LightTransfer 通过高效迁移预训练 Transformer 模型,显著缩减推理阶段的 KV 缓存,降本增效。
原文标题:优于o1预览版,推理阶段KV缓存缩减一半,LightTransfer降本还能增效
原文作者:机器之心
冷月清谈:
本文介绍了一种名为 LightTransfer 的方法,旨在将预训练的 dense Transformer 模型高效转换为 hybrid 模型,从而在推理阶段显著减少 KV 缓存的使用。该方法基于观察到的模型中存在的冗余层(lazy 层),将这些层替换为仅需常数大小 KV 缓存的 streaming attention。LightTransfer 分为训练和测试两个阶段:训练阶段(LightTransfer-Train)识别并替换模型中 50% 的 lazy attention 层;测试阶段(LightTransfer-Test)则在推理过程中动态识别和转换 lazy 层,并结合优先队列策略,有效控制 prefilling 阶段的内存峰值。实验结果表明,LightTransfer 在长文本生成和长上下文理解任务中均表现出色,能够在缩减 KV 缓存的同时保持甚至提升模型性能。
怜星夜思:
1、LightTransfer 方法中 lazy ratio 的阈值 50% 是如何确定的?有没有尝试过其他比例,不同的比例会对模型的效果产生什么影响?
2、LightTransfer-Test 中,使用 LSE(log-sum-exp)避免重新计算注意力权重这个思路非常巧妙!但是,这种方法会不会因为精度问题而影响 lazy ratio 的计算结果?有没有其他的优化方案?
3、LightTransfer 主要针对的是长文本生成和长上下文理解任务,那么,这种方法是否适用于其他类型的 NLP 任务,比如文本分类、机器翻译等?如果应用到其他任务中,可能需要做哪些调整?
2、LightTransfer-Test 中,使用 LSE(log-sum-exp)避免重新计算注意力权重这个思路非常巧妙!但是,这种方法会不会因为精度问题而影响 lazy ratio 的计算结果?有没有其他的优化方案?
3、LightTransfer 主要针对的是长文本生成和长上下文理解任务,那么,这种方法是否适用于其他类型的 NLP 任务,比如文本分类、机器翻译等?如果应用到其他任务中,可能需要做哪些调整?
原文内容

LLM 在生成 long CoT 方面展现出惊人的能力,例如 o1 已能生成长度高达 100K tokens 的序列。然而,这也给 KV cache 的存储带来了严峻挑战。为应对这一难题,“hybrid model” 成为了一条备受关注的可行路径:它在标准 transformer 的部分层中引入更高效的注意力机制(如 RNN 或 sliding window attention),以替代原有的注意力层。近期的研究(如 minimax-01、gemma2 等)已经充分验证了这种混合模型的有效性,但目前依然需要从头训练,尚未出现可以直接轻量级迁移已经训练好的 dense transformer 模型到 hybrid model 的方案。
我们希望提出一种简洁高效的方法,将已经预训练完成的 dense transformer 模型顺利转换为 hybrid models。为此,我们提出了 LightTransfer,这一思路源于一个关键观察:现有模型中存在大量呈现 “lazy” 特性的冗余层 [1]。因此,一个直观的想法就是将这些冗余层替换为仅需常数大小 KV cache 的 streaming attention,从而无需维护完整的 KV cache,将 dense Transformer 转变为更高效的 hybrid model。

图片来源:https://arxiv.org/pdf/2309.17453

-
项目主页:https://sites.google.com/view/lighttransfer
-
Huggingface 模型:cxdu/QwQ-32B-LightTransfer
-
github 代码:https://github.com/sail-sg/LightTrans
LightTransfer-Train
1) 方法
LightTransfer 的方法非常直接:我们先在训练集上跑一遍 benchmark,识别出最 “lazy”,也就是 lazy ratio 最高的 50% attention 层,然后将这些层替换为 streaming attention。lazy ratio 用来衡量模型在第 (i) 层的注意力分配:它统计了来自 Query 对初始和最近 key 的注意力权重之和,数值越高就代表该层的注意力越集中在这些 key 上,也就越 lazy。lazy ratio 的具体定义如下:

其中:
-
 表示最后一部分的查询(query)集合;
表示最后一部分的查询(query)集合; -
 分别表示初始与最近部分的键(key)集合;
分别表示初始与最近部分的键(key)集合; -
 为在第 i 层从查询 q 到键 k 的注意力权重。
为在第 i 层从查询 q 到键 k 的注意力权重。
当 值越高,说明第 i 层对这些键的关注度越集中,也就越“lazy”。
值越高,说明第 i 层对这些键的关注度越集中,也就越“lazy”。
QwQ 中每层的 lazy ratio 分布如下:
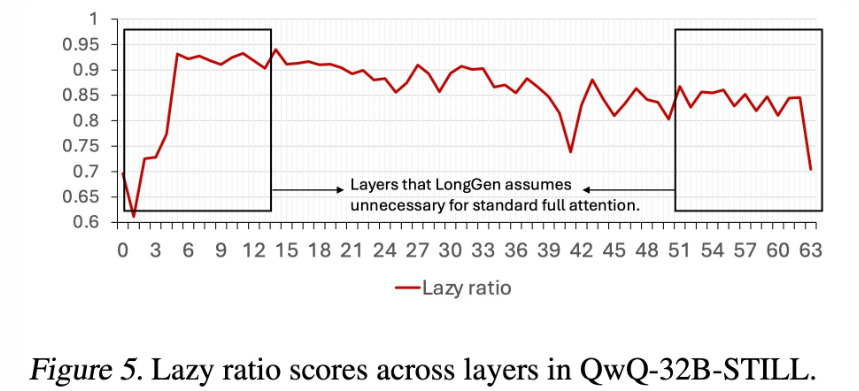
2) 实验结果
我们的主要实验对象是 o1 类的长 CoT 生成模型。由于 QwQ 并未公开其训练数据,我们遵循 STILL [2] 的方案,使用与其完全相同的训练设置(包括数据集、训练参数以及以 Qwen2.5-32B-Instruct 作为起点),唯一的差别在于,我们将 50% 的层换成 streaming attention。这样就能在推理阶段显著缩减近一半的 KV cache。

从表中可以看出,LightTransfer 在 AIME24 & 25 以及 MathOAI 上的表现优于 QwQ-STILL 和 o1-preview。
LightTransfer-Test
1) Motivation
对于另外一种更为主流的长上下文理解(long context understanding)任务而言,输入文本本身就非常冗长,因此在测试阶段可以对模型进行即时(on-the-fly) 转换。
2) 方法
基于这一点,我们提出了 LightTransfer-Test,使得模型在推理环节仅依赖 prefilling 的结果就能完成识别和转换。然而,在实际操作中,我们也面临了两个问题:
问题 1:与 Flash Attention 的不兼容
当前,Flash Attention 已成为标配,但它并不会显式计算并存储注意力权重 (attention weights);因此,如果我们想要获得用于衡量 lazy ratio 的注意力信息,就必须重新计算注意力权重,这会带来不可忽视的额外开销。
解决方案:为避免重复计算,我们借鉴了 online softmax 的思路,利用 Flash Attention 在计算过程中生成的 LSE(log-sum-exp)作为 lazy ratio 的分母。更值得注意的是,我们惊喜地发现分子的计算复杂度仅为 O (1),而若重新计算则需要 O (seq_len),因此这种方法有效地避免了大规模的重复开销。具体算法如下:

问题 2:prefilling 阶段的峰值内存
若等到 prefilling 结束后才根据各层的 lazy ratio 进行识别和转换,那么整个 prefilling 阶段所需的内存峰值并没有减少。
解决方案:为了解决这个问题,我们设计了一种基于优先队列的策略,保证在 prefilling 阶段,所需的内存峰值不会超过设定阈值(即 50% 的 full KV + 50% 的 streaming KV)。具体地说,我们维护一个以 lazy ratio 为优先级的队列:在 prefilling 过程中,一旦队列中排队的层数超出预先设定的阈值(例如 50% 的网络层),我们会从队列中移除 lazy ratio 最高的层,并将其 KV cache 切换为 streaming 版本。这样就无需像 SqueezeAttention [3] 那样等到 prefilling 完成后才压缩 KV cache,从而有效避免了 prefilling 阶段峰值内存居高不下的问题。LightTransfer 具体做法如下图:

3) 实验结果

从表中可以看出,LightTransfer-Test 在 LongBench 上相较于其他层间 KV cache 压缩方法(如 MiniCache 和 SqueezeAttention)具有更好的表现。它在将近一半的 KV cache 被削减的情况下,四个模型的平均性能仅下降了 1.5%; 尤其是在拥有更多层数的 LlaMa 3-70B 上。
[1] Xiao et al. Efficient streaming language models with attention sinks. ICLR 2024.
[2] Min ei tal. Imitate, explore, and self-improve: A reproduction report on slow-thinking reasoning systems. arXiv 2024.
[3] Wang ei al. Squeezeattention: 2d management of kv-cache in llm inference via layer-wise optimal budget. ICLR 2025.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com