传统困惑度(PPL)无法准确评估大模型长文本能力?北大、MIT、阿里提出LongPPL新指标,并通过LongCE损失函数提升模型长文本处理能力。
原文标题:长文本有了专属困惑度!北大、MIT、阿里推出LongPPL新指标
原文作者:机器之心
冷月清谈:
北京大学、MIT、阿里联合研究发现,传统困惑度(PPL)在评估大模型长文本能力时存在局限性,因为它对所有token进行平均计算,未能充分关注对长文本处理性能至关重要的关键token。研究团队通过长-短上下文对比的方法,提出了LSD和LCL指标来定位这些关键token,并在此基础上构建了新的评估指标——长文本困惑度(LongPPL),该指标与模型在长文本任务中的实际表现高度相关。此外,他们还提出了长文本交叉熵损失(LongCE),通过赋予关键token更高的权重,显著提升了模型通过微调增强长文本处理能力的效果。实验证明,LongCE可以与现有的长文本泛化方法无缝结合,具有广阔的应用前景。
怜星夜思:
1、文章提出的LongPPL和LongCE,分别在评估和训练上优化了大模型对长文本的处理。那么,你认为未来在实际应用中,我们应该如何更好地结合这两者,以充分发挥其优势?
2、文章提到,LongCE可以通过赋予关键token更高的权重来优化模型训练。那么,你认为除了调整token的权重之外,还有没有其他方法可以进一步改进长文本模型的训练过程?
3、文章中提到,LongPPL与模型在LongBench任务集上的表现具有高度相关性。那么,你认为LongPPL是否可以完全替代传统的困惑度(PPL)指标?在什么情况下,我们仍然需要使用PPL?
2、文章提到,LongCE可以通过赋予关键token更高的权重来优化模型训练。那么,你认为除了调整token的权重之外,还有没有其他方法可以进一步改进长文本模型的训练过程?
3、文章中提到,LongPPL与模型在LongBench任务集上的表现具有高度相关性。那么,你认为LongPPL是否可以完全替代传统的困惑度(PPL)指标?在什么情况下,我们仍然需要使用PPL?
