DeepSeek GRPO算法加持,7B模型仅用强化学习拿下数独!博主实测,无需冷启动数据,探索语言模型结构化推理能力。
原文标题:使用DeepSeek的GRPO,7B模型只需强化学习就能拿下数独
原文作者:机器之心
冷月清谈:
本文是技术博主Hrishbh Dalal关于使用DeepSeek GRPO算法,通过强化学习训练7B参数语言模型解决数独问题的实践总结。实验旨在探索语言模型在结构化思维、空间推理和逻辑推理方面的能力。文章详细介绍了数据准备(包括难度分级和格式转换)、实验方法(对比7B和3B模型)、奖励系统(格式合规性、网格架构、解答准确度和规则合规性)的设计,并分享了实验结果和从中获得的启发,主要包括模型尺寸对学习稳定性的影响、多成分奖励的重要性,以及强化学习在教授结构化思维方面的潜力。最后,作者提出了未来研究方向,包括增加难度、扩大计算规模、探索模型架构、使用蒸馏法等,并强调了基于过程的奖励对模型学习复杂推理任务的重要性。实验表明,即使没有冷启动数据,7B模型也能通过强化学习学会玩数独,但3B模型表现不佳,这暗示了复杂推理任务存在一个最小的模型规模阈值。
怜星夜思:
1、文章中提到7B模型在解决数独问题上表现出色,而3B模型则遇到困难。除了模型大小,还有哪些因素可能导致这种差异?例如,LoRA秩的选择对结果有什么影响?
2、文章中设计了多种奖励函数,包括格式合规性、网格架构、解答准确度以及规则合规性奖励。你认为哪种奖励函数对于模型学习解决数独问题至关重要?为什么?
3、文章提到作者计划使用蒸馏法,从更大的模型(如DeepSeek R1)中提炼冷启动数据集。你认为这种方法对于提高模型解决数独问题的能力有多大帮助?蒸馏过程中有哪些需要注意的关键点?
2、文章中设计了多种奖励函数,包括格式合规性、网格架构、解答准确度以及规则合规性奖励。你认为哪种奖励函数对于模型学习解决数独问题至关重要?为什么?
3、文章提到作者计划使用蒸馏法,从更大的模型(如DeepSeek R1)中提炼冷启动数据集。你认为这种方法对于提高模型解决数独问题的能力有多大帮助?蒸馏过程中有哪些需要注意的关键点?
原文内容
选自hrishbh.com
作者:Hrishbh Dalal
编译:Panda、蛋酱
没有任何冷启动数据,7B 参数模型能单纯通过强化学习学会玩数独吗?
近日,技术博主 Hrishbh Dalal 的实践表明,这个问题的答案是肯定的。并且他在这个过程中用到了 DeepSeek 开发的 GRPO 算法,最终他「成功在一个小型数独数据集上实现了高奖励和解答」。

下面我们就来具体看看他的博客文章,了解一番他的开发思路。
原文地址:https://hrishbh.com/teaching-language-models-to-solve-sudoku-through-reinforcement-learning/
现在的语言模型已经能完成很多任务了,包括写论文、生成代码和解答复杂问题。但是,如何让它们学会解答需要结构化思维、空间推理和逻辑推理的难题呢?这就是我最近的实验的切入点 —— 通过强化学习教语言模型解决数独问题。
教语言模型玩数独的难点
对语言模型来说,数独有自己独特的难点。不同于开放式的文本生成,玩数独需要:
-
遵循严格的规则(每行、每列和每框必须包含数字 1-9,且不能重复)
-
保持一致的网格格式
-
应用逐步的逻辑推理
-
理解网格元素之间的空间关系
-
得出一个正确的解答
有趣的是,语言模型并不是为结构化问题设计的。它们的训练目标是预测文本,而不是遵循逻辑规则或维持网格结构。然而,通过正确的方法,它们可以学会这些技能。
准备数据:从数值到网格
本实验使用了来自 Kaggle 的包含 400 万数独的数据集,其中有非常简单的,也有非常困难的。准备数据集的过程包含几大关键步骤:
1、加载和过滤:使用 kagglehub 库下载数据集并根据难度级别过滤数独。
2、难度分类:根据线索数量,将数独分为四个难度级别:
-
Level 1(非常简单):50-81 条线索
-
Level 2(简单):40-49 条线索
-
Level 3(中等):30-39 条线索
-
Level 4(困难):17-29 条线索
3、每个数独一开始都被表示成了 81 个字符的字符串。这里将其转换为具有适当行、列和框分隔符的网格格式:

