入的金融交易指令、投资咨询内容,防范欺诈、洗钱等违规行为。
对模型生成的财务报告、风险评估结果进行合规性校验。 -
医疗健康信息交互:电子病历生成内容,防止泄露患者隐私(如身份证号、诊断记录),确保 AI 生成的医疗建议符合相关法规。通过多模态大模型识别医疗影像中的敏感信息,并结合合规规则库进行自动化拦截。
-
社交媒体与 UGC 内容管理:实时审核用户发布的图文、视频内容,拦截涉黄、暴恐、虚假信息。对 AI 生成的推荐内容(如短视频标题、评论)进行合规性检查。
-
政务服务平台交互:审核公众提交的政务咨询内容,防止恶意攻击或敏感信息传播,确保 AI 生成的政策解读、办事指南符合相关法规。
-
电商与直播平台风控:审核商品描述、直播弹幕内容,拦截虚假宣传、违禁品信息,对 AI 生成的营销文案进行广告法、合规性检查。

应对方案:
AI 网关接入了阿里云内容安全,对面向大语言模型的输入指令和生成文字分别提供审核服务。包括:
-
防止攻击:验证输入可以阻止恶意提示注入,防止模型生成有害内容。
-
维护模型完整性:避免输入操纵模型,导致错误或偏见输出。
-
用户安全:确保输出没有有害或误导性内容,保护用户免受不良影响。
-
内容适度:过滤掉不适当的内容,如仇恨言论或不雅语言,特别是在公共应用中。
-
法律合规:确保输出符合法律和伦理标准,尤其在医疗或金融领域。
6. 语义缓存
需求场景:
大模型 API 服务定价分为每百万输入 tokens X 元(缓存命中)/ Y 元(缓存未命中),X 远低于 Y,以通义系列为例,X 仅为 Y 的40%,通过在内存数据库中缓存大模型响应,并以网关插件的形式来改善推理的延迟和成本。在网关层自动缓存对应用户的历史对话,在后续对话中自动填充到上下文,从而实现大模型对上下文语义的理解。例如
-
高频重复性查询场景:客服系统、智能助手等场景中,用户常提出重复问题(如“如何重置密码”“退款流程”),通过缓存常见问题的回答,避免重复调用模型,降低调用成本。
-
固定上下文多次调用场景:法律文件分析(如合同条款解读)、教育教材解析(如知识点问答)等场景,需对同一长文本多次提问。通过缓存上下文,避免重复传输和处理冗余数据,提升响应速度,降低调用成本。
-
复杂计算结果复用场景:数据分析与生成场景(如财报摘要、科研报告生成),对相同数据集的多次分析结果缓存,避免重复计算。
-
RAG(检索增强生成)场景中:缓存知识库检索结果(如企业内部 FAQ),加速后续相似查询的响应。
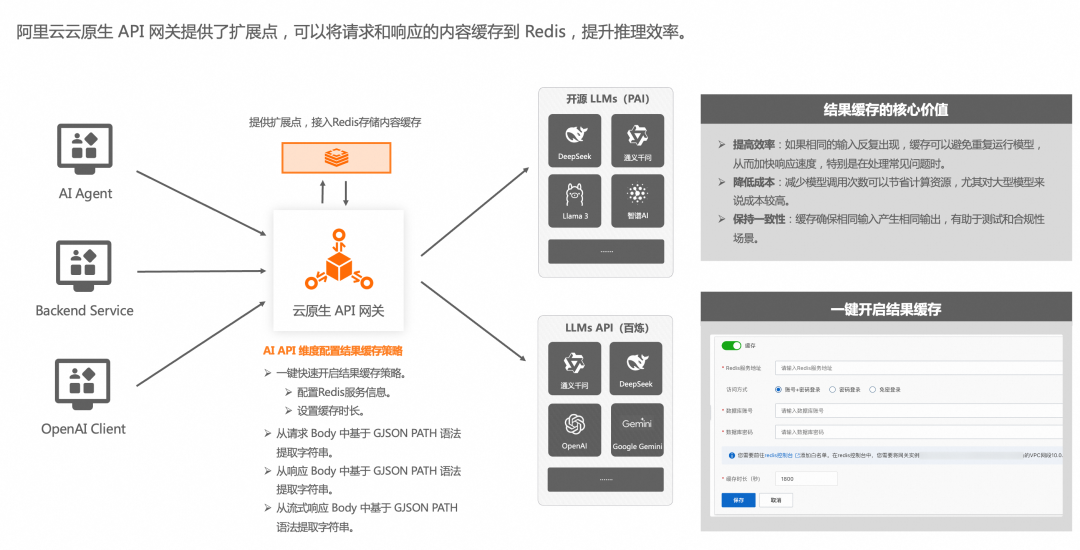
应对方案:
AI 网关提供了扩展点,可以将请求和响应的内容缓存到 Redis 中,并支持配置 Redis 服务信息、设置缓存时间。
7. 联网搜索+获取检索网页的全文
需求场景:
联网搜索已经成为大模型的标配。如果不支持联网搜索,或者支持联网搜索,仅能获取网页标题、摘要、关键词而非全文,内容生成效果都会大打折扣。