原文内容

随着大模型在长文本处理任务中的应用日益广泛,如何客观且精准地评估其长文本能力已成为一个亟待解决的问题。
传统上,困惑度(Perplexity, PPL)被视为衡量模型语言理解与生成质量的标准指标——困惑度越低,通常意味着模型对下一个词的预测能力越强。由于长文本可被视为一般文本的扩展,许多研究自然地通过展示模型在长文本上的低困惑度来证明其长文本泛化能力的有效性。但你知道,这个评估方式可能完全错了吗?
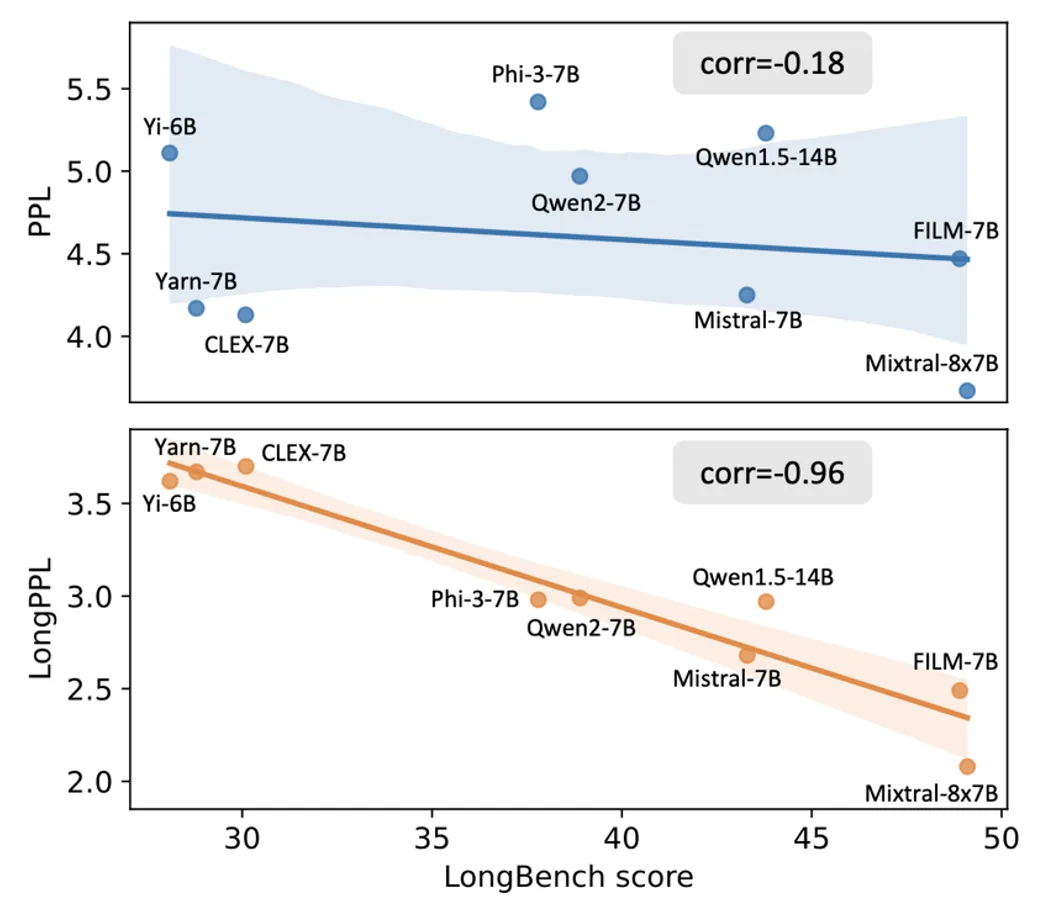
近期研究发现,困惑度在长文本任务中的适用性存在显著局限性:某些在困惑度指标上表现优异的模型,在实际长文本应用中却未能达到预期效果。如图 1(上)所示,在 9 种主流长文本大模型上,困惑度(y 轴)与模型在长文本任务中的真实表现(x 轴)之间的相关性极低。这一反常现象引出了一个关键问题:为何困惑度(PPL)在长文本场景下失效?
针对这一问题,北京大学王奕森团队与 MIT、阿里一道开展了深入研究,探讨困惑度在长文本任务中失效的原因,并提出全新指标 LongPPL,更精准反映长文本能力。
通过实验,他们发现长文本中不同 token 对长距离上下文信息的依赖程度存在显著差异。其中,对长上下文信息依赖较强的 token 在评估模型的长文本处理性能时起到关键作用,但这类 token 在自然文本中只占少数。这表明,困惑度失效的原因在于其对所有 token 进行平均计算,无法充分关注这些与长文本能力关系密切的关键 token。
为此,他们将困惑度的计算限制在长文本的关键 token 上,从而定义出能够反映模型长文本处理能力的长文本困惑度(LongPPL),该指标表现出与长文本任务性能极高的相关性 (如图 1(下))。此外,他们还基于这一设计思想提出长文本交叉熵损失(LongCE),显著提升了模型通过微调增强长文本处理能力的效果。

-
论文题目: What is Wrong with Perplexity for Long-context Language Modeling?