4、提示词工程:每个数独都会被封装在一个精心设计的提示词中,而该提示词的作用是指示模型:
-
在 <think> 标签中逐步思考解决方案
-
在 <answer> 标签中提供具有适当网格格式的最终答案
对于初始实验,我创建了一个包含 400 个训练样本的聚焦数据集,这主要是使用更简单的数独来为学习构建一个基线。这个数据集被刻意选得较小,目的是测试模型使用有限样本学习的效率。加上我的资源有限:如果使用 unsloth grpo 训练,24GB RTX 4090 大约最多只能放入 3000 上下文长度。因此我只能选择更简单的问题以避免内存溢出(OOM),因为困难的问题及其推理链更长。
实验方法
我决定探索强化学习(尤其是 GRPO)能否让语言模型变成数独求解器。我实验了两种不同的模型大小:
-
Qwen 2.5 7B Instruct:使用了秩为 16 的 LoRA 进行微调
-
Qwen 2.5 3B Instruct:使用了秩为 32 的 LoRA 进行微调
重要的是,我没有使用冷启动数据或从 DeepSeek R1 等较大模型中蒸馏的数据。这里会从基础指令微调版模型开始,单纯使用强化学习。训练配置包括:
-
批量大小:1
-
梯度累积步骤:8
-
学习率:3e-4(Karpathy 常数)
-
最大部署:500
-
每 10 步评估一次
-
最大序列长度:3000 token

Andrej Karpathy 曾表示 3e-4 是 Adam 的最佳学习率
奖励系统:通过反馈进行教学
强化学习的核心是奖励函数 —— 可以告诉模型它何时表现良好。我设计了一个多分量奖励系统,它具有几个专门的功能:
1. 格式合规性奖励
为了实现良好的解析,模型应该始终记得使用正确的思考和答案标签(分别是 <think></think> 和 <answer></answer> 标签)。这些标签有两个关键目的:
-
将推理过程与最终答案分开
-
使提取与评估模型的解答变得容易
为了强制实施这种结构,我实现了两个互补的奖励函数:

第一个函数(tags_presence_reward_func)为出现的每个标签提供部分 credit,其作用是鼓励模型包含所有必需的标签。第二个函数(tags_order_reward_func)则用于确保这些标签以正确的顺序出现 —— 先思考再回答。它们一起可教会模型保持将推理与解答分开的一致结构。
2. 网格架构奖励
为了让我们读懂数独的解答,必须以特定的网格格式呈现它。该奖励函数的作用便是评估模型维持正确网格结构的能力:

该函数会将网格格式分解为多个部分 —— 正确的行数、正确的分隔符位置、适当使用分隔符。模型每个方面正确了都会获得一些奖励。这种细粒度的方法有助于模型学习数独网格的特定空间结构。
3. 解答准确度奖励
当然,最终目标是让模型正确解答数独。这里使用了两个奖励函数来评估解答的准确度:

第一个函数 (exact_answer_reward_func) 会为完全正确的解答提供大奖励 (5.0),从而为模型提供正确解答数独的强大动力。
第二个函数 (simple_robust_partial_reward_function) 会更微妙一些,会为部分正确的解答提供部分 credit。它有两个关键特性:
-
严格强制模型保留原始线索(如果任何线索发生变化,则给予零奖励);
-
对于模型正确填充的每个空单元格,都按比例给予奖励。
这种部分奖励对于学习至关重要,因为它能为模型在训练期间提供更平滑的梯度。
4. 规则合规奖励
最后,数独解答必须遵守游戏规则 —— 任何行、列或 3×3 框中都没有重复数字:

该函数会检查每行、每列和每 3×3 框是否有重复项,模型满足每个约束时都能获得一些奖励。这能让模型学会数独的基本规则,鼓励它生成有效的解答,即使它们与预期答案不完全匹配。
出人意料的结果:尺寸很重要
实际训练结果揭示了一些有趣的事情:模型大小对学习稳定性和性能具有巨大的影响。
7B 模型(使用了秩为 16 的 LoRA)结果优良:
-
保持了稳定的完成长度,约为 1000 token
-
能生成格式一致的解答
-
奖励指标稳步提升
-
在整个训练过程中保持了策略稳定性
与之形成鲜明对比的是,3B 模型(使用了秩为 32 的 LoRA )表现不佳:
-
训练期间出现灾难性的不稳定性
-
出现巨大的策略分歧(KL 飙升至 80!)
-
未能保持一致的性能
-
最终崩溃,无法恢复
图表清楚地说明了这一点:7B 模型(粉色线)保持了稳定的性能,而 3B 模型(绿色线)则出现了剧烈波动,并且最终完全失败。
训练和测试的完成长度情况:

训练和测试的净奖励:

答案格式奖励:

最重要的:最终答案奖励(模型生成完全正确的响应网格并完全匹配):
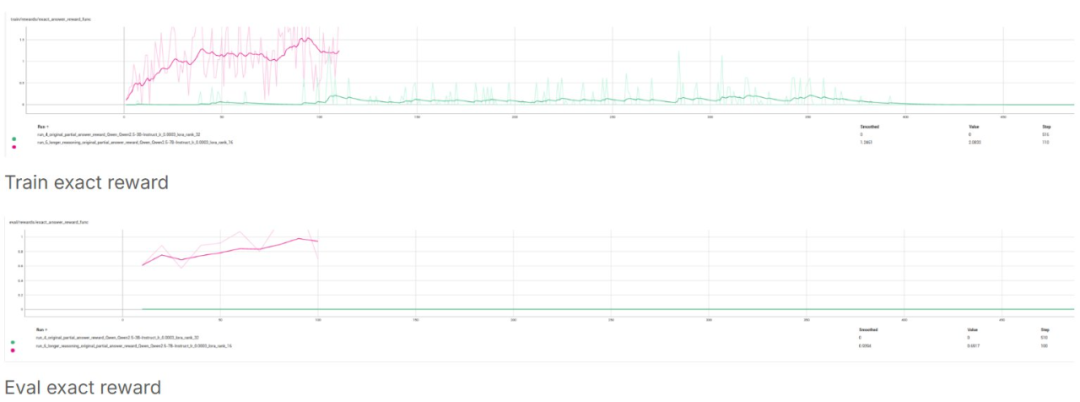
对于 7B 模型,精确答案奖励增长意味着模型能给出完全匹配的答案,但 3B 则出现崩溃情况。这证明 7B 模型学会了用很少的数据解决数独问题,并且学习速度很快!
部分奖励:

我们得到的启发
这个实验揭示了关于复杂推理任务的语言模型教学的几个重要启示:
1、Deepseek R1 论文中提到,在没有冷启动数据的情况下,复杂推理存在一个最小规模阈值。
有些任务需要一定的模型能力才能稳定学习。3B 模型的失败表明,数独解题可能就是这样一种任务。
2、稳定是学习的前提
在模型学会正确解题之前,它需要保持稳定的训练动态。7B 模型始终如一的指标使其能够取得稳步进展。
3、多成分奖励提供更好的指导
与单一的通过 / 失败信号相比,将奖励细分为格式合规性、规则遵守性和解题准确性有助于更有效地指导学习过程。
4、强化学习可以教授结构化思维
尽管困难重重,GRPO 还是成功地教会了 7B 模型保持正确的格式并开始解题,这些技能并不是语言模型所固有的。
下一步:扩大实验范围
这在很大程度上是一个持续进行的项目,计划下一步采取几个步骤:
-
增加难度:引入更具挑战性的谜题来测试模型的推理能力
-
扩大计算规模:使用更多计算资源,进行更长时间和更大批次的训练
-
探索模型架构:测试 7B 模型的 LoRA rank 32,看更高的 rank 是否能提高性能
-
蒸馏法:从 DeepSeek R1 等大型模型中提炼出冷启动数据集,然后在此基础上应用 GRPO
-
高级奖励函数:实施我已经设计好但尚未在训练中部署的更细致入微的奖励机制
-
评估框架:开发更复杂的评估指标,以评估推理质量,而不仅仅是解决方案的准确性
增强的奖励函数的重要性
我未来工作中最重要的一个方面就是实现我已经设计好的更复杂的奖励函数。目前的简单奖励函数是有效的,但增强版包含了几项关键改进,可以显著提高学习效率。
以下是我设计的增强奖励函数,但尚未在训练中实施:

这些奖励函数背后的思维过程
我的奖励函数设计理念围绕几个关键原则:
-
渐进式奖励优于二元反馈:我不会简单地将答案标记为正确或错误,而是为部分解答提供部分奖励。这能创造一个更平滑的学习梯度,有助于模型渐进式改进。
-
难度感知型扩展:这些增强过的函数会将问题难度作为一个乘数,这能为解决更难的问题提供更高的奖励。这能鼓励模型解决更难的问题,而不仅仅是优化简单的问题。
-
严格的线索保存:所有奖励函数都执行了一条不可协商的规则,即必须保留原始问题线索。这可以防止模型通过更改问题本身来「作弊」。
-
额外奖励阈值:这些经过增强的函数包括当模型超过某些性能阈值(75%、85%、95% 正确)时的额外奖励。当模型走上正轨时,这些作为激励里程碑,可以加速学习。
-
最低奖励底线(我最关注的一点):即使是部分正确的解答也会获得较小的最低奖励(0.05),确保模型即使进展很小,也能获得一些反馈。
当前的简单函数侧重于最关键的方面(线索保存和部分 credit),而这里增强后的版本则通过难度调整和渐进奖励增加了复杂性。在未来的训练中,我计划实现这些更微妙的奖励函数,看看它们能否进一步提高学习效率和解答质量。
我设计奖励函数的关键见解是:基于过程的奖励(奖励旅程,而不仅仅是目的)对于模型学习复杂的推理任务至关重要。通过提供中间步骤和部分解答的反馈,可创建一个比二元成功 / 失败信号更有效的学习环境。
这很重要,并且不仅是数独
让语言模型学会玩数独不仅仅是为了解谜娱乐,还为了开发能够完成以下任务的 AI 系统:
-
遵从结构化流程
-
逐步应用逻辑推理
-
保持格式一致性
-
根据已知规则验证自己的成果
-
理解空间关系
这些功能的应用场景远不止于游戏:
-
编程:教模型编写遵循严格语法和逻辑约束的代码
-
数学问题求解:实现复杂数学问题的分步解答
-
科学推理:帮助模型理解和应用科学方法和原理
-
形式验证:训练模型根据既定规则检查自己的成果
总结:未尽的旅程
这个实验只是我通过强化学习让语言模型学习结构化推理的探索的开始。虽然 7B 模型的初步结果很有希望,但仍有许多需要学习和改进的地方。
3B 和 7B 模型性能之间的明显差异凸显了一个重要的教训:对于某些任务,要实现稳定学习,对基础模型有最低的尺寸要求。随着我继续使用更多数据、更好的奖励函数和更大的模型来改进方法,我期望看到更出色的结果。
随着新发现的出现,我将定期更新这个项目。教机器逻辑思考和解决结构化问题的旅程充满挑战但又令人着迷 —— 我很期待其未来走向。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com