应对方案:
AI 网关通过以下增强,实现了联网搜索+获取检索网页的全文:
-
LLM 重写 Query:基于 LLM 识别用户意图,生成搜索命令,可以大幅提升搜索增强效果。
-
关键词提炼:针对不同的引擎,需要生成不同的提示词,例如 Arxiv 里英文论文居多,关键词需要用英文。
-
领域识别:以 Arxiv 举例,Arxiv 划分了计算机科学/物理学/数学/生物学等等不同学科下的细分领域,指定领域进行搜索,可以提升搜索准确度。
-
长查询拆分:长查询可以拆分为多个短查询,提高搜索效率高质量数据:Google/Bing/Arxiv 搜索都只能输出文章摘要,而基于阿里云信息查询服务 IQS 对接 Quark 搜索,可以获取全文,可以提高 LLM 生成内容的质量典型应用场景效果展示。
8. 大模型可观测
需求场景:
可观测常见于成本控制和稳定性场景。由于大模型应用的资源消耗比 Web 应用更加敏感和脆弱,因此成本控制对可观测的需求更为强烈,如果缺少完备的可观测能力,异常掉用可能会耗费几万甚至几十万的资损。
除了QPS、RT、错误率等传统观测指标,大模型的可观测还应具备:
-
基于 consumer 的 token 消耗统计。
-
基于模型的 token 消耗统计。
-
限流指标: 每单位时间内有多少次请求因为限流被拦截,限流消费者统计(是哪些消费者在被限流)。
-
缓存命中情况。
-
安全统计:风险类型统计、风险消费者统计。

应对方案:
AI 网关支持查看网关监控数据,在商业版上开启日志投递、链路追踪、以及如何通过云原生 API 网关查看 REST API 和接口的监控数据。这些功能将帮助您更高效地管理和优化接口性能,同时提升整体服务质量。此外,通过 SLS 还可以汇总 Actiontrail 事件、云产品可观测日志、LLM 网关明细日志、详细对话明细日志、Prompt Trace 和推理实时调用明细等数据汇总,从而建设完整统一的可观测方案。
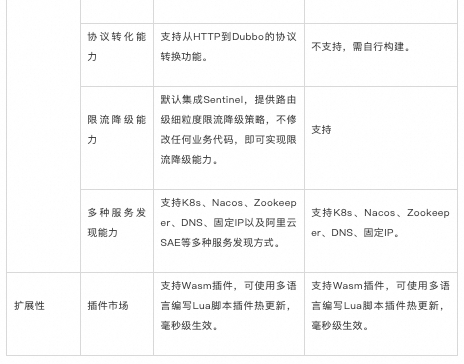
三、Higress AI 网关的商业版服务
如果您已经在阿里云上自建大模型应用,希望快速获取开箱即用的 AI 网关能力,并在性能、稳定性、和阿里云其他云产品有更高的交付标准,可以直接使用阿里云云原生 API 网关,相比开源,云原生 API 网关的优势包括:


零门槛,即刻拥有 DeepSeek-R1 满血版
DeepSeek 是热门的推理模型,能在少量标注数据下显著提升推理能力,尤其擅长数学、代码和自然语言等复杂任务。本方案涵盖云上调用满血版 DeepSeek 的 API 及部署各尺寸模型的方式,无需编码,最快 5 分钟、最低 0 元即可实现。
点击阅读原文查看详情。