-
论文地址: https://arxiv.org/abs/2410.23771
-
代码地址: https://github.com/PKU-ML/LongPPL
并非所有 token 都反映模型长文本能力
为探讨困惑度在长文本任务中失效的原因,作者首先分析了长文本与短文本在本质上的差异。直观来看,一段文本中不同词语对长距离上下文的依赖程度存在显著差异。例如,在小说中,某个情节的发展可能需要与数章之前埋下的伏笔相呼应,而某些语法上的固定搭配则通常无需依赖较远的上下文。在长文本场景下,这种依赖程度的差异较短文本更为显著。
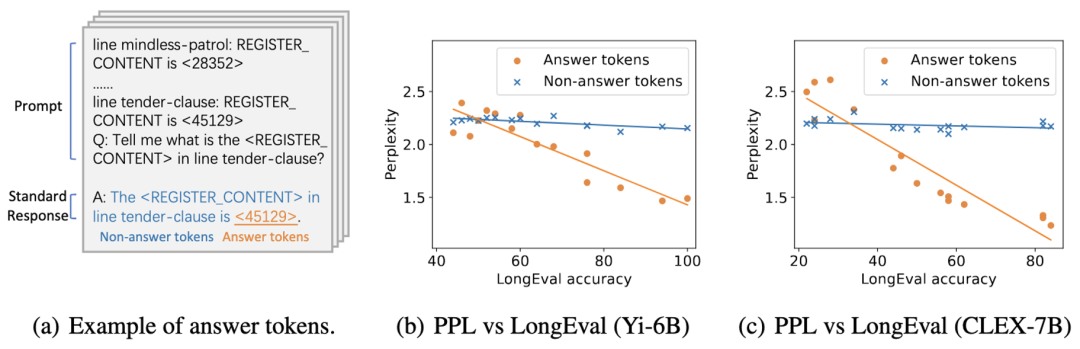
为了量化并验证这一直观认识,本文首先考虑了一个简单的任务场景——LongEval 长文本键值对检索任务(图 2(a))。在此任务中,模型根据问题在长上下文中检索出与给定键相匹配的值。本文将问题的标准回答划分为非答案部分(蓝色)和答案部分(橙色)。显然,非答案部分的生成仅依赖短上下文,即最后的问句内容;而答案部分则需要模型聚焦于完整的长上下文信息。
图 2 (b)(c) 表明,答案部分的困惑度与模型在此任务中的实际表现高度相关,而非答案部分的困惑度几乎与任务表现无关。由此可见,依赖长上下文信息的关键 token 在评估模型的长文本能力时更加重要。
通过长-短上下文对比在自然文本中定位关键 token
在上述结果的启发下,一个自然而然的想法是:若将困惑度指标限定于依赖长上下文信息的关键 token 上,便可更有效地评估模型处理长文本的能力。
然而,实际应用中存在一个挑战:在自然文本中,无法像 LongEval 基准中那样明确标注哪些 token 依赖于长距离上下文,因此迫切需要一种指标来自动识别这些关键 token。
为了解决这一问题,本文提出了一种长-短上下文对比的方法。具体而言,本文将每个 token x_i 的长上下文 l_i=(x_1,…,x_(i-1)) 截断成短上下文 s_i=(x_(i-K),…,x_(i-1)),然后计算模型 θ 在长 / 短上下文下生成同一 token 的(对数)概率差距 (Long-short difference, LSD):
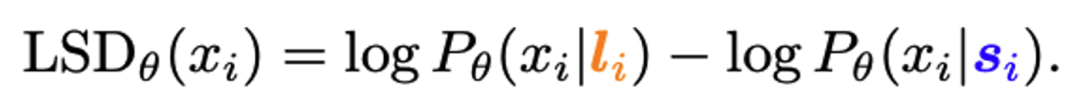
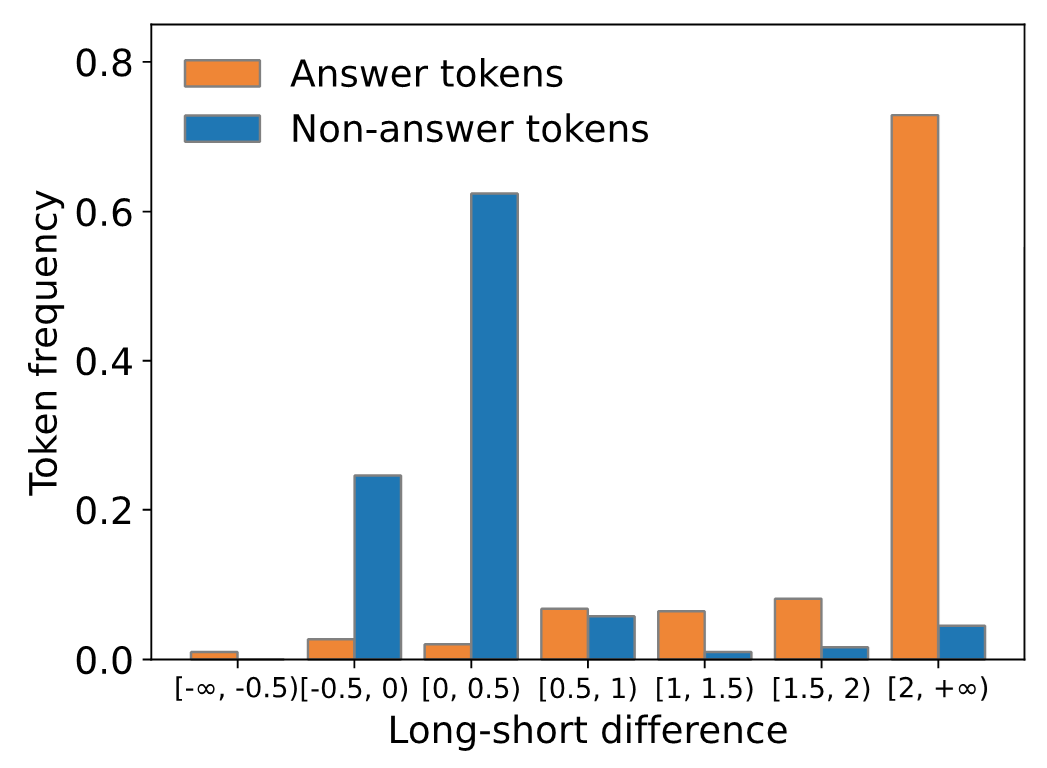
这一指标用于量化长上下文对模型预测准确度的提升。图 3 表明,在 LongEval 任务中,LSD 几乎能够完美区分答案部分和非答案部分。与长上下文信息相关的答案部分 LSD 值普遍大于 2,而与长上下文信息几乎无关的非答案部分 LSD 值普遍在 - 0.5 到 0.5 之间。这一结果初步验证了该指标在定位关键 token 方面的有效性。
此外,本文发现模型基于长文本的(对数)生成概率 (Long-context likelihood, LCL) 也有助于定位关键 token(在此不做展开):
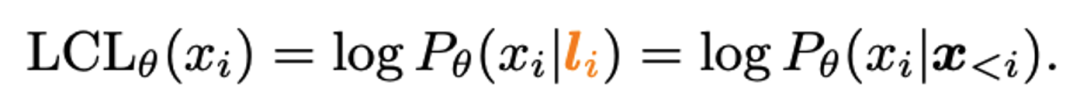
困惑度无法反映模型长文本能力的原因
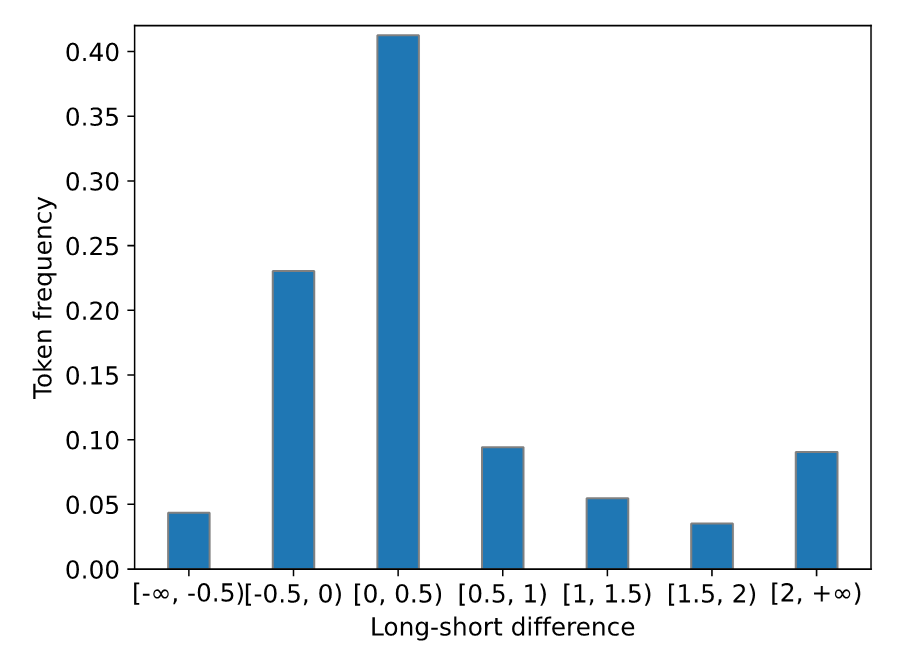
进一步,本文在 GovReport 政府报告数据集上计算了按 LSD 分类的 token 分布。如图 4 所示,大部分 token 的 LSD 集中在 [-0.5, 0.5) 范围内,而 LSD 大于 2 的 token 占比不到 10%。这意味着在自然文本中,只有非常少数的 token 与长上下文中的信息有强相关性,而绝大部分的 token 只需要依赖短上下文的信息即可生成。
这一结果表明,困惑度在长文本上失效的原因在于其对所有 token 进行平均计算,未能充分关注长文本中这些少数的关键token。
长文本困惑度——长文本能力评估指标的改进
基于上述分析,为了克服传统困惑度指标在长文本场景下的局限性,本文提出了一个新的评估指标——长文本困惑度(LongPPL)。具体设计为:
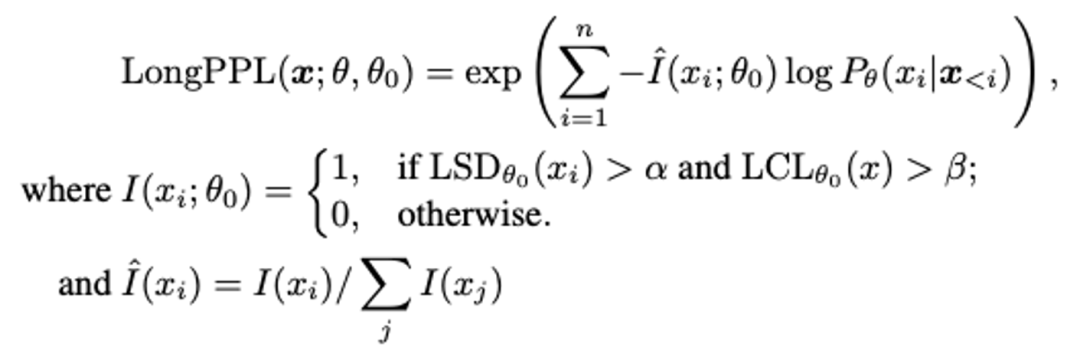
其核心思想在于通过 LSD 和 LCL 指标,将困惑度的计算限制在长文本的关键 token 上,从而聚焦于关键 token 的预测质量,以更准确地反映模型的长文本能力。
实验结果表明,模型在自然文本上的 LongPPL 和长文本任务的实际表现高度相关。如图 1(下)所示,在 GovReport 数据集上,9 个主流长文本大模型的 LongPPL 与在 LongBench 任务集上表现的皮尔逊相关系数达到了 - 0.96。
长文本交叉熵——长文本训练方法的优化
除了用于评估长文本能力外,本文还基于 LongPPL 的思想提出了一种改进的训练损失 —— 长文本交叉熵(LongCE):
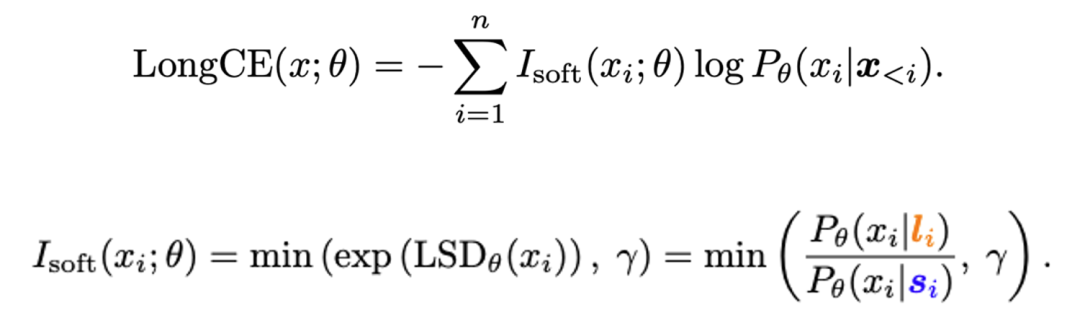
在提升模型长文本能力的微调过程中,LongCE 会赋予关键 token 更高的权重,使得模型在训练中更加聚焦提升这些关键 token 的预测准确性,从而增强模型在长文本任务中的表现。
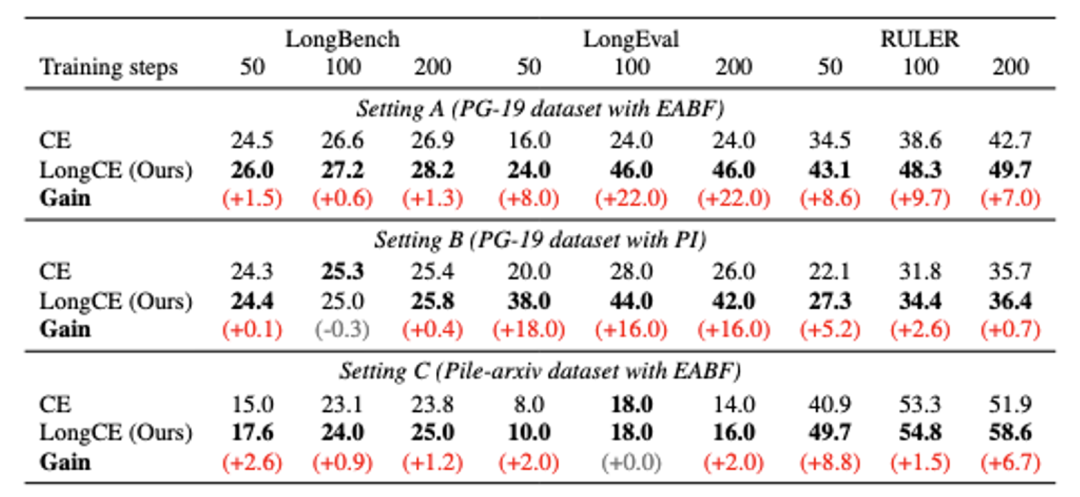
为了验证 LongCE 的有效性,研究团队在 Llama-2-7b 模型的基础上进行了多组对比实验。
实验设计涵盖了不同的训练数据集(包括 PG-19 书籍数据集和 Pile-arxiv 论文数据集)以及不同的训练方法(包括熵感知基调整 EABF 和位置插值 PI,其中 EABF 与 Deepseek-v3 采用的 YaRN 插值方法相似)。实验评估采用了 LongBench、LongEval 和 RULER 这三个广泛使用的长文本测试任务集。
实验结果表明,在各种实验设定下,采用 LongCE 进行微调的大模型在长文本处理能力上均显著优于使用传统交叉熵损失函数进行微调的模型。这表明,不仅是评估,长文本的训练也应根据其特点来设计损失函数,而非简单地沿用短文本场景的损失函数!
值得注意的是,由于当前主流的长文本泛化方法主要集中于模型架构和参数的优化,而未涉及训练损失函数的改进,因此 LongCE 可以与这些方法实现无缝结合,展现出广阔的应用前景和强大的性能提升潜力。
更多文章细节,请参考原文。